
前一阵有个同事突发奇想,说5G基带芯片可不可以用GPU来做通用计算,反正都是乘加嘛。这样既省了基带的面积(有个参考数据,28nm时候,4G CAT7要十几个平方毫米,而低端的手机芯片一共也就30-40mm的预算,中端的也不过60mm),而数据传输率不高的时候,多出来的GPU核还可以拿来打游戏,多好。想法不错,于是我们就开始算PPA,看看靠不靠谱。
作者:djygrdzh
来源:https://zhuanlan.zhihu.com/p/32369065
首先,上一个传统4G基带模块图:
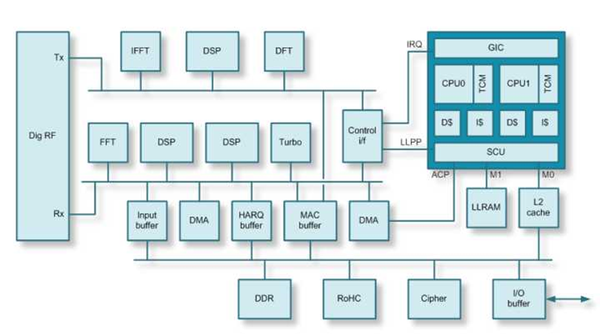
输入大致需要滤波,解码,FFT,均衡,解交织,信道估算等步骤,输出就简单多了,省了滤波和解码,信道估算等。上图使用了DSP来做数据通路外加一层控制,二三四层协议放在CPU做,用DMA来搬数据。这个结构,做LTE CAT4问题不大,毕竟CAT4下载才150Mbps。但是到了5G就不一样,5G的传输率在一下子飞跃到10Gbps,而第一代也得2-3Gbps左右,这运算量一下子高了20-60倍。
于是做了下估算。假设5G是8x8MIMO,8路通道,那么滤波需要运算量如下:
30.72Mbps(每通道数据传输率) x 8(通道数) x 4(过采样) = 1Gbps。
这意味着1Gbpsx32(32阶矩阵)x2(正反变换)=64G次的16x16MAC(乘加)运算。这是每秒钟要完成的计算量。对应到DSP上,一个每周期能做4次MAC的DSP核,运行在1Ghz,需要16个。这得是多大的面积和功耗啊,而这只是第一个环节。第二大计算模块是解码,按照经验大概推了下,需要5G MAC/s。其余的就小了,iFFT大概224M MAC/s,负载均衡,解交织等加起来也不过100M MAC,可以忽略不计。
总的来说,10Gbps的线速需要70G MAC/s,用128MAC/cycle的DSP需要跑在600MHz,16纳米上面积估计3mm左右。那用GPU需要多少个核呢?假设带宽和延迟不是问题,跑在850Mhz的GPU,每个核的峰值运算能力是FP32 30GFLOPS,相当于60G次16x16 MAC,几乎一个核就能搞定。此时功耗小于500毫瓦,面积小于5mm,看上去似乎可行。
不过,用GPU做滤波和解码有个非常大的问题,就是延迟。GPU的驱动是跑在CPU上的,GPU指令动态生成,所有的数据buffer全都要分配好,然后丢给GPU。这个过程是毫秒级的。用做图形无所谓,因为60帧刷新的话,足足有16ms的时间完成顶点和渲染,而一般的通用计算只要求平均性能,不会要求每一帧的延迟。到了基带就不一样,有些命令和信号解析的处理必须是在几十个微秒内完成,也许计算量并不大但是延迟有要求。而GPU的现有驱动结构很难做到这点。
还有一点,对于频域信号FDD,某些下载场景,哪怕下载速率相对不大,GPU都必须一直开着并全力计算,不能开一小段时间,做完处理就关闭。这样,几百毫瓦的功耗其实就非常大了。在场测时,这样的场景是必须测试的,此时功耗就比asic方案大。
所以,用GPU做基带通用计算就不太可行。而用DSP可以解决延迟的问题,对于70G
MAC/s来说,功耗和面积应该是Asic的2倍以上,还是有点大。所以我觉得,靠谱的方案还是在数据通路上使用ASIC做大部分的计算。功耗可以降到几十毫瓦,面积更是可以缩小。
我这有张5G基带芯片的结构图:
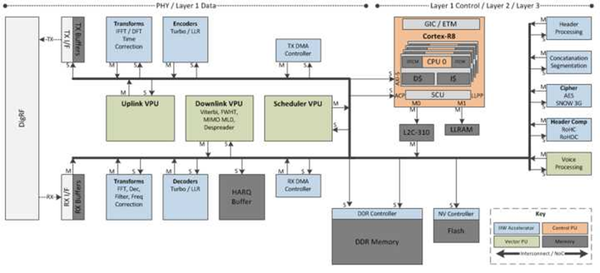
和4G不同,这个结构里大量使用ASIC模块,还出现了一个VPU。这个概念其实来自于高通的设计,高通自己定制了一个向量处理器,把基带常用的计算做成指令放进去,具体情况不清楚,据说很好用。
数据通路解决了,接下来还有控制通路,也就是图上的棕色部分,使用了Cortex-R8。相比4G,5G的控制通路性能需求也是涨得非常快。有一个数据,拿R8单核跑4G LTE 2-4层协议栈,600Mbps就需要跑在600Mhz左右。以此类推,做5Ggen1的控制,数据率在3Gbps,就需要3-4个跑在1Ghz的R8,好在R8最大可以支持到MP4,此时的面积倒是不大,功耗也是几百毫瓦。这个功耗不像数据通路前端部分不能关,经过频域时域转换,如果没有数据进来,是可以降低运行频率,甚至关掉几个核留一个待机的。MP4的好处是核之间可以有双向硬件一致性,对于某个数据包做处理,分别要经过1,2,3,4核做不同工序的话,就可以完全不用软件刷新缓存了,这其实省了非常多的时间。因为一个32KB的缓存刷新时间肯定是毫秒级的,而如果每个数据包只有1KB大小,那相当于每传1KB就要刷新一次一级数据缓存,因为程序并不知道一级数据缓存的那些部分被用了,只能统统刷走。当然,还有一些别的方法可以做优化,比如数据分类,只需要用一次的就把页属性设成non-cacheable,不要占用缓存,而经常要用的可以多个包一起刷,降低overhead。这些都和系统设计有关,不管AMP/SMP都用得上。之前的4G基本都是用单核来做所有的协议处理,到了5G就必须考虑多核情况了。
不过我在想,这才是3Gbps而已,10Gbps的全速5G怎么办?难道基带也得用10核吗?是不是得像网络处理一样,加个ASIC自动合并类似的包,或者干脆都使用大包?
推荐阅读
授权转自知乎,欢迎关注Arm攒机指南专栏,后续还有AI等相关篇章。

