
GAN 论文阅读笔记!共六篇,本文为第一篇。
来源:https://zhuanlan.zhihu.com/p/56861824
作者:林小北
生成式对抗网络(_GAN_, Generative Adversarial Networks )毫无疑问是近几年来较为火热的生成模型。其核心思想非常简单:引入对抗的概念,让两个网络——生成器网络(Generator)和判别器网络(Discriminator)互相对抗。
0. 符号定义
在介绍GAN之前,先简要介绍一下符号定义和必要的概念。
记生成器为




KL散度(Kullbakc-Leibler divergence)常常用来刻画两个概率分布的差异的一种测度,其定义如下:
注意KL散度是不对称的,对KL散度稍加修改即可得到其对称形式,也就是JS散度(Jensen-Shannon divergence):


1. 原理
GAN的原理也非常简单直接:生成器网络根据随机噪声 生成伪造的图片,而判别器网络判断图片真假。判别器的目标是:尽量判断真实图片为真,判断判别器伪造的图片为假,提高判断真假的准确度。生成器的目标是:尽量让伪造图片看起来真,降低判别器的准确度。
2. 从零推导GAN
基于这个对抗的思想,很自然地就能推导出原始GAN的公式了。
首先考虑判别器D的公式,这是一个二分类问题,那么熟悉机器学习的同学很容易想到采用交叉熵损失函数作为判别器的优化目标。令 为图片 为真实的概率,那么其损失函数为

接下来考虑生成器G的公式,G的目标是与判别器D唱反调,既然D的目标是最小化 ,那么G的目标就设定为最小化 ,也就是

综合起来,我们就得到了原始GAN的标准公式:

3. GAN的性质
我们靠着“对抗”的思想,就得到了GAN的公式,那么这个公式到底有没有数学依据呢?在原始的GAN论文中,证明了在一定假设条件下,GAN能够使得生成器G(z)生成的数据分布
首先,对于固定的生成器G,我们总能找到一个最优的



把

也就是说,如果D对于所有的G都能够迅速变化为最优判别器 ,那么,生成器G实际上是在最小化真实数据分布 与伪造数据分布 之间的JS散度。当JS散度为0的时候,两个数据分布也就重合了。
所以,基于这个理想的假设——“完美的D”,GAN的结论看起来非常漂亮!仅仅依靠这种简单的对抗思想,就可以让生成器生成的数据分布接近真实分布。
然而,现实中GAN的应用,却不可避免地会出现两类问题,一是梯度消失,二是模型坍塌。梯度消失,顾名思义,就是损失函数对生成器和判别器的参数的梯度变为零导致GAN无法收敛;模型坍塌,则是指生成器生成的图像局限于某一小的区域,对输入的噪声不再敏感,失去了生成图片的多样性。关于前者,引发了以WGAN为代表的广泛的讨论,也是我后面的阅读笔记会详细讨论的;关于后者,目前似乎还没有比较权威的解释,建议对GAN有比较深入的理解后再阅读这一篇博客 《Mode collapse in GANs》。
4. GAN另一种形式
观察下图
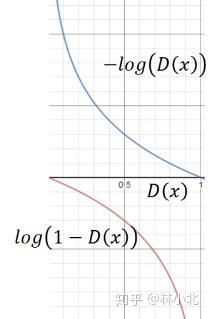
对于标准的GAN,一般在算法刚开始的时候,也就是判别器D能够很好地区分真实数据分布



这个改进思路,也可以从原公式推导得到。如前面所说,D的损失函数

G要与D(x)唱反调,有两种思路:
第一种是与D(x)取相反的损失函数,也就是刚才推导标准GAN的结果,G的损失函数为

第二种是交换真实数据和伪造数据的位置,然后取和D一样的损失函数,这是上面提到的改进形式,此时G的损失函数为

5. 总结:
原始的GAN有如下三个要点:
(1) D刻画了
(2) 原始的GAN,D(x)表示的是数据x真实的概率,为此D(x)的值域是[0,1]。
(3) 原始的GAN,采用的是logistic分类器作为D的结构。
那么,对应地,我们也该有这些思考:
(1) D(x)的值域一定要是[0,1]吗?如果 D(x)表示的是数据x真实的程度,而不是概率的?
(2) 除了logistic分类器,我们还有别的二分类器选择吗?
(3) 对于所以的G,我们是不是总能以很低的代价,找个一个完美的D?
参考论文:
Generative Adversarial Networksarxiv.org
参考链接:
马天猫Masn:GAN原理学习笔记zhuanlan.zhihu.com
推荐阅读
更多深度学习,GAN相关论文阅读笔记请关注深度学习论文阅读笔记专栏。
关于作者林小北:毕业于清华大学自动化系,京东算法工程师。
欢迎关注知乎专栏:https://zhuanlan.zhihu.com/c_1080771046889623552

