

1. 需求
如果要你实现一个前端路由,应该如何实现浏览器的前进与后退 ?
博客首更地址 :github
2. 问题
首先浏览器中主要有这几个限制,让前端不能随意的操作浏览器的浏览纪录:
- 没有提供监听前进后退的事件。
- 不允许开发者读取浏览纪录,也就是 js 读取不了浏览纪录。
- 用户可以手动输入地址,或使用浏览器提供的前进后退来改变 url。
所以要实现一个自定义路由,解决方案是自己维护一份路由历史的记录,从而区分 前进、刷新、回退。
下面介绍具体的方法。
3. 方法
目前笔者知道的方法有两种,一种是 在数组后面进行增加与删除,另外一种是 利用栈的后进先出原理。
3.1 在数组最后进行 增加与删除
通过监听路由的变化事件 hashchange,与路由的第一次加载事件 load ,判断如下情况:
- url 存在于浏览记录中即为后退,后退时,把当前路由后面的浏览记录删除。
- url 不存在于浏览记录中即为前进,前进时,往数组里面 push 当前的路由。
- url 在浏览记录的末端即为刷新,刷新时,不对路由数组做任何操作。
另外,应用的路由路径中可能允许相同的路由出现多次(例如 A -> B -> A),所以给每个路由添加一个 key 值来区分相同路由的不同实例。
注意:这个浏览记录需要存储在 sessionStorage 中,这样用户刷新后浏览记录也可以恢复。
笔者之前实现的 用原生 js 实现的轻量级路由 ,就是用这种方法实现的,具体代码如下:
// 路由构造函数
function Router() {
this.routes = {}; //保存注册的所有路由
this.routerViewId = "#routerView"; // 路由挂载点
this.stackPages = true; // 多级页面缓存
this.history = []; // 路由历史
}
Router.prototype = {
init: function(config) {
var self = this;
//页面首次加载 匹配路由
window.addEventListener('load', function(event) {
// console.log('load', event);
self.historyChange(event)
}, false)
//路由切换
window.addEventListener('hashchange', function(event) {
// console.log('hashchange', event);
self.historyChange(event)
}, false)
},
// 路由历史纪录变化
historyChange: function(event) {
var currentHash = util.getParamsUrl();
var nameStr = "router-history"
this.history = window.sessionStorage[nameStr] ? JSON.parse(window.sessionStorage[nameStr]) : []
var back = false, // 后退
refresh = false, // 刷新
forward = false, // 前进
index = 0,
len = this.history.length;
// 比较当前路由的状态,得出是后退、前进、刷新的状态。
for (var i = 0; i < len; i++) {
var h = this.history[i];
if (h.hash === currentHash.path && h.key === currentHash.query.key) {
index = i
if (i === len - 1) {
refresh = true
} else {
back = true
}
break;
} else {
forward = true
}
}
if (back) {
// 后退,把历史纪录的最后一项删除
this.historyFlag = 'back'
this.history.length = index + 1
} else if (refresh) {
// 刷新,不做其他操作
this.historyFlag = 'refresh'
} else {
// 前进,添加一条历史纪录
this.historyFlag = 'forward'
var item = {
key: currentHash.query.key,
hash: currentHash.path,
query: currentHash.query
}
this.history.push(item)
}
// 如果不需要页面缓存功能,每次都是刷新操作
if (!this.stackPages) {
this.historyFlag = 'forward'
}
window.sessionStorage[nameStr] = JSON.stringify(this.history)
},
}以上代码只列出本次文章相关的内容,完整的内容请看 原生 js 实现的轻量级路由,且页面跳转间有缓存功能。
3.2 利用栈的 后进者先出,先进者后出 原理
在说第二个方法之前,先来弄明白栈的定义与后进者先出,先进者后出原理。
3.2.1 定义
栈的特点:后进者先出,先进者后出。
举一个生活中的例子说明:就是一摞叠在一起的盘子。我们平时放盘子的时候,都是从下往上一个一个放;取的时候,我们也是从上往下一个一个地依次取,不能从中间任意抽出。
因为栈的后进者先出,先进者后出的特点,所以只能栈一端进行插入和删除操作。这也和第一个方法的原理有异曲同工之妙。
下面用 JavaScript 来实现一个顺序栈:
// 基于数组实现的顺序栈
class ArrayStack {
constructor(n) {
this.items = []; // 数组
this.count = 0; // 栈中元素个数
this.n = n; // 栈的大小
}
// 入栈操作
push(item) {
// 数组空间不够了,直接返回 false,入栈失败。
if (this.count === this.n) return false;
// 将 item 放到下标为 count 的位置,并且 count 加一
this.items[this.count] = item;
++this.count;
return true;
}
// 出栈操作
pop() {
// 栈为空,则直接返回 null
if (this.count == 0) return null;
// 返回下标为 count-1 的数组元素,并且栈中元素个数 count 减一
let tmp = items[this.count-1];
--this.count;
return tmp;
}
}其实 JavaScript 中,数组是自动扩容的,并不需要指定数组的大小,也就是栈的大小 n 可以不指定的。
3.2.2 应用
栈的经典应用: 函数调用栈
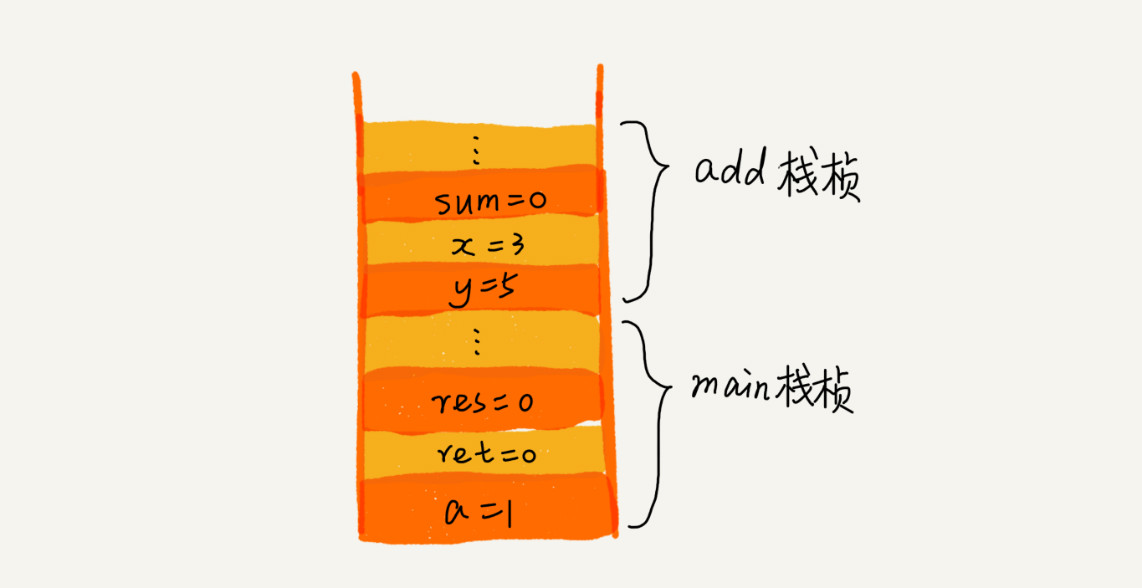
操作系统给每个线程分配了一块独立的内存空间,这块内存被组织成“栈”这种结构, 用来存储函数调用时的临时变量。每进入一个函数,就会将临时变量作为一个栈帧入栈,当被调用函数执行完成,返回之后,将这个函数对应的栈帧出栈。为了让你更好地理解,我们一块来看下这段代码的执行过程。
function add(x, y) {
let sum = 0;
sum = x + y;
return sum;
}
function main() {
let a = 1;
let ret = 0;
let res = 0;
ret = add(3, 5);
res = a + ret;
console.log("res: ", res);
reuturn 0;
}
main();上面代码也很简单,就是执行 main 函数求和,main 函数里面又调用了 add 函数,先调用的先进入栈。
执行过程如下:
3.2.3 实现浏览器的前进、后退
第二个方法就是:用两个栈实现浏览器的前进、后退功能。
我们使用两个栈,X 和 Y,我们把首次浏览的页面依次压入栈 X,当点击后退按钮时,再依次从栈 X 中出栈,并将出栈的数据依次放入栈 Y。当我们点击前进按钮时,我们依次从栈 Y 中取出数据,放入栈 X 中。当栈 X 中没有数据时,那就说明没有页面可以继续后退浏览了。当栈 Y 中没有数据,那就说明没有页面可以点击前进按钮浏览了。
比如你顺序查看了 a,b,c 三个页面,我们就依次把 a,b,c 压入栈,这个时候,两个栈的数据如下:

当你通过浏览器的后退按钮,从页面 c 后退到页面 a 之后,我们就依次把 c 和 b 从栈 X 中弹出,并且依次放入到栈 Y。这个时候,两个栈的数据就是这个样子:
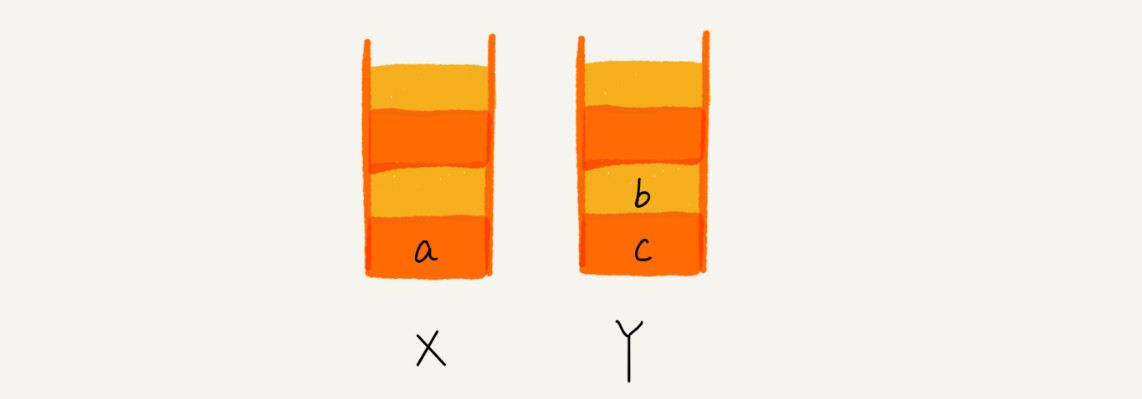
这个时候你又想看页面 b,于是你又点击前进按钮回到 b 页面,我们就把 b 再从栈 Y 中出栈,放入栈 X 中。此时两个栈的数据是这个样子:
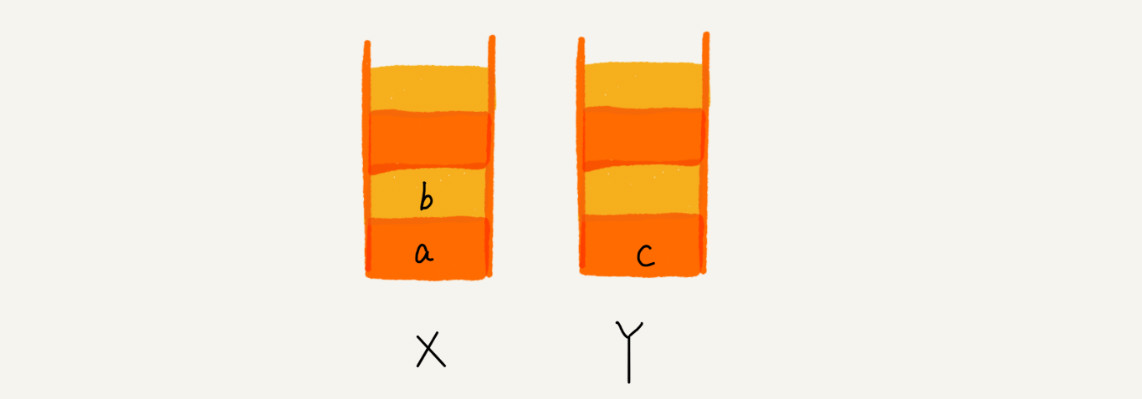
这个时候,你通过页面 b 又跳转到新的页面 d 了,页面 c 就无法再通过前进、后退按钮重复查看了,所以需要清空栈 Y。此时两个栈的数据这个样子:
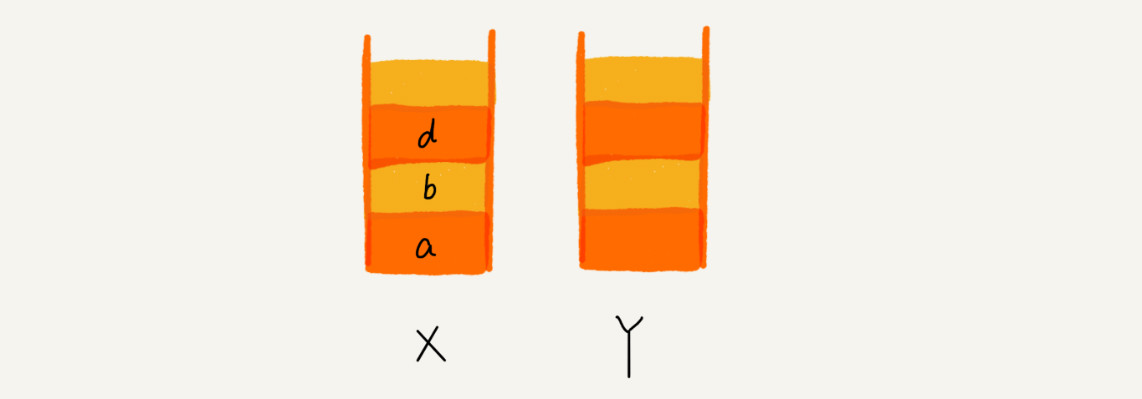
如果用代码来实现,会是怎样的呢 ?各位可以想一下。
其实就是在第一个方法的代码里面, 添加多一份路由历史纪录的数组即可,对这两份历史纪录的操作如上面示例图所示即可,也就是对数组的增加和删除操作而已, 这里就不展开了。
其中第二个方法与参考了 王争老师的 数据结构与算法之美。
4. 最后
博客首更地址 :github
参考文章:数据结构与算法之美

