
人脸检测是一个很常用的算法,可应用在许多业务中,可为应用提供人脸所在图片区域的坐标信息,一般用(xmin, ymin, xmax, ymax)的坐标格式进行描述。本文我们给大家介绍的BlazeFace是一个非常轻量级的人脸检测器,其在许多嵌入式设备中都可以达到超实时的效率,在一些性能较好的手机gpu中甚至可达亚毫秒级(文中在某果手机中进行了该实验)。笔者复现了该算法,在RK3399开发板中,使用阿里开源的MNN进行移植,CPU上的inference仅耗时10ms,性能相当强劲。下图为其在各个设备上的耗时,基于MNN的测试代码见GitHub。
首发:https://zhuanlan.zhihu.com/p/73741766
作者:张新栋
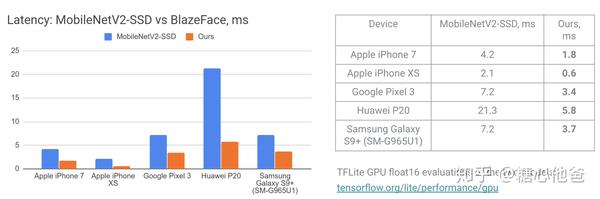
BlazeFace在各个平台的推理速度
下面我们来跟大家分析讨论一下该算法模型的设计。我打算从两个方面去给大家说说该算法,第一个是骨干网络的设计,第二个是检测回归器的设计。
- 骨干网络设计
首先我们先看看骨干网络,其骨干网络设计的出发点很简单,就是快准狠!第一,模型的表达能力要够用;其次,推理的速度要快。目前能同时满足需求的骨干网络有MobileNet系列、ShuffleNet系列、SqueezeNet系列等,由于BlazeFace是谷歌的工作,其大概率会继续MobileNet进行改进。
熟悉MobileNet工作的同学可能会比较清楚,如果你想加速MobileNet骨干网络的前传速度,我们可以通过调节depth multiplier的方式,这里我们假设输入的尺寸不变。我们做工程如果这么去设计无可厚非,回归到论文写作本身上看,这么做的贡献是不够的。我们先来看看论文作者的骨干网络的模块设计,如下图
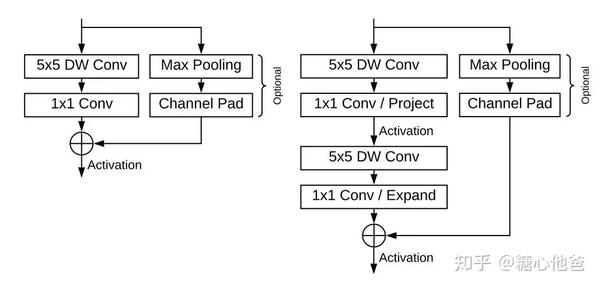
左: single blaze, 右: double blaze
作者区别于MobileNet的模块设计,使用了更大感受野的depthwise convolution配合1x1卷积核来进行特征提速。因为作者在实验中发现,1x1卷积核的开销实际上要大于depthwise convolution。作者在较低层次的特征提速中,第一通过增加depthwise conv的感受野,用以增加特征的提取能力;第二降低1x1卷积核的输出通道数,用以提升推理速度,作者称其为single blaze。
在高层次的特征提取中,MobileNet的处理是对应增加1x1卷积核的通道数,depthwise conv亦同理。该方式虽然可较好的对高层次的特征进行提取,但会引入较大的计算量,MobileNet到最后几层的输出通道数达1024,这在嵌入式设备中是一个不小的计算量。更直接一点,大家肯定会想到的方法就是减少1x1的卷积输出通道数,但是又会造成模型表达能力的减弱。为了克服这个问题,作者沿用之前的思路,采取大感受野的depthwise conv配合小维度的1x1卷积核。不过作者这里做了一个小改动,采用了嵌套single blaze的方式来增加模型的表达能力。仔细观察上图可以发现,其在第一个single blaze的输出为24,而在第二个single blaze的输出为96。相比于MobileNet动则256、512、1024的1x1卷积核输出通道数,作者仅仅用了一个24和一个96的1x1卷积核就完成了操作。在相同的模型层数下,BlazeFace的网络大小要小于MobileNet很多,速度上也会快上不少。作者的实验中可以看出,在正脸检测的任务上略优于MobileNet SSD,同时速度是其约4倍,非常优秀。
- 检测回归器的设计
检测回归器的设计,作者主要还是参考了SSD的工作。由于该算法主要需处理的任务为正脸的检测,其anchor在大多数的情况下,使用比例为1.0的anchor即可以得到很好的效果。相比于传统的SSD通过级联6个尺度下的特征(本文作者实现的MSSD级联了4个尺度下的特征),BlazeFace仅仅级联了2个尺度的特征进行人脸检测,且在16x16特征下每个点仅采用2个anchor,在8x8特征下每个点采用6个anchor,在数据分布不复杂的情况下,既能解决问题,又可以提升网络推理的速度,一举两得。
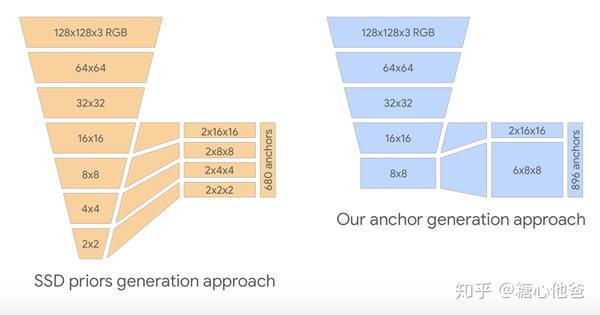
左:MSSD网络结构,右:BlazeFace网络结构
- 最后
BlazeFace是一个非常高效的人脸检测器,其在近距离正脸场景下的人脸检测任务的表现中非常优异,既可以保证检测的准确性,又有很快的推理速度,非常适合部署于嵌入式设备中。后续我们会再写一篇文章,给大家介绍如何用tensorflow来实现BlazeFace,并借助MNN进行端上设备的网络推理加速。欢迎大家留言讨论、关注专栏,谢谢大家!
- 参考
推荐阅读
专注嵌入式端的AI算法实现,欢迎关注作者微信公众号和知乎嵌入式AI算法实现专栏。

更多嵌入式AI相关的技术文章请关注极术嵌入式AI专栏。

