本篇文章主要是手把手教你搭建 ELK 实时日志分析平台,那么,ELK 到底是什么呢?
ELK 是三个开源项目的首字母缩写,这三个项目分别是:Elasticsearch、Logstash 和 Kibana。
- Elasticsearch 是一个搜索和分析引擎。
- Logstash 是服务器端数据处理管道,能够同时从多个来源采集数据,转换数据,然后将数据发送到诸如 Elasticsearch 等存储库中。
- Kibana 则可以让用户在 Elasticsearch 中使用图形和图表对数据进行可视化。

Elasticsearch 的核心是搜索引擎,所以用户开始将其用于日志用例,并希望能够轻松地对日志进行采集和可视化。有鉴于此,Elastic 引入了强大的采集管道 Logstash 和灵活的可视化工具 Kibana。
ELK日志系统数据流图如下:

简短了解 ELK 是个啥后,让我们一起动手搭建 ELK 实时日志分析平台,首先安装 Elasticsearch。
注:ELK 环境搭建版本很关键,建议统一版本,避免错误无处下手,我在这里选用的是 7.1.0 版本。
ElasticSearch 介绍与安装
ElasticSearch 的介绍与安装在上一篇文章已经讲过了,这里就不进行赘述了,大家可以点击下方链接查看:
如果你已经了解并安装好 Elasticsearch,那么就跟着我一起往下一步进发:了解并安装 Kibana。
Kibana 介绍与安装
这部分主要讲解如何下载并安装 Kibana,以及如何安装 Kibana 插件,同时会针对 Kibana 的界面进行简单的介绍。
首先让我们来看下 Kibana 究竟是何物?
什么是 Kibana?
Kibana 是为 Elasticsearch 设计的开源分析和可视化平台,你可以使用 Kibana 来搜索,查看存储在 Elasticsearch 索引中的数据并与之交互,你可以很容易实现高级的数据分析和可视化,以图标的形式展现出来。
在简单了解了 Kibana 后,让我们来到 Kibana 的下载网站 https://www.elastic.co/cn/downloads/kibana ,目前使用的是 Windows 系统,因此下载 Windows 版本的 Kibana 下载包 kibana-7.1.0-windows-x86_64.zip。
运行 Kibana
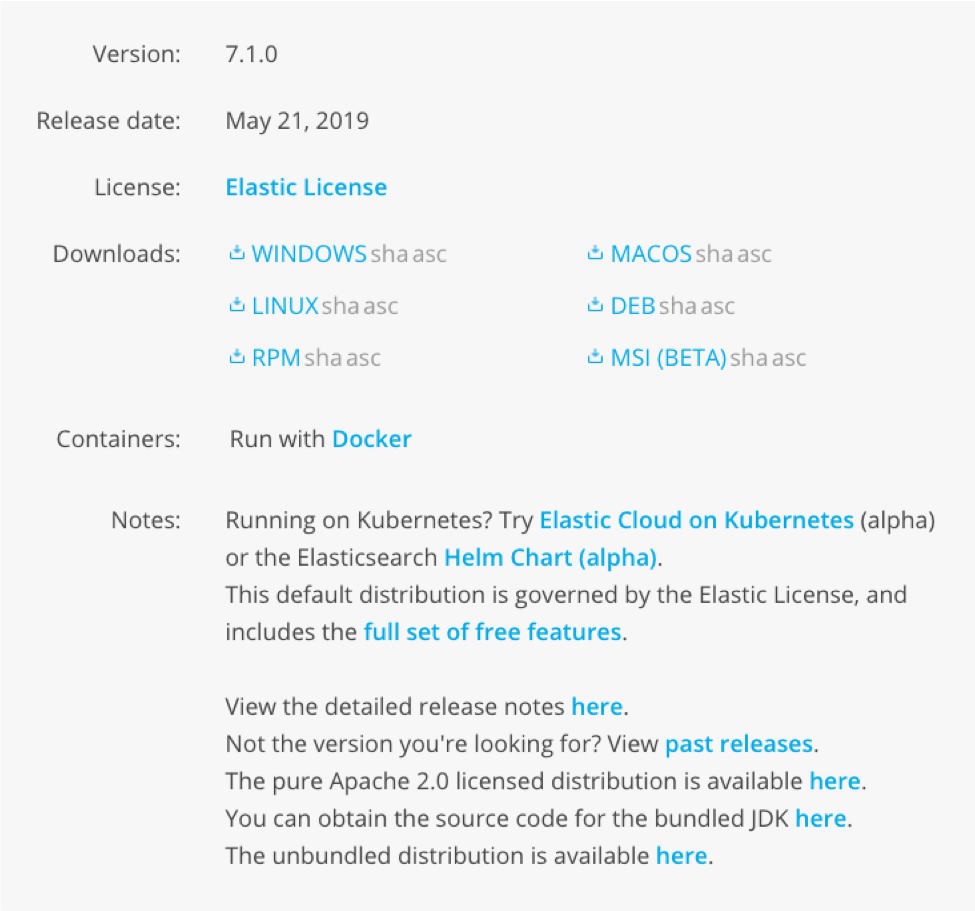
下载完成后在本地解压,如果需要对 Kibana 做一些定制,可以在 config 目录下 编辑 kibana.yml 文件,在运行 Kibana 之前需要先运行 ElasticSearch(以下简称 ES),因为 Kibana 是基于 ES 运行的,现在进入 bin 目录下打开 kibana.bat 就可以运行 Kibana 了,我们现在打开浏览器,Kibana 是运行在 5601 端口上的,因此打开 http://localhost:5601,打开后会出现如下页面:
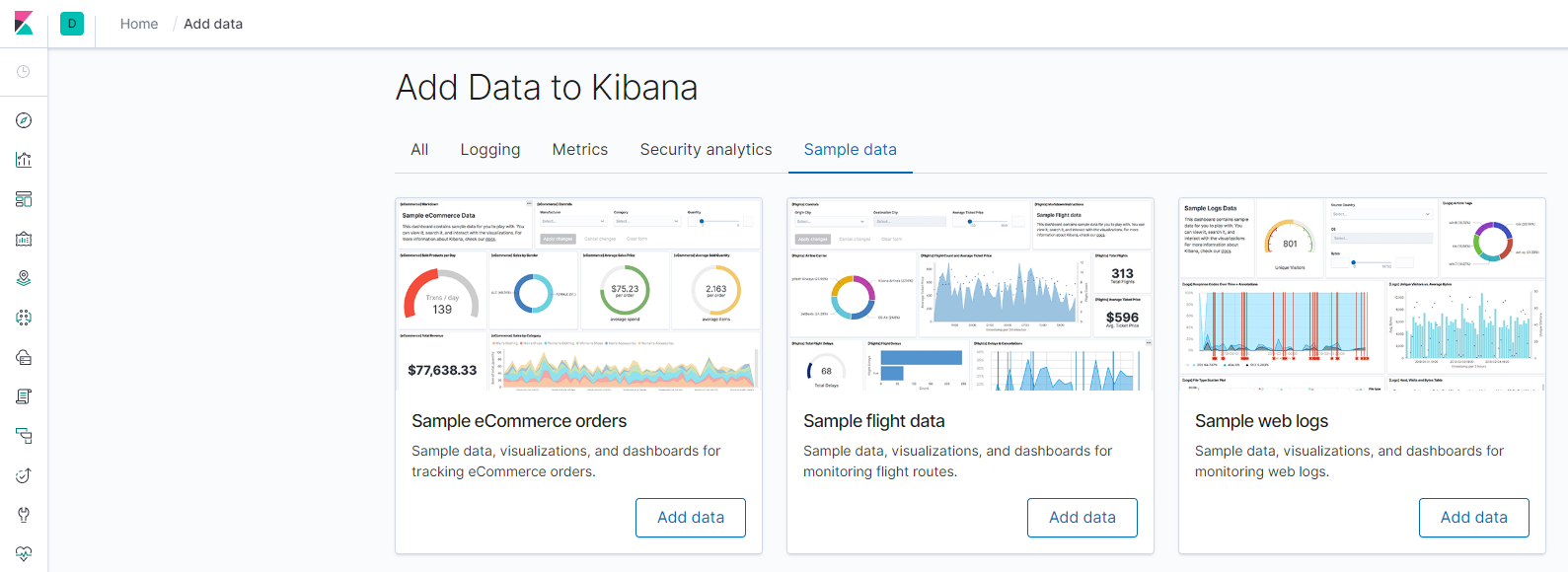
导入样例数据,查看 Dashboard
进入首页后会提示我们可以添加一些测试数据,ES 在 Kibana 开箱即用的版本中,已经为我们准备了三种样例数据,电商网站的订单,航空公司的飞行记录以及 WEB 网站的日志,我们可以点击 Add data,把他们添加进来,添加完成后,我们可以打开 Dashboards 界面,就可以看到系统已经为我们创建了数据的 Dashboard。

第一个是电商的利润报表,我们可以打开来看一下:

在 Dashboard 中,我们可以将多套可视结果整合至单一页面内,而后提供搜索查询或者点击可视结果内的某元素指定过滤条件,从而实现结果过滤,Dashboard 能够帮助我们更全面地了解总体日志内容,并将各可视结果同日志关联起来,以上就是 Kibana 的 Dashboard 功能。
Dev Tools
接下来介绍 Kibana 里面非常有用的工具 Dev Tools,其实就是可以很方便地在 Kibana 中执行 ES 中的一些 API,比如我们上文讲到的检测有哪些节点在运行: GET /_cat/nodes?v,这样我们就能在 Kibana 中运行 ES 命令了。

另外,Kibana 的 Dev Tools 还有许多的快捷菜单操作,比如 Ctrl + / 可以查看 API 帮助文档,其他的大家可以去自行摸索。
安装与查看插件
Kibana 可以通过插件的方式来提供一些 Kibana 中的特定应用或者增强图表展示的功能,Kibana 安装插件和 ES 非常相似。
输入 kibana-plugin install kibana-plugin install https://github.com/sivasamyk/logtrail/releases/download/v0.1.31/logtrail-7.1.0-0.1.31.zip 就可以下载 LogTrail 插件了。
在 cmd 中输入 kibana-plugin list 可以查看本机已安装的 Kibana 插件。

如果想移除插件可以使用 kibana-plugin remove logtrail 命令来进行移除插件。
到此为止,我们就下载并安装完成 Kibana,并对 Kibana 主要功能进行简单介绍,还介绍了 Dev Tools,大家可以自己在本地进行实践操作下。
目前就差 ELK 三兄弟的最后一个:Logstash,让我们一起学习下。
Logstash 介绍与安装
这部分主要是下载并安装 Logstash,并通过 Logstash 将测试数据集导入到 ES 中。
话不多说,首先让我们来了解下 Logstash 是个啥?
什么是 Logstash?
Logstash 是开源的服务器端数据处理管道,能够同时从多个来源采集数据,转换数据,然后将数据发送到您最喜欢的存储库中。
Logstash 能够动态地采集、转换和传输数据,不受格式或复杂度的影响。利用 Grok 从非结构化数据中派生出结构,从 IP 地址解码出地理坐标,匿名化或排除敏感字段,并简化整体处理过程。
数据往往以各种各样的形式,或分散或集中地存在于很多系统中。Logstash 支持各种输入选择 ,可以在同一时间从众多常用来源捕捉事件,能够以连续的流式传输方式,轻松地从您的日志、指标、Web 应用、数据存储以及各种 AWS 服务采集数据。
再了解过后,让我们去下载安装 Logstash。
安装 Logstash
还是来到 Logstash 的官网,进入到下载页面 https://www.elastic.co/cn/downloads/logstash,下载的时候注意要和 ES 和 Kibana 的版本相同,这里下载的为 7.1.0 版本 logstash-7.1.0.zip。
下载后进行解压,也可以进入 conf 目录下修改 logstash.conf 进行配置,运行的时候可以通过指定配置文件 logstash -f logstash.conf 就可以执行数据的插入和转换的工作。
再安装完成之后,让我们来使用 Logstash 往 ES 中导入数据。
用 Logstash 导入 ES
下面我们来导入测试数据集,首先修改 logstash.conf 文件,内容为:
input {
file {
path => ["D:/SoftWare/logstash-7.1.0/csv/movies.csv"]
start_position => "beginning"
sincedb_path => "D:/SoftWare/logstash-7.1.0/csv/null"
}
}
filter {
csv {
separator => ","
columns => ["id","content","genre"]
}
mutate {
split => { "genre" => "|" }
remove_field => ["path", "host","@timestamp","message"]
}
mutate {
split => ["content", "("]
add_field => { "title" => "%{[content][0]}"}
add_field => { "year" => "%{[content][1]}"}
}
mutate {
convert => {
"year" => "integer"
}
strip => ["title"]
remove_field => ["path", "host","@timestamp","message","content"]
}
}
output {
elasticsearch {
hosts => "http://localhost:9200"
index => "movies"
document_id => "%{id}"
}
stdout {}
}
测试数据集来自 Movielens :https://grouplens.org/datasets/movielens/,大家可以前往下载。配置文件中的 path 根据自己下载的测试文件路径去修改。另外,配置文件的逻辑将在以后的文章中进行讲解。
现在来执行命令 logstash -f logstash.conf 来把数据导入 ES。当看到数据打印到控制台时,数据也正在被写入 ES 中。

到此为止,我们就成功安装了 Logstash,并通过 Logstash 将测试数据集写入 ES,同时我们的 ELK 实时日志分析平台就搭建完成了。
补充
在通过 Logstash 将测试数据集写入 ES 后,小伙伴会发现 movies 索引状态为 yellow,不用担心,yellow 代表有副本分片没有被分配。
因为只在本机之启动了一个节点,而 movies 的索引设置了一个主分片一个副本分片,主副分片是无法分配在一个节点上的。
解决方法:修改索引 setting,将副本 replica 设置成 0,或者为集群增加一个节点,状态就会变为 green。
总结
本文主要了解了什么是 ELK,然后通过实际操作和大家一起搭建了一个 ELK 日志分析平台,如果在搭建过程中有什么问题,欢迎留言交流讨论。
如果 ELK 安装包或者测试数据集下载速度慢的话,可以在【武培轩】公众号回复 elk资料即可获得。
参考文献https://www.elastic.co/guide/...
https://www.elastic.co/guide/...
Elasticsearch核心技术与实战

