
这个技术社区公式排版有点问题,建议观看:机器博弈 (二) 遗憾最小化算法。
现代的博弈论快速与人工智能进行结合,形成了以数据驱动的博弈论新的框架。博弈论与计算机科学的交叉领域非常多,有以下几个方面:
- 理论计算机科学:算法博弈论
- 人工智能:多智能体系统、AI游戏、人机交互、机器学习、广告推荐等。
- 互联网:互联网经济、共享经济。
- 分布式系统:区块链。
人工智能与博弈论结合,形成了两个主要研究方向:1. 博弈策略的求解;2. 博弈规则的设计。
博弈论提供了许多问题的数学模型。纳什定理确定了博弈过程问题存在解。人工智能的方法可以用来求解均衡局面或者最优策略。
主要研究的问题就是:如何高效求解博弈参与者的策略以及博弈的均衡局势。
其应用领域主要有:
- 大规模搜索空间的问题求解:围棋。
- 非完美信息博弈问题求解:德州扑克。
- 网络对战游戏智能:Dota、星球大战。
- 动态博弈的均衡解:厂家竞争、信息安全。
遗憾最小化算法(Regret Minimization):
我们对遗憾最优化算法(RM)中符号做若干定义:
- 假设一共有$N$个玩家。玩家$i$所采用的策略表示为$\sigma_{i}$。
- 对于每个信息集$I_{i} \in \xi_{i}$,$\sigma_{i}(I_{i}):A(I_{i}) \rightarrow [0,1]$是在动作集$A(I_{i})$上的概率分布函数。玩家$i$的策略空间用$\sum_{i}$表示。
- 一个策略组包含所有玩家策略,用$\sigma =(\sigma_{1}$,$\sigma_{2}$,$\cdots$,$\sigma_{|N|})$。
- $\sigma_{-i}$表示$\sigma$中除了$\sigma_{i}$之外的策略(即除去玩家$i$所采用的策略)。
- 在博弈对决中,不同玩家在不同时刻会采取相应策略以及行动。策略$\sigma$下对应的动作序列$h$发生概率表示为$\pi^{\sigma}(h)$。于是,$\pi^{\sigma}(h)=\prod_{i \in N} \pi_{i}^{\sigma}(h)$,这里$\pi_{i}^{\sigma}(h)$表示玩家$i$使用策略$\sigma_{i}$促使行动序列$h$发生的概率。除玩家$i$以外,其他玩家通过各自策略促使行动序列$h$发生的概率可表示为:$\pi_{-i}^{\sigma}(h)=\prod_{i \in N \ / \{i\}} \pi_{j}^{\sigma}(h)$。
- 对于每个玩家$i \in N$,$u_{i}:Z \rightarrow R$表示玩家$i$的收益函数,即在到达终止序列集合$Z$中某个终止序列时,玩家$i$所得到的收益。
- 玩家$i$在给定策略$\sigma$下所能得到的期望收益可如下计算:$u_{i}(\sigma)=\sum_{h \in Z}u_{i}(h)\pi^{\sigma}(h)$。
最佳反应策略与纳什均衡
我们来看一下遗憾最小化算法下的最佳反应策略和纳什均衡。
- 玩家$i$对于所有玩家的策略组$\sigma_{-i}$的最佳反应策略$\sigma_{i}^{*}$满足如下条件:
$$ u_{i}(\sigma_{i}^{*},\sigma_{-i}) \geq max_{\sigma_{i}^{'}\in \sum_{i}} u_{i}(\sigma_{i}^{'},\sigma_{-i}) $$
即玩家$i$采用其它策略获得的收益小于采用最佳策略所能获得的收益。(这里其它玩家策略保持不变。)
在策略组$\sigma$中,如果每个玩家的策略相对于其他玩家的策略而言都是最佳反应策略,那么策略组$\sigma$就是一个纳什均衡(Nash equilibrium)策略。
纳什均衡:策略组$\sigma =(\sigma_{1}^{*}$,$\sigma_{2}^{*}$,$\cdots$,$\sigma_{|N|}^{*})$是纳什均衡当且仅当对每个玩家$i \in N$,满足如下条件:
$$ u_{i}(\sigma) \geq max_{\sigma_{i}^{'}} u_{i}(\sigma_{i}^{*},\sigma_{2}^{*}, \cdots , \sigma_{i}^{'}, \cdots, \sigma_{|N|}^{*}) $$
$\varepsilon$-纳什均衡与平均遗憾值
$\varepsilon$-纳什均衡:
- 对于给定的正实数$\varepsilon$,策略组$\sigma$是$\varepsilon$-纳什均衡当且仅当对于每个玩家$i \in N$,满足如下条件:
$$ u_{i}(\sigma) + \varepsilon \geq max_{\sigma_{i}^{'} \in \sum_{i}}u_{i}(\sigma_{i}^{'},\sigma_{-i}) $$
- 平均遗憾值(average overall regret):假设博弈能够重复地进行(如围棋等),令第$t$次博弈时的策略组为$\sigma^{t}$,若博弈已经进行了$M$次,则这$M$次博弈对于玩家$i \in N$的平均遗憾值定义为:
$$ \overline{Regret_{i}^{M}} = \frac{1}{M}max_{\sigma_{i}^{*} \in \sum_{i}}\sum_{i=1}^{M}(u_{i}(\sigma_{i}^{*},\sigma_{-i}^{t})-u_{i}(\sigma^{t})) $$
策略选择
- 遗憾最小化算法是一种根据过去博弈中的遗憾程度来决定将来动作选择的方法
- 在博弈中,玩家$i$在第$T$轮次(每一轮表示一次博弈完成)采取策略$\sigma_{i}$的遗憾值定义如下(累加遗憾):
$$ Regret_{i}^{T}(\sigma_{i})=\sum_{t=1}^{T}(\mu_{i}(\sigma_{i},\sigma_{-i}^{t})-\mu_{i}(\sigma^{t})) $$
- 通常遗憾值为负数的策略被认定为不能提升下一时刻收益,所以这里考虑的遗憾值均为正数或0;
- 计算得到玩家$i$在第$T$轮次采取策略$\sigma_{i}$的遗憾值后,在第$T+1$轮次玩家$i$选择策略$a$的概率如下(悔值越大、越选择,即亡羊补牢):
$$ P(a) = \frac{Regret_{i}^{T}(a)}{\sum_{b \in {所有可能选择策略}}Regret_{i}^{T}(b)} $$
Rock-Paper-Scissors,RPS 例子
- 假设两个玩家$A$和$B$进行石头-剪刀-布(Rock-Paper-Scissors,RPS)的游戏,获胜玩家收益为1分,失败玩家收益为-1分,平局则两个玩家收益均为零分。
- 第一局时,若玩家$A$出石头($R$),玩家$B$出布($P$),则此时玩家$A$的收益$\mu_{A}(R,P)=-1$,玩家$B$的收益为$\mu_{B}(P,R)=1$。
- 对于玩家$A$来说,在玩家$B$出布($P$)这个策略情况下,如果玩家$A$选择出布($P$)或者剪刀($S$),则玩家$A$对应的收益值$\mu_{A}(P,P)=0$或者$\mu_{A}(S,P)=1$。
- 所以第一局之后,玩家$A$没有出布的遗憾值为:
$\mu_{A}(P,P)-\mu_{A}(R,P)=0
-(-1)=1$,
没有出剪刀的遗憾值为:
$\mu_{A}(S,P)-\mu_{A}(R,P)=1-(-1)=2$。
- 所以在第二局中,玩家$A$选择石头、剪刀和布这三个策略的概率分别为0、2/3、1/3。因此,玩家$A$趋向于在第二局中选择出剪刀这个策略。
- 在第一轮中,玩家$A$选择石头和玩家$B$选择布、在第二局中玩家$A$选择剪刀和玩家$B$选择石头情况下,则玩家$A$每一轮遗憾值及第二轮后的累加遗憾取值如下:
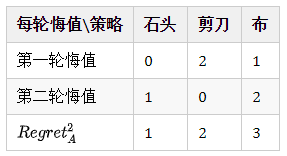
- 从上表可知,在第三局时,玩家$A$选择石头、剪刀和布的概率分别为1/6、2/6、3/6
- 在实际使用中,可以通过多次模拟迭代累加遗憾值找到每个玩家在每一轮次的最优策略。
- 但是当博弈状态空间呈指数增长时,对一个规模巨大的博弈树无法采用最小遗憾算法。
我的微信公众号名称:深度学习与先进智能决策
微信公众号ID:MultiAgent1024
公众号介绍:主要研究分享深度学习、机器博弈、强化学习等相关内容!期待您的关注,欢迎一起学习交流进步!

