
作者:nihui
转自:知乎
在线管线缓存,online pipeline cache,英文太长了,于是翻译成中文六个字塞进标题里
ncnn 开 gpu 后加载模型太慢了 QAQ
简单的上层 API,底下实现可能非常复杂。 自从 ncnn 实现了自动管理 gpu instance,现在只需要一行代码设个 true 就能打开 gpu 推理功能。
net.opt.use_vulkan_compute = true; // Add this line to enable gpu inference
net.load_param("resnet.param");
net.load_model("resnet.bin");
打开 gpu 后,模型加载时间会显著变慢,在手机上,原本 cpu 加载 100ms,gpu 可能需要 5~6s。
https://github.com/Tencent/ncnn/issues/1708github.com
我当然是知道的,慢就慢在创建 pipeline 这里,vkCreateComputePipelines。ncnn 每个 gpu 算子都是用 shader 拼出来的,模型里有各种 op,所有 op 的所有 shader 最终都要经过这里,让驱动编译出 gpu 能跑的东西。shader 多了就慢了,而且因为某些驱动 bug,还不能多线程创建 pipeline。
在线管线缓存的思路
既然创建 pipeline 那么慢,想办法绕过吗?这是关键步骤,绕不过的!尽量减少创建 pipeline 还是可以做到的。
通常,模型里的算子种类不会特别丰富,总是 Convolution Pooling Concat 这些,前面层创建过的 pipeline,如果参数完全一致,后面层可以直接复用。
参数不一样是不行的,kernel stride dilation activation 等等参数,为了更好的优化,被做成了编译期常量(specialization constant),所以都叫 Convolution,参数不一样,实际 shader 代码就不一样,不能复用。
选项开关不一样也是不行的,fp16 存储/计算,是否用 image 等等参数,直接决定 pipeline 输入输出的数据结构类型,为了方便代码复用,被做成了宏开关,所以都叫 Convolution,选项不一样,实际 shader 代码就不一样,不能复用。
localsize 也是编译期常量,可能有些显卡支持可变的 localsize,但就目前 vulkan spec 的意思,localsize 不一样,实际编译出来的pipeline不一样,不能复用
总之,能不能复用,就看这四样是否同时相等
- op 类型,Convolution, Pooling ...
- op 参数(specialization) ,kernel, stride ...
- 选项开关(option),fp32, fp16, image ...
- localsize
digest 查找
缓存就是管理 key-value,key是上面四个,value就是创建好可以被复用的 spirv二进制/shader信息/VkShaderModule/VkDescriptorSetLayout/VkPipelineLayout/VkPipeline/VkDescriptorUpdateTemplateKHR 实际上,不仅 pipeline 复用了,那些和 pipeline 相关的各种结构也能复用,进一步减少编译代价
VkShaderModule shader_module;
VkDescriptorSetLayout descriptorset_layout;
VkPipelineLayout pipeline_layout;
VkPipeline pipeline;
VkDescriptorUpdateTemplateKHR descriptor_update_template;
ShaderInfo shader_info;
为了更快的找到复用 pipeline,我把这四个东西处理为 128bit digest,128bit 的相等比较在现代 cpu 上速度非常快

- op\_type 就是 op 类型,直接用 32bit 表示
- option 都是 true/false 开关,用 8bit 表示8个开关状态
- localsize 通常不会很大,x/y/z 各用 8bit 表示,一共 24bit
- specialization 是一个 vector<32bit> 的序列,不同的 op 会有不同数量的参数,0~20个左右,不会特别多,我用了比较好实现的 murmur3 fnv1a 两种 32bit hash 函数,拼成一个 64bit 的 digest,我觉得两个 digest 同时碰撞的几率已经足够低,并且还有前面 op\_type option localsize 检查,于是没有考虑碰撞问题
https://en.wikipedia.org/wiki/MurmurHashen.wikipedia.org

如果是外部基于 spirv 创建 pipeline,那么就把开头 32bit 换为 spirv murmur3 digest
怎么开启使用呢?
更新最新的 git master 代码便自动开启,不需要修改任何 cpp 代码
稍微改了下 benchncnn 测试工具,输出了模型加载时间,并用 oneplus7T 手机测试对比(qcom855plus)。 shapehint 表示模型中保存了输入输出 featuremap shape,ncnn 会自动根据 shape 信息,附加额外的 specialization constant,固化 shader 中的 shape,并调整 localsize 设置。shapehint 可以进一步提高 gpu 推理速度,但对于在线管线缓存是不利的,原先完全一致的 op 类型参数组合因 shape 不同而无法复用。
shapehint 的推理速度提升在大部分实测中并不明显,实际使用 shapehint 的情形也比较少,所以我又稍微改了下加载代码,测试了下没有 shapehint 的模型加载耗时。
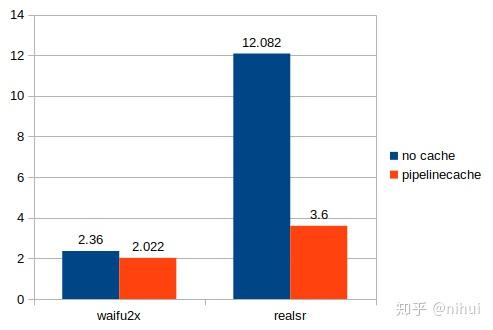
图中 shapehint 就是原先完全没有在线管线缓存的耗时,shapehint+pipelinecache 是自动打开的结果,pipelinecache 是去掉 shapehint 的结果,是最终效果

pc 上我用 waifu2x-ncnn-vulkan 和 realsr-ncnn-vulkan 超分辨率作为测试,平台是 r7-1700 rtx2070 fedora-32。realsr 模型层数多,在线管线缓存的复用率更高,收益非常明显
waifu2x-ncnn-vulkan(cunet),59层,241x180 -> 502x360
realsr-ncnn-vulkan(DF2K\_JPEG),999层,300x200 -> 1200x800
多次执行取整体耗时中位数,包含初始化,模型加载,图片解码,超分辨率,图片编码等全部步骤
那么,离线管线缓存呢?
离线管线缓存,就是 vkCreateComputePipelines 传入 pipeline\_cache 参数的做法,vulkan spec 上说可以加快创建速度,看起来挺不错。本来是打算把这个也做出来的,但后来发现了些问题,并不容易,于是这次就没有一起做出来。
- pc 上实验下来没有加速效果,因为驱动暗地里已经悄悄帮我缓存了
- 离线缓存,需要存出一个二进制文件,要设计新的接口,调用方也要加新的代码,具体怎么存储和加载没想清楚
- 最重要的问题,这个离线缓存如何保持兼容性?系统或驱动升级不兼容,换硬件不兼容,缓存文件损坏如何处理等等...
我需要想想清楚考虑得更全面,再尝试下,全部解决后再写个文章分享也不迟呀
推荐阅读
更多嵌入式AI算法部署等请关注极术嵌入式AI专栏。

