
时隔一年,终于有机会再攒一颗芯片。这一次,是热点中的汽车芯片。
记得两年前,在中国找不出几家做前装汽车芯片的公司。而两年后的今天,突然如雨后春笋般的涌现出十多家,其范围涵盖了辅助驾驶,中控,仪表盘,T-Box,网关,车身控制,电池管理,硬件加解密,激光雷达,毫米波雷达,图像传感器和图像信号处理器等,八仙过海各显神通。
全球范围内,汽车芯片一年销售额大致是$400亿,其中数字芯片$100亿:信息娱乐(中控)芯片约$25亿,均价在$25;MCU约$60亿,30亿片,均价$2;辅助驾驶约$17亿。全球一年大约卖一亿辆车,每辆车平均$100的数字芯片。其中辅助驾驶芯片处于快速增长阶段。汽车芯片的主要供应商,恩智浦,瑞萨数字部分较多,英飞凌,德州仪器模拟部分较多。汽车芯片是仅存的几个利润还不错的市场,技术门槛也并非不可逾越,更不存在绝对的生态闭环。只是量没有消费电子那么大,一年出个几百万片就不错了。在这个领域里,新造车势力方兴未艾,传统造车势力追求差异化,又赶上5G,自动驾驶与人工智能的热点,于是汽车芯片成了继虚拟现实,矿机,NB-IOT,人工智能之后新的投资方向。
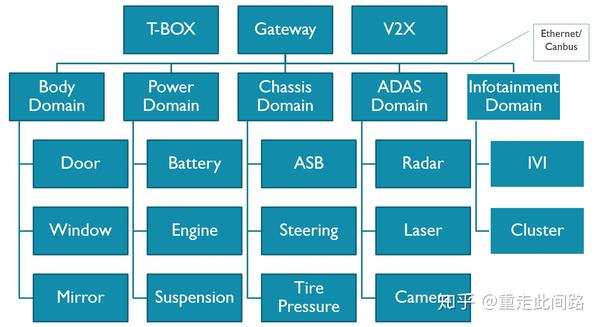
上图是一个典型的汽车电子系统框架。这个系统分为几个域,车身,动力总成,底盘,信息娱乐,辅助驾驶,网关和T-Box。每个域有着各自的域控制器,通过车载以太网和Can总线互联。我们就以架构上最复杂的中控和辅助驾驶芯片为例,展开探讨其设计思路与方法。
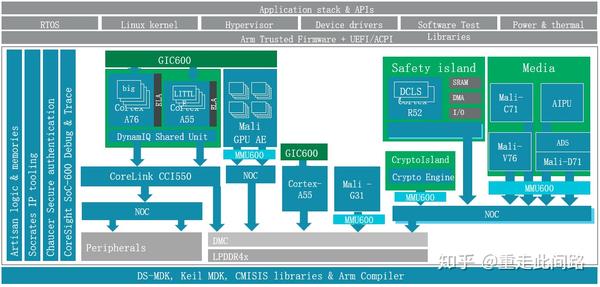
新一代的中控芯片的架构如下图,主要由处理器,图形处理器,多媒体,图像处理,安全(Security)管理,功能安全(Safety),片上调试和总线等子系统构成。它和通常的应用处理器区别主要在于虚拟化,功能安全,实时性和车规级电气标准。
先说虚拟化。虚拟化其实是从服务器来的概念,为什么汽车也会有这个需求?两点原因:现在的中控芯片有一个趋势,集成仪表盘,降低成本。以前的仪表盘通常是用微控制器做的,图形界面也较简单。而现在的系统越来越炫,甚至需要图形处理器来参与。很自然的,这就使得中控和仪表盘合到单颗芯片内。它们跑的是不同的操作系统,虚拟化能更好的实现软件隔离。当然,有些厂商认为虚拟化还不够,需要靠物理隔离才放心,这是后话,稍后展开。另一个趋势是中控本身需要同时支持多个屏幕,每个屏幕分属于不同的虚拟机和操作系统,这样能简化软件设计,提高软件的可靠性。
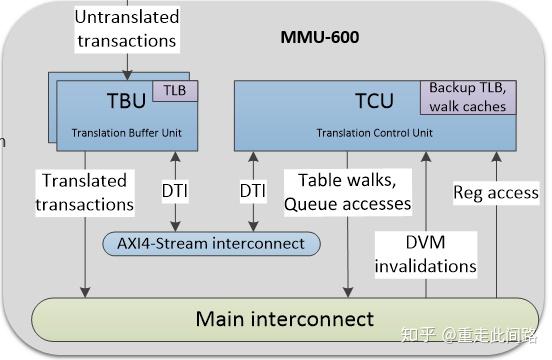
虚拟化在硬件上有什么具体要求?这并没有明确定义。可以依靠处理器自带的二阶内存管理单元(s2MMU),实现软件虚拟机;也可以在内存控制器前放一个硬件防火墙MPU,对访问内存的地址进行检查和过滤,不做地址重映射;还可以使用系统内存管理单元SMMU实现完整的硬件虚拟化,这是我们要重点介绍的。
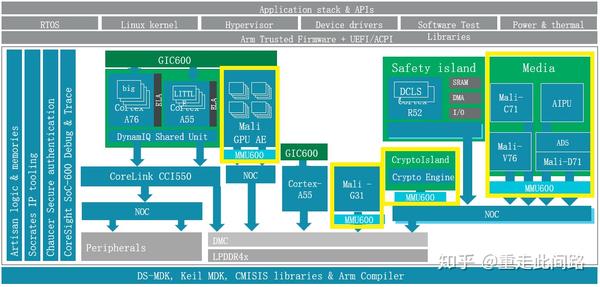
如上图黄色框所示,每个主设备和总线之间,都加了一个SMMU600。为什么每个主设备后都要加?很简单,如果不加,那必然存在安全漏洞,和软件虚拟化无异。那为何不用MPU?MPU的的实现方法,通常是用一个片上内存来存放过滤表项。如果做到4K字节的颗粒度,那4G字节内存就需要1百万项,每项8位,总共1MB的片上内存,这是个不小的成本。另外一个原因是,MPU方案的物理地址空间对软件是不透明的,采用SMMU对上层软件透明,更贴近虚拟化的需求。
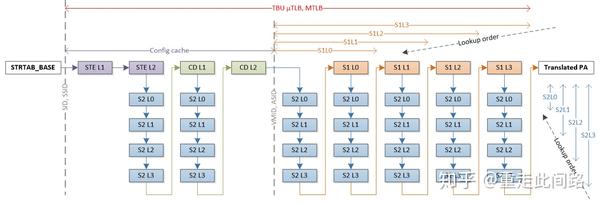
当处理器发起一次地址虚实转换请求,MMU会在内部的TLB缓存和Table Walk缓存查找最终页表项和中间表项。如果在内部缓存没找到,那就需要去系统缓存或者内存读取。在最差情况下,每一阶的4层中间表可能都是未命中,4x4+4=20,最终会需要20次内存读取。对于SMMU,情况可能更糟。如上图所示,由于SMMU本身还需引入多级描述符来映射多个页表,最极端情况需要36次的访存才能找到最终页表项。如果所有访问都是这个延迟,显然无法接受。
Arm传统的设计是添加足够大的多级TLB缓存和Table Walk缓存,效果如下:
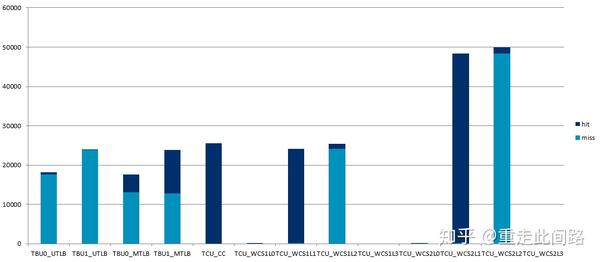
这是启用2阶地址映射后的实测结果,其各项缓存大小均配置成较大,然后把两个主设备连到接口,进行地址较为随机的访问。可以看到,主设备的5万次访问,在经过SMMU后,产生了近5万次未命中。这意味着访问的平均延迟等于访存延迟,150ns以上。另一方面,处理器开了虚拟机后,它的随机访存效率,和未开虚拟机比,却能做到80%以上,这是为什么呢?答案很简单,处理器内部的MMU,会把中间页表的物理地址继续发到二级或者三级缓存,利用缓存来减少平均延迟。而SMMU就没有这么幸运,在Arm先前的手机处理器参考设计中,并没有系统缓存。这种情况下,即使对于延迟不太敏感的主设备,比如图形处理器,打开虚拟化也会造成性能损失,可能高达9%,这不是一个小数目。
怎么解决这个问题?在Arm服务器以及下一代手机芯片参考设计中,会引入网状结构总线,而不是之前的交叉线结构的一致性总线。网状结构总线的好处,主要是提升了频率和带宽,并且,在提供多核一致性的同时,也可以把系统缓存交给各个主设备使用。不需要缓存的主设备还是可以和以前一样发出非缓存的的数据传输,避免额外占用缓存,引起频繁的缓存替换;同时,SMMU可以把页表和中间页表项放在缓存,从而缩短延迟。
Arm的SMMU600还做了一点改进,可以把TLB缓存贴近各个主设备做布局,在命中的情况下,一个时钟周期就可以完成翻译;同时,把Table Walk缓存放到另一个地方,TLB缓存和Table Walk缓存通过内部总线互联。几个主设备可以同时使用一个Table Walk缓存,减少面积,便于布线的同时,又不失效率。其结构如下图:
如果我们读一下Arm的SMMU3.x协议,会发现它是支持双向页表维护信息广播的,这意味着除了缓存数据一致性外,所有的主设备,只要遵循SMMU3.x协议,可以和处理器同时使用一张页表。在辅助驾驶芯片设计时,如果需要,把重要的加速器加入同一张页表,可以避免软件页表更新操作,进一步提高异构计算的效率。不过就SMMU600而言,它仅仅支持单向的广播,接了SMMU600的主设备,本身的缓存和页表操作并不能广播到处理器,反过来是可以的。
对于当前的汽车芯片,如果没有系统缓存,那如何减少设备虚拟化延迟呢?办法也是有的。汽车的虚拟机应用较为特殊,目前8个虚拟机足够应付所有的分屏和多系统需求,并且一旦分配,运行阶段无需反复删除和生成。我们完全可以利用这点,把二阶段的SMMU页表变大,比如1GB,固定分配给某个虚拟机。这样,设备在进行二阶段地址映射时,只需少数几项TLB表项,就可以做到一直命中,极大降低延迟。需要注意的是,一旦把二阶映射的物理空间分配给某设备,就不能再收回并分给其他设备。不然,多次回收后,就会出现物理地址离散化,无法找到连续的大物理地址了。
SMMU接受的是从主设备发过来的物理地址,那它是怎么来区分虚拟机呢?靠的是同样从主设备发送过来的vmid/streamid。如果主设备本身并不支持虚拟化,那就需要对它进行时分复用,让软件来写入vmid/streamid。当然,这个软件必须运行在hypervisor或者是secure monitor,不然会有安全漏洞。具体的做法,是在虚拟机切换的时候,hypervisor修改寄存器化的vmid/streamid,提供输入给SMMU即可。如果访问时的id和预设的不符,SMMU会报异常给hypervisor。
如果主设备要实现硬件的方式支持虚拟化,那本身需要根据多组寄存器设置,主动发出不同的vmid/streamid。为了对软件兼容,可以把不同组按照4KB边界分开,这样在二阶地址映射时,可以让相同的实地址访问不同组的寄存器,而对驱动透明。同时,对于内部的资源也要做区分,不能让数据互相影响。如果用到缓存,那缓存还必须对vmid敏感,相同地址不同vmid的情况,必须识别为未命中。
如果主设备本身不支持虚拟化,并且本身特别复杂,那还需要定制驱动。以Arm的图形处理器为例,到目前为止,硬件上还没有正式支持虚拟化,如果软件要支持,可能会有以下几种方案:
假设我们用的Hypervisor是Xen,它运行于Arm处理器的EL2,虚拟机运行于EL0/1。正常的图形处理器驱动会分成用户空间与核心空间两部分。要实现虚拟化,时分复用图形处理器,Xen上本身不可能跑驱动,因为目前驱动只支持Linux。所以就只能让虚拟机来跑原先的驱动,而没有办法在Hypervisor上再运行一个驱动来进行访问控制。同时,重映射图形处理器在CPU上的二阶段地址,让寄存器访问和数据通路处于‘穿透’的模式,不引起异常,提高效率。相应的,让虚拟机直接访问寄存器,那访问控制就实现不了了。为了实现多虚拟机的调度,我们可以在Hypervisor里面实现一个调度器,并且在核心态的驱动部分开放接口,让Hypervisor可以主动调度。示意图如下:
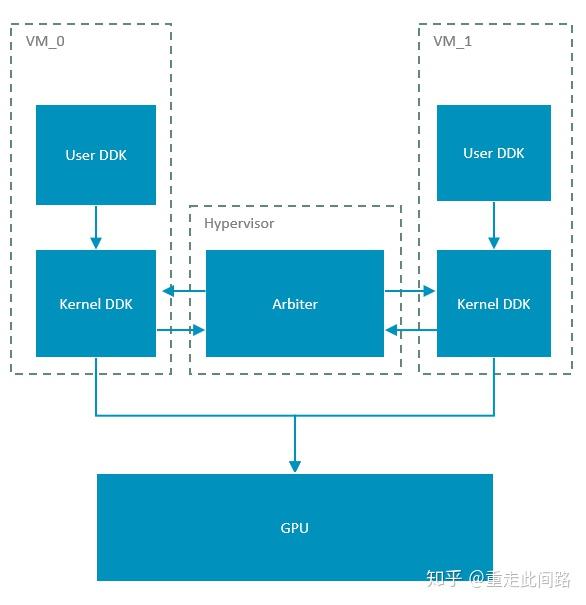
这个实现的优点很明显,改动较少,实现简单,无论是Xen和KVM都可以适配。缺点是主动权并不掌握在Hypervisor,如果某个虚拟机上渲染任务过于繁重,一直不把控制权交给调度器,那只有强制重启。另一个明显的缺点是,无法在图形处理器同时运行两个虚拟机上的任务。这就需要另一种虚拟机的实现方式,如下图:
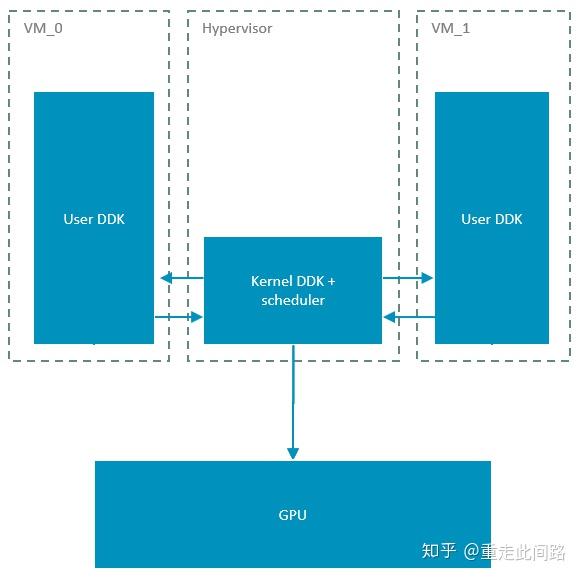
在这种实现下,虚拟机里只跑驱动的用户空间,所有涉及核心空间的调用全都扔到Hypervisor。这要求Hypervisor本身是Linux,只有KVM符合这个要求。Arm的Mali图形处理器,硬件上是支持指定某个渲染核心跑特定任务的,也就是可以把某个虚拟机的任务运行在特定渲染核心的。这样,如果有实时性的操纵系统要跑,比如仪表盘,可以保留出一个核来,不被其他虚拟机抢占,来实现一定程度的QoS。此时,图形处理器是真正同时跑两个虚拟机任务的,而不是时分复用。至于输出的frame buffer,不同的任务是可以放到不同物理地址的,只是没法区分SteamID,没法做隔离。
Arm支持硬件虚拟化的图形处理器估计还要一年才会出来。具体到细节,虚拟化除了需要寄存器分组,缓存对vmid敏感之外,通用的一些单元也需要支持分组。
关于虚拟机的效率,还有两点需要注意:
Arm现有的中断控制器GIC600,受限于GICv3.x协议,是没有办法绕过Hypervisor,直接把虚拟中断送到Guest OS的。外部中断送进来,还是得经由Hypervisor权限设置寄存器,产生一个虚拟中断到Guest OS。中断直接送到Guest OS要到GICv4才会改进。
Armv8.1及之后的CPU,都支持一个叫VHE的机制,可以加速2型虚拟机的切换。具体原理是,KVM等2型虚拟机,Hypervisor就在Linux核心里面,而Linux需要完整的2阶3/4层页表。另外一方面,Armv8.1之前的处理器EL2没有对应的页表。如果没有VHE,那这个Hypervisor必须把一部分驻留在EL2做高权限操作,而Host Linux还是运行在EL1。这样,很多操作需要从EL1陷入EL2,改完再回到EL1的Linux核心,多了一层跳转。有了VHE,那么Host Linux核心直接运行在EL2,可以操作EL1的4层页表的页表寄存器,软件上不用做修改。硬件上,这些访问会被重定向到EL2,以保证权限。
对于1型虚拟机,比如Xen,这个改动没有影响。这里我们要提一下QNX的虚拟机,它是1型虚拟机。QNX是目前唯一一个能达到Asil-D等级的操作系统(包含Hypervisor)。如果需要实现Asil-D级别的系统,必须把现有的软件从Linux系统移植到QNX。所幸的是,QNX也是符合Posix标准的,尤其是图形处理器的驱动,移植起来会省事一些。QNX不是所有的模块都是Asil-D级,移植过去的驱动,其实是没有安全等级的。QNX依靠Asil-D级的核心软件模块和Hypervisor,保证99%以上的失效覆盖率。如果子模块出了问题,那只能重启子模块。
前面说到,有些厂商认为虚拟化还不够,有些场景要物理隔离。虚拟化的时候,硬件资源还是共享的,只不过对软件是透明。这样其实并不能完全防止硬件的冲突和保证优先级。请注意,硬件隔离是Separation,而不是分区Partition,Partition是用MPU来做的。在中控的系统框架图内,我们把采用物理隔离的红色部分单独列出来,如下图:
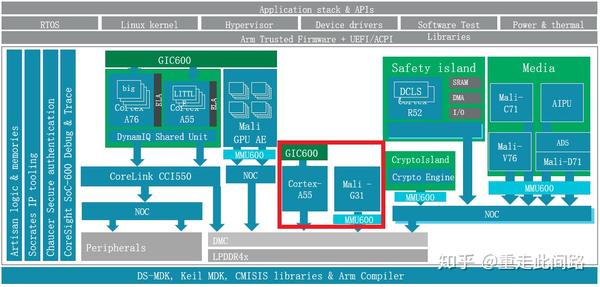
此时的处理器A55和图形处理器G31,独立于作为信息娱乐域的处理器A76/A55和图形处理器G76之外,拥有自己的电源,时钟和电压。作为优化,红色部分可以和其余的处理器用一致性总线连接起来,在不作为仪表盘应用的时候,作为SMP的一部分来使用。而需要隔离的时候,用多路选择连接到NoC或者内存控制器。这样既节省了面积,又实现了隔离。
同样的,图形处理器也有物理隔离的需求。实现其实并不复杂,比支持硬件虚拟化要直接,如下图:
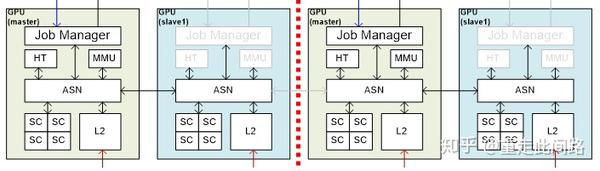
由于图形处理器面积最大的是渲染核心SC,这部分不动。其余的硬件模块,每组核都复制一份,组和组之间用内部总线ASN互联。当拆成多个图形处理器的时候,每个冗余模块分别控制自己的资源。此时,每组GPU需要独立运行一个驱动。而把所有资源融合运行的时候,冗余的部分自动关闭,由一个模块集中调度。此时,某些公用资源可能会遇到性能瓶颈,但汽车通常只会要求物理隔离两个组,分别给仪表盘和信息娱乐,并且仪表盘所需资源较少,融合的时候,可以启用信息娱乐的共享单元,从而避免瓶颈。对于系统中其余的主设备,也可以利用类似的设计思路来实现隔离。
有了同时支持虚拟化和硬件隔离的图形处理器,我们的中控芯片构架会有如下改动:
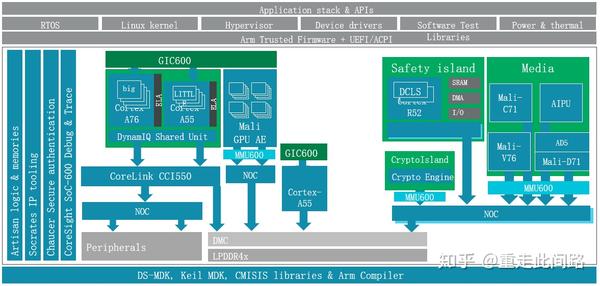
此时图形处理器的物理隔离和硬件虚拟化可以同时启用,跑多份驱动,满足前文的需求。
至此,虚拟化和隔离结束,开始讨论车规。
目前我们说的车规分两个,功能安全和电气标准。前者由ISO26262定义,后者由AEC-Q100定义。
功能安全在芯片上的设计原则是要尽可能多的找出芯片上的失效场景并纠正。失效又分为系统和随机两种,前者依靠设计时的流程规范来保证,后者依赖于芯片设计上采取的种种失效探测机制来保证。我们在这主要谈后者。
简单来说,芯片的失效率,是基于单个晶体管在某个工艺节点的失效概率,推导出片上逻辑或者内存的失效概率。面积越大,晶体管越多,相应的失效率越大。ISO26262把安全等级做了划分,常见的有ASIL-B和ASIL-D级。ASIL-B要求芯片能够覆盖90%的单点失效场景,而ASIL-D则是99%。这其实是个非常高的要求。一个晶体管的失效概率虽低,可是通常一个复杂芯片是上亿个晶体管组成的,如果不采取任何措施,那任何一点的错误都可能造成功能失效,失效率很高。
ISO26262手册第五篇的附件D,详细描述了硬件失效的探测手段。在这部分,硬件系统被分为几个模块:输入端有传感器,连接件,中继,数模接口;处理部分包含处理单元,各类内存闪存。系统层面有总线,电源和时钟。系统框架如下图:
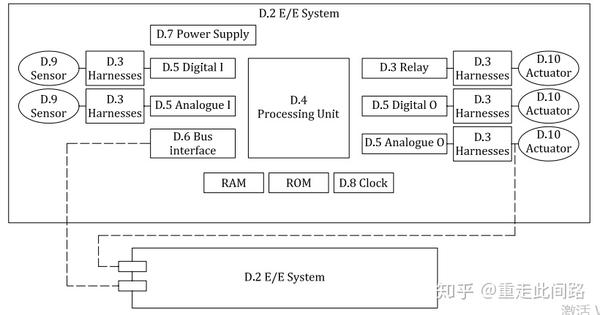
针对每一单元,ISO26262手册定义了一些方法,来检测这些单元是否失效,并给出每一种方法的可靠度。比如传输线,可以有校验码,超时,计数器,发送测试向量等。再比如处理单元,可以使用软硬件自检,冗余加比较,额外硬件模块监测等方法。这些方法并不能简单的应用于芯片功能安全设计。那芯片上怎么办?我们采用自底向上的方法,先从晶体管开始分析,再到IP模块级,然后到芯片系统级,再讨论几个典型场景,最后自顶向下分析。
在芯片的随机错误中,有一类是永久错误,比如逻辑或者片上内存的某一位一直粘在0或者1,或者干脆短路及断路。对于这一类错误,在芯片封测的时候,我们可以使用边界扫描和MBIST来发现坏掉的晶体管。这样,问题就转换为怎样提高DFT的覆盖率。这一块,业界已经有成熟的方法了。
仅仅有出厂测试是不够的,晶体管会在使用过程中慢慢老化损坏。因此,我们需要在每次开机的时候都进行自检,提前发现问题,减少在系统运行状态下出错的可能。此时,我们需要使用LBIST和MBIST。其原理和出厂测试很像,也是利用扫描链,不同的是芯片里需要LBIST/MBIST控制器,用来运行测试向量和模板。自然,这会引入额外的成本。覆盖率越高,成本相应越大。
有了LBIST/MBIST也还不够,我们需要在晶体管失效发生后几个时钟周期就探测到错误,而不是开机时候发现。对于逻辑来说,为了做到这点,最直接的方法莫过于采用冗余设计,也就是把逻辑复制一份,然后用硬件比较器比较输出。通常这被称为锁步设计(Lock-Step)。理论上,对于有限状态机,只要输入一致,时钟周期一致,输出一定一致。通常数字部分不存在真随机单元,哪怕是缓存替换算法,也是伪随机的,所以上述条件可以满足。冗余的结果是逻辑面积增加一倍,比较器也会引入一些额外的面积开销和时序影响。
这么简单就实现了功能安全?并没有,有几个问题需要解决:
第一个问题是,比较器到底比哪些信号?以处理器为例,如果我们只是在对总线的接口上增加比较器,芯片内部的很多模块,比如写缓冲,并不能在较短且确定的时间内把影响传递到对外接口,被比较器发现。此时,处理器可能是处于失效状态而并没有被探测出来。那我们就不能说当前冗余机制能覆盖此类失效。为此,我们需要把比较器连到内部子模块接口处,并且分析是不是能在较短时间内看到影响。这需要在设计阶段就考虑,具体做法如下图:
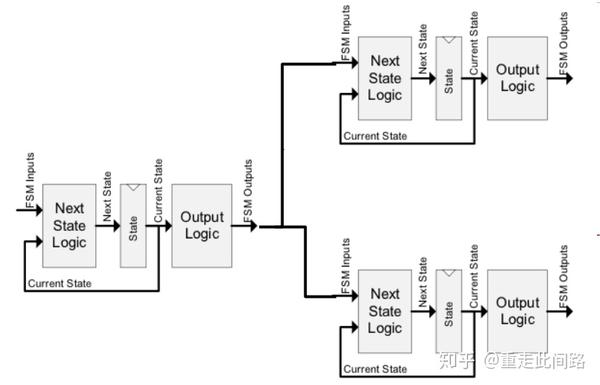
对于任何一个寄存器,一定可以找到影响它的组合逻辑和上一级寄存器。在这条通路上任何一位出了问题,那么在一个时钟周期后,我们就可以看到寄存器输出与其冗余的模块产生不一致。把这个节点记为1,然后再以1的输入寄存器为新起点,找到节点2。依次类推,我们可以往前找出一条没有循环的通路,这条通路上的任何一点发生问题,在确定的较短时间内,一定会在最终输出上反应出来。我们把这个通路记为模块X。通过一定的EDA工具,我们可以在芯片内找出若干个模块X,如下图的例子:
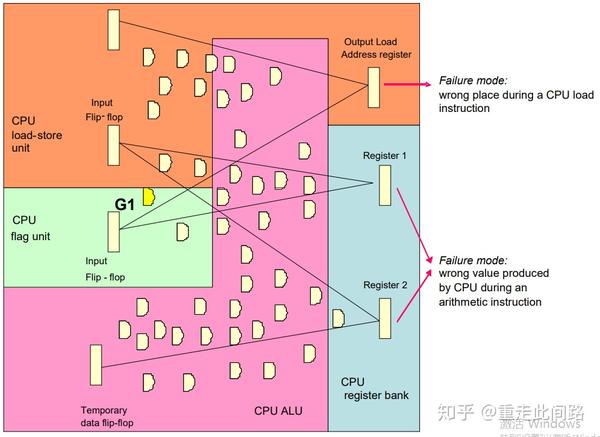
这里,IP模块被划为存取单元(A门),标志单元(B门),计算单元(C门)和寄存器组(D门)。从输出端看,于上一级寄存器间连线所覆盖的组合逻辑为门数,一个寄存器算10个门。如上图,存取单元的地址寄存器输出受24个组合逻辑门外加2个寄存器的影响,那共存在44种单点错误会引起失效。依此类推,寄存器组的1号输出,受28个门影响,而2号受49个门影响。加起来总共121种可能。简单计算可知,存取单元失效率44/121=36.4%,寄存器组合计77/121=63.6%。是其中有些门被统计了多次,比如图中的G1,这一点会反映在总的概率里面。
基于上述的思想,我们来看处理器是怎么做的。在EDA工具的帮助下,我们将它划分为几个大模块:内存管理单元,写缓冲,取指单元,数据处理单元,程序追踪缓冲, 数据/指令缓存,总线接口单元, 时钟和重置控制单元, ECC/奇偶校验控制单元, 中断接口, 监听控制单元。此处,我们没有把片上内存包含进去,即使是讨论缓存,也指的是控制逻辑部分。
每一个单元内,又可以细分成很多子模块。以数据处理单元为例, 又分为通用寄存器组,存取单元,浮点单元,浮点寄存器组,解码单元,调试单元,控制信号单元,系统寄存器组,分支执行单元等。每一个子单元又可以再一次细分。细分的目的是判断在晶体管失效时,受其影响的寄存器是不是会失效,并且这个失效能被外部比较器探测到。这就需要把内部信号拉到外面。那到底怎么决定哪些信号拉出去哪些不拉?覆盖率是不是足够?工具给的节点和模块信息只能作为参考,设计人员还是要一个个检查来做最后决定。通常会有很多信号被拉出来,比如Cortex-R5,20多万门的逻辑,最终送到比较器的信号数达2000多个,平均每100门就有一个信号。
在芯片过认证的时候,如果IP本身没有过经过认证,或者以前没有被广泛采用,认证机构可能会需要一条条的和芯片公司讨论,看看连出来的的管脚是不是能提供足够的失效检测覆盖率。通常这些设计相关的信息,IP公司并不会提供给芯片公司,所以认证公司可能会要和IP设计公司拿这些信息,导致更长的认证时间。相应的,如果是广泛使用的IP模块,这个时间可以缩短。
解决了冗余设计覆盖率的问题,还有第二个问题。如果遭受电磁冲击或者射线影响,即使用了冗余设计,也可能两个模块同一时间产生一样的错误。这个比较容易处理,只要把两个同样的逻辑,输入错开几拍就可以。在输出的时候,错开相同的拍数,使得比较器还是看到相同的结果。
第三个问题,复制了一份逻辑,并且比较器发现了错误,能把他纠正过来吗?很可惜,不能。除非复制两分逻辑,三个同时比较。这样的代价就是再增加原先100%的逻辑部分面积,对于大的处理器设计,基本没人这么做。如果是小的处理逻辑,比如看门狗电路,倒是可以。
第四,逻辑比较器本身,也是可能出错的。这类错误已经被ISO26262定义,也就是所谓的潜藏错误Latent Fault。如果发现比较器本身的失效覆盖率不够,那同样可以对比较器采用冗余设计,做比较器的比较器,提高它的覆盖率。对于Asil-D来说,潜藏错误覆盖率需要达到90%,而Asil-B是60%。
以上都是对于逻辑错误的分析。还有一类是内存错误。这里内存指的是片上内存,也包含嵌入式闪存。内存的错误比较容易发现,通常ECC就可以做到99%覆盖率,1位纠正多位报错。有些内存,比如一级指令缓存,只支持奇偶校验,不支持纠正。
对于逻辑的冗余和内存的ECC,芯片里面需要加入错误注入来机制。请注意,错误注入机制并不是为了验证单点和多点错误失效率,而是为了验证错误探测机制本身是不是能达到设计的要求。
综上所述,逻辑冗余和内存ECC是帮助我们达到Asil-B/D等级的必要手段。没有冗余设计的时候,把一个程序在一个核上运行两遍,然后比较结果,也是一种通向高等级安全的办法,但仅仅适用于简单的,实时性要求不高的运算。如果存在永久错误,这个方法就会失效,需要不断执行在线检测。同样,用两个非冗余处理器同时做相同运算,也是一种方法。但如果计算很复杂,这样做不但会增加系统延迟和带宽,成本也并不低。这两种方法并不能从本质上改善安全等级,如果最终安全等级需要Asil-D,上述方法会要求分解后子模块也得达到Asil-B。而Asil-B的单点90%覆盖率,不用冗余机制同样很难达到。还有一种方法,单路计算,另一路判断其结果是不是合理。作为监测的这一路提高到Asil-D。这只有在特定场景才有可能应用,我们后面会讨论到。所以说,要做通用的Asil-B/D,最好从设计开始就使用逻辑冗余和内存ECC。
实际设计中,特别是对于处理器,在冗余设计之外,还有一套错误发现和纠正机制。Arm把它称作RAS (Reliability,Availability,Serviceability)。RAS并不能代替冗余设计来实现Asilb-B/D,毕竟它的覆盖率太低。但有些场景,比如ECC报错,指令报错,这套机制可以在不重启核心的情况下纠正错误,或者阻止错误在纠正前被扩散(Data Poisoning),又或者记录下错误时的上下文。这是它的优点,在没有冗余设计的芯片里也是有一些用处的。
让我们结合ISO26262文档,来看看Arm的面向汽车应用的IP是怎么实现高等级功能安全的。
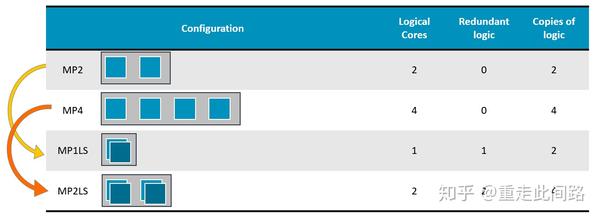
上面是A76AE配置图,也就是面向汽车的A76,它引入了Split-Lock的设计。正常情况下,可以当4核SMP用,在冗余模式下,核心内所有的逻辑和内存都复制两份,互为备份。这两种模式需要重启来进行切换,不能动态切换,对于汽车应用来说足够。核心内部添加的比较器,约占5%的面积,频率也会有5%左右的损失。
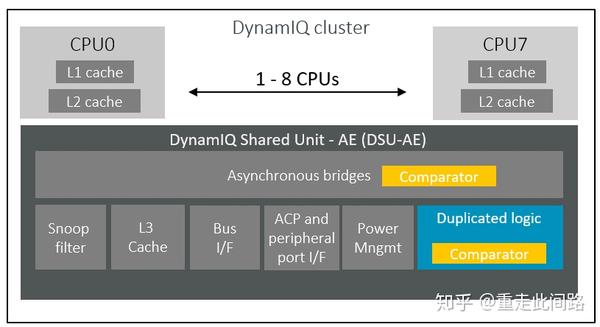
新的A76AE是Armv8.2架构,如上图所示,一个处理器组之内,包含了DSU做三级缓存和内部互联。和核心部分不同,这里采用的是传统的锁步模式,只复制逻辑,内存还是一份。省了大面积的缓存开销。通常DSU里面逻辑只占很小一部分,并且面积利用率还很低,所以最终额外的面积并不大,15%左右。
Arm还有一个支持汽车Asil-D等级的处理器A65AE,可以作为小核,放在不同的处理器组,并和大核通过CMN600AE总线互联,提供高能效比的异构计算。A65AE支持单核双线程,通过增加一个寄存器组,使得两个软件线程可以在一个物理核上共享流水线,并且对软件透明。这其实最初来自于网络处理器的需求,执行单元经常等待高延迟的读传输。为了提高流水线利用率,A65AE增加了5%左右的硬件寄存器,提高了20%左右的总性能。
下图是辅助驾驶芯片里A76AE和A65AE的各种组合。在汽车上,尤其是在辅助驾驶的领域,同样存在同时需要大小核的场景:大核跑决策,单线程性能要求高;小核跑计算,能效比要求高。

接下来看看Arm新的实时处理器Cortex-R52,通常它被当作安全岛来使用,是整个芯片的安全设计基石。在R52上,各种安全机制均有所体现,包括锁步,实时虚拟化,地址分区,内存ECC,总线ECC,在线MBIST,LBIST,在线软件测试库,RAS,如下图所示:
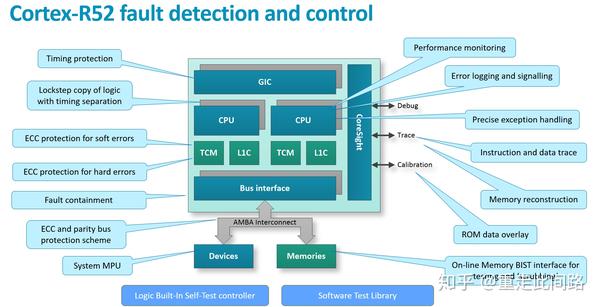
R52的同时支持锁步和Split-Lock模式。锁步模式下,只有一个核,冗余部分仅仅复制逻辑,不复制内存,逻辑就是额外的成本,没法省掉。Split-Lock模式,配置完整的两套核,包括逻辑与内存,平时作为Split模式使用,相当于两个AMP,在进入Lock模式时,其中一套的内存不起作用。此外,由于采用的是MPU的虚拟化,地址并没有重映射,只是多了一层访问检查。这也就意味着地址对软件不透明,不同的虚拟机可以看到别人的地址,只不过没法访问。
R52的最大亮点是实现了实时虚拟化,这是为了软件达到更高的安全等级而准备的。和A系列基于MMU的虚拟化不同,它是在原来的EL1 MPU基础上,添加了EL2 2MPU。同时,为了保证R系列的实时性,避免我们前文提到的SMMU访内延迟极大增加的问题,R52没有采用内存映射,也不转换地址,而是用片上内存,做两层的权限检查。用户可以指定几十个区域,颗粒度可以不同,但是没法做到页表那么多的条数。在R52上,由于没有A系列的EL3,安全启动就需要先进入EL2,然后再建立信任链,流程和A系列类似。
另一个重要的安全设计是支持在线的MBIST和SBIST。在线MBIST原理并不复杂,它在片上内存接口前添加控制逻辑,不断探测是不是有处理器那边发过来的传输。如果没有,那就趁空闲时间读写内存并做测试。SBIST就是针对处理器IP的在线软件测试。我们可以把这个测试运行在某个虚拟机上,通过中断来周期性的切换,花5%的时间来不停检测硬件。当然,必须把虚拟机切软硬件换时间保证在较小范围内,不影响实时任务的调度。
这两种在线测试,可以作为开机自检的补充,也可以作为在锁步/ECC机制但点错误覆盖率不够时的补充,更可以作为发现潜藏错误的补充。但是在高等级的安全设计中,尤其是在安全岛的设计里,仅仅靠这两种在线测试发现单点错误还是不够的,也只能作为补充。
其他方面,R52还对MPU编程做了优化,不是像以前需要针对一个CP15寄存器填,填完再用内存壁垒指令确保写入次序。现在采用多组寄存器方式,基本20-30时钟周期就可以完成虚拟机切换的寄存器编程。此外中断寄存器放到了cluster内部,不用再通过AXI口出去,减少一些延迟。
再来看看中断控制器GIC600AE。以AE结尾的IP表示在原有的基础上做了功能安全设计,可以支持到Asil-D。GIC600AE结构如下图:
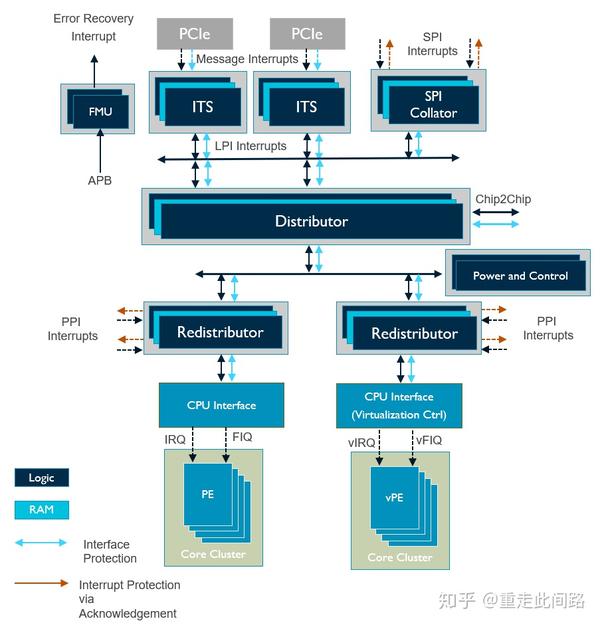
和处理器一样,GIC600AE的逻辑部分是靠锁步来支持Asil-B/D,内存部分是ECC。不同的是,不像处理器是一个单一硬核,GIC600AE是一个分布式的结构,布局布线可以分开,只是在中心有个分配器(Distributor)。每个处理器附近的子分配器(Redistributor)和分配器之间,就需要安全总线协议设计,这就是新的AMBA点对点功能安全扩展:
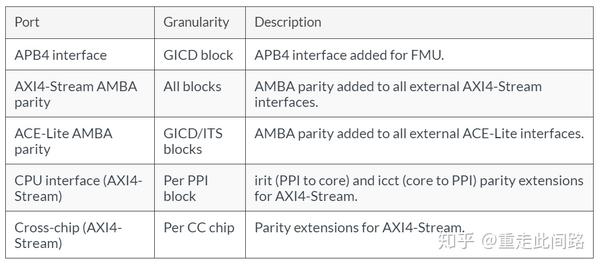
可以看到的是,各类AMBA的地址和数据线,接口上均添加了奇偶校验,这也是ISO26262所要求的传输线安全措施之一;对于重置和时钟,P/Q通道等信号,大多采用复制的方式来保护;而对于AXIS端口,则采用负载加上CRC的方法,免去添加管脚。由于中断控制器不像处理器,可以有中断系统来处理各类错误和失效,因此GIC600AE在分配器中添加了一个错误管理单元,可以把我们所提及的各类错误做集中管理,记录并上报。此外,在分配器与子分配器之间,GIC600AE还添加了看门狗,防止超时未响应。
由于目前GIC600AE还比较新,对于一些老的设计,可能并没有与之匹配的中断控制器可用。这种情况下,就只能把和安全相关的工作用轮询来完成,避免走中断通道。轮询的对象可以是一段ECC保护的内存,也可以是有冗余设计的硬件锁或者外置exclusive monitor。
MMU600AE也是类似的安全设计,在此我们不深入讨论。对于Coresight这样的片上调试系统,由于本身并不涉及安全,它的错误被称作safe fault,不计入考虑范围。 我们接下去看看CMN600AE。
CMN600是Arm服务器总线IP,它最大的特点是网状拓扑结构,对外支持AMBA CHI接口,内部改用路由结构转发数据,并提供硬件一致性和系统缓存,还支持多芯片互联。CMN600在T16FFC上可以做到2Ghz,极大的拓展了带宽,非常适合ADAS这类有大量异构计算的应用。
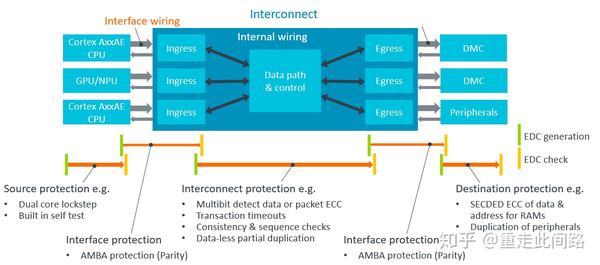
CMN600AE做了功能安全设计,引入了完整的端到端的失效探测机制。如上图,整个总线被分成三类模块,主设备,总线,从设备。主设备与总线,总线与从设备之间,总线内部,会有错误探测编码,也就是EDC。各处的EDC策略可以是不同的。
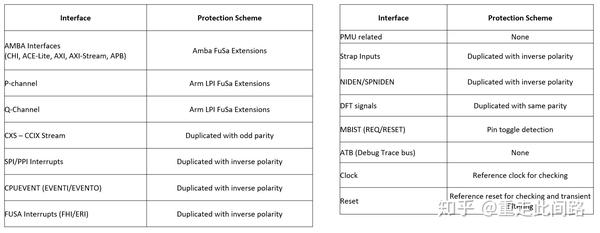
这是主设备与总线,总线与从设备接口处的EDC,和GCI600AE的有些相似,只不过更全。对于一些控制类信号,采用复制的方法,有时候把两根线正负反转;对于数据线和地址线,采取添加奇偶位的做法。
在总线内部,由于网状总线的特点是把传输转成管脚更少的包FLIT传输,所以在每个包后面,加了CRC-8数据作为校验,而不是添加管脚。对于总线处理模块,仍旧采用逻辑锁步和内存ECC来做安全设计。此外,CMN600在传输上加了计数器,如果从设备端超时不响应,那就报异常。
除了锁步,ECC和传输线保护,有一类IP模块设计,可以使用简单一些的方法,来达到一定的安全等级。下图是一个简单的图像信号处理单元,从前到后,流水分别是Raw域,RGB域,YUV域,每个域都包含了各自的子模块。模块之间,包括到DDR的传输,使用传输线安全设计。而子模块内部,如果输出结果是单调递增,单调递减或者在某一区域内的,就可以用带冗余的简单逻辑做硬件监控,来实现Asil-B/D等级。
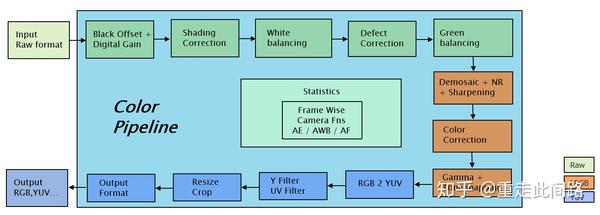
我们取RGB域上的Local Tome Mapping为例。Local Tome Mapping的本意是,对于高动态HDR或者标准动态范围SDR的图,可以把局部的亮度调整到一个合适范围内,效果如下图。基于这个假设,我们可以写简单逻辑,看某个区域的像素是不是颜色保持不变,而亮度和原来比有合理提高。这个简单的逻辑,可以使用锁步来确保高等级功能安全。根据功能安全的功能分解原则,Asil-D可以分解为Asil-D的监控模块和QM的功能模块,这样,还是能保证整个Local Tome Mapping子模块的高安全等级。

以上是IP模块级别对于安全设计的考量,接下来我们谈下模块级实时性设计。
所谓实时性,是在一个确定的,比较小的时间内处理完任务。很多时候,我们其实并不是真的需要实时性,而只是需要一个比较高的平均性能。Arm的R系列专门为严格的实时性设计:确定的几十ns的中断响应时间;紧耦合内存保证流水线在一个时钟周期就能访问指令和数据;内部总线具有QoS保证优先级;不存在页表,MPU做在核心内部,无需外部访问。真实的应用场景可能并不需要纳秒级的响应时间,哪怕是马达控制,系统响应在毫秒级也足够了。而毫秒与纳秒差了1百万倍。这就给了Arm的A系列机会。
A系列最大的不确定性来自于访问外部内存时的延迟。我们前面在讨论虚拟机的时候分析过,最差情况下,一次页表读取,可能需要20倍的访存时间,差不多是3us。为了使A系列有可能用于实时性任务,软件上的优化是必须的,包括虚拟机上下文切换等。硬件上,可以缩短特权级切换时间,也可以采取固定分配来提高页表查找命中率,还可以固定分配某块缓存或者片上内存给某处理器。方法很多,不一一列出。
以上的优化可以减少单个处理单元的延迟。但是复杂系统里有很多主设备,它们之间共享内存和其他从设备,是有可能产生阻塞和死锁的。死锁可以在设计流程过程中通过充分的验证来发现,而阻塞就得靠优先级QoS设计来避免了。下面我们看看CMN600AE是如何处理的。
实时处理最简单的方案是给传输分优先级。芯片中的总线和从设备根据优先级来决定处理次序。但是仅仅采用优先级会有个问题,某些内部资源,比如缓冲,其所有表项已经被低优先级的传输占用了。此时如果来一个高优先级的传输,由于之前的还没有完成,就会出现高优先级被低优先级阻塞的情况。怎么办?可以预先保留相应的资源给高优先级,不被低优先级占用,就不会产生阻塞。
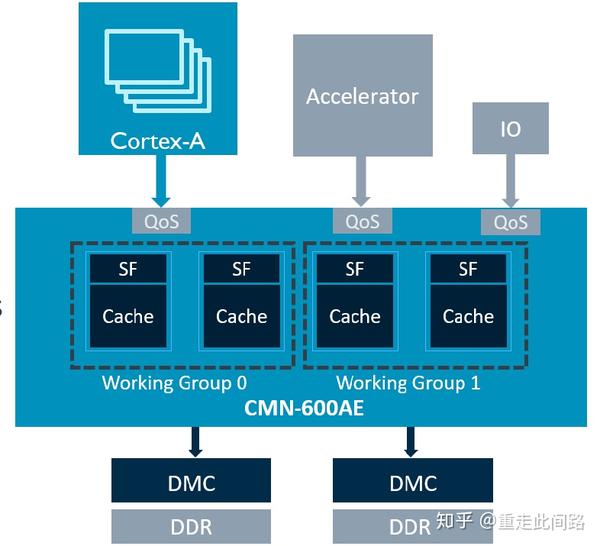
如上图,在每个与主设备的接口处,都有一个QoS模块,里面包含了一个优先级定义,可以被软件编程。这个优先级会随着传输到总线的每一个部分,每个部分都根据优先级来给它相应的资源。有时候,同样高优先级的请求过多,超过了系统资源的承受范围。这时候,CMN600AE的内部模块,会告诉请求传输的模块重传,并给它一个筹码。每请求一次,筹码加一。下次这个筹码就会随着新的请求一起传过来,只要资源有空闲,那么拥有最高筹码的请求将被允许。QoS模块还负责统计它所管理的传输,看看平均延迟是多少,传输间隔是多少,然后动态调整其优先级。
CMN600AE另一个很重要的特性是支持片间硬件一致性互联。对于辅助驾驶芯片,当面积大到一定程度,比如400mm^2@16nm,良率会迅速下跌。这时候,进一步增加面积不是一个好的选择。应对的办法是实现片间互联,减少单个die的面积。当然,实现高速的PHY本身也会引入相当大的面积,TSMC16FFC上一个支持PCIe Gen4x16的PHY就要6个平方毫米,而一个处理器组的CHI接口理论读写带宽可以做到2x256bitx2Ghz=1Tbps,相当于4组x16的PCIe Serdes PHY,24个平方毫米,这等于2组4核A76加DSU的面积。此外,其功耗也是个问题,我没有具体数据,但是根据TSMC16FFC上DDR phy 每10G字节一瓦来看不会低,所以要做好取舍。片间互联还会引入额外的片间延迟,可能要达到50ns。
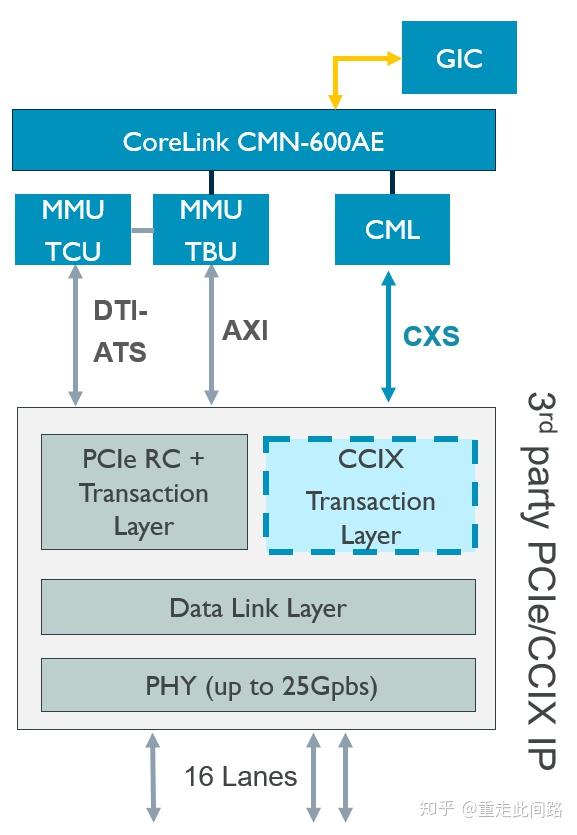
如上图,有了CMN600AE和片间互联协议CML,我们就可以把MMU600AE和GIC600AE全部串联起来,实现片间虚拟化和中断系统,对软件完全透明。其中,MMU600AE访存的实时性靠固定分配虚拟机,以及使用大页表来保证,目的是消除页表项的未命中。对于中断系统的实时性,片内的话使用传统的SPI/PPI,问题不大,片外的话,只能使用PCIe的消息中断机制MSI了。支持消息中断需要ITS表,类似于页表,也存放在内存中,也有类似缓存的设计。只要保证ITS缓存条目足够多,映射的设备数量不太多,也是可以消除未命中,提高实时性的。
以上是关于保证实时性的一些考量。接着来看看AEC-Q100,和芯片设计相关的是温度和电压。
温度设计相对简单,只要工艺允许,标准库和内存单元支持,那只需在做后端时加入温度限制条件即可。现在新的中控和辅助驾驶多用TSMC16FFC,可以支持-40C~150C的节温,相当于环境-40C~125C,其代价是牺牲一定的频率和面积。
ESD测试是对接口的要求,包括2000V+的HBM和6A+的CDM。和封装相关,也和芯片IO设计相关。和数字部分IP一样,PHY和GPIO也需要使用IP来支持AEC-Q100。此处的GPIO指的是200Mhz以下的低速IO,包括但并不限于SPI/PWM/I2C等接口协议。
以GPIO为例,车载设备通常需要支持3.3V和1.8V。为了符合AEC-Q100,GPIO在设计时就能承受额外的电流,并分析各种情况,看看是不是每一条电路分支都能被覆盖到。通常对于车用GPIO,仅仅用仿真来保证设计的可靠度还不够,还必须真正流片,用测试芯片做HTOL/LTOL测试,不断变化温度,做满2600小时。否则,会发生仿真通过但是测试芯片过不了测试的问题。一旦测试失效,那必须做失效分析,看看是哪里的电流承载不了,然后修bug重新流片测试。
同时,GPIO本身同样需要支持功能安全,也就是要加入探测电路,对各类可能产生的失效报警。相对来说,模拟电路失效种类较少,比较容易做到Asil-D。相应的,IP还得提供FMEA和FMEDA报告,供芯片公司过认证。
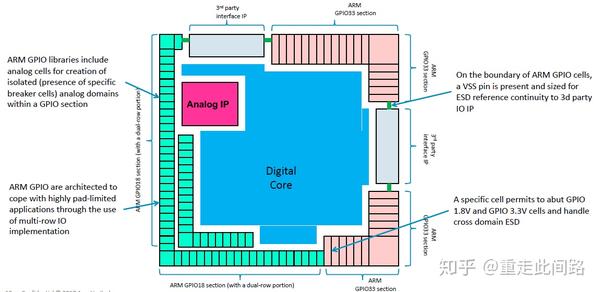
上图是集成在芯片内部的GPIO,集成时,除了要插入一些特殊的单元来完成不同电压的IO模块隔离,还需要注意一定的IO上电次序。
至此,IP模块分析完毕。接下去我们从芯片系统层面开始分析中控和辅助驾驶芯片。
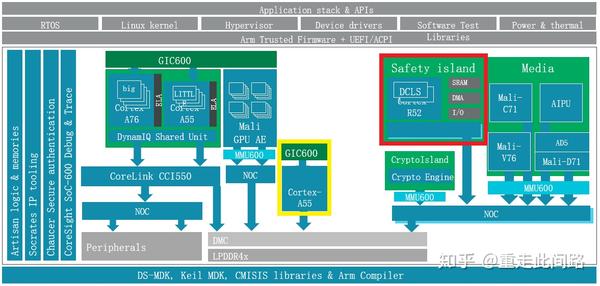
让我们回头看看上面的中控芯片结构图。最重要的是红色框内的安全岛,由R52和紧耦合内存,中断控制器,总线,内存控制器,以及DMA控制器,硬件锁,SRAM等组成。理想情况下,每一个模块都需要是Asil-B/D的。如果做不到,那么至少R52,紧耦合内存和硬件锁做到。由它们构成安全的基石,用来轮询其余模块是否发生故障。同时,这个安全岛还可以作为系统控制器,来控制其余模块的电源,电压和时钟状态;否则,还需要一个Asil-B/D的电源管理的有限状态机来做这件事情,具体可以参考CMN600AE里时钟,P/Q通道和重置信号的设计。
作为信息娱乐域的处理器,多媒体,加解密,总线,中断控制器,调试系统等均无需安全等级,出错不影响驾驶。需要安全等级的是仪表盘,Asil-B级。由于我们这里已经做了隔离设计,所以不需要考虑信息娱乐域的大小核以及其他主设备对其产生的影响。内存控制器虽然是共享的,但只要做好了类似CMN600AE的QoS,保留出相应的资源,也不用担心被低优先级阻塞。
黄色框内作为仪表盘处理器的A55,很难被替换成R52,因为图形处理器通常需要支持MMU的操作系统。此处的操作系统,可以是Asil-B/D级的QNX等,也可以是Asil-B/D级虚拟机之上建立的实时操作系统。另一方面,A55虽然有ECC和RAS机制,但并不支持锁步,很难做到通用场景下的Asil-B等级。至于同样被隔离的图形处理器G31,更没有安全设计。那怎么把仪表盘做到Asil-B?一旦发生故障,比如仪表盘画不出正确的图层,或者干脆不响应,我们可以把A55和G31排除在安全状态之外,让R52驱动外置LED灯告知驾驶员错误信息。这样,就把问题归到了怎样用Asil-D级的安全岛探测错误。这个就相对要简单多了。可以计算每一帧r的CRC,看看是不是连续几帧不变;也可以定期让A55响应中断或者喂狗,又或者同时采用。
在这里,我们引入了一个概念,出错处理。在失效发生后,系统需要在失效容忍时间间隔(FTTI)内进入安全状态。所谓的安全状态,可以是之前的正常运行状态,也可以是应急的处理状态。之前仪表盘的错误警告LED就是一种应急处理的安全状态。
对于锁步设计,最简单的做法就是重置整个逻辑。如果是处理器,那就需要重启相应的处理器核心。而这个重启,必须在失效容忍时间间隔内完成,否则,还是要被视作失效。通常,这个最短容忍时间是10毫秒到100毫秒,和系统应用场景有关。
对于简单的微控制器,100毫秒甚至10毫秒重启并不困难。但对于一个复杂的处理器,重启就是麻烦事了。如果按照传统的开机流程,那几秒钟是需要的,没法符合要求。那我们就只剩下两条路,第一个是使用虚拟机。如果发生失效的并不是Hypervisor所运行的处理器核,可以只重启某个虚拟机来实现加速。对于重要的高实时任务,还可以两个虚拟机跑同一个业务,互为备份,一个出问题那立刻切另外一路;也可以用一个虚拟机待机,看其余哪个虚拟机重启,立刻开始接手那个虚拟机的业务。如果是Hypervisor所运行的处理器核重启,那优化重启过程,保存当前上下文环境至内存,并且尽量调整驱动启动步骤,做到最先使用的主设备优先初始化。可以参考手机上的Suspend To Ram机制,手机基本上可以做到休眠时全芯片下电,数据保留在DDR,唤醒时处理器起来调用显示模块,先显示之前保存的图层,再启动图形处理器渲染新的帧,做到无明显感觉。利用这种机制,对于仪表盘失效,可以先告警,然后在毫秒级的时间内完成相应子系统重启。
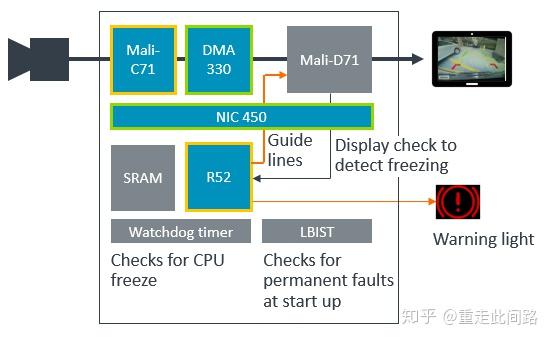
再来看看媒体部分的安全设计问题。上图中是倒车后视的子系统,图像信号处理是C71(Asil-B),R52(Asil-D),总线NIC450(QM),DMA330(QM),SRAM(带ECC),显示模块D71(QM)。子系统要求做到Asil-B等级。由于并不是所有模块都做到了Asil-B,我们需要对其做失效树分析。真正出现失效的场景,在于显示画面冻结在某一帧。瞬时错误引起的一些问题,比如某帧画面有坏点,并不构成失效。因此,我们要做的事情就变成两件:先用R52从显示模块获取每一帧的CRC,看看是不是连续多帧都不变,如果出错,立刻亮灯告警,这个计算必须在失效容忍时间间隔内完成;其次,开机或者周期性运行LBIST/MBIST,看看是不是存在永久错误,有的话也需要告警。只要图像的源头C71有Asil-B,R52高于Asil-B,我们可以放松对其余几个模块探测瞬时错误的要求。
接下来我们看辅助驾驶的芯片框架图,和中控不同,辅助驾驶需要感知和决策,是一个复杂的实时运算过程,没有办法通过安全岛监测来达到高等级安全,只能通过处理器本身来保证。所以这里的处理器全部换成了带冗余设计的A76AE和A65AE。虚拟化在这个系统里并不是必须,MMU600AE仅仅是为了虚实地址转换。由于没有采用虚拟机,各个处理单元之间的数据分区可以靠CMN600AE的MPU来完成。没有经过CMN600AE的设备,需要在和总线之间添加MPU来实行地址保护,并且所有的MPU配置要保持一致。另一方面,使用MPU也限制了分区不能太多,否则就需要映射到内存。到底使用虚拟机还是MPU进行分区需要看应用来决定。另外,如果需要片间互联,那所有主设备都应该通过NoC AE形成子网连到CMN600AE。
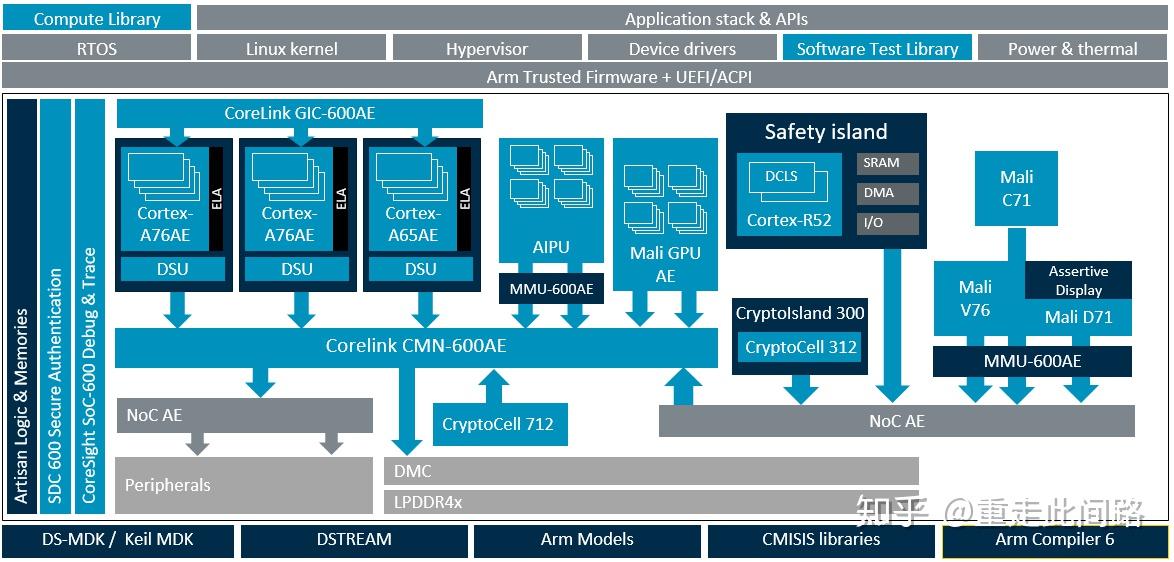
这个框架的计算流是这样的:C71(Asil-B)把数据从传感器收集,做固定的图像信号处理,把结果放到DDR;A65AE读取数据,进行车道检测等传统的矢量运算。相对于大核,A65AE提供了高能效比的运算能力,适合多路并行计算;也可以把任务丢到图形处理器来运算,延迟稍大,能效比也很高。如果涉及神经网络运算,那A76AE会把任务调度到AI加速器上,同时在算子不支持的情况下负责部分计算;也可以把所有神经网络运算调度到图形处理器,这样就不存在算子不支持的问题。当然,对于神经网络计算,图形处理器能效比还是赶不上专用加速器。A76AE作为大核,具有很高的单线程性能,可以用来做辅助驾驶的决策。CMN600AE作为桥梁,连接了所有设备,并提供高带宽,实时性,硬件一致性以及系统缓存。由于总线支持单向硬件一致性,图形处理器和AI加速器从处理器拿数据的时候,处理器不用刷新缓存,从而减少延迟。当然,由于受布线和接口协议限制,有些对延迟不敏感的主设备还是需要通过NoC连到CMN600AE。
最后划一下重点。汽车芯片的关键是实时性,功能安全,电气,虚拟化。功能安全最复杂,需要IP级就开始支持。如果不符合,那需要场景分析做分解,用最少的代价实现安全。至于AI加速器应用,辅助驾驶算法应用就不说了,每家都不一样,这篇只负责搭好汽车芯片的框架。安全防护(Security)也不讨论,和消费电子需求很接近,在之前的的文章中也已经阐述过了。
相关直播视频:新一代汽车芯片架构
授权转自知乎,欢迎关注ARM攒机指南专栏,后续还有AI等相关篇章。

