
文件操作
对文件操作流程
- 打开文件,得到文件句柄并赋值给一个变量;
- 通过句柄对文件进行操作;
- 关闭文件;
with:自动关闭文件;
with open('log', 'r') as f:
...- 文件操作之
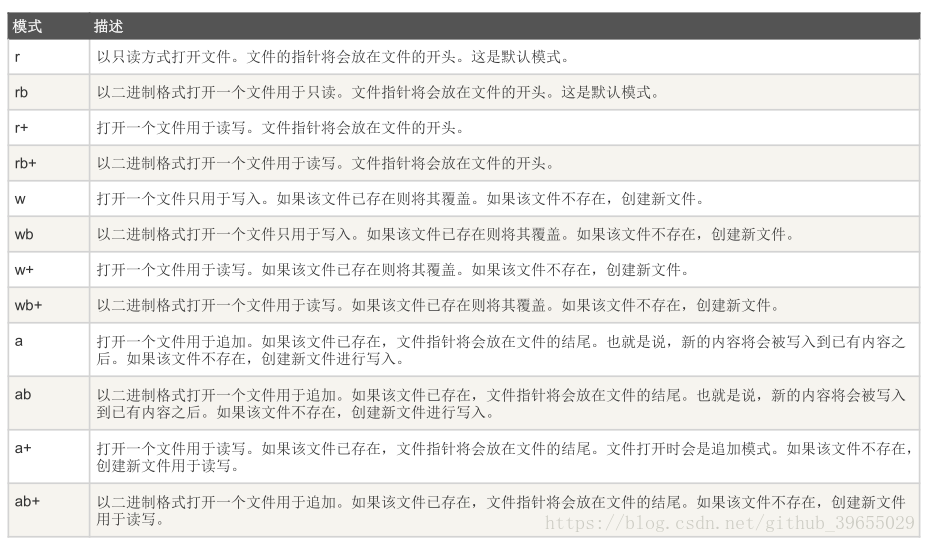
open()
模式匹配与正则表达式
- 正则表达式:简称regex,是文本模式的描述方法;
正则表达式匹配步骤:
- 导入正则表达式模块```re```; - 用```re.compile()```函数创建一个```Regex```对象(记得使用原始字符串); - 向```Regex```对象的```search()```方法传入想要查找的字符串,返回一个```Match```对象; - 调用```Match```对象的```group()```方法,返回实际匹配文本的字符串;- 管道:
|,用于匹配多个表达式中的一个,匹配多个分组; - 问号:
?,实现可选匹配;
>>> import re
>>> batRegex = re.compile(r'Bat(wo)?man')
>>> mo1 = batRegex.search('The Adventures of Batman.')
>>> print(mo1.group())
Batman
>>> mo2 = batRegex.search('The Adventures of Batwoman.')
>>> print(mo2.group())
Batwoman- 星号:
*,匹配零次或多次,即星号之前的分组,可以在文本中出现任意次;
>>> import re
>>> batRegex = re.compile(r'Bat(wo)*man')
>>> mo1 = batRegex.search('The Adventures of Batwowoman')
>>> print(mo1.group())
Batwowoman- 加号:
+,匹配一次或多次,加号前面的分组必须"至少出现一次”;
>>> import re
>>> batRegex = re.compile(r'Bat(wo)+man')
>>> mo1 = batRegex.search('The Adventures of Batwowoman')
>>> print(mo1.group())
Batwowoman
>>> mo2 = batRegex.search('The Adventures of Batman')
>>> print(mo2 == None)
True- 花括号:
{ },匹配特定次数;
>>> import re
>>> batRegex = re.compile(r'ha{3}')
>>> mo1 = batRegex.search('hahaha')
>>> print(mo1.group())
hahaha
>>> mo2 = batRegex.search('haha')
>>> print(mo2 == None)
Truefindall()方法返回结果:- 若调用在一个没有分组的正则表达式上,则返回一个匹配字符串的列表,如```['123-324-5832', '324-589-0983']```; - 若调用在一个有分组的正则表达式上,则返回一个字符串的元组的列表(每个分组对应一个字符串),如```[('123', '453', '4324'), ('343', '654', '3245)]```;^xxx:表示字符串必须以xxx开始;xxx$:表示字符串必须以xxx结尾;- 绝对路径:从根文件夹开始;
- 相对路径:相对于程序的当前工作目录;
读写文件的步骤:
- 调用```open()```函数,返回一个```File```对象; - 调用```File```对象的```read()```或```write()```方法; - 调用```File```对象的```close()```方法,关闭该文件;永久删除文件和文件夹:
- ```os.unlink(path)```删除```path```处的文件; - ```os.rmdir(path)```将删除```path```处的文件夹,但文件夹必须为空; - ```shutil.rmtree(path)```删除```path```处的文件夹,包含的所有文件和文件夹都会被删除;
调试
- 反向跟踪:Python遇到错误,就会产生错误信息,这些信息包含了出错信息、导致该错误的代码行号,以及导致该错误的函数调用的序列(调用栈);
欢迎关注微信公众号:村雨1943;创作不易,未经同意,转载请注明出处~

