
1. 技术背景
锁在 Linux 内存管理中起着非常重要的作用。一方面,锁在内存管理中保护了多线程的临界区并发处理; 另一方面,内存管理各种锁的使用在一些场景也会表现出性能问题。本文针对内核内存管理中典型的锁进行介绍及典型优化案例总结。
本文分析基于 Linux 内核 6.9 版本(部分为低版本内核,会特别说明)。
2. 内存管理中的锁
2.1 PG_Locked
Linux 内核物理内存使用 page 进行管理,page 的使用需要考虑并发处理,在内核中借助 PG_locked 实现,当 page 被标记了 PG_locked 时表明 page 已经被锁定,正在使用中,不要修改。page 结构体中定义了 flag 可以表示是否被锁定。
struct page {
unsigned long flags; /* Atomic flags, some possibly
* updated asynchronously */
…
}内核中使用 lock_page 来对 page 上锁。接口如下:
static inline bool folio_trylock(struct folio *folio)
{
return likely(!test_and_set_bit_lock(PG_locked, folio_flags(folio, 0)));
}
void __folio_lock(struct folio *folio)
{
folio_wait_bit_common(folio, PG_locked, TASK_UNINTERRUPTIBLE,
EXCLUSIVE);
}
static inline void lock_page(struct page *page)
{
struct folio *folio;
might_sleep();
folio = page_folio(page);
if (!folio_trylock(folio))
__folio_lock(folio);
}从上面代码可以看到,lock_page是可能存在睡眠的,因此,不要在不可睡眠的上下文使用。它会尝试对page设置PG_locked标记,如果page的PG_locked已经被置位,也就是此时有人正在访问此page,会通过__folio_lock设置uninterruptable sleep状态等待PG_locked标记被清除。
以典型的 filemap_fault 为例,使用 PG_locked 流程如下:
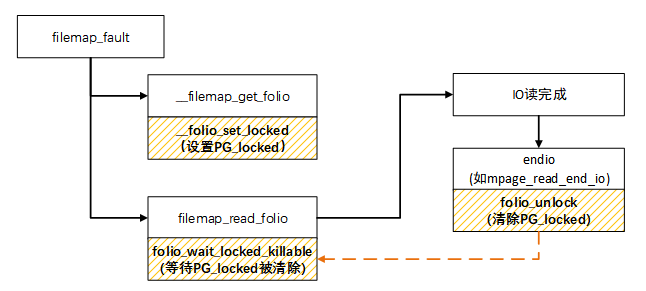
filemap_fault -> __filemap_get_folio ->filemap_get_pages -> filemap_add_folio-> __folio_set_locked(设置page的PG_locked)
filemap_read_folio-> folio_wait_locked_killableà folio_wait_bit_killable(folio, PG_locked) –> folio_wait_bit_common(等IO完成PG_locked被清除)
mpage_read_end_io->folio_mark_uptodate->folio_unlock(IO完成时会标记page的PG_update,同时清除PG_locked)。
简单来说,当发生文件页 pagefault,所需内存不在文件缓存时,会分配 page 页面,发起 IO 读操作,但这里 IO 读操作仅下发 IO 读请求,还不能保证 page 中已经读取到所需内容,因此会在下发 IO 读请求前设置了 PG_locked 标记,当 IO 完成时,会清除 PG_locked 标记。这也就是为什么可以在 systrace 中看到 blockio 黄条时一般会 blocked reson 为 folio_wait_bit_killable 的原因。
同理,匿名页发生 page fault 时也是类似流程,只是如果使用 zram 时,没有实际的 IO 而已。整个过程同样也是由 PG_locked 控制页面等待及完成读取(解压缩)的并发过程。
2.2 lru_lock
Linux 内核在内存回收是使用 LRU(Last Recent Used)算法,即最近最少使用算法。在内存回收时扫描 active 和 inactive LRU 链表进行。lruvec 结构体中有一个自旋锁保护 LRU 链表的操作过程的并发问题。
struct lruvec {
struct list_head lists[NR_LRU_LISTS];
/* per lruvec lru_lock for memcg */
spinlock_t lru_lock;
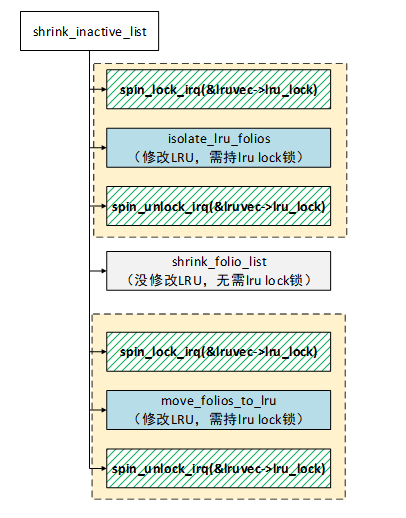
}shrink_inactive_list和shrink_active_list等典型的操作LRU的过程都需要持有此锁。下面以shrink_inactive_list为例,列举了锁的使用过程。
2.3 mmap_lock
Linux 内核用 vma 表示进程地址空间,进程地址的访问受 mmap_lock 锁保护。mmap_lock 是定义在 mm_struct 中的读写信号量成员。
struct mm_struct {
…
struct rw_semaphore mmap_lock;
…
}mmap_lock保护进程虚拟地址vma rbtree、vma list、vma flags等。进程发生page fault缺页,mmap, mprotect等访问vma的操作时,可能会持有该锁。
获取 mmap_lock 写锁一般以下典型接口:
mmap_write_trylock
mmap_write_lock_killable
mmap_write_lock
mmap_write_lock_nested
我们以 mmap_write_lock_killable 为例看下具体的 API 实现:
#define TASK_KILLABLE (TASK_WAKEKILL | TASK_UNINTERRUPTIBLE)
static inline int __down_write_killable(struct rw_semaphore *sem)
{
return __down_write_common(sem, TASK_KILLABLE);
}
int __sched down_write_killable(struct rw_semaphore *sem)
{
might_sleep();
rwsem_acquire(&sem->dep_map, 0, 0, _RET_IP_);
if (LOCK_CONTENDED_RETURN(sem, __down_write_trylock,
__down_write_killable)) {
rwsem_release(&sem->dep_map, _RET_IP_);
return -EINTR;
}
return 0;
}
static inline int mmap_write_lock_killable(struct mm_struct *mm)
{
int ret;
__mmap_lock_trace_start_locking(mm, true);
ret = down_write_killable(&mm->mmap_lock);
__mmap_lock_trace_acquire_returned(mm, true, ret == 0);
return ret;
}从上面可以看出down_write_killable获取mmap_lock过程可能会sleep,因此调用者需要注意不能使用在不可睡眠上下文。如果成功获取到锁,返回0,如果获取不到锁(锁已经被其它线程持有),会设置当前进程为TASK_KILLABLE状态,TASK_KILLABLE状态其实就是可杀的D状态,从宏定义可以到它是TASK_WAKEKILL | TASK_UNINTERRUPTIBLE的组合。
在 systrace 中经常可以看到这几个函数的 block reson 的紫色的 uninterruptable sleep 的 D 状态。
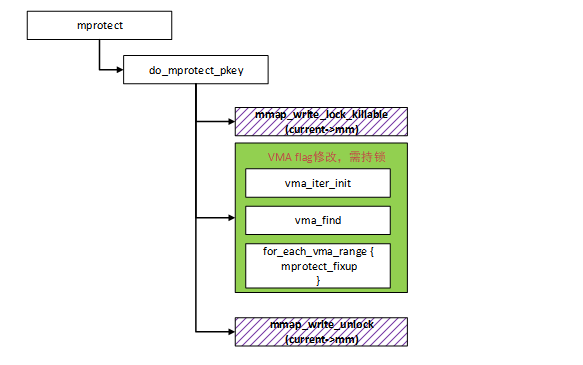
mprotect 可以用来修改一段指定内存区域的保护属性。由于它会修改进程 vma 区域 flag,因此,为了处理并发问题,需要 mmap_lock 的保护。我们以 mprotect 为例,分析 mmap_lock 的使用。
内核中的 mmap_lock(在 5.15 之前的内核版本中称为 mmap_sem)锁,实际上是一个读写锁,可以支持并发的多线程读访问。然而,在某些情况下,即使需要获取读取者(reader)读锁,也需要等待,这时该锁实际上就变成了互斥锁。这种情况常见于下面两种场景:
1)线程 1 持有写锁,线程 2 尝试获取读锁。
线程 1 持有写锁时,线程 2 需要等待直到线程 1 释放写锁。这种行为确保了在有写者的情况下,其他线程(包括读者)将被阻塞。这种等待直到写锁释放的模式类似于互斥锁的行为。
2) 线程 1 持有读锁,线程 2 尝试获取写锁,后续线程 3 也尝试获取读锁:
线程 1 持有读锁时,线程 2 尝试获取写锁而处于等待状态。由于写者优先级高于读者,因此线程 3 即使尝试获取读锁也会处于等待状态,直到写锁被释放。这保证了在需要修改共享数据时,写者优先级最高,而后续读者需要等待写锁释放后才能获取读锁。
因此,即使是一个读写锁,在特定条件下也可能会表现出类似于互斥锁的行为,以保证对共享资源操作的正确性和一致性。
2.4 anon_vma->rwsem
Linux 内核内存紧张时会进行内存回收。内存回收通过反向映射 rmap 机制找到 page 所有映射的 vma 并进行解除映射。对匿名页而言,page 找到 vma 的路径一般如下:page->av(anon_vma)->avc(anon_vma_chain)->vma,其中 avc 起到桥梁作用。
anon_vma 简称 av, 用于管理匿名页 vma, 当匿名页需要解映射时需要先找到 av,再通过 av 进行查找处理。struct anon_vma_chain,简称 avc。主要用于链接 vma 和 av。
这几个重要数据结构的关系如下图:
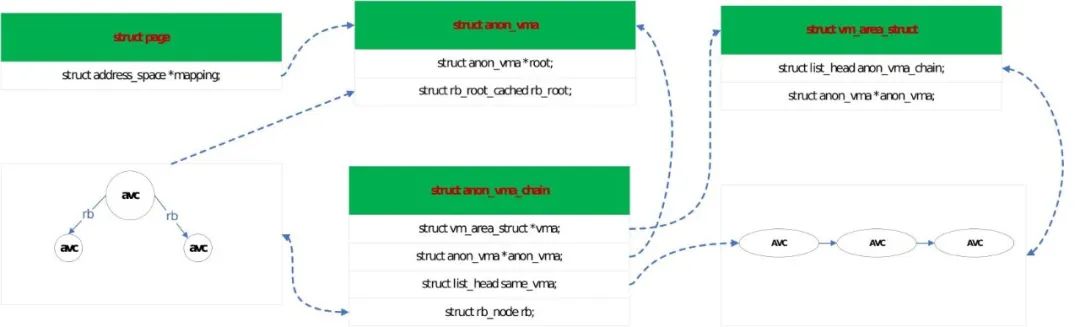
anon_vma 定义了一组红黑树,vma 中数据结构维护了 avc,当需要访问 av 中的红黑树数据和 vma 中的 avc 时,需要锁保护。
anon_vma->rwsem 是定义在 anon vma 数据结构中的读写信号量。
struct anon_vma {
struct anon_vma *root; /* Root of this anon_vma tree */
struct rw_semaphore rwsem; /* W: modification, R: walking the list */
…
}获取锁的接口主要是anon_vma_lock_write和anon_vma_lock_read。当然也有带try类型的。这里不赘述。
static inline void __sched __down_write(struct rw_semaphore *sem)
{
rwbase_write_lock(&sem->rwbase, TASK_UNINTERRUPTIBLE);
}
static inline void anon_vma_lock_write(struct anon_vma *anon_vma)
{
down_write(&anon_vma->root->rwsem);
}
static inline void anon_vma_lock_read(struct anon_vma *anon_vma)
{
down_read(&anon_vma->root->rwsem);
}可以看到,如果anon_vma的rwsem没有获取成功(已有其它线程持有)。当前进程会设置为TASK_UNINTERRUPTIBLE。这也是systrace中我们有时可能看到block reason为anon_vma_lock_write的D状态(uninterruptable sleep)的原因。
典型的在fork线程时dup_mmap->anon_vma_fork->anon_vma_lock_write持写锁路径:
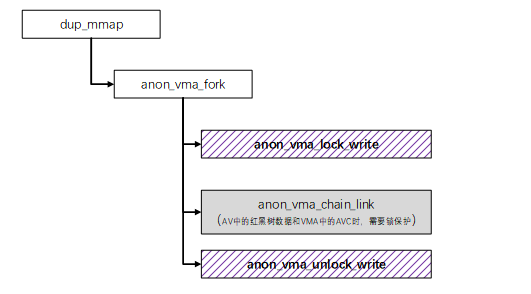
内存回收对匿名页进行反向映射是需要持读锁的典型路径:
static struct anon_vma *rmap_walk_anon_lock(struct folio *folio,
struct rmap_walk_control *rwc)
{
struct anon_vma *anon_vma;
if (rwc->anon_lock)
return rwc->anon_lock(folio, rwc);
anon_vma = folio_anon_vma(folio);
if (!anon_vma)
return NULL;
if (anon_vma_trylock_read(anon_vma))
goto out;
if (rwc->try_lock) {
anon_vma = NULL;
rwc->contended = true;
goto out;
}
//获取读锁
anon_vma_lock_read(anon_vma);
out:
return anon_vma;
}
static void rmap_walk_anon(struct folio *folio,
struct rmap_walk_control *rwc, bool locked)
{
struct anon_vma *anon_vma;
pgoff_t pgoff_start, pgoff_end;
struct anon_vma_chain *avc;
if (locked) {
anon_vma = folio_anon_vma(folio);
/* anon_vma disappear under us? */
VM_BUG_ON_FOLIO(!anon_vma, folio);
} else {
//获取读锁
anon_vma = rmap_walk_anon_lock(folio, rwc);
}
if (!anon_vma)
return;
//遍历找VMA过程需要锁保护
pgoff_start = folio_pgoff(folio);
pgoff_end = pgoff_start + folio_nr_pages(folio) - 1;
anon_vma_interval_tree_foreach(avc, &anon_vma->rb_root,
pgoff_start, pgoff_end) {
struct vm_area_struct *vma = avc->vma;
unsigned long address = vma_address(&folio->page, vma);
VM_BUG_ON_VMA(address == -EFAULT, vma);
cond_resched();
if (rwc->invalid_vma && rwc->invalid_vma(vma, rwc->arg))
continue;
if (!rwc->rmap_one(folio, vma, address, rwc->arg))
break;
if (rwc->done && rwc->done(folio))
break;
}
if (!locked)
//释放锁
anon_vma_unlock_read(anon_vma);
}2.5mapping->i_mmap_rwsem
上一节介绍了匿名页反向映射需要的锁,同样,文件页在反向映射也需要对应的锁,它就是 mapping->i_mmap_rwsem。page 结构体中有 mapping 成员。借助此成员,可以方便快捷地找到对应匿名页或文件页。在 page->mapping 不为 0 的情况下,如果第 0 位为 0,说明该页为匿名页,此 mmaping 指高一个 anon_vma 结构变量;如果第 0 位不为 0,则 mapping 指向一个每个 file 一个的 address_space 地址空间结构变量。
struct address_space 结构体中的 i_mmap 是一个优先搜索树,关联了这个文件 page cache 页的 vm_area_struct 就挂在这棵树上。当文件页反向映射时,需要通过 page--->i_mmap--->vma 这个查找顺序并解除对应映射。
struct address_space 结构体中定义了 i_mmap_rwsem 读写信号量锁,用于保护 i_mmap。
struct address_space {
struct inode *host;
struct xarray i_pages;
struct rw_semaphore invalidate_lock;
gfp_t gfp_mask;
atomic_t i_mmap_writable;
#ifdef CONFIG_READ_ONLY_THP_FOR_FS
/* number of thp, only for non-shmem files */
atomic_t nr_thps;
#endif
struct rb_root_cached i_mmap;
unsigned long nrpages;
pgoff_t writeback_index;
const struct address_space_operations *a_ops;
unsigned long flags;
errseq_t wb_err;
spinlock_t i_private_lock;
struct list_head i_private_list;
struct rw_semaphore i_mmap_rwsem;
void * i_private_data;
} __attribute__((aligned(sizeof(long)))) __randomize_layout;典型的获取 i_mmap_rwsem 锁的接口是 i_mmap_lock_write 和 i_mmap_lock_read。获取写锁的路径举例如下:
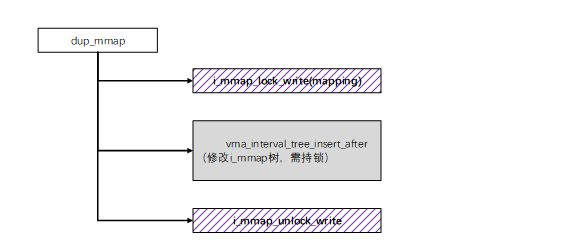
内存回收对文件页进行反向映射是需要持读锁的典型路径:
static void rmap_walk_file(struct folio *folio,
struct rmap_walk_control *rwc, bool locked)
{
struct address_space *mapping = folio_mapping(folio);
pgoff_t pgoff_start, pgoff_end;
struct vm_area_struct *vma;
/*
* The page lock not only makes sure that page->mapping cannot
* suddenly be NULLified by truncation, it makes sure that the
* structure at mapping cannot be freed and reused yet,
* so we can safely take mapping->i_mmap_rwsem.
*/
VM_BUG_ON_FOLIO(!folio_test_locked(folio), folio);
if (!mapping)
return;
pgoff_start = folio_pgoff(folio);
pgoff_end = pgoff_start + folio_nr_pages(folio) - 1;
if (!locked) {
if (i_mmap_trylock_read(mapping))
goto lookup;
if (rwc->try_lock) {
rwc->contended = true;
return;
}
//持读锁
i_mmap_lock_read(mapping);
}
lookup:
//遍历i_mmap,需锁保护
vma_interval_tree_foreach(vma, &mapping->i_mmap,
pgoff_start, pgoff_end) {
unsigned long address = vma_address(&folio->page, vma);
VM_BUG_ON_VMA(address == -EFAULT, vma);
cond_resched();
if (rwc->invalid_vma && rwc->invalid_vma(vma, rwc->arg))
continue;
if (!rwc->rmap_one(folio, vma, address, rwc->arg))
goto done;
if (rwc->done && rwc->done(folio))
goto done;
}
done:
if (!locked)
//释放锁
i_mmap_unlock_read(mapping);
}2.6shrinker_rwsem
1.9 内核 shrinker_rwsem 已经被改为 mutex 了。这里呈现原来的 shrinker_rwsem 使用及问题,因此这部分基于 6.6 内核进行分析。后续的案例会分析 6.9 内核针对这个锁的优化改动。
shrinker 是一把全局的读写信号量锁。
DECLARE_RWSEM(shrinker_rwsem)shrinker_rwsem 锁主要用于保护 shrinker_list 链表。驱动可能会注册相应的 shinker 以便在内存回收时被回调进行 shrinker 其内存。在注册时会将对应的 shrinker 加到全局的 shrinker->list 上。在内存紧张进行内存回收时会遍历 shrinker->list 的 shrinker 进行回调。因此为处理并发问题,需要锁保护。shrinker->rwsem 主要就是确保这两个过程的并发。
获取写锁的典型路径:
void register_shrinker_prepared(struct shrinker *shrinker)
{
down_write(&shrinker_rwsem);
list_add_tail(&shrinker->list, &shrinker_list);
shrinker->flags |= SHRINKER_REGISTERED;
shrinker_debugfs_add(shrinker);
up_write(&shrinker_rwsem);
}获读锁的典型路径:
static unsigned long shrink_slab(gfp_t gfp_mask, int nid,
struct mem_cgroup *memcg,
int priority)
{
unsigned long ret, freed = 0;
struct shrinker *shrinker;
/*
* The root memcg might be allocated even though memcg is disabled
* via "cgroup_disable=memory" boot parameter. This could make
* mem_cgroup_is_root() return false, then just run memcg slab
* shrink, but skip global shrink. This may result in premature
* oom.
*/
if (!mem_cgroup_disabled() && !mem_cgroup_is_root(memcg))
return shrink_slab_memcg(gfp_mask, nid, memcg, priority);
//获取shrinker_rwsem读锁
if (!down_read_trylock(&shrinker_rwsem))
goto out;
//遍历shrinker_list进行回调,需要锁保护
list_for_each_entry(shrinker, &shrinker_list, list) {
struct shrink_control sc = {
.gfp_mask = gfp_mask,
.nid = nid,
.memcg = memcg,
};
ret = do_shrink_slab(&sc, shrinker, priority);
if (ret == SHRINK_EMPTY)
ret = 0;
freed += ret;
/*
* Bail out if someone want to register a new shrinker to
* prevent the registration from being stalled for long periods
* by parallel ongoing shrinking.
*/
if (rwsem_is_contended(&shrinker_rwsem)) {
freed = freed ? : 1;
break;
}
}
//放锁
up_read(&shrinker_rwsem);
out:
cond_resched();
return freed;
}
3. 典型优化案例总结
3.1 Linux 开源社区优化案例
3.1.1 案例 1:per memcg lru_lock 优化 1
自内核引入 memcg 以来,系统单一的 lru list 已经分成了每个内存组一个 lru list,由每个内存组单独管理自己的 lru lists。但 per memcg lru lock 却没有同时引入,导致 lru 锁在不同 memcg 上的竞争十分激烈。社区中 per-memcg LRU lock 的补丁集为每个 memcg 引入了 lru lock,来解决这个存在已久的问题。
阿里巴巴的 Alex Shi 在 2020 年提交了一组 patchset 优化此问题,在 linux5.11 合入主线。
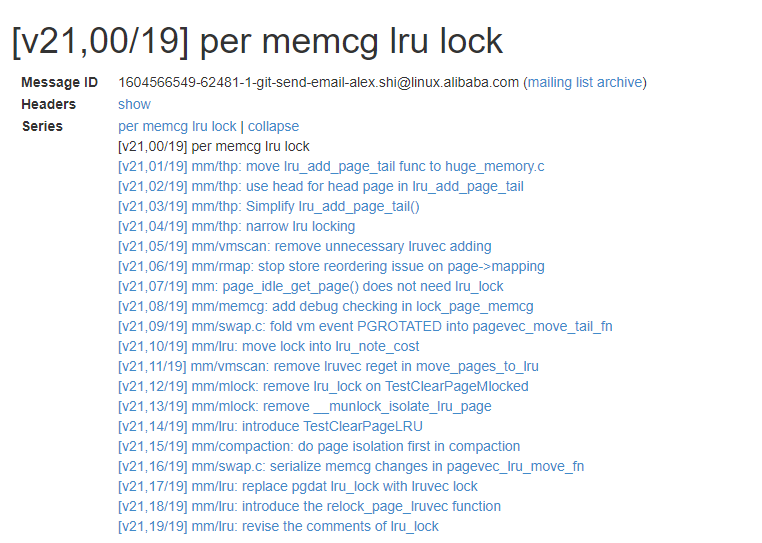
通过这组 patchset 的修改,获得了 62%的性能提升。
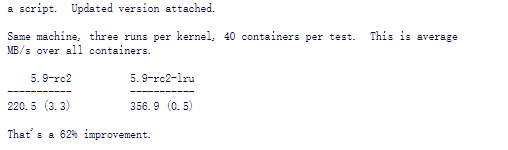
这个改动主要是是通过大锁化小锁。
优化的核心如下:
1)在 lruvec 增加了 per memcg 的 spinlock_t 类型的 lru_lock 成员。
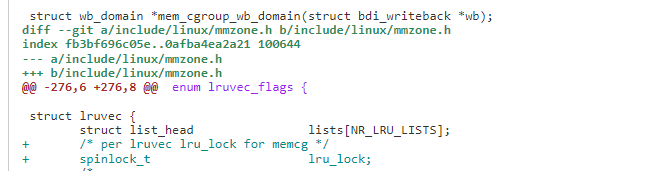
2)对给定的 page,可以获取对应 memcg 的 lruvec 的 lru_lock 并返回对应 lruvec。
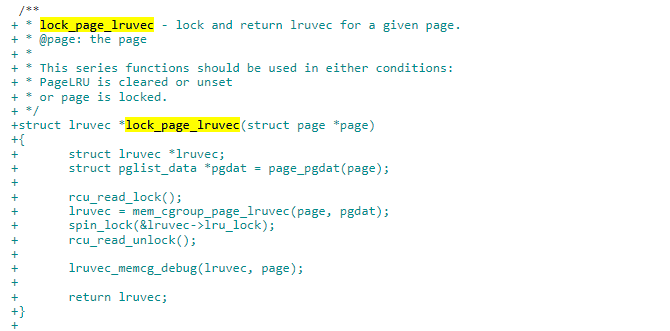
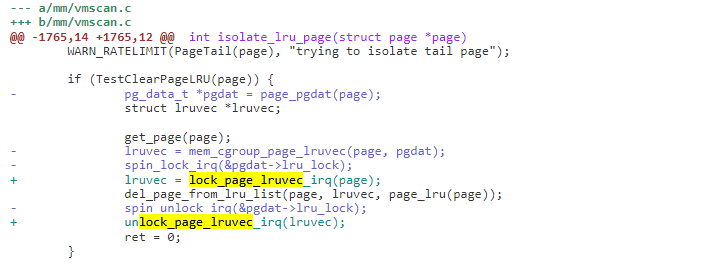
3)原来需要获取 node 的 lru_lock 的地方,换成了获取 memcg 的 lru_lock。
3.1.2 案例 2:mmap_lock 优化之 IO fault path 路径锁优化 2
在内核中经常发生优先级翻转的问题。例如一个进程在遍历/proc/pid 节点下的任何信息,可能会获取 mmap_lock 读锁,但如果一个低优先级任务获取了 mmap_lock 写锁,或正在执行耗时操作,这对高优先级进程的性能明显产生了影响。
Josef Bacik 在 2018 年提交了一组 patchset, 在 page fault 发生 IO 耗时操作路径上尽快释放 mmap_lock 锁,相关处理借助 page fault 现成的 retry 机制完成。在 linux5.1 内核进入主线。

此组 patchset 几个关键修改点:
1)增加 page fault 的 cached_page,retry 时 handle_mm_fault_cacheable 直接处理

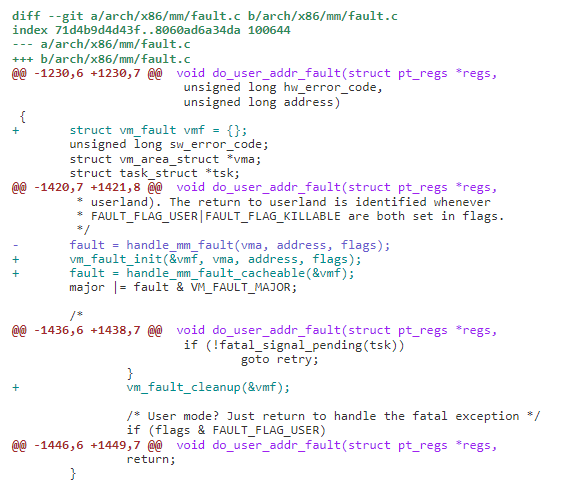
2)重新设计文件映射 page fault 路径,以便在可能执行 IO 或长时间阻塞的任何时间点释放 mmap sem(mmap_lock)
新增加 maybe_unlock_mmap_for_io,在可能执行 IO 操作时调用,可能会释放 mmap_sem 锁。
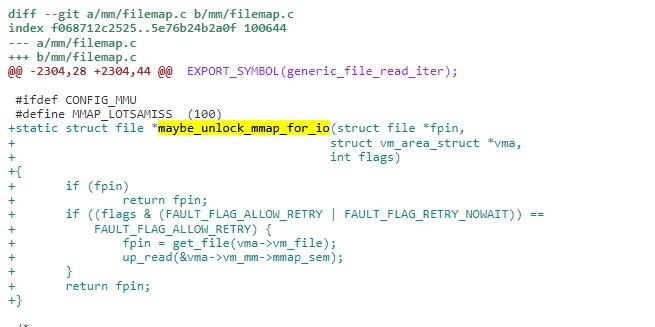

耗时的 IO 还没有完成,释放 mmap_sem 锁,返回 VM_FAULT_RETRY 重载获取锁再进入此路径。

3.1.3 案例 3:mmap_lock 优化之 SPF 优化 3
SPF 是 Speculative page-fault handling 的缩写,中文是投机性缺页。它的主要思路是先尝试不需要获取 mmap_sem(mmap_lock)进行 page fault 操作,能进行这个的前提是在整个 page fault 过程 vma 没有发生变化,一旦发生变化,这个操作就是白干的,需要重载获取 mmap_sem 进行正常操作。
SPF 改动最早出现在 2010 年左右,由 Peter Zijlstra 提交 handle page fault without holding the mm semaphore 的 patchset,但由于还存在一些问题,直到 2019 年 IBM 的 Laurent Dufour 修复了相关问题,重启了这项工作。但此 patchset 一直没能 merge 进内核主线。
据描述,优化效果如下:
在 Android 平台进行测试,应用程序启动时间平均提升 6%,一些大型应用程序(100 个线程以上)启动时间提高了 20%。
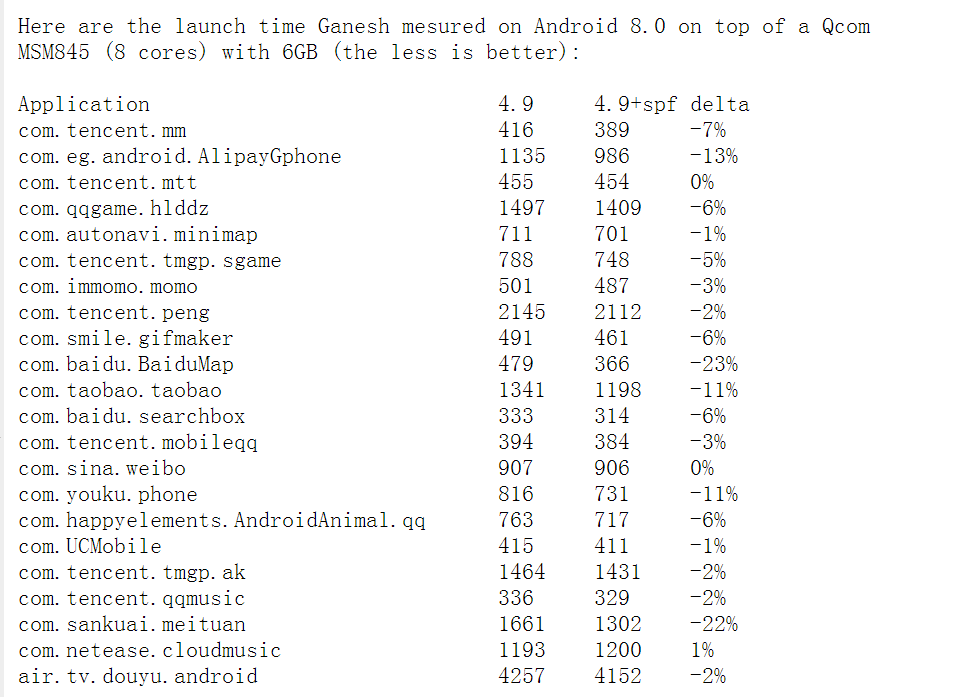
Dufour 提交 patset 如下:
关键修改点简介:
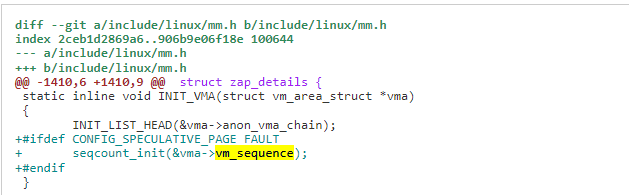
1)引入 vma vm_sequence 计数,当 vma 发生变化时,进行计数。在 VMA 修改的地方引入 seqlock, 在进入临界区前调用 vm_write_begin, 出临界区再调用 vm_write_end, 两者都会对 vma->vm_sequence 增加计数。因此如果发生发 VMA 修改,可以通过获取 vma->vm_sequence 来判断。

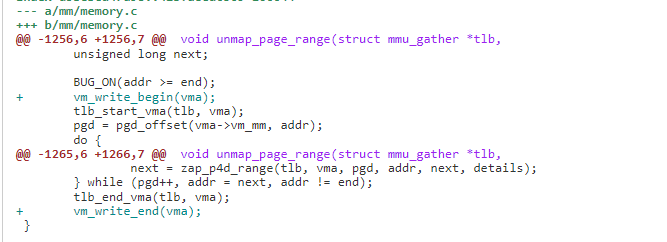
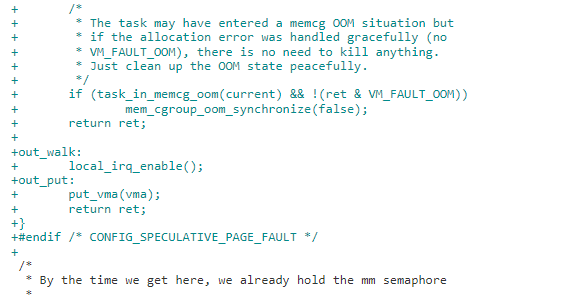
2)新增handle_speculative_fault 接口,page fault 时会先尝试handle_speculative_fault。Spf 处理如果 vma 的 vm_sequence 在整个处理过程没有发生计数,即 vma 没有被修改。可以不需要 mmap_sem 完成 page faut,如果发生变生,返回 VM_FAULT_RETRY 重来一次获取 mmap_sem 的操作。



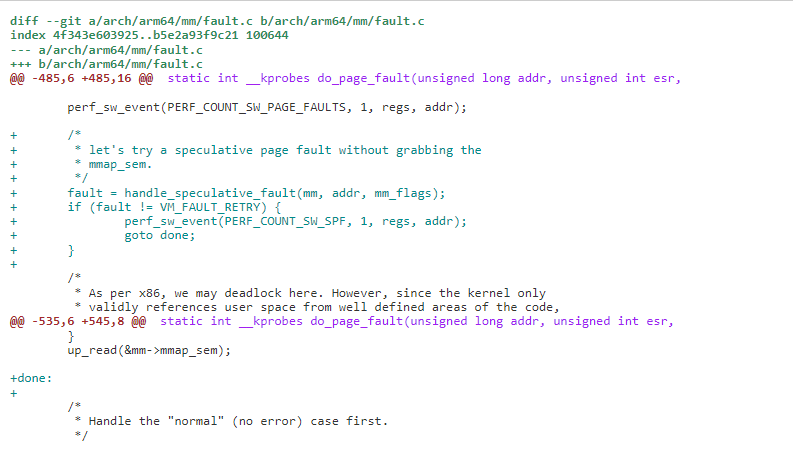
3)需要对应体系结构支持,如 arm64 在处理 page fault 前,先走 SPF 流程,如果成功直接完成 page faut, 如果不成功,就走原来的持 mmap_sem 流程。
3.1.4 案例 4:mmap_lock 优化之 PVL 优化 4
mmap_sem 锁最大的问题是一个进程级别的大锁,锁保护的范围太大,导致本应该可以并发进行的一些操作,无法进行并行。例如,线程 1 page fault 访问的 vma1,线程 2 mmap 操作的是 vma2,这两个 vma 不一样,本来完全可以进行并发,但由于都被 mmap_sem 锁保护导致无法并行。
Google 的 Suren Baghdasaryan 在 2023 年提交一组 patchset,引入了 per vma lock(PVL),通过 per vma lock 保护 vma 的修改,不同 vma 访问可以并发进行。在 linux6.4 进入主线。
通过 per vma lock, 一些 benchmark 测试显示,收益稍差于 SPF,可以达到 SPF 约 75%效果
Performance benchmarks show similar although slightly smaller benefits as
with SPF patchset (~75% of SPF benefits). Still, with lower complexity
this approach might be more desirable.另外在Android上一些多线程并发的APP(约100个线程)的启动时间最大可以优化20%

Patchset 提交如下:
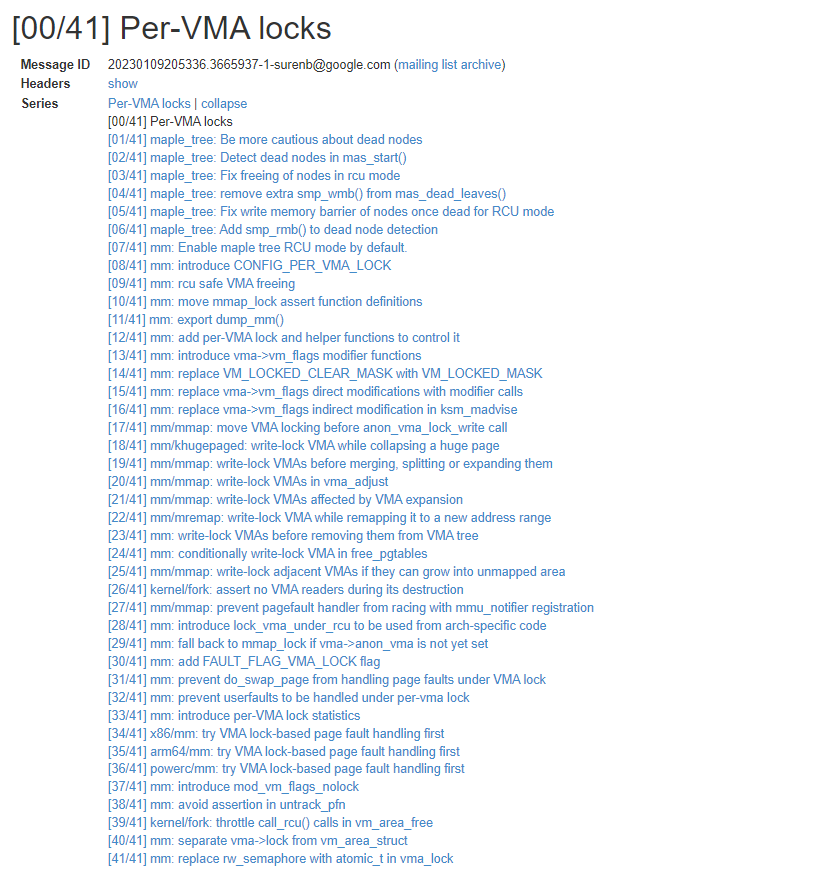
关键修改点简介如下:
1)每个描述 VMA(用 vm_area_struct 描述)里面实际增加了一个 vm_lock_seq 成员和 lock 锁。struct mm_struct 新增加 mm_lock_seq 成员。当对 VMA 进行写时,会增加 vm_lock_seq 计数,通过 vm_lock_seq 和 mm_lock_seq 的比对,可以判断是否有人正在持写锁写 VMA。
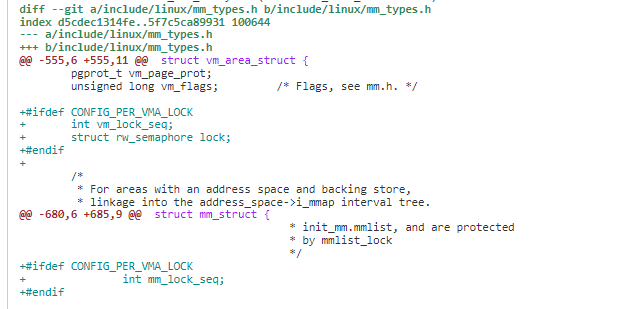
2)封装了 vma_write_lock 和 vma_read_try_lock 接口。
vma_write_lock 写锁获取由接口,它首先会取 vma->lock 锁,然后向 vma->vm_lock_seq 中写入 vma->vm_mm->mm_lock_seq。就马上释放 vma-> lock 锁了。

进程级 mm->mm_lock_seq 会在 vma_write_unlock_mm 的时候增加 1。
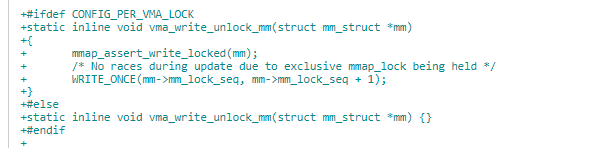
vma 读锁获取由接口 vma_read_trylock 完成,它判断 vma->vm_lock_seq 是否与 vma->vm_mm->mm_lock_seq 相等,如果相等,表示有人获取写锁。否则拿到 vma->lock,与写锁不同的是,在这个过程一直持有 vma->lock 锁,直到完成时通过 vma_read_unlock 释放。
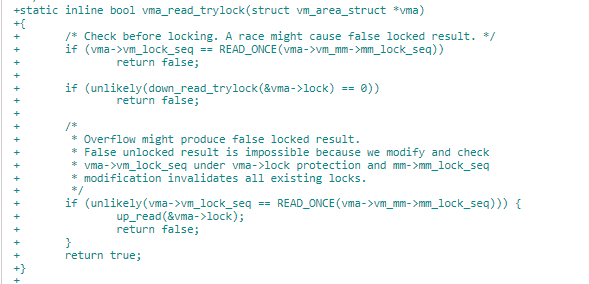

- mmap 写修改地方,由 vma_write_lock 标记。
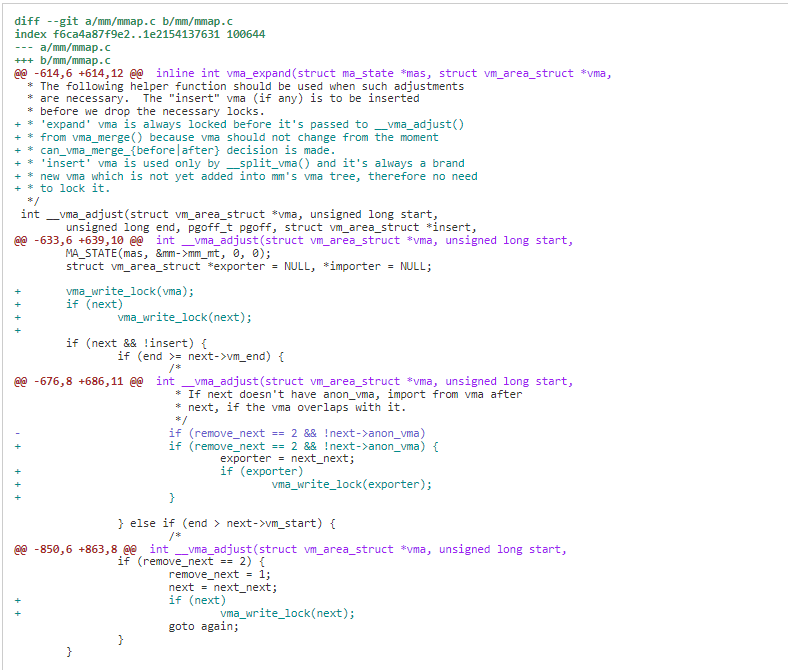
3)try VMA lock-based page fault handling first
lock_vma_under_rcu 调用尝试获取 vma 读锁。如果 vma seq 和 mm seq 相等,表明有人正在进行写操作,回退使用 mmap_lock。否则获取 vma 的读锁进行 page fault,完成后释放。
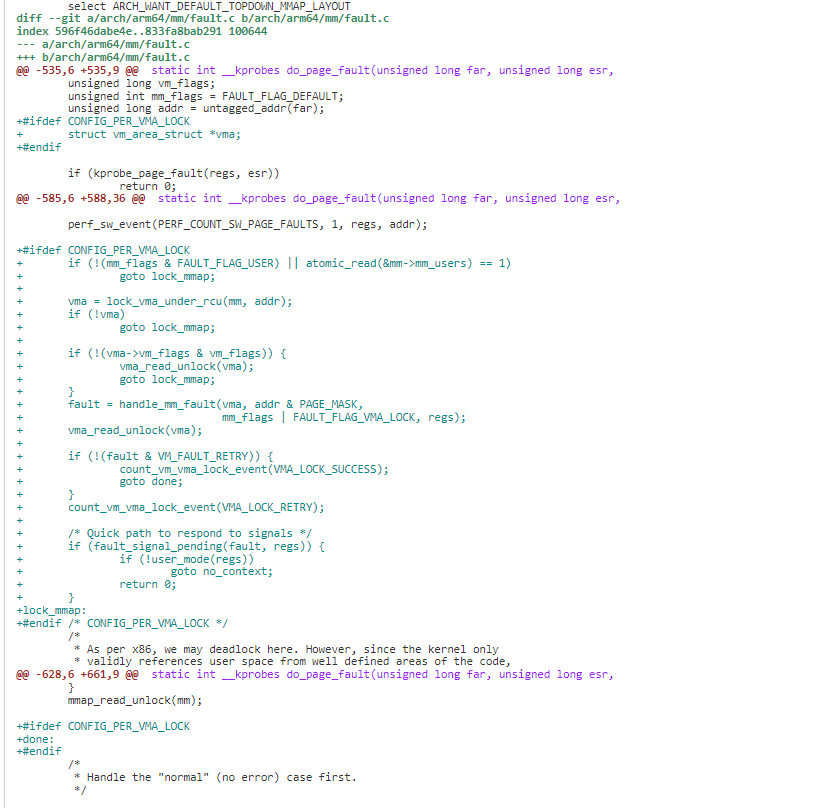
这个优化是典型的大锁化小锁的优化。总结一下,通过此优化后的场景锁的使用情况:
1)、当 thread1 处理 vma1 需要持w rite 锁时,需要持 mm->mmap_lock;此时当 thread2 处理 vma2 需要持 read 锁时,因为 mm->mm_lock_seq 与 vma2 里保存的 vma>vm_lock_seq 不同,所以 thread2 处理 vma2 不需要持 mm->mmap_lock,因此也不需要等待 thread1 去释放 mm->mmap_lock,从而 thread1 和 thread2 可以并行处理;同理:与此同时,thread3 处理 vma3、thread4 处理 vma4 需要持读锁的场景也不需要。
2)、当 thread1 处理 vma1 需要持 write 锁时,同时 thread2 处理 vma1 也需要持 read 锁时,两者就转换成去持 mm->mmap_lock 读写锁逻辑,必须等待 thread1 写完成或者 thread2 读完成,才能唤醒另外的 thread 执行。
第一点优化了更大程度增加了同一地址空间不同 vma 并行处理能力,在处理同一 vma 时转换成原来的处理方式,也没有不会带来任何额外性能损耗。
3.1.5 案例 5:mmap_lock 优化之 fault around 优化 5
mmap_lock 锁竞争最大的是发生在 page fault,如果可以减少 page fault,就可以从源头上减少对 mmap 的竞争。2016 年 Vinayak Menon 就在内核对 fault_around_bytes 提交了可配置的 patch.
通过把 fault_around_bytes 配置来优化性能,但也需要平衡内存压力。此参数默认此参数是 64K。Vinayak Menon 提供的一些测试结果可以参考如下:
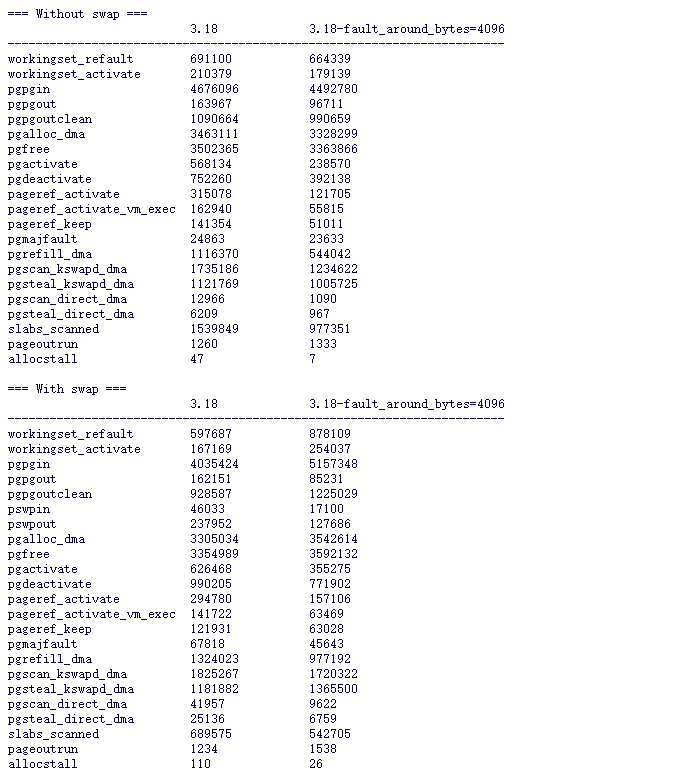
Patchset 参数提交列举如下:

它优化的思路是在文件页缺页时会把当次附近地址的一起建立映射(大小可按需求配置),它只会对本身存在 page cache 的提前建立映射,并不会产生 page cache。
3.1.6 案例 6:mmap_lock 优化之 unmap 优化 6
当上层在用户态调用 free 时,底层调用 munmap,但是 munmap 代价并不小,因为它需要持 mmap_sem 的 write 锁后解除所有的 PTE 映射并释放回内存伙伴系统。这个代价会随着 VMA 区域长短增大成线性增加关系。例如 unmap 320GB 需要约 18 秒。
阿里巴巴的 yang.shi 在 2018 年提交一组分段 unmmap 的 patchset。
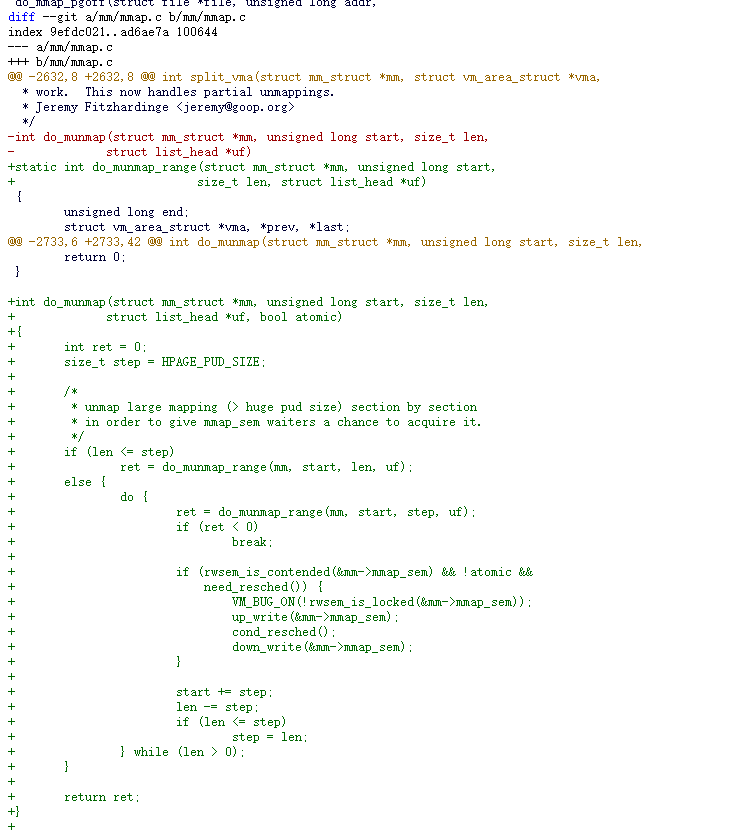
关键修改很简单,就是对大于 HPAGE_PUD_SIZE(1GB)的,每次 unmmap HPAGE_PUD_SIZE 大小,然后判断一下 mmap_sem 是否有 waiter,并且当前处于可睡眠上下文,主动释放 mmap_sem 并让出 CPU,然后下一次重新获得 CPU 运行时再次获取 mmap_sem 继续进行 unmap。收益如下:

此 pathset 未进入主线。
大部分人相比 munmap 更喜欢使用
madvise_dontneed 调用, 它不需要持 mmap_sem 的写锁,只需要持 mmap_sem 的读锁。因此进程中其它线程发生缺页时,仍然可以并发处理,相对而言性能优于 munmap。由于 madvise_dontneed 并不是立刻释放虚拟地址,它也有一些缺陷,可能会导致虚拟地址紧张(特别是对于 32 位应用)。
3.1.7 案例 7:rmap 路径的锁性能优化 7
在系统内存紧张的场景同时有进程在持续处理它们的 vma 工作如 fork, mmap,munmap 等行为时,rmap 反向映射路径上的锁如 i_mmap_rwsem 和 anon_vma->root->rwsem 会存在明显的竞争。它可能会使内存回收路径性能较差或者卡住。在一些观察中,可以看到 kswapd 等待这些锁的耗时在 300ms 以上, 最坏的情况下,可以达到 1s 以上,这使得其它一些进程进入 direct recalim, 当然,进入 direct reclaim 也会卡在这些锁上面。
2022 年 minchan 提交了一组 patchset 优化种情况的问题,优化补丁已在 5.19 合入主线。合入补丁后,可以看到在 rmap 路径上的平均耗时大幅下降。
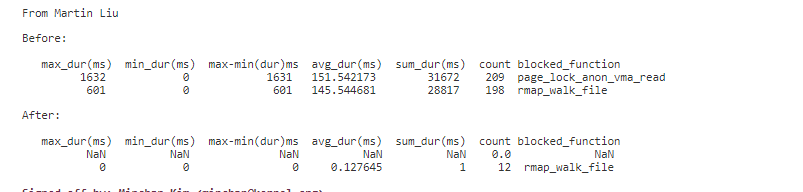
patchset 提交如下:
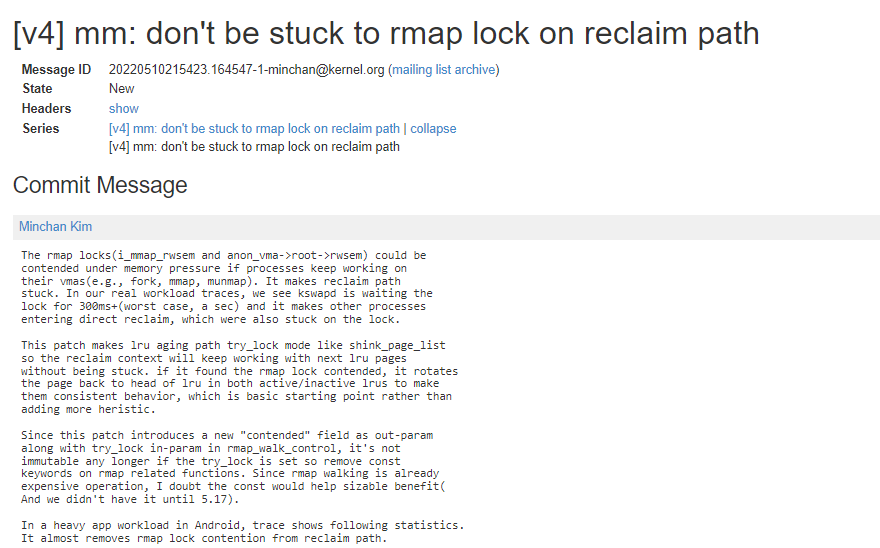
关键修改简介:
1)封装了 i_mmap_rwsem 和 anon_vma->root->rwsem 锁的 trylock_read 接口。


2)在 rmap 时先进行 trylock,在 trylock 成功时,按原来流程处理 。trylock 不成功时,表明锁存在竞争,设置 rwc->contended 为 true 然后返回。
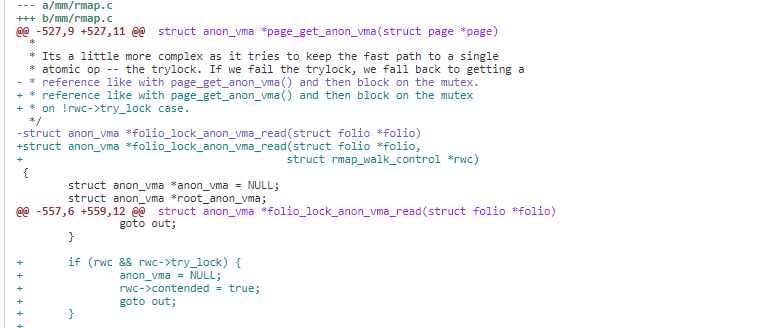
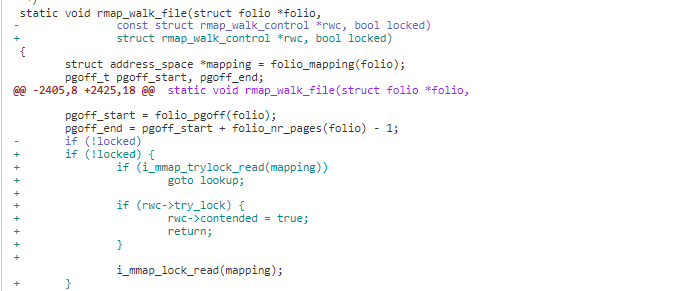
3)在 folio_check_references 如果 referenced_ptes 为-1 即 rmap 的锁存在竞争,trylock 不成功,跳过此 page 的处理。

3.1.8 案例 8:shrinker lockless 优化 8
shrinker_rw 是一把全局的读写锁,用于保护一些操作例如 shrink slab, shrinker registration 和 shrinker 的 unregistration 等。这些都容易存在性能问题。例如:
1)当系统内存压力大且同时系统文件系统存在 mount 和 unmount 时,shinrk slab 会受到影响(down_read_trylock 失败)
2)如果一个 shrinker 被 blocked 住(例如上面 1 描述的情况且一个写者来临,写者会被 blocked,然后所有 shriner 相关操作也会被 blocked)
例如,当一个 driver 进行 register 一个 shrinker 时,它需要写锁,如果 shirnk slab 在内回收时,由于 runnable 或 D 状态等长时间没释放此锁,那么 register 的进程需要长时间等待。同样,如果一个进程在 unreginer 一个 shrinker 时,由于 runnable 较长时间没有释放锁,shrink slab 由于获取不到锁,内存回收也明显的受到影响。
字节跳动的 zhengqi 在 2023 年 09 月提交了一组 patchset,借助 refcout 计数和 RCU 将全局 shinker 锁优化为无锁操作。patchset 在 linux6.7 合入主线。
patchset 提交如下:
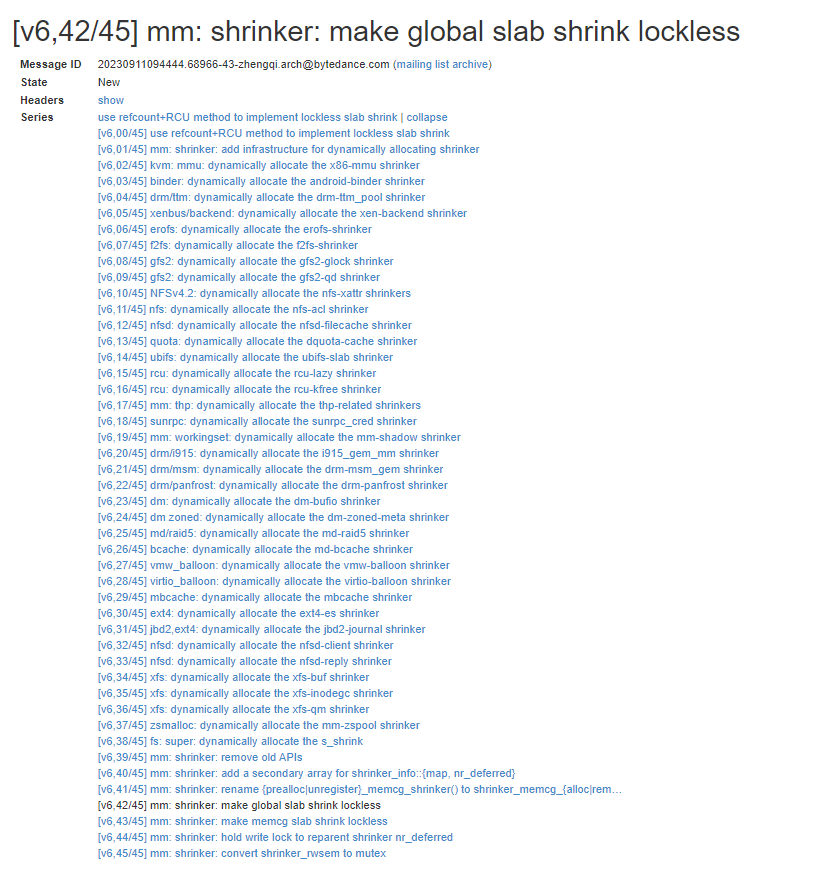
合入 patch 后,可以看到性能明显提升,收益数据如下:
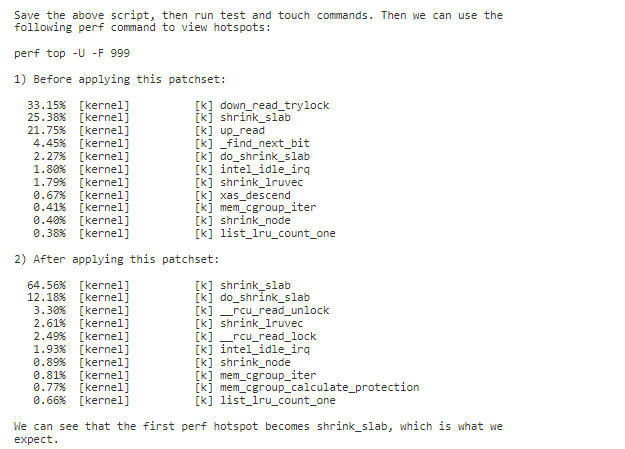
关键修改简介如下:
1)封装了 shrinker_alloc、shrinker_register、shrinker_free 接口。


2)改造原来直接调用 register_shrinker 的地方。

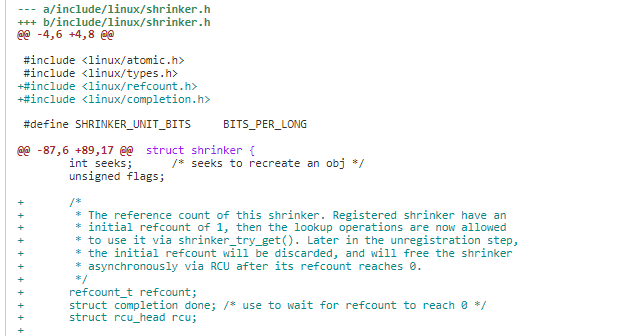
3)Shrinker 新增 refcount、struct completion done、struct rcu_head rcu 成员。
Refcount 会在 shrinker Registered 的时候拥有初始值 1,然后一些查找操作将被通过 shrinker_try_get 允许使用它。然后在 unregistration 的时候 Refcount 会进行计数的减少,当其为 0 时,会通过异步的 RCU 来释放 shrinker。
在原来获取 shrinker 读写锁的地方,现在先通过获取 shrinker_try_get 增加 shrinker->refcount 引用计数,完成 shrinker 操作后通过 shrinker_put 减少 shrinker->refcount 引用计数。
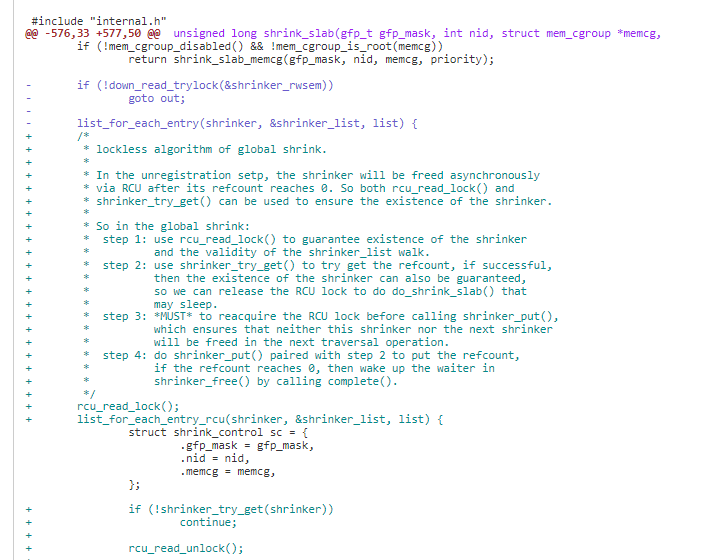

当 shrinker->refcount 引用计数减少时,如果到达到 0,即没有进程在使用,就设置 shrinker->done complete 操作。

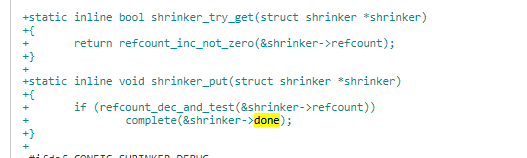
shrinker->done 条件满足,即没有进程在使用 shrinker 了,通过 rcu cb 进行删除释放。

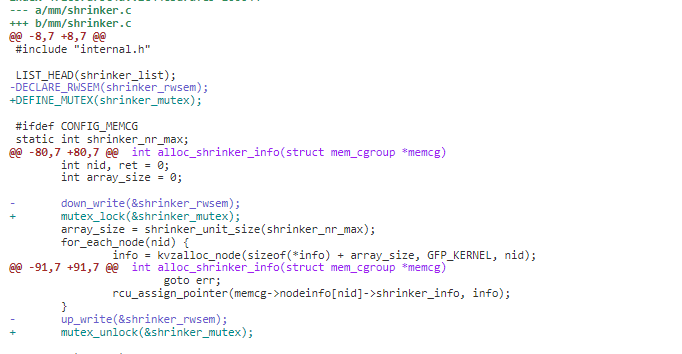
4)在确认没有 reader, shrinker_rwsem 替换为 mutex 锁
4. 优化演进方向总结
通过上面案例,可以看到在内存锁(操作系统锁的方向也一样)在优化的演进和方向上主要是以下优化方向:
1)lock less 无锁操作。要想优化锁的性能问题,最根本的改善办法就是无锁操作。可以参考上面案例中的 shrinker lockless 案例和 SPF 案例。
2)缩小临界区,尽早释放锁。如果锁无法避免,需要避免长时间持锁的临界区,可以考虑先释放锁,完成耗时操作后,再次获取锁完成此过程。可以参考 IO fault path 路径锁优化和 munmap 优化的案例。
3)大锁化小锁。把大锁拆成小锁,减少锁竞争的粒度。可以参考 PVL 优化案例和 per memcg lru lock 优化案例。
4)降低锁等待的影响。在锁竞争激烈时,尽量不让等待锁影响关键路径的性能。可以参考上面 rmap 路径的锁性能优化的案例。
5)减少持锁次数。通过一些提前操作的方式或一次性多操作的方式,或从业务源头减少相关持锁操作方式,降低持锁次数。可以参考上面 fault around 案例。
5. 参考资料
1.https://patchwork.kernel.org/...
2.https://patchwork.kernel.org/...
3.https://patchwork.kernel.org/...
4.https://patchwork.kernel.org/...
5.https://lore.kernel.org/all/2...
6.https://lore.kernel.org/lkml/...
7.https://patchwork.kernel.org/...
8.https://patchwork.kernel.org/...
9.https://elixir.bootlin.com/li...
END
作者:watson
来源:OPPO内核工匠
推荐阅读
欢迎大家点赞留言,更多 Arm 技术文章动态请关注极术社区嵌入式客栈专栏欢迎添加极术小姐姐微信(id:aijishu20)加入技术交流群,请备注研究方向。

