
为什么要有分布式锁
随着架构系统的演进,由纯真的单机架构到容器化编排的分布式架构,可以说是一个大型互联网企业发展的必然走向。在网站初创时,应用数量和用户较少,可以把 Tomcat 和Mysql 部署在同一台机器上。随着用户数量增多,访问量增大,并发升高,Tomcat 和 MySQL 竞争资源,此时,单机已经扛不住了,需要把 Tomcat 和 MySQL 分离在不同的机器上,用于提升单台机器的处理能力。业务从来没有减少,产品越做越大。应用也越来越复杂,原来的大应用,拆分成多个小应用,加入各级缓存,做了反向代理负责均衡,最后坠入分库分表的深渊。
微服务渐渐代替了庞大冗杂的服务,每个小服务,各司其职。这时候是不是就不存在资源竞争的问题了呢?答案毋庸置疑,在架构的演进过程中,无时无刻都存在着资源竞争的问题。
说起资源竞争的问题,是不是想起了在计算机科学中的一个经典问题——哲学家就餐,也就是在并行计算中多线程同步( Synchronization )时产生的问题?哲学家就餐问题用来解释死锁和资源耗尽的问题,我们不做详细的讨论,感兴趣的同学可以搜索资料了解。既然存在资源竞争的问题,解决的方案必然是对资源加锁,对于锁大家肯定不陌生,在 Java 中synchronized 关键字和 ReentrantLock 可重入锁在我们的代码或者一些开源代码中随处可见的,一般用于在本地多线程环境中控制对资源的并发访问。但是随着微服务架构的蓬勃兴起,分布式的快速发展,本地加锁已经不能满足我们的业务需求,如果还通过本地加锁的方式锁定资源,在分布式环境中是无用的。于是人们为了在分布式环境中也能实现本地锁的效果,也是纷纷各出其招。
Martin Kleppmann 是英国剑桥大学的分布式系统的研究员,之前和 Redis 之父 Antirez 进行过关于 RedLock(红锁,后续有讲到)是否安全的激烈讨论。Martin 认为一般我们使用分布式锁有两个场景:
- 效率:使用分布式锁可以避免不同节点重复相同的工作,这些工作会浪费资源。比如用户付了钱之后有可能不同节点会发出多封短信。
- 正确性:加分布式锁同样可以避免破坏正确性的发生,如果两个节点在同一条数据上面操作,比如多个节点机器对同一个订单操作不同的流程有可能会导致该笔订单最后状态出现错误,造成损失。
分布式锁的特点
在了解分布式锁之前,我们首先要了解操作系统级别的锁(特指 Linux 系统)和 Java 编发编程时遇到的锁。对 Linux 锁和 Java锁有大概的了解后,我们深入分析分布式锁的实现机制。如果还想深入了解 Linux 的锁相关的信息,可查阅参考文章。
linux 锁的特点
在现代操作系统里,同一时间可能有多个内核执行命令在执行,因此内核其实像多进程多线程编程一样也需要一些同步机制来同步各执行单元对共享数据的访问。尤其是在多核CPU 系统上,更需要一些同步机制来同步不同处理器上的执行单元对共享的数据的访问。在主流的 Linux 内核中包含了几乎所有现代的操作系统具有的同步机制,这些同步机制包括:
- Atomic(原子操作): 所谓原子操作,就是该操作绝不会在执行完毕前被任何其他任务或事件打断,也就说,它的最小的执行单位,不可能有比它更小的执行单位。
- Mutex(互斥量): 互斥锁主要用于实现内核中的互斥访问功能。内核互斥锁是在原子 API 之上实现的,但这对于内核用户是不可见的。对它的访问必须遵循一些规则:同一时间只能有一个任务持有互斥锁,而且只有这个任务可以对互斥锁进行解锁。互斥锁不能进行递归锁定或解锁。一个互斥锁对象必须通过其API初始化,而不能使用memset或复制初始化。一个任务在持有互斥锁的时候是不能结束的。互斥锁所使用的内存区域是不能被释放的。使用中的互斥锁是不能被重新初始化的。并且互斥锁不能用于中断上下文。但是互斥锁比当前的内核信号量选项更快,并且更加紧凑,因此如果它们满足您的需求,那么它们将是您明智的选择。但是,对于互斥锁而言,如果资源已经被占用,其它的资源申请进程只能进入 sleep 状态。
- Spinlock(自旋锁): 自旋锁与互斥锁有点类似,只是自旋锁不会引起调用者睡眠,如果自旋锁已经被别的执行单元保持,调用者就一直循环在那里看是否该自旋锁的保持者已经释放了锁,”自旋”一词就是因此而得名。由于自旋锁使用者一般保持锁时间非常短,因此选择自旋而不是睡眠是非常必要的,自旋锁的效率远高于互斥锁。
- rwlock(读写锁): 读写锁实际是一种特殊的自旋锁,它把对共享资源的访问者划分成读者和写者,读者只对共享资源进行读访问,写者则需要对共享资源进行写操作。这种锁相对于自旋锁而言,能提高并发性,因为在多处理器系统中,它允许同时有多个读者来访问共享资源,最大可能的读者数为实际的逻辑 CPU 数。写者是排他性的,一个读写锁同时只能有一个写者或多个读者(与CPU数相关),但不能同时既有读者又有写者。
- semaphore(信号量): 信号量在创建时需要设置一个初始值,表示同时可以有几个任务可以访问该信号量保护的共享资源,初始值为1就变成互斥锁(Mutex),即同时只能有一个任务可以访问信号量保护的共享资源。一个任务要想访问共享资源,首先必须得到信号量,获取信号量的操作将把信号量的值减1,若当前信号量的值为负数,表明无法获得信号量,该任务必须挂起在该信号量的等待队列等待该信号量可用;若当前信号量的值为非负数,表示可以获得信号量,因而可以立刻访问被该信号量保护的共享资源。当任务访问完被信号量保护的共享资源后,必须释放信号量,释放信号量通过把信号量的值加1实现,如果信号量的值为非正数,表明有任务等待当前信号量,因此它也唤醒所有等待该信号量的任务。
- rw_semaphore(读写信号量): 读写信号量对访问者进行了细分,或者为读者,或者为写者,读者在保持读写信号量期间只能对该读写信号量保护的共享资源进行读访问,如果一个任务除了需要读,可能还需要写,那么它必须被归类为写者,它在对共享资源访问之前必须先获得写者身份,写者在发现自己不需要写访问的情况下可以降级为读者。
- 条件变量
- seqlock(顺序锁): 顺序锁也是对读写锁的一种优化,对于顺序锁,读者绝不会被写者阻塞,也就说,读者可以在写者对被顺序锁保护的共享资源进行写操作时仍然可以继续读,而不必等待写者完成写操作,写者也不需要等待所有读者完成读操作才去进行写操作。但是,写者与写者之间仍然是互斥的,即如果有写者在进行写操作,其他写者必须自旋在那里,直到写者释放了顺序锁。
- BKL(大内核锁): 大内核锁本质上也是自旋锁,但是它又不同于自旋锁,自旋锁是不可以递归获得锁的,因为那样会导致死锁。但大内核锁可以递归获得锁。大内核锁用于保护整个内核,而自旋锁用于保护非常特定的某一共享资源。进程保持大内核锁时可以发生调度,具体实现是:在执行 schedule 时,schedule 将检查进程是否拥有大内核锁,如果有,它将被释放,以致于其它的进程能够获得该锁,而当轮到该进程运行时,再让它重新获得大内核锁。注意在保持自旋锁期间是不允许发生调度的。
- brlock(大读者锁): 大读者锁是读写锁的高性能版,读者可以非常快地获得锁,但写者获得锁的开销比较大。大读者锁只存在于 2.4 内核中,在 2.6 中已经没有这种锁(提醒读者特别注意)。它们的使用与读写锁的使用类似,只是所有的大读者锁都是事先已经定义好的。这种锁适合于读多写少的情况,它在这种情况下远好于读写锁。
- RCU(Read-Copy Update): 顾名思义就是读-拷贝修改,它是基于其原理命名的。对于被RCU保护的共享数据结构,读者不需要获得任何锁就可以访问它,但写者在访问它时首先拷贝一个副本,然后对副本进行修改,最后使用一个回调(callback)机制在适当的时机把指向原来数据的指针重新指向新的被修改的数据。这个时机就是所有引用该数据的CPU都退出对共享数据的操作。
Java锁的特点
在很多书写Java并发的文章中,我们经常看到有这些锁的概念。这些概念中,并不全指锁的状态,有的是指所得特性,有的是指所得设计。本文仅仅简要叙述锁的概念,不过多涉及Java锁的实现,这部分内容放在《Javaer不得不说的 Java “锁”事》一文中。
- 公平锁 / 非公平锁:按照多线程申请资源是否按照顺序来获取锁。
- 可重入锁 / 不可重入锁:广义上的可重入锁指的是可重复可递归调用的锁,在外层使用锁之后,在内层仍然可以使用,并且不发生死锁(前提得是同一个对象或者 class),这样的锁就叫做可重入锁,否则就叫不可重入锁。 ReentrantLock 和 synchronized都是可重入锁。
独享锁 / 共享锁:
- 独享锁该锁每一次只能被一个线程所持有。
- 共享锁该锁可被多个线程共有,典型的就是ReentrantReadWriteLock里的读锁,它的读锁是可以被共享的,但是它的写锁确每次只能被独占。
互斥锁 / 读写锁:
- 在访问共享资源之前对进行加锁操作,在访问完成之后进行解锁操作。加锁后,任何其他试图再次加锁的线程会被阻塞,直到当前进程解锁。这是互斥锁。
- 读写锁既是互斥锁,又是共享锁,read 模式是共享,write 是互斥(排它锁)的。
乐观锁 / 悲观锁:
- 悲观锁总是假设最坏的情况,每次去拿数据的时候都认为别人会修改,所以每次在拿数据的时候都会上锁,这样别人想拿这个数据就会阻塞直到它拿到锁, Java中 synchronized 和 ReentrantLock 等独占锁就是悲观锁思想的实现。
- 乐观锁总是假设最好的情况,每次去拿数据的时候都认为别人不会修改,所以不会上锁,但是在更新的时候会判断一下在此期间别人有没有去更新这个数据,可以使用版本号机制和CAS算法实现。乐观锁适用于多读的应用类型,这样可以提高吞吐量,像数据库提供的类似于 write_condition 机制,其实都是提供的乐观锁。在 Java 中 java.util.concurrent.atomic 包下面的原子变量类就是使用了乐观锁的一种实现方式CAS实现的。
- 分段锁:分段锁其实是一种锁的设计,并不是具体的一种锁,对于 ConcurrentHashMap 而言,其并发的实现就是通过分段锁的形式来实现高效的并发操作。
偏向锁 / 轻量级锁 / 重量级锁:
- 偏向锁是指一段同步代码一直被一个线程所访问,那么该线程会自动获取锁。降低获取锁的代价。
- 轻量级锁是指当锁是偏向锁的时候,被另一个线程所访问,偏向锁就会升级为轻量级锁,其他线程会通过自旋的形式尝试获取锁,不会阻塞,提高性能。
- 重量级锁是指当锁为轻量级锁的时候,另一个线程虽然是自旋,但自旋不会一直持续下去,当自旋一定次数的时候,还没有获取到锁,就会进入阻塞,该锁膨胀为重量级锁。重量级锁会让其他申请的线程进入阻塞,性能降低。
- 自旋锁:是指当一个线程在获取锁的时候,如果锁已经被其它线程获取,那么该线程将循环等待,然后不断的判断锁是否能够被成功获取,直到获取到锁才会退出循环。
分布式锁的特点
对系统内核锁和Java锁有初步的了解之后,我们总结发现,所必需的要有以下特点:
- 互斥性: 互斥性是最基本的特征,分布式锁需要保证在不同节点的不同线程的互斥。
- 可重入性: 同一个节点上的同一个线程如果获取了锁之后那么也可以再次获取这个锁。
- 锁超时: 和本地锁一样支持锁超时,防止死锁。
- 高效,高可用: 加锁和解锁需要高效,同时也需要保证高可用防止分布式锁失效,可以增加降级。
- 支持阻塞和非阻塞: 和 ReentrantLock 一样支持 lock 和 trylock 以及 tryLock(long timeOut)。
- 支持公平锁和非公平锁(可选):公平锁的意思是按照请求加锁的顺序获得锁,非公平锁就相反是无序的。这个一般来说实现的比较少。
常见分布式锁
一般实现分布式锁有以下几个方式:
- MySql
- Zk
- Redis
- Etcd
- 自研分布式锁:如谷歌的Chubby。
下面就 MySQL 和 zk curator 客户端加锁的实现方式逐一列举,关于 Redis、Zk 原生客户端、etcd 等其他方式的分布式锁的实现原理,放在后面的章节。
MySQL分布式锁
MySQL实现分布式锁相对简单,创建一张锁资源表。
CREATE TABLE resource_lock (
`id` BIGINT(20) UNSIGNED NOT NULL PRIMARY KEY AUTO_INCREMENT,
`resource_name` VARCHAR(32) NOT NULL DEFAULT '' COMMENT '资源名称',
`node_info` VARCHAR(128) NULL DEFAULT NULL COMMENT '',
`count` INT(10) NOT NULL DEFAULT '0' COMMENT '',
`description` VARCHAR(128) NULL DEFAULT NULL COMMENT '',
`gmt_create` TIMESTAMP NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '',
`gmt_modify` TIMESTAMP NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '',
UNIQUE KEY `uk_resource` (`resource_name`)
) ENGINE = InnoDB DEFAULT CHARSET=utf8mb4 COMMENT '资源加锁表';前面分布式锁所说的 lock(),trylock(long timeout),trylock() 这几个方法可以用下面的伪代码实现。
lock()
lock一般是阻塞式的获取锁,阻塞知道获取到锁或者异常结束,那么我们可以写一个死循环来执行其操作:
public void lock() {
while(true) {
if (mysqlLock.lock(resoureName)) {
return;
}
// 休眠3ms后重试
LockSuprot.parkNanos(1000*1000*3);
}
}mysqlLock.lcok() 内部是一个SQL,为了达到可重入锁的效果那么我们应该先进行查询,如果有值,那么需要比较 node_info 是否一致,这里的 node_info 可以用机器 IP 和线程名字来表示,如果一致那么就加可重入锁 count 的值,如果不一致那么就返回false。如果没有值那么直接插入一条数据。伪代码如下:
public class MysqlLock {
@Resource
private MysqlLockMapper mysqlLockMapper;
private NodeInfo nodeInfo;
public MysqlLock(NodeInfo nodeInfo) {
this.nodeInfo = nodeInfo;
}
@Transcation
public boolean lock(String resourceName) {
MyResource result = mysqlLockMapper.existsResource(resourceName);
if (result != null) {
if (Objects.equeals(nodeInfo, result.getNodeInfo())) {
mysqlLockMapper.updateResourceCount(resourceName);
return true;
} else {
return false;
}
} else {
mysqlLockMapper.insertResource(resourceName, nodeInfo);
}
}
}需要注意的是这一段代码需要加事务,必须要保证这一系列操作的原子性。
上面代码对应的三条 Mybatis 版的SQL语句如下:
-- mysqlLockMapper.existsResource
select * from resource_lock where resource_name = ${resourceName} for update
-- mysqlLockMapper.updateResourceCount
update resource_lock set count = count + 1 where resource_name = ${resourceName}
-- mysqlLockMapper.insertResource
insert into resource_lock(`resource_name`,`node_info`,`count`,`description`)
values(#{resourceName}, ${nodeInfo}, 1, '')
trylock()
tryLock() 是非阻塞获取锁,如果获取不到那么就会马上返回,代码可以如下:
public boolean tryLock() {
return mysqlLock.lock(resourceName);
}trylock(long millsecs)
public boolean trylock(long millsecs) {
// 记录超时时间
long deadline = System.currentTimeMillis() + millsecs;
while(true) {
if (mysqlLock.tryLock()) {
return true;
}
deadline = deadline - millsecs;
// 避免网络延迟引起加锁失败,增加自旋超时阈值,可设置为300ms
if (deadline <= spinTimeoutThreshold) {
return false;
}
if (millsecs <= 0) {
return false;
}
}
}mysqlLock.lock 和上面一样,但是要注意的是 select … for update 这个是阻塞的获取行锁,如果同一个资源并发量较大还是有可能会退化成阻塞的获取锁。
unlock()
public boolean unlock() {
MyResource result = mysqlLockMapper.existsResource(resourceName);
if (result != null) {
if (Objects.equeals(nodeInfo, result.getNodeInfo())) {
if (result.getCount() > 1) {
// count - 1
mysqlLockMapper.decrementResource(resourceName);
} else {
mysqlLockMapper.deleteResource(resourceName);
}
} else {
return false;
}
} else {
return false;
}
}上面新增两条 Mybatis 版本的SQL语句:
-- mysqlLockMapper.decrementResource(resourceName)
update resource_lock set count = count - 1 where resource_name = ${resourceName}
-- mysqlLockMapper.deleteResource(resourceName)
delete from resource_lock where resource_name = ${resourceName}
锁超时
我们注意到,锁的释放是通过 delete 语句删除资源锁的,如果加锁的客户端由于某些原因挂掉了,锁就一直存在。这时,我们可以通过定时任务,在加锁的时候添加任务到任务系统,也可以通过定时任务检查释放锁。
ZK客户端Curator分布式锁
ZooKeeper也是我们常见的实现分布式锁方法,ZooKeeper 是以 Paxos 算法为基础分布式应用程序协调服务。Zk 的数据节点和文件目录类似,所以我们可以用此特性实现分布式锁。我们以某个资源为目录,然后这个目录下面的节点就是我们需要获取锁的客户端,未获取到锁的客户端注册需要注册 Watcher 到上一个客户端,可以用下图表示。
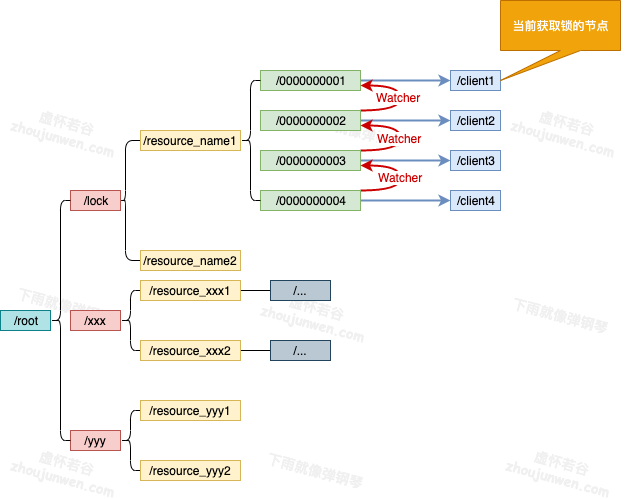
/lock是我们用于加锁的目录,/resource_name是我们锁定的资源,其下面的节点按照我们加锁的顺序排列。
Curator 封装了 Zookeeper 底层的 API,使我们更加容易方便的对 Zookeeper 进行操作,并且它封装了分布式锁的功能,这样我们就不需要再自己实现了。
Curator 实现了可重入锁(InterProcessMutex),也实现了不可重入锁(InterProcessSemaphoreMutex)。在可重入锁中还实现了读写锁。
Curator-Recipes实现了五种分布式锁:
- Shared Reentrant Lock 分布式可重入锁
- Shared Lock 分布式非可重入锁
- Shared Reentrant Read Write Lock 可重入读写锁
- Shared Semaphore 共享信号量
- Multi Shared Lock 多共享锁
下面就分布式可重入锁举例。
可重入锁InterProcessMutex
InterProcessMutex 是 Curator 实现的可重入锁,创建 InterProcessMutex 实例
InterProcessMutex 提供了两个构造方法,传入一个 CuratorFramework 实例和一个要使用的节点路径,InterProcessMutex 还允许传入一个自定义的驱动类,默认是使用 StandardLockInternalsDriver。
public InterProcessMutex(CuratorFramework client, String path);
public InterProcessMutex(CuratorFramework client, String path, LockInternalsDriver driver);获取锁
使用 acquire 方法获取锁, acquire 方法有两种:
public void acquire() throws Exception;获取锁,一直阻塞到获取到锁为止。获取锁的线程在获取锁后仍然可以调用 acquire() 获取锁(可重入)。 锁获取使用完后,调用了几次 acquire(),就得调用几次 release() 释放。
public boolean acquire(long time, TimeUnit unit) throws Exception;与 acquire()类似,等待 time * unit 时间获取锁,如果仍然没有获取锁,则直接返回 false。
- 共享资源
public class FakeLimitedResource {
//总共250张火车票
private Integer ticket = 250;
public void use() throws InterruptedException {
try {
System.out.println("火车票还剩"+(--ticket)+"张!");
}catch (Exception e){
e.printStackTrace();
}
}
}- 使用锁操作资源
public class ExampleClientThatLocks {
/** 锁 */
private final InterProcessMutex lock;
/** 共享资源 */
private final FakeLimitedResource resource;
/** 客户端名称 */
private final String clientName;
public ExampleClientThatLocks(CuratorFramework client, String lockPath, FakeLimitedResource resource, String clientName) {
this.resource = resource;
this.clientName = clientName;
lock = new InterProcessMutex(client, lockPath);
}
public void doWork(long time, TimeUnit unit) throws Exception {
if ( !lock.acquire(time, unit) ) {
throw new IllegalStateException(clientName + " could not acquire the lock");
}
try {
System.out.println(clientName + " has the lock");
//操作资源
resource.use();
} finally {
System.out.println(clientName + " releasing the lock");
lock.release(); //总是在Final块中释放锁。
}
}
}
- 客户端
public class LockingExample {
private static final int QTY = 5; // 并发操作线程数
private static final int REPETITIONS = QTY * 10; // 资源总量
private static final String CONNECTION_STRING = "127.0.0.1:2181";
private static final String PATH = "/locks";
public static void main(String[] args) throws Exception {
//FakeLimitedResource模拟某些外部资源,这些外部资源一次只能由一个进程访问
final FakeLimitedResource resource = new FakeLimitedResource();
ExecutorService service = Executors.newFixedThreadPool(QTY);
try {
for ( int i = 0; i < QTY; ++i ){
final int index = i;
Callable<Void> task = new Callable<Void>() {
@Override
public Void call() throws Exception {
CuratorFramework client = CuratorFrameworkFactory.newClient(CONNECTION_STRING, new ExponentialBackoffRetry(1000, 3,Integer.MAX_VALUE));
try {
client.start();
ExampleClientThatLocks example = new ExampleClientThatLocks(client, PATH, resource, "Client " + index);
for ( int j = 0; j < REPETITIONS; ++j ) {
example.doWork(10, TimeUnit.SECONDS);
}
}catch ( InterruptedException e ){
Thread.currentThread().interrupt();
}catch ( Exception e ){
e.printStackTrace();
}finally{
CloseableUtils.closeQuietly(client);
}
return null;
}
};
service.submit(task);
}
service.shutdown();
service.awaitTermination(10, TimeUnit.MINUTES);
}catch (Exception e){
e.printStackTrace();
}
}
}
起五个线程,即五个窗口卖票,五个客户端分别有50张票可以卖,先是尝试获取锁,操作资源后,释放锁。
加锁的流程具体如下:
- 首先进行可重入的判定:这里的可重入锁记录在 ConcurrentMap,threadData 这个 Map 里面,如果threadData.get(currentThread)是有值的那么就证明是可重入锁,然后记录就会加1。我们之前的 Mysql 其实也可以通过这种方法去优化,可以不需要 count 字段的值,将这个维护在本地可以提高性能。
- 然后在我们的资源目录下创建一个节点:比如这里创建一个 /0000000002 这个节点,这个节点需要设置为 EPHEMERAL_SEQUENTIAL 也就是临时节点并且有序。
- 获取当前目录下所有子节点,判断自己的节点是否位于子节点第一个。
- 如果是第一个,则获取到锁,那么可以返回。
- 如果不是第一个,则证明前面已经有人获取到锁了,那么需要获取自己节点的前一个节点。/0000000002 的前一个节点是 /0000000001,我们获取到这个节点之后,再上面注册Watcher(这里的 watcher 其实调用的是 object.notifyAll(),用来解除阻塞)。
- object.wait(timeout) 或 object.wait() :进行阻塞等待这里和我们第5步的watcher相对应。
释放锁
线程通过 acquire() 获取锁时,可通过 release()进行释放,如果该线程多次调用了 acquire() 获取锁,则如果只调用一次 release() 该锁仍然会被该线程持有。
note:同一个线程中InterProcessMutex实例是可重用的,也就是不需要在每次获取锁的时候都new一个InterProcessMutex实例,用同一个实例就好。
解锁的具体流程:
- 首先进行可重入锁的判定: 如果有可重入锁只需要次数减 1 即可,减1之后加锁次数为 0 的话继续下面步骤,不为 0 直接返回。
- 删除当前节点。
- 删除 threadDataMap 里面的可重入锁的数据。
读写锁
Curator提供了读写锁,其实现类是 InterProcessReadWriteLock,这里的每个节点都会加上前缀:
private static final String READ_LOCK_NAME = "__READ__";
private static final String WRITE_LOCK_NAME = "__WRIT__";根据不同的前缀区分是读锁还是写锁,对于读锁,如果发现前面有写锁,那么需要将 watcher 注册到和自己最近的写锁。写锁的逻辑和我们之前分析的依然保持不变。
锁超时
Zookeeper不需要配置锁超时,由于我们设置节点是临时节点,我们的每个机器维护着一个ZK的session,通过这个session,ZK可以判断机器是否宕机。如果我们的机器挂掉的话,那么这个临时节点对应的就会被删除,所以我们不需要关心锁超时。
分布式锁的安全问题
- 长时间的GC pause: 做Java开发的同学肯定对 GC 不陌生,在 GC 的时候会发生STW(stop-the-world),例如CMS垃圾回收器,会有两个阶段进行 STW 防止引用继续进行变化。Martin反驳Redlock的文章《How to do distributed locking》中对此有详细的解释,下面此图来源此文:
client1 获取了锁并且设置了锁的超时时间,但是 client1 之后出现了 STW,这个 STW 时间比较长,导致分布式锁进行了释放,client2 获取到了锁,这个时候 client1 恢复了锁,那么就会出现 client1,client2 同时获取到锁,这个时候分布式锁不安全问题就出现了。这个其实不仅仅局限于 RedLock,对于我们的 ZK,Mysql 一样的有同样的问题。
- 时钟发生跳跃:对于Redis服务器如果其时间发生了跳跃,那么肯定会影响我们锁的过期时间,那么我们的锁过期时间就不是我们预期的了,也会出现 client1 和 client2 获取到同一把锁,那么也会出现不安全,这个对于 Mysql 也会出现。但是 ZK 由于没有设置过期时间,那么发生跳跃也不会受影响。
- 长时间的网络I/O:这个问题和我们的 GC 的 STW 很像,也就是我们这个获取了锁之后我们进行网络调用,其调用时间可能比我们锁的过期时间都还长,那么也会出现不安全的问题,这个 Mysql 也会有,ZK 也会出现这个问题。
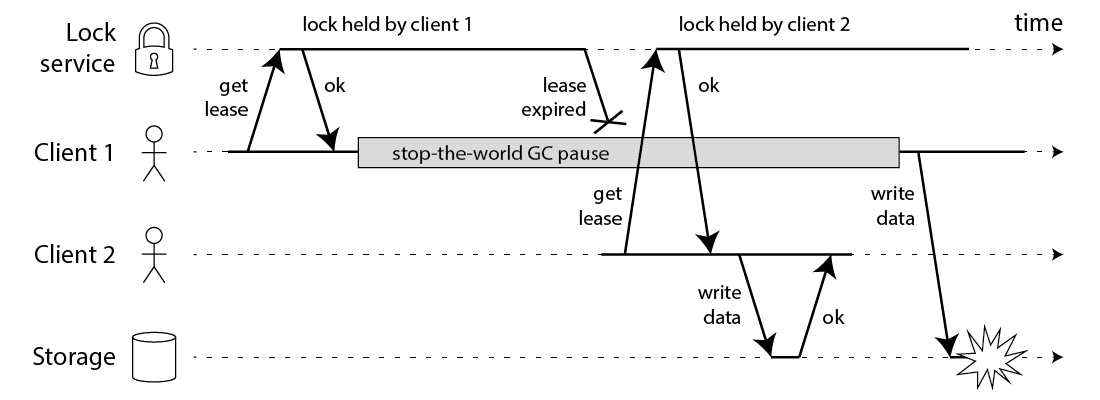
GC的STW
对于这个问题可以看见基本所有的都会出现问题,Martin 给出了一个解法,对于 ZK 这种他会生成一个自增的序列,那么我们真正进行对资源操作的时候,需要判断当前序列是否是最新,有点类似于我们乐观锁。当然这个解法Redis作者进行了反驳,你既然都能生成一个自增的序列了那么你完全不需要加锁了,也就是可以按照类似于Mysql乐观锁的解法去做。
时钟发生跳跃
Martin 觉得 RedLock 不安全很大的原因也是因为时钟的跳跃,因为锁过期强依赖于时间,但是 ZK 不需要依赖时间,依赖每个节点的 Session。Redis作者也给出了解答:对于时间跳跃分为人为调整和 NTP 自动调整。
- 人为调整:人为调整影响的那么完全可以人为不调整,这个是处于可控的。
- NTP自动调整: 这个可以通过一定的优化,把跳跃时间控制的可控范围内,虽然会跳跃,但是是完全可以接受的。
长时间的网络I/O
这一块不是他们讨论的重点,我自己觉得,对于这个问题的优化可以控制网络调用的超时时间,把所有网络调用的超时时间相加,那么我们锁过期时间其实应该大于这个时间,当然也可以通过优化网络调用比如串行改成并行,异步化等。可以参考下面两篇文章:
并行化-你的高并发大杀器,异步化-你的高并发大杀器
参考文章
该文首发《虚怀若谷》个人博客,转载前请务必署名,转载请标明出处。
古之善为道者,微妙玄通,深不可识。夫唯不可识,故强为之容:豫兮若冬涉川,犹兮若畏四邻,俨兮其若客,涣兮若冰之释,敦兮其若朴,旷兮其若谷,混兮其若浊。
孰能浊以静之徐清?孰能安以动之徐生?
保此道不欲盈。夫唯不盈,故能敝而新成。
请关注我的微信公众号:下雨就像弹钢琴,Thanks♪(・ω・)ノ


