
Arm在19年5月份新推出的Cortex A77架构,采用TSMC 7nm工艺,3GHz峰值频率,性能提升20%。之前一篇文章介绍过X86最强处理器ZEN的架构,详见。本文基于同样原则来分析ARM架构最强处理器A77,深入探讨其设计方案以及和X86架构的异同。
作者:MikesICroom
原文:https://mp.weixin.qq.com/s/80VgWjbg7vFEUOV0BsHBWw
首先简要介绍下Arm指令集架构。目前通用处理器基本上分为2个阵营,一个是以INTEL,AMD为首的CISC(Complex Instruction Set Computer)指令集,另一个是以Arm为首的RISC(Reduced Instruction Set Computer)指令集。两者之间的主要区别是指令的功能单一性。RISC ISA通常一条指令完成简单独立的一种运算或控制,指令长度固定,格式较为统一。而CISC ISA指令的功能要复杂的多,指令长度可变,格式复杂。由于RISC指令编码和功能上非常有利于硬件实现,处理器发展到今天,不论X86还是Arm,其硬件执行核心已经都是RISC架构了,而X86多了一层将CISC指令 翻译成RISC类微指令的步骤,因此译码部分不但增加了额外的流水线级,实现上也复杂许多,这也是X86处理器功耗大于同级别的RISC处理器的一个重要因素。
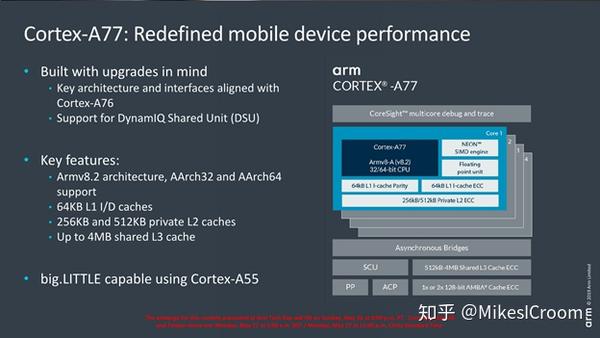
Cortex A77面向移动高性能领域,采用Armv8.2 64位指令集架构。硬件设计上和A76一脉相承,都采用了7nm工艺,峰值频率也没有变化。从这点来看,A77的流水线结构应该和A76是一致的,20%的提升主要在微架构的细节方面,用来提高IPC和并行执行的能力。随着工艺进展到7nm,其单芯片的功耗密度在很大程度上制约着主频的提升。ARM主要面向移动市场,并没有在频率控制上向INTEL看齐,而更加追求单位功耗下的性能比。因此很多设计上并不以频率为首要目标,可以看到其L1 cache size达64KB,甚至超过了ZEN2的32K。其他的如DynamIQ,big.LITTLE等基本都是ARM的标配。
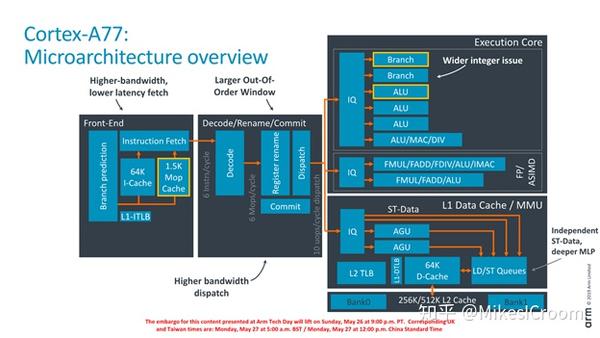
A77的流水线结构没有太大变化,还是标准的physical register Out-of-Order machine。其中有几个值得注意的点。第一个是1.5K entry的Mop Cache。这个在X86上存在了很久的结构终于出现在Arm的处理器中。X86是复杂指令集,引入Mop Cache可以存储解码后的微指令,这样能够直接bypass fetch和decode的流水线,获得更大的dispatch宽度。我们看到这个Mop cache是放在fetch级的,和Icache的结果mux后,统一送给decode模块。如果这个结构正确的话,这个Mop cache的主要目的就是功耗控制和减少branch penalty。Decode级增加到了6条指令,同时拓宽了issue宽度,增加了1个AlU和1个BRU。这样A77的执行单元有4个ALU,2个BRU,2条Load-store pipe。可以看到Apple的处理器设计对Arm还是有很大影响的。在大家都在大幅提高并发能力,推高单核峰值性能的趋势下,Arm也没办法独善其身,继续其极致能耗比的设计。另一个原因可能也和Arm服务器的再次兴起有关,随着华为、amazon推出自行设计的Arm服务器芯片,冷却了几年的Arm服务器市场似乎又热闹了起来。在这种形式下,Arm也需要一款单核性能能和X86阵营较量的处理器,能够推动更多的厂家进入,向X86发起挑战。A77的配置,可以说是兼顾了高端移动市场和入门级服务器市场的需求。

前端流水线,最重要的改动就是增加了Mop cache。假设其宽度和decode数目一致,1.5K的entry就可以存储9千条32位指令,应该可以覆盖大多数移动领域的应用场景。在Mop cache wArmup后,指令可以不经Icache通路,直接从Mop cache发送到decode级,这样整个fetch单元都可以进入低功耗状态。同时其中存储指令译码后的信息,包括分支和循环的预测结果,可以实现zero cycle的hardware loop,进一步提高了循环的执行效率。第三,从Mop取指相当于减少了fetch流水线的长度,这样出现branch misprediction之后,如果新的target也在Mop中,flush流水线的penalty也会降低不少。这里还提了一个Dynamic code的优化手段,似乎是学习了code sequence的相关特征来提高后级执行的能力,具体不知道Arm是怎么做的。
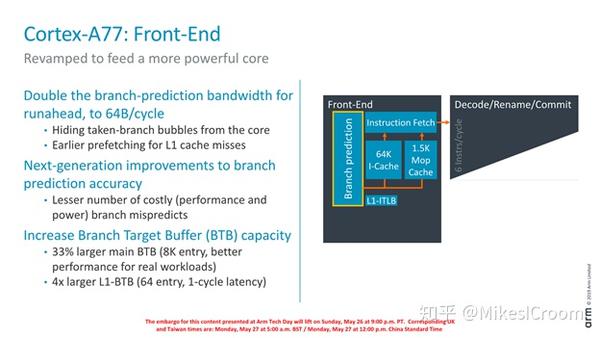
Branch prediction是另一个重点优化的手段。可以看出和ZEN2的方向如出一辙,这也是前端流水线最重要的性能指标。A77拓宽了branch prediction的bandwidth到64B,这样理论上可以同时预测16条32位指令的分支结果。同时也和ZEN一样,大幅增加了BTB的size。可以看到,A77相对于ZEN少了一个L0 BTB,只有2级BTB。由于没有具体的数据,很难说哪个方案更好,应该是根据各自面对的应用场景测试后选择的方案。共同的趋势都是更大的预测器和预测宽度。
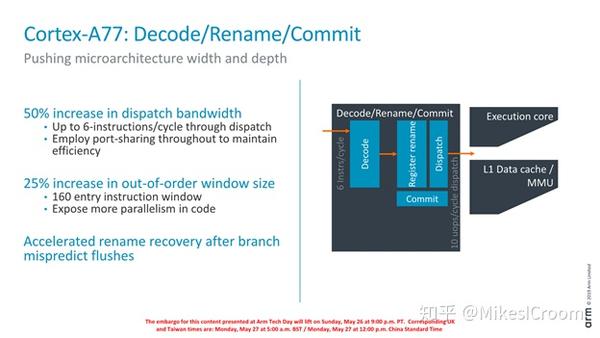
Decode级主要是增加了50%的dispatch宽度,6条指令的并发理论上可以提供更大的并行执行能力。随之ROB的entry数也增加到160个。这里提到了加快renaming table在branch misprediction后的update速度。通常renaming table会在相应branch retire时,恢复到actual renaming的状态。这里提到的accelerate,有可能是提供了多个branch recovery点,可以不等retire,直接恢复到最近的recovery点上。这样硬件复杂度和面积都会增加。由于没有更详细的信息,也只能做上述合理的推测。
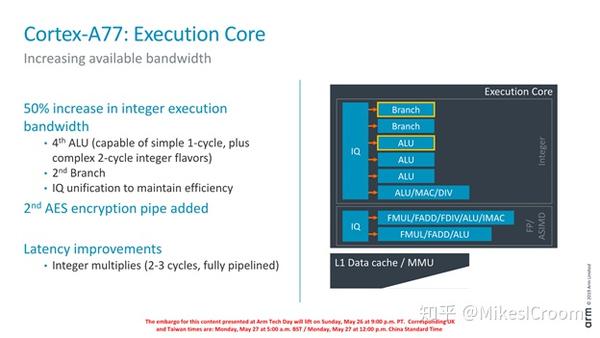
执行单元,主要是数量的增加,向Apple看齐。注意Arm一直保持了single cycle的ALU,这在单核IPC性能上至关重要,ZEN2也保持了这一点。A77采用了Unified Issue Queue,这和ZEN分离式的设计有所不同。一体化的IQ可以带来更好的schedule效果,但会在很大程度上制约频率的提升。这里体现了Arm并不以频率为首要目标,而更多的考虑综合的能耗。另外的变化是增加了crypto流水线,提高AES编解码的能力。对于这一点,作者还是持保留态度。目前对于crypto的加速通常采用专用加速器实现,因为 算法确定,ASIC能获得非常高的加速比,同时硬件代价较小。并且ASIC实现的crypto加速器可以和处理器完全隔离,做到纯硬件的加解密,这样安全级别很高。而用处理器实现,首先性能和功耗有数量级上的差距,其次是指令实现,软件参与度较高,安全性上难以保证。

Load-store流水线,同样采用了统一的Issue Queue。可以看到A77有2个address的path和2个st-date的path,可以同时执行2条存储指令。组合可能是2条load,2条store,1 load+1 store。这里采用了2条store pipe的方案还是比较激进的,应该为了更高的内存搬运的性能。对于通常的应用,这额外的一条store data估计是起不到多大作用的。

这里Arm着重介绍了其pre-fetching的机制。数据的prefetch可以很好的隐藏系统内存的访问延迟,在高性能处理器上非常重要。通常的prefetch都是根据数据执行的特征,支持1维或多维的stride形式预取。A77提出了一种system-aware的prefetching,号称针对存储子系统的特征提供更高的prefetch能力。由于信息有限,不知道这个system aware是怎么实现的,可能是根据内存延迟的不同,以及L3 cache 各核心的使用率,动态调节了prefetch的数目和策略。
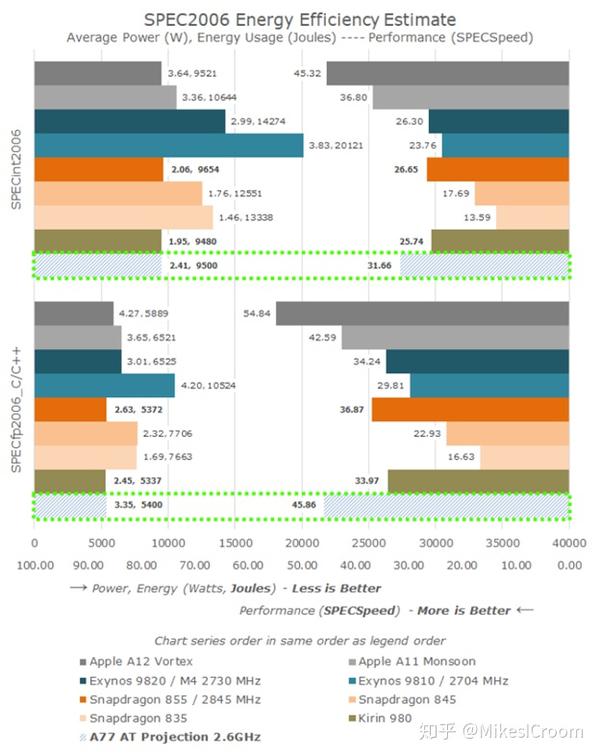
从Arm给出的性能指标来看,A77的能效比还是很高的,尤其是功耗,这也是Arm最核心的竞争力。
从A77的技术指标来看,通用处理器的设计呈现出以下趋势:首先,和在“ZEN2”一文中解释的那样,通用处理器的微架构已经趋于稳定,大的方面玩不出新的花样了,都在细节上做进一步的提升,比如更宽的发射通路,更多的执行单元,更大的预测器等。这给了后来者一个很好的追赶机会。其次,Arm的移动处理器的设计正在逐步趋同于INTEL和AMD在桌面处理器的结构,除了核心频率较低以外,其他的指标已经差距不大了,很多X86上独有的技术正在逐步出现在Arm的设计中。随着工艺逼近其物理极限,Arm和INTEL的差距在快速的缩小,很可能不远的将来,Arm处理器会具有和X86在服务器市场一战的资本。第三,工艺尺寸的缩小带来功耗密度的大幅增加,成为制约核心频率的重要因素。可以看到A77并没有支持更高的频率,并且按之前SOC设计来看,最终的芯片估计只能维持在2.5G左右。由于移动端散热条件更为苛刻,可能通常的应用会采用多核心工作在较低频率,而对于游戏等大型应用,会提高单核的频率,其他核心降频或进入低功耗,保持整个芯片的功耗在可控范围内。INTEL的睿频技术也是差不多的方式。功耗将在很长一段时间里成为处理器性能提升的瓶颈,对设计者能否根据具体的应用场景来提供灵活的执行方式提出了更高挑战。
因此,领先者制约重重,后来者可以奋起直追。现在可能是国内处理器发展的大好时机。比如前几天平头哥宣布的玄铁910,综合性能已经可以和Arm A72持平,这是国产处理器和世界一流水平差距最小的一次。可能用不了多久,我们就能在移动市场追上Arm的脚步。不过Arm的优势更多的在于生态,新兴的RISCV能否打破这个限制,以开源为核心建立起自己的生态体系,就成为国产处理器商业化道路上的关键因素。期待这一天早日到来。
[1] 文中图片来源于Arm Tech Day Presentation, May 26, 2019.
更多AI处理器架构设计的技术干货,,欢迎扫码关注公众号MikesICroom,同时欢迎关注AI处理器架构设计专栏。

