
RabbitMQ 的高可用性
RabbitMQ 是比较有代表性的,因为是基于主从(非分布式)做高可用的
RabbitMQ 有三种模式:单机模式、普通集群模式、镜像集群模式。
单机模式
单机模式,生产几乎不用。
普通集群模式(无高可用性)
普通集群模式,有服务器ABC,在服务器ABC上分别启动RabbitMQ实例,生产者生产消息1,随机发给某一实例A,实例BC
上记录消息1的原数据信息(比如消息1具体信息在示例A上),消费者消费消息,随机连接某个示例B,消费消息1,实例B根据
原数据发现消息1在实例A上,则实例B去实例A拉取消息返回给消费者。
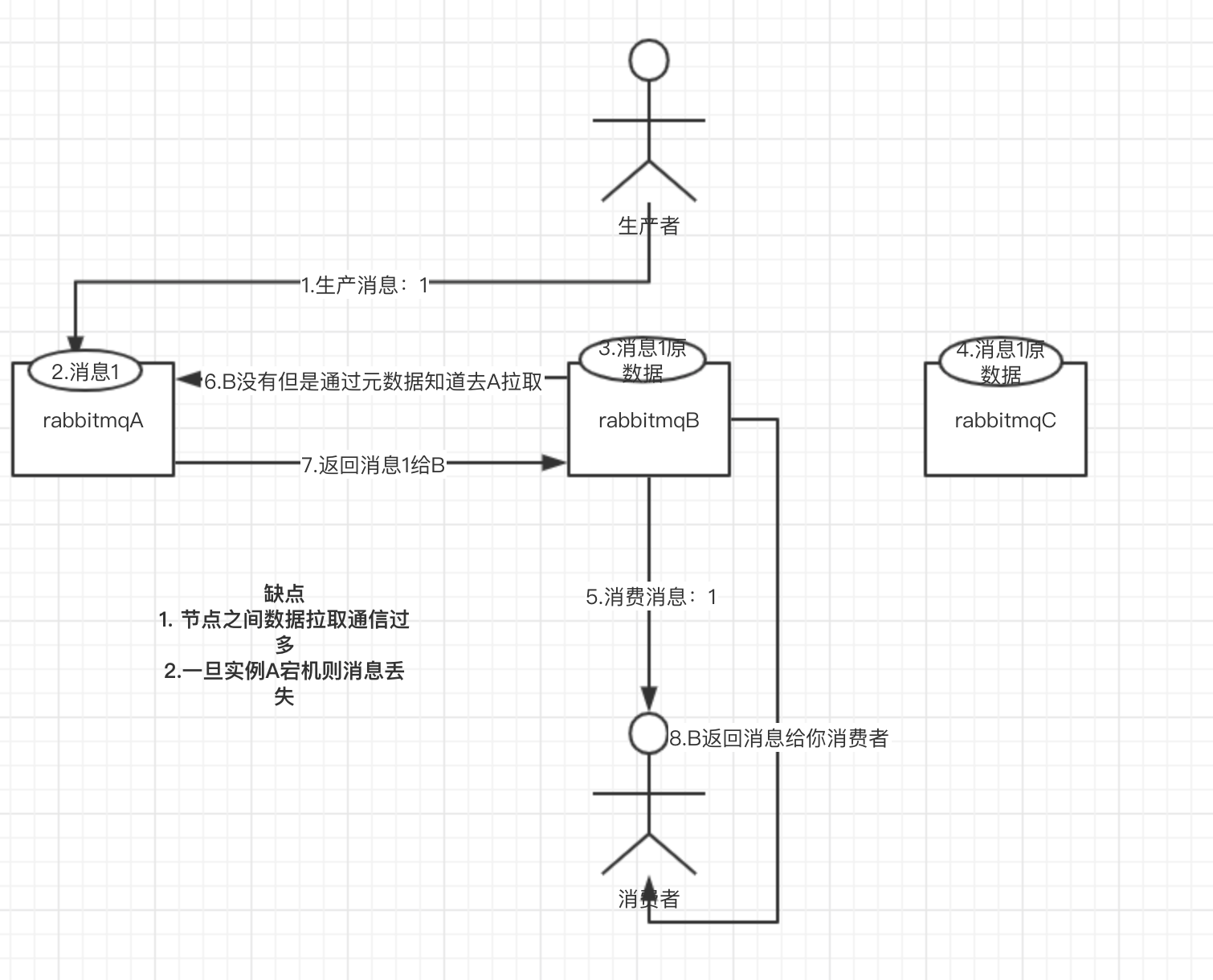
就是个普通集群。因为这导致你要么消费者每次随机连接一个实例然后拉取数据,要么固定连接那个 queue 所在实例消费数据,前者有数据拉取的开销,后者导致单实例性能瓶颈。
而且如果那个放 queue 的实例宕机了,会导致接下来其他实例就无法从那个实例拉取,如果你开启了消息持久化,让 RabbitMQ 落地存储消息的话,消息不一定会丢,得等这个实例恢复了,然后才可以继续从这个 queue 拉取数据。
所以这个事儿就比较尴尬了,这就没有什么所谓的高可用性,这方案主要是提高吞吐量的,就是说让集群中多个节点来服务某个 queue 的读写操作。
镜像集群模式(高可用性)
这种模式,才是所谓的 RabbitMQ 的高可用模式。跟普通集群模式不一样的是,在镜像集群模式下,你创建的 queue,无论元数据还是 queue 里的消息都会存在于多个实例上,就是说,每个 RabbitMQ 节点都有这个 queue 的一个完整镜像,包含 queue 的全部数据的意思。然后每次你写消息到 queue 的时候,都会自动把消息同步到多个实例的 queue 上。
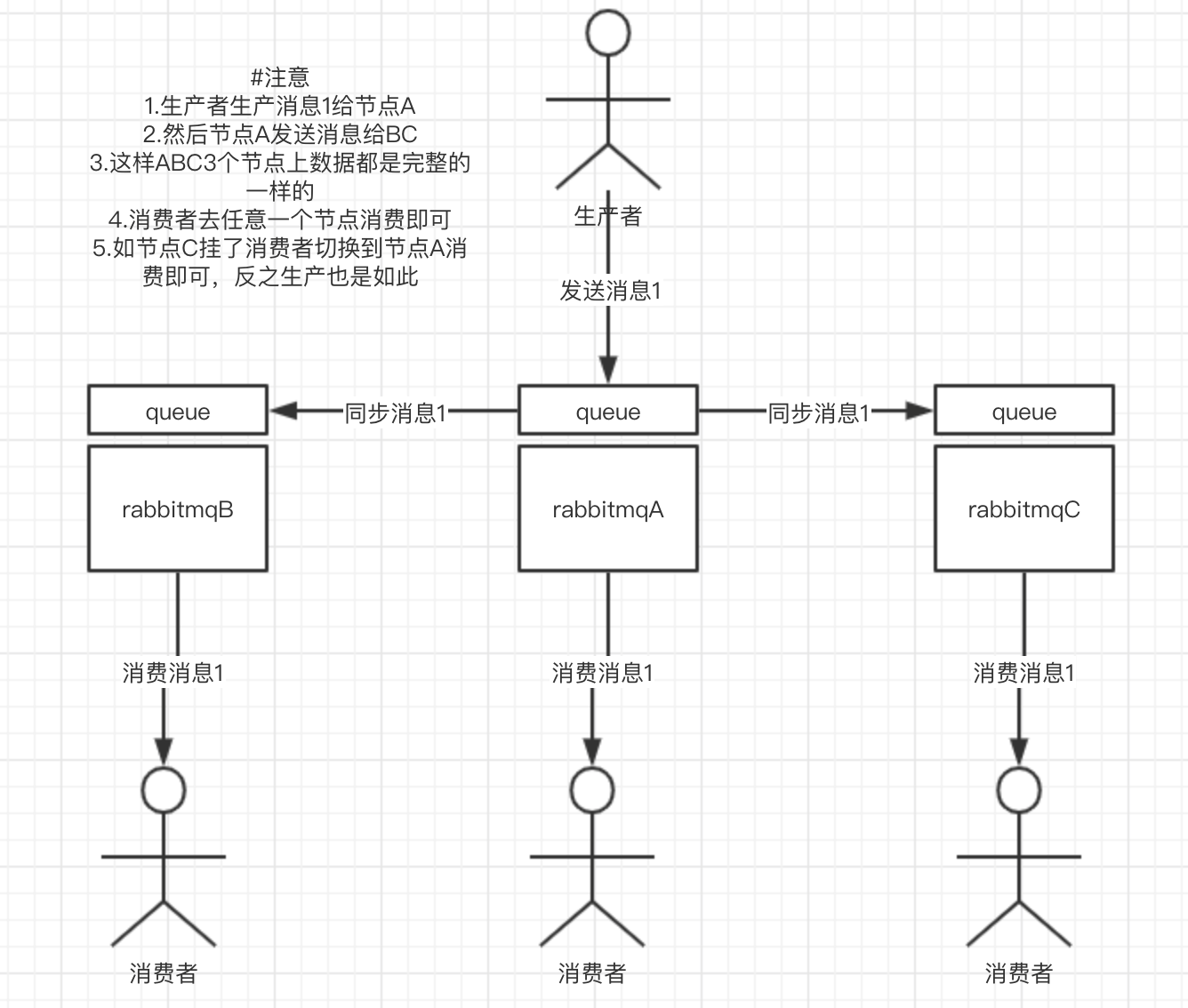
那么如何开启这个镜像集群模式呢?其实很简单,RabbitMQ 有很好的管理控制台,就是在后台新增一个策略,这个策略是镜像集群模式的策略,指定的时候是可以要求数据同步到所有节点的,也可以要求同步到指定数量的节点,再次创建 queue 的时候,应用这个策略,就会自动将数据同步到其他的节点上去了。
这样的话,好处在于,你任何一个机器宕机了,没事儿,其它机器(节点)还包含了这个 queue 的完整数据,别的 consumer 都可以到其它节点上去消费数据。坏处在于,第一,这个性能开销也太大了吧,消息需要同步到所有机器上,导致网络带宽压力和消耗很重!第二,这么玩儿,不是分布式的,就没有扩展性可言了,如果某个 queue 负载很重,你加机器,新增的机器也包含了这个 queue 的所有数据,并没有办法线性扩展你的 queue。你想,如果这个 queue 的数据量很大,大到这个机器上的容量无法容纳了,此时该怎么办呢?
如感觉文章对你有所帮助,可以关注微信公众号【五彩的颜色】鼓励一下


