
首发:知乎
作者:张新栋
我们在做深度学习的网络训练阶段,会不经意的引入很多额外的Op,加大porting的难度、增加porting的流程。虽然我在很多项目中都尽力的去协调training和porting两端的工作,但是很多时候还是很难做到一个很完整的闭环,特别是碰到不熟悉的框架的时候。最近碰到了一个小case,相信我们很多同学在进行porting的时候也会碰到的,pretrain model已经给出的情况下,在不联动training步骤的情况下,我们怎么进行落地?以如下网络为例,

origin
熟悉该模型的同学应该能看出这是一个人脸识别网络,拿到该模型的时候,我先对其进行了评估,有几个问题是会影响我们进行porting的:
1、前置插入了identity拷贝op、sub op和mul op,实际上就是(x - mean)/std的预处理操作。该类组合在一些场景下可能会影响模型的落地,比如在NPU场景,就需要看看量化工具的支持程度了。
2、模型是从mxnet转的onnx,PRelu的slope为一维的。onnx在做inference的时候,可能无法正常进行broadcase。
3、还是mxnet转onnx的遗留问题,BatchNormalization的参数设置,在不同版本的onnx-runtime中的兼容性存在问题。
如果上面三个问题都能解决,porting起来难度会减小很多。针对问题1,我们的想法很简单,直接把identity、sub和mul给裁剪掉,后面把预处理拉出来做就好;针对问题2和问题3,我们基于原始的onnx graph的基础上进行参数修改和重构即可。下面我们来看,如何一步一步进行解决。
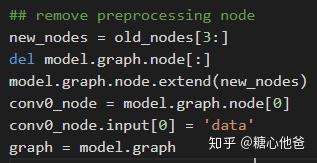
一、Op裁剪
思路很简单,我们录入的模型是一个DAG,裁剪后也要保持网络为一个DAG。如原始的预处理的数据流为data--->Identity--->Sub--->Mul--->Conv0,我们在进行Op裁剪以后,数据流则变成:data--->Conv0。核心代码也非常简单,我们只取从Conv0往后的nodes,然后再修改Conv0的input为data即可。
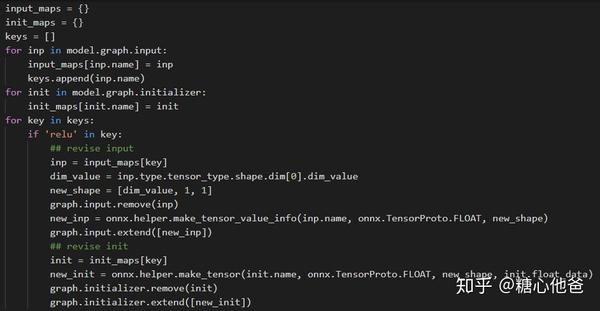
二、PRelu参数修改
PRelu的参数为一维的,我们在onnxruntime中进行inference的时候可能无法正常进行broadcast(graph optimization阶段也无法进行),所以我们的思路很直接:直接修改slope参数的shape信息,若原来是1x64的向量,则将其shape信息改成(64, 1, 1)。修改后可以正常进行broadcast。核心代码如下,我们需要构建input maps(节点信息)和initializer maps(权值信息),然后遍历所有node去找出prelu的节点进行修改。
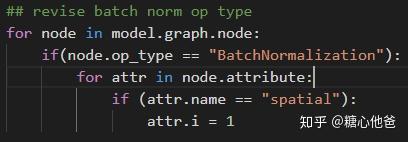
三、BatchNormalization参数修改
思路跟上面的类似,迭代遍历所有节点找到BN层,然后对其spatial参数进行修改就好。下面为核心代码部分:
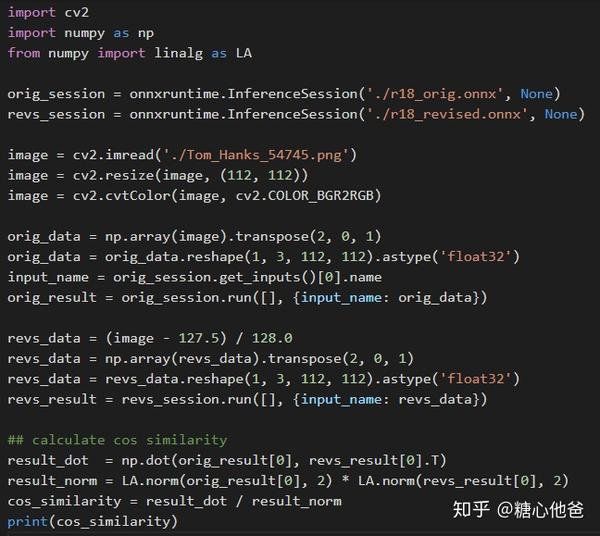
四、模型验证、导出及数值验证
最后在进行模型导出的时候,可以借助onnx的工具进行graph的有效性验证,调用如下的api即可:onnx.checker.check\_model。此外进行裁剪和修改的模型,需要与原有模型进行数值对比,我采用的方案为计算原始graph和修改后graph的cos similarity,一般如果流程没有出错的话,cos similarity会非常接近1.0。如下为核心代码片:
最后也附上修改后的graph的拓扑图:

本文基于onnx,跟大家简单介绍了如何基于pretrained model进行网络裁剪和修改的任务。大家如果有感兴趣的任务或者话题,也可以下方留言。欢迎大家留言、关注专栏,谢谢大家!
推荐阅读
专注嵌入式端的AI算法实现,欢迎关注作者微信公众号和知乎嵌入式AI算法实现专栏。
更多嵌入式AI相关的技术文章请关注极术嵌入式AI专栏


