
GAN 论文阅读笔记!共六篇,本文为第四篇。
来源:https://zhuanlan.zhihu.com/p/58778284
作者:林小北
在学习完GAN和WGAN的原理后,总结出GAN的套路如下:用判别器D去区分真实的数据分布

在原始GAN中,当D达到最优时,这个差异为两个分布之间的JS散度;在WGAN中,当D达到最优时,这个差异为两个分布之间的W距离。除了JS散度和W距离之外,还有别的选择吗?
答案是肯定的:LSGAN(Least Squares GAN,最小二乘GAN)把判别器的损失函数改成最小二乘损失函数,得到Pearson
1.梯度消失与Sigmoid
WGAN认为原始GAN梯度消失的原因在于:当真实数据分布与伪造数据分布没有重合的时候,JS散度会变成一个恒定值进而导致梯度。
个人认为,梯度消失的一大原因在于原始GAN的判别器用概率描述样本的真实程度。为了描述概率,原始GAN的判别器最后一层采用sigmoid层把D的值域映射到[0,1]区间。而sigmoid函数的曲线如下:
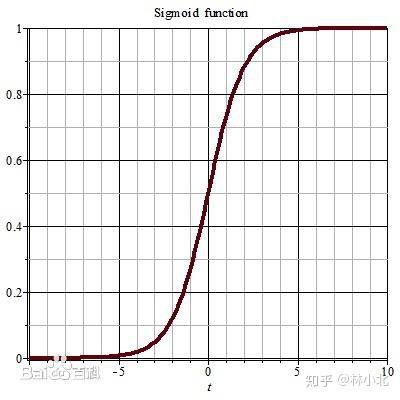
可以看出,sigmoid存在变化平缓的区域。当判别器总是把样本数据映射到这片区域的时候,将会导致对生成器的梯度变得很小。
WGAN改变了思路,D(x)不再描述x真实的概率,而改成描述x真实的程度。这样子,D(x)的值域不再局限于[0,1],这也可能是WGAN收敛性优于原始GAN的原因。
2. Least Squares GAN
有了上面的理解,就很容易理解LSGAN的原理了。与WGAN一样,LSGAN的D(x)不再描述x真实的概率,而改成描述x接近真实/虚假的程度。

3. f散度

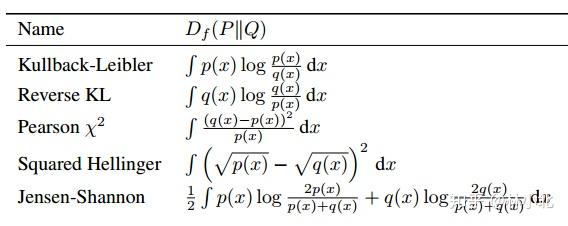
4. 从f散度到f-GAN
与WGAN类似,要把f散度用到GAN里面,问题核心就在于如何利用判别器D得到f散度。


5. 总结与思考
在理解WGAN和f-GAN后,我们能够很好地回答对GAN的疑问:
(1) D(x)的值域一定要是[0,1]吗? 不一定! 比如在WGAN中我们使用D(x)表示的是数据x真实的程度,此时D(x)的值域为实数域。
(2) 除了logistic分类器,我们还有别的二分类器选择吗? 当然!在LSGAN中我们采用线性分类器来区分真假数据也完全没有问题,f-GAN甚至则从散度的角度花式批发GAN。此外,说到分类器就不得不提到SVM。基于SVM的思想,也能对GAN进行改造,参见下一篇笔记。
参考链接:
Least Squares Generative Adversarial Networksarxiv.orgf-GAN: Training Generative Neural Samplers using Variational Divergence Minimizationarxiv.orgf-GAN简介:GAN模型的生产车间 - 科学空间|Scientific Spaceskexue.fm
推荐阅读
更多深度学习,GAN相关论文阅读笔记请关注深度学习论文阅读笔记专栏
关于作者林小北:毕业于清华大学自动化系,京东算法工程师
欢迎关注知乎专栏:https://zhuanlan.zhihu.com/c\_1080771046889623552

