
HDP版本:2.6.4.0Kylin版本:2.5.1
机器:三台 CentOS-7,8G 内存
Kylin 的计算引擎除了 MapReduce ,还有速度更快的 Spark ,本文就以 Kylin 自带的示例 kylin_sales_cube 来测试一下 Spark 构建 Cube 的速度。
一、配置Kylin的相关Spark参数
在运行 Spark cubing 前,建议查看一下这些配置并根据集群的情况进行自定义。下面是建议配置,开启了 Spark 动态资源分配:
<!--more-->
## Spark conf (default is in spark/conf/spark-defaults.conf)
kylin.engine.spark-conf.spark.master=yarn
kylin.engine.spark-conf.spark.submit.deployMode=cluster
kylin.engine.spark-conf.spark.yarn.queue=default
kylin.engine.spark-conf.spark.driver.memory=2G
kylin.engine.spark-conf.spark.executor.memory=4G
kylin.engine.spark-conf.spark.executor.instances=40
kylin.engine.spark-conf.spark.yarn.executor.memoryOverhead=1024
kylin.engine.spark-conf.spark.shuffle.service.enabled=true
kylin.engine.spark-conf.spark.eventLog.enabled=true
kylin.engine.spark-conf.spark.eventLog.dir=hdfs\:///kylin/spark-history
kylin.engine.spark-conf.spark.history.fs.logDirectory=hdfs\:///kylin/spark-history
#kylin.engine.spark-conf.spark.hadoop.yarn.timeline-service.enabled=false
#
#### Spark conf for specific job
#kylin.engine.spark-conf-mergedict.spark.executor.memory=6G
#kylin.engine.spark-conf-mergedict.spark.memory.fraction=0.2
#
## manually upload spark-assembly jar to HDFS and then set this property will avoid repeatedly uploading jar
## at runtime
kylin.engine.spark-conf.spark.yarn.archive=hdfs://node71.data:8020/kylin/spark/spark-libs.jar
kylin.engine.spark-conf.spark.io.compression.codec=org.apache.spark.io.SnappyCompressionCodec
#
## 如果是HDP版本,请取消下述三行配置的注释
kylin.engine.spark-conf.spark.driver.extraJavaOptions=-Dhdp.version=current
kylin.engine.spark-conf.spark.yarn.am.extraJavaOptions=-Dhdp.version=current
kylin.engine.spark-conf.spark.executor.extraJavaOptions=-Dhdp.version=current其中 kylin.engine.spark-conf.spark.yarn.archive 配置是指定了 Kylin 引擎要运行的 jar 包,该 jar 包需要自己生成且上传到 HDFS 。由于我执行 Kylin 服务的用户是 kylin,所以要先切换到 kylin 用户下去执行。命令如下:
su - kylin
cd /usr/hdp/2.6.4.0-91/kylin
# 生成spark-libs.jar文件
jar cv0f spark-libs.jar -C $KYLIN_HOME/spark/jars/ ./
# 上传到HDFS上的指定目录
hadoop fs -mkdir -p /kylin/spark/
hadoop fs -put spark-libs.jar /kylin/spark/二、修改Cube的配置
配置好 Kylin 的相关 Spark 参数后,接下来我们需要将 Cube 的计算引擎修改为 Spark ,修改步骤如下:
先指定 Kylin 自带的生成 Cube 脚本:sh ${KYLIN_HOME}/bin/sample.sh ,会在 Kylin Web 页面上加载出两个 Cube 。
接着访问我们的 Kylin Web UI ,然后点击 Model -> Action -> Edit 按钮:
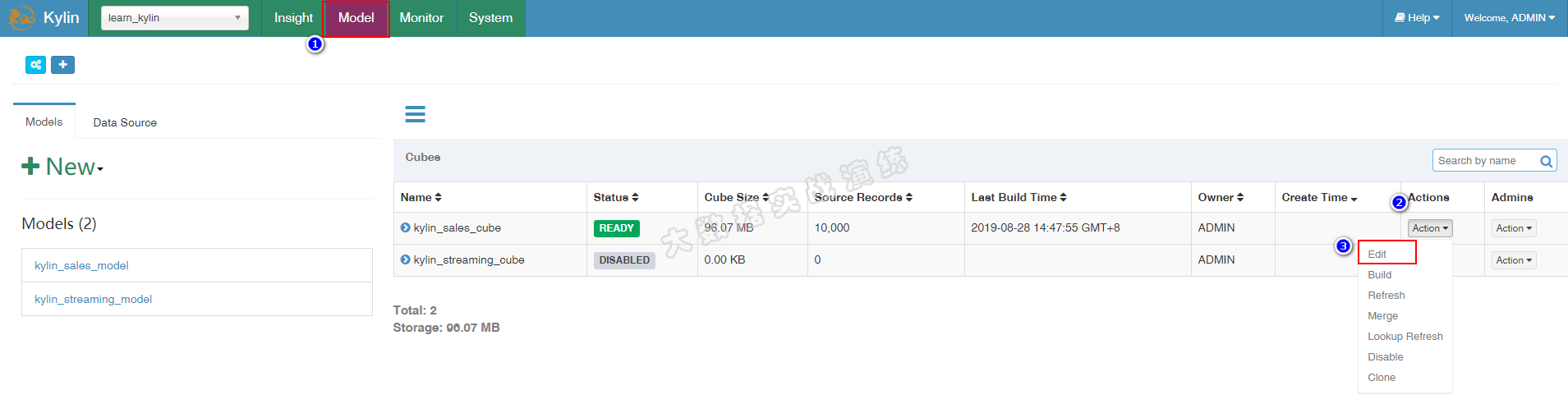
点击第五步:Advanced Setting,往下划动页面,更改 Cube Engine 类型,将 MapReduce 更改为 Spark。然后保存配置修改。如下图所示:


点击 “Next” 进入 “Configuration Overwrites” 页面,点击 “+Property” 添加属性 “kylin.engine.spark.rdd-partition-cut-mb” 其值为 “500” (理由如下):
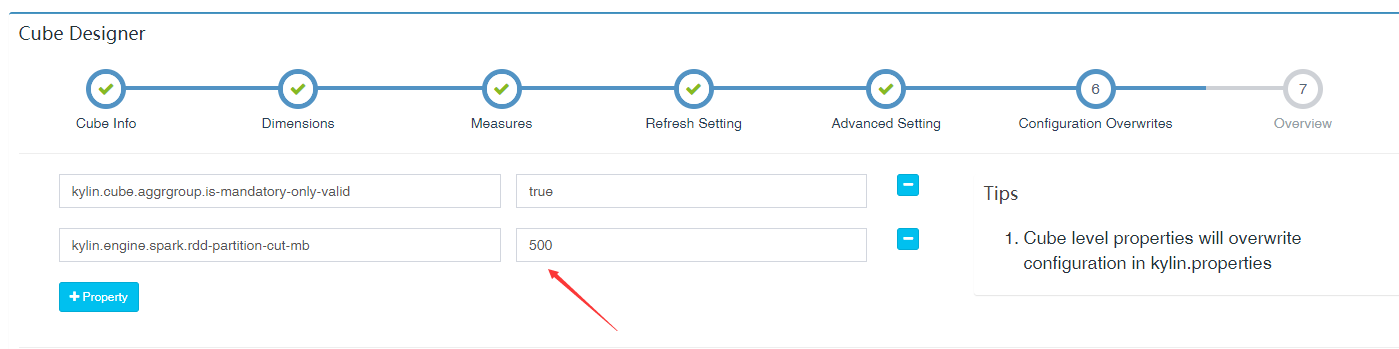
样例 cube 有两个耗尽内存的度量: “COUNT DISTINCT” 和 “TOPN(100)”;当源数据较小时,他们的大小估计的不太准确: 预估的大小会比真实的大很多,导致了更多的 RDD partitions 被切分,使得 build 的速度降低。500 对于其是一个较为合理的数字。点击 “Next” 和 “Save” 保存 cube。
对于没有”COUNT DISTINCT” 和 “TOPN” 的 cube,请保留默认配置。
三、构建Cube
保存好修改后的 cube 配置后,点击 Action -> Build,选择构建的起始时间(一定要确保起始时间内有数据,否则构建 cube 无意义),然后开始构建 cube 。
在构建 cube 的过程中,可以打开 Yarn ResourceManager UI 来查看任务状态。当 cube 构建到 第七步 时,可以打开 Spark 的 UI 网页,它会显示每一个 stage 的进度以及详细的信息。
Kylin 是使用的自己内部的 Spark ,所以我们还需要额外地启动 Spark History Server 。
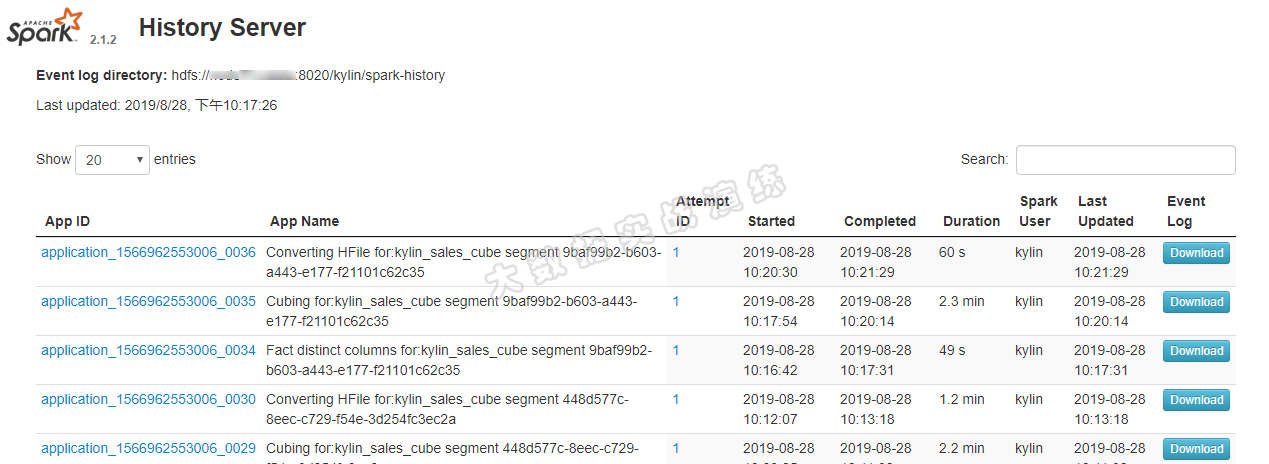
${KYLIN_HOME}/spark/sbin/start-history-server.sh hdfs://<namenode_host>:8020/kylin/spark-history访问:http://ip:18080/ ,可以看到 Spark 构建 Cube 的 job 详细信息,该信息对疑难解答和性能调整有极大的帮助。
四、FAQ
在使用 Spark 构建 Cube 的过程中,遇到了两个错误,都解决了,特此记录一下,让大家明白,公众号内都是满满的干货。
1、Spark on Yarn 配置调整
报错内容:
Exception in thread "main" java.lang.IllegalArgumentException: Required executor memory (4096+1024 MB) is above the max threshold (4096 MB) of this cluster! Please check the values of 'yarn.scheduler.maximum-allocation-mb' and/or 'yarn.nodemanager.resource.memory-mb'.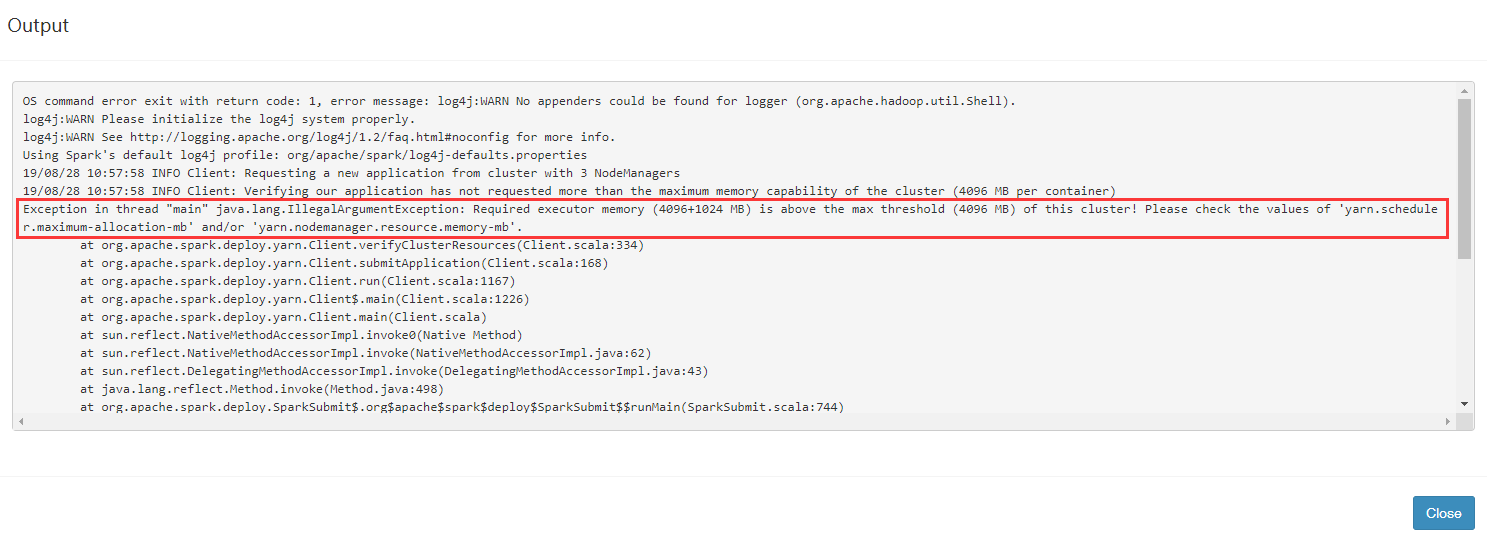
问题分析:
根据报错日志分析,任务所需的执行内存(4096 + 1024MB)高于了此集群最大的阈值。可以调整Spark任务的执行内存或者是Yarn的相关配置。
Spark任务所需的执行内存(4096 + 1024MB)对应的配置分别是:
- kylin.engine.spark-conf.spark.executor.memory=4G
- kylin.engine.spark-conf.spark.yarn.executor.memoryOverhead=1024
Yarn相关配置:
- yarn.nodemanager.resource.memory-mb:NodeManager是YARN中单个节点的代理,它需要与应用程序的ApplicationMaster和集群管理者ResourceManager交互。该属性代表该节点Yarn可使用的物理内存总量。
- yarn.scheduler.maximum-allocation-mb:代表单个任务可申请的最大物理内存量。该配置值不能大于yarn.nodemanager.resource.memory-mb配置值大小。
解决办法:
以调整 Yarn 配置为例,调整 yarn.scheduler.maximum-allocation-mb 大小,由于依赖于 yarn.nodemanager.resource.memory-mb ,所以两个配置都调整为比执行内存(4096+1024 MB)大的数值,比如:5888 MB 。
2、构建 Cube 第八步:Convert Cuboid Data to HFile 报错
报错内容:
java.lang.NoClassDefFoundError: Could not initialize class org.apache.hadoop.hbase.io.hfile.HFile
问题分析:
kylin.engine.spark-conf.spark.yarn.archive 参数值指定的 spark-libs.jar 文件缺少 HBase 相关的类文件。
解决办法:
由于缺失 HBase 相关的类文件比较多,参照 Kylin 官网给出的解决方式依旧报找不到类文件,所以我将 HBase 相关的 jar 包都添加到了 spark-libs.jar 里面。如果你已经生成了 spark-libs.jar 并上传到了 HDFS,那么你需要重新打包上传。具体操作步骤如下:
su - kylin
cd /usr/hdp/2.6.4.0-91/kylin
cp -r /usr/hdp/2.6.4.0-91/hbase/lib/hbase* /usr/hdp/2.6.4.0-91/kylin/spark/jars/
rm -rf spark-libs.jar;jar cv0f spark-libs.jar -C spark/jars/ ./
hadoop fs -rm -r /kylin/spark/spark-libs.jar
hadoop fs -put spark-libs.jar /kylin/spark/然后切换到 Kylin Web 页面,继续构建 Cube 。
五、Spark与MapReduce的对比
使用 Spark 构建 Cube 共耗时约 7 分钟,如下图所示:

使用 MapReduce 构建 Cube 共耗时约 15 分钟,如下图所示:
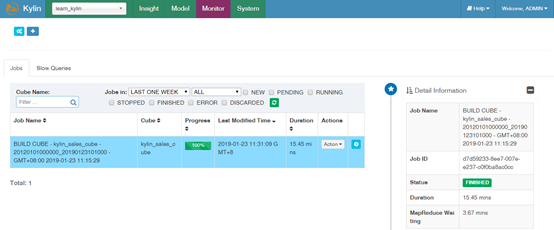
还是使用 Spark 构建 cube 快,还快不少!
六、总结
本篇文章主要介绍了:
- 如何配置 Kylin 的相关 Spark 参数
- 如何更改 Cube 的计算引擎
- 生成 spark-libs.jar 包并上传到 HDFS
- Spark 构建 Cube 过程中的 FAQ
- Spark 与 MapReduce 构建 Cube 的速度对比
本文参考链接:
推荐阅读:


