
2021.4.16-4.17,阿里云视频云亮相 LiveVideoStackCon 音视频技术大会上海站,带来三场不同视角的主题演讲,并与众多行业伙伴一同交流。在 “编解码的新挑战与新机会” 专场,视频云的资深技术专家深度分享了 “窄带高清” 技术演进思路。
窄带高清是一套以人眼的主观感受最优为基准的视频编码技术,研究在带宽受限的情况下,如何追求最佳的视觉感受。阿里云早在 2015 年就提出了该技术概念,在 2016 年正式推出窄带高清技术品牌并产品化,自提出便促动整个行业开始逐步引用该概念,形成了行业共识并不断演化至今。
阿里云智能视频云资深技术专家王豪,在演讲中阐释了窄带高清的本质、当前的技术聚焦点、及其未来的方向与布局。以下为完整的演讲内容。
“大家好,我是王豪,来自阿里云智能视频云。现在主要负责视频编码和增强。我们团队一直关注视频编码和处理方向的进展及其技术前沿工作。今天和大家分享的是我们在窄带高清方面的进展和思考,希望能与大家一起探讨。
我今天重点要讲的是三个部分:窄带高清是什么、关于现在在窄带高清方面关注哪些内容、以及关于未来的布局是什么。”
阿里云的窄带高清
1.1 窄带高清技术

窄带高清是阿里云视频云的技术品牌,是属于内容自适应编码里的。窄带高清是修复增强 + 压缩的问题,主要目标是追求质量、码率、和成本的最优均衡。在这个方向我们有两代不同版本。
第一代是均衡版,主要作用是如何用最少的成本去实现自适应的内容处理和编码,达到质量提升同时节省码率的目的。所以,我们在窄高 1.0 充分利用编码器里的信息帮助视频处理,即成本很小的前处理方法,从而实现低成本的自适应内容处理和编码。同时,在编码器里,主要时间是基于主观的码控。
第二代(窄高 2.0),与窄高 1.0 相比会有更多的、更充分的、复杂度更高的技术来保证自适应能力,同时我们在窄高 2.0 里增加了修复能力,比较适用于高热内容,比如优酷世界杯。对这种重要的比赛用窄高 2.0 进行处理,在质量提升的同时,码率节省也更多,具体内容我在后面会一一展开。
1.2 窄带高清的全景图

上图是窄带高清的框图。从上一页 PPT 来讲,窄带高清除了单点技术之外,主打内容自适应。上图最下面的内容是核心技术:视频处理和视频编码。视频处理和视频编码是原子能力,上面的内容就是如何去做自适应。对窄带高清来说,自适应来自三个维度。
第一个维度:业务。不同的视频语音业务对窄带高清的诉求是不一样的,比如长视频和短视频:由于视频的采集方式不同和时效性不同,它所需要的窄高采用的技术和编码模式都是不同的。
第二个维度:视频热度。在首淘场景中对高热内容可以用窄高 2.0 启动二次转码来实现质量的进一步提升和码率的节省。
第三个维度:内容。内容分为两块 ——High level 和 Low level。
High level 第一点就是语义。在语义中,基于不同的场景决策最优的编码参数,同时还有分割,分割就是 ROI,我们可以对感兴趣的区域进行编码。第二点是质量,片源质量包括失真,包括亮度、对比度、噪声等等,以及它的片源质量是怎样的。这些内容极大地决定了视频处理的组合和强度,同时对编码器的决策也会有很大的影响。
Low level 被我们认为是低成本的思路,包括时空复杂度和 JND 两个内容,我在后面都会进行展开。
视频普惠化下的视频编码与视频处理
阿里云视频云当下重点发力的内容之一是把视频普惠化,而视频普惠化的关键在于成本,2021 年我们会继续聚焦在 264、265 持续成本的节省,同时在下一代 VVC 和 AV1 上发力。
2.1 视频处理
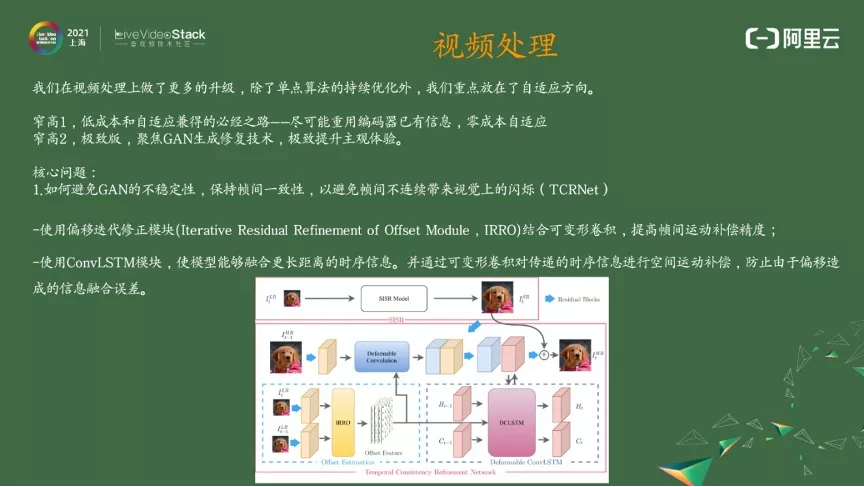
在视频处理方向,除了单点算法之外,我们还把重点放在了自适应方向上。窄高 1.0 的核心就是低成本和自适应如何兼得,我们的重要思路就是:尽可能地重用编码器的编码信息去帮助视频处理做自适应的决策,这样的自适应是零成本自适应,包括视频编码里的 CUtree 和自适应量化 (AQ) 的信息、运动搜索的信息等,充分地使用到这些信息并帮助视频处理做出决策。
窄高 2.0 除了之前讲的场景语义帮助编码做决策之外,另一个重点要讲的是基于 GAN 的生成修复技术。这里的核心问题:由于 GAN 生成是不稳定的,怎样保证帧间一致性就是一个难题 —— 这里我们用的是 TCRnet。TCRnet 是用 IRRO 偏移迭代修正模块结合可变形卷积来提高运动补偿的精度,同时利用 ConvLSTM 进行时序信息的补偿防止造成信息误差。
2.2 视频处理人像处理

我们认为无论是在点播、直播还是 RTC 场景里面,人脸部分一直是人的 ROI,如果我们能把人脸区域或人像区域做比较大的提升,那这块对主观质量来说一定有比较好的提升以及视觉增强。我们这块是和高校合作的,从上图可以看出,和 LR 以及 DFDNet 对比起来,我们的结果(第三列和第六列)清晰度更高,同时鲁棒性更好。目前我们的算法正在申请专利,等结束之后会更加详细地分享。
内容分析
3.1 片源质量
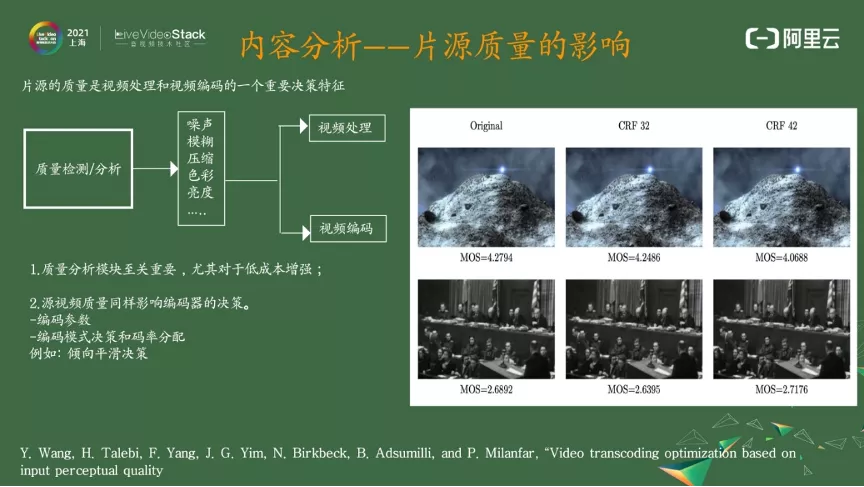
片源质量是一个非常重要的决策因素。大家一般关注在视频处理上,比如对片源检测有哪些失真:噪声、模糊、压缩、色彩、亮度等,根据这些失真来做视频处理决策,做组合以及强度。对低成本的视频增强来讲,视频质量的分析非常重要。因为对一个大模型来说,可以用大模型学到很多自适应能力;对小模型来说,要给它足够的先验信息,帮助它在低成本下实现视频处理的较好的决策。
除了对视频处理的帮助之外,片源质量对视频编码的影响也比较大。
大家可以看到视频右边这个图,这个图我是从谷歌那篇 paper 中摘出来的,我们自己测也能发现,但谷歌那边 MOS 打分非常详细,所以我把这个图给贴出来。上图右侧的图片中 CRF42 跟源的质量差不多,但是下面的 CRF42 的质量比源的质量还高。
在片源质量较差的情况下,自适应编码是个低通滤波,如果用自适应编码将噪声滤掉,这对主观质量是有提升的。这对我们的启发是之前做的主播优化,就是如何通过编码决策,通过 QP (量化参数) 分配,通过一些码控前处理来帮助编码器把高频留下来。
大家都会认为错误的高频会比模糊的低频更好,但是在片源质量差的情况下就不是这个思路了,主观优化的思路要反过来,怎样把编码器的决策使它偏向于模糊的决策,或者使它倾向于做一个平滑的,比如多选双向预测、多选低帧。整个窄带高清里面很重要的模块就是视频质量的分析检测 —— 用来帮助我们做编码和处理的决策信息。
3.2 JND

JND 对工业界来说是一个非常重要的方向。传统的视频编码是基于信息论的,所以它在一直做时域冗余、空间冗余、统计冗余等等的冗余,但是对视觉冗余的挖掘是远远不够的。
JND 对视觉冗余的挖掘思路十分直接。上图取自于王海强博士的一篇 paper,它的思路是传统做 RDO ,是一个连续的凸曲线,但在人眼中它是个阶梯形的,那我们就可以找这个阶梯,找到这个阶梯就可以省下码率栏,使它主观质量不可见。基于这个思路 —— 也是 JND 的思路,JND 分为两个思路。
3.2.1 自顶向下
自顶向下就是要去模拟人的 HVS 的机制来实现 JND 的拟合,但是人们对 HVS 的研究还远远不够,很难用一个东西模拟它,所以现在业界有一些学者去研究间接数据集,通过数据的驱动来逼近 HVS 。
现存的几个问题:第一个就是视频编码的失真其实跟码控、主观优化都有很大关系,稍微动一点编码器的配置,失真差异就会很大;第二个就是基于像素级的标注是不可能的,因为人眼看东西是有角度的,不可能对整个像素进行标注,这样做的工作量是非常大的,所以业界一般用的是第二种方案。
3.2.2 自底向上
自底向上的核心主要是对视觉皮层的视觉特征来进行表真,包括颜色、亮度、对比度、运动等方式。这种也分为像素域和子带域,有没有可能用深度学习来帮助 JND 做提升。
3.3 关于 JND

上图的工作核心是因为 IQA 的业界研究比较多,且有很多的数据集来帮助 IQA 做提升,而 JND 的研究不够。但是 IQA 和 JND 都是保真视频的客观冗余和质量,有没有可能两个做结合,使它互为先验信息呢?
接下来是它的两个主要假设,第一个视频冗余的去除是噪声叠加,大概意思是给一张图上加噪声,加完以后还看不出来,那么这个图的这个区域就是有冗余的。第二个在图上加噪声,然后利用 IQA 作评价把冗余去除变换为噪声叠加,噪声叠加后这个图片用 IQA 做评价。
上图是一个自变量卷积的网络。I 是原图,PC 是吴老师提出的一个特征,PC 是人眼用表真复杂度较低的方式去表真这个规则纹理,而对无规则纹理则用复杂度较高的模式表真。复杂度低和复杂度高的模式对应的 JND 是不一样的,所以把 PC 做为先验传到网络里面,把原图、PC、以及原图和 PC 的综合(concatenation)做为自变量卷积做成的图。
这个思路是利用 IQA 的结果来帮助 JND 做提升,从上图中可以看到,整个思路有很多漏洞,比如 IQA 的判断,哪个 IQA 可以来判断噪声叠加之后的图的质量,PC 是不是好的表真方式等,这些问题都是有提升空间的,但这是我们目前看到帮助 JND 提升的比较好的方向。
视频编码与处理联合优化
4.1 视频编码与处理联合优化的思路

现在我们正在做的视频编码和视频处理的联合优化就是既有发送端也有接收端,不仅有前处理也有后处理。
基于上面的框图来说,整个视频编码的失真假设是有所改变的,不再是编码前后的失真,而是前处理之前和后处理之后的失真。同时码率也会发生变化,不一定是只有基本层,还可以有增项层来帮助视频后处理去做提升和恢复。
视频编码与处理联合优化有几种思路。
第一个思路是怎样利用视频处理帮助编码提升压缩率。这里可以利用场景分类、内容理解、质量分析以及 JND 帮助做出决策;第二是除了帮助视频编码做决策之外,还可以利用视频编码视频前处理提升视频质量达到更好效果。
第二个思路是怎样用视频编码帮助视频处理提升效果,这边的处理指的是后处理。这里有两个核心问题,基于后处理的情况如何做编码的决策。之前用的 RDO 的公式、曲线 \ 以及码率分配都是基于编码器得到的。但是在有后处理的情况下,在决策和预测时应该做出怎样的变化,这是我们和高校正在探索的问题。
这里着重讲分层编码,分享一下我们在这一部分的思考。
分层编码一定要满足几个条件:
第一个条件是是否能找出更高效的数据表达形式,不仅仅是上传的信息在编码器做码率分配就可以,而是编码器在做码率分配时有更高效的方式才会有分层的价值。
第二个是发现对质量贡献有价值的信息,传递这些信息会比在普通编码时码率分配那些信息更高效,可以识别出对质量更具有价值的信息,这一点后面会进行展开。
第三个是编码处理的联合优化。
4.2 关键点 + 雅可比矩阵

上图大家可能看的比较多,像英伟达也是基于这份会议 paper 来制订的会议方案,这个就是一个非常好的更有效的数据表达形式。
这里引用 19 年的一篇文章,First Order motion model for image animation,它的工作是做图像合成,给一张原图然后生成一张图,生成的这张图包括原图的结构信息加上引导图的姿态信息。
从上图可以看到,这里分为了两个模块。一个模块是运动预测模块,是图中的黄色区域;第二个模块是生成模块。在运动预测模块前面对关键点进行检测,这个关键点和我们以为的关键点不一样,不是人脸的关键点,而是通过网络分析 —— 这样对运动表真会更有帮助 —— 得出关键点附近的雅可比矩阵。雅可比矩阵是一个 2*2 的局部仿射变换的矩阵。
基于关键点和雅可比矩阵,可以通过 Dance motion 来得到密集的光流加上遮挡图,把遮挡图、密集光流进入生成网络后来生成最后的图。我框出的图中 Keypoint Detector 就是一个编码器。编码输出了它的特征,特征点和 22 的这个矩阵就是要传输的码流,后面就是解码器。现在的关键点加 22 的矩阵是一个非常高效的表达形式。假设关键点有十个,对应的 2*2 矩阵也有十个,那么对一张图的表示只需要 50 个比特,这比传统编码器更加高效。
我们基于这个思路也在做自己的方案,现在有一些成果,在这里和大家分享一点 —— 我们觉得在这个整体中非常重要的是工程的鲁棒性。它的使用是有限制的,人偏到一定程度,背景比较乱或者人有其他动作时,这种方法就失效了。我们要做一下工程方面的保证,把这些条件全部检测出来,来保证在合适使用的时间把它使用上。
4.3 核心问题
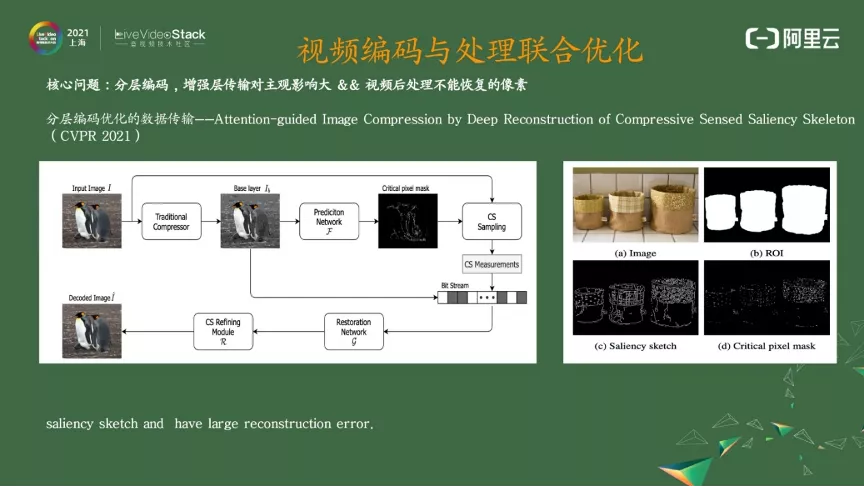
工作的思路是,我们要传输对主观影响大、同时视频后处理不能恢复的像素。编码传到后面深度学习进行视频修复,修复了我们能真正识别出来的信息。信息是否需要传?修复的信息就不需要传了,把不能恢复的信息进行传输,能让整体更高效。
大家从图上可知这是一篇 CVPR 2021 的 paper。它的思路是进来一张图,用传统的编码器或者是 JPEG 去编,编成 Base layer 直接输一个预测网络,预测网络可以得到关键像素的值。这个关键像素是对主观影响大且视频后处理不能恢复的像素,和原图一起做一个感知压缩,作为增强层的码流来融合到编码器的码流里,一起传到对端来进行修复。
有意思的是,它能识别信息后处理后的能做与不能做,它的问题是关键点的预测是直接通过压缩之后的重建图得出的。原因在我不想传位置信息,直接通过压缩之后的重建图得出关键点,在解码端也可以做。但如果把它放入视频编码里,这对失真图的预测来说是个比较大的问题,但这开启了一个比较好的方向,一个我们可以去尝试的方向。
4.4 LCEVC

从纯压缩率来讲,从输入视频到采样,比如 4k 到 1080 经过 540 后用 Base Layer 进行编码,做一个基本层。把这个重建帧进行熵采样成 1080 的重建帧,跟 1080 的源进行残差,残差进行变换量化、熵编码、反变换量化,L-1Filter 是一个传统编码器里面的 Filter,它的方式会更简单。把重建之后的东西跟 1080 的源相减 3k 或 4k 做时域的预测,做 L2 的 Tem poral Layer 的编码。
Tem poral 预测是一个同位的预测,没有应用搜索。基于有效的框图来说需要有几个条件,它做了降采样和升采样,Base Layer 可以认为是一个低频信号,残差可以被认为高频信号,那这个框架是否对高频信号有更好的压缩,这是我们的问题。这里最核心的问题是如果它真的对高频信号有更好的压缩,那整个框架要求就非常高。
第二,它对增强层的压缩比传统编码器更好。从我们的分析包括结果来看都没有达到这两个条件,因为它的时域的信息利用不足,对视频来讲时域冗余才是核心。同时它增强层的所有的 Transfrom 是哈达玛变换的不是 ECT,很多都是近似。
所以压缩率来讲没有达到分层编码应该达到的水平,但很可能在软硬结合的时候是有优势的。硬件编码器可能动不了,需要用软件编码器去做一些分层方面的考虑,这个问题可以后面和各位专家共同讨论一下。
4.5 视频编码与处理联合优化
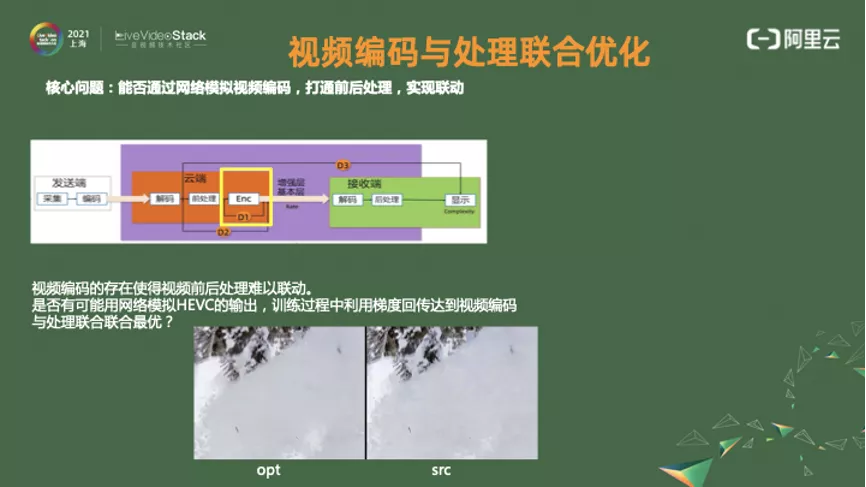
从上图可以看到,视频编码由于编码器的存在把它的前后截断了,是否有可能利用网络模拟视频编码,使得它能够拥有市面的驱动回传,达到前处理和后处理的联动,达到主观最优,我们据此做了些尝试。
我们也用网络去近似它,去模拟传统的 HEVC。后来看效果,网络模拟不能很准确,但我们从主观上和客观上看到了效果,这对我们是个很好的启发。
网络模拟到什么程度或者说你这个起作用的原因是什么,起作用的是不是一个趋势,基于这个趋势怎么构建模拟过程可能能帮助实现前后的联动。我们计划今年下半年发 paper,等 paper 公布后和大家好好讨论。因为我们发现不用模拟得很准确就能出效果。
从上图的中下方可以看出,对传统的视频编码模拟还不足的情况下,处理联动起来之后块效应少了,细节变多了。
质量评价定义了技术选择

质量评价定义了一个技术选择,如何评价算法就定义算法往哪个方向去演进。
上图主要说的是引入 GAN 之后,主观质量和客观质量的正相关性没那么强,即主观质量好不一定客观指标高,所以右图的 quality 和 distortion 的 tradeoff 需要调整。在这个曲线上主观质量好客观质量必定差,主观质量差客观质量就可以好。
在上图中左侧可以看出,SRGAN 是很清楚的,SRResNet 是糊的,最右边的图质量最好,但它的 PSRN/SSIM 是比较低的,同时 VMAF 也是比较低的。所以用 VMAF 来评测也不是特别合适的方式。
我们在视频编码中也发现了一个类似的规律 —— 主观评价是评价窄带高清的唯一方法。我们也找了很多客观评价的东西,包括 LPM,NPS 等等,也包括很多无源的有源的。确实真正符合主观的还没找到,这块是我们必须要做的。
窄带高清的测评方案

我们的思路放在如何提升主观评测效率。主观既然是唯一评价方法,那么是否有方式提升主观评测效率,比如视频素材的选择,怎么从这些维度去选你的视频作为测试集,包括 MSO 最常用的时空复杂度,包括内容、视频的质量,包括与评测算法相关的因素。
如果想评测调色,就要选调色相关的视频,比如时延比较大的与时延比较小的等等。同时,比例也很重要。由于比例是一个结论,所以不合适的比例对你的结论会有比较大的影响。
从上图右侧可以看到,MUS 在测编码器的时候会把几千个视频放到表里面,不同视频在不同区域的分布是什么样子的,如果能达到这个分布我们就知道它的权重了 —— 是不同视频对最后结果的权重是什么。
客观评价有很多种,看平均的值,看 min、max,或者用其他什么方式,但都很难在实际中应用起来。这些可能对不同的场景有效,但怎么样做到鲁棒也是我们自己的一个困惑,所以我们现在把重点放在主观上 —— 核心是如何用很多工具、用很多数据、用很多系统来帮助主观提升评测效率。
这里有几种评测方式:第一个是专家评测。Golden eye 一定要细腻地发现各种失真,这里用 10 个人是比较好的。细粒度是右边这个图,做了一些工具,包括可以随时放大的、可以拖动的等等来帮助我们发现编码或者算法方面的一些小的提升;用户评测这方面太大,我们平时做的比较少,我们觉得专家评测和细粒度评测已经可以把我们整个算法覆盖住了;打分方面,对比模式是 0 到 1 时好时坏,还是 MOS 的 0 到 5 分。我觉得如果人少,推荐 01;人多的话推荐用 MOS。
窄带高清的商用结果

上图是我们的结果,现在在窄带高清 1.0 和窄带高清 2.0 的直播、点播、RTC 方面已经大规模商用。刚刚已经说了,窄高 1.0 的定位是通惠,窄高 2.0 则用更高的算法来帮助特殊的直播,包括优酷的世界杯体育直播和 OTT 直播。
同时,在窄高 2.0 里面,我们还在做生成技术 —— 就是刚刚讲的对人脸的修复。

上图视频由于画面运动比较快,我们节省了 30% 的画面,使主观质量更好。
关于未来:视觉 + 大脑

关于未来,窄带高清的未来肯定是视觉加大脑,这点毋庸置疑,因为从压缩效率来讲肯定是视觉加大脑的效率是最高的。
下面的图引自徐迈教授,上面写了人眼的干锥细胞有十亿个,或者说十亿个 Camaro。从视觉进入大脑 V1 视觉皮层的一个带宽只有 8M—— 不管你看什么内容最终传输到大脑的只有 8M,这个压缩率是非常高的。
下面这个 1.44T 和 8M 对比,从未来的角度看,我们觉得它需要采集计算存储认知方面的创新才能达到这个目标。
举个例子,我们现在的采集都是基于像素的采集,业界也在做基于事件的采集,基于神经脉冲的采集;从计算来讲,虽然现在计算的效率提高了很多,但是和人脑来比算力还远远不够,包括它的消耗 —— 比如我们人吃顿饭能看好久,但机器需要很多的电 —— 这一点从计算上一定得进行突破。
存储是我们持续关注的一个点。是否有可能我的视频编码越多我的视频质量就越好?或者我编码的成本越低,像大脑一样,我们人看过这个东西就直接脑补上了?这些都是从存储里面去找东西来帮助我们去做修复,很多东西都不用传了。
认知也是一样的,关于机器的压缩也有,从特征到像素,因为人脑是不能传像素的,肯定是传特征的,那它的特征是什么也是待学术界要去分析的。

以下有几个问题是我们短期的问题,我们会一直沿着这些问题探讨下去,也以及部分地在这些方面做了合作布局,与高校一起来突破。
第一个,能否随着处理的视频越来越多,压缩效率可以越来越好,这个是我们想跟高校去布局的方向。同时,在联合优化方面,像我们看到的一份 2019 年的 paper,在人脸表达姿态的表达方面有更高效的表达形式了,因为那个不是做压缩的,在压缩方面有没有可能针对更多的场景,或者有压缩的更好的表达形式出来。
第二个,传统的视频编码在中间使前后分离。我们现在有一些结果,发现视频编码是一个工作量大的事情,是否有可能把编码器模拟出来,彻底打通前后处理。这是我们自己在做的、同时也是和高校一起在探索的方向。
第三个,我们针对视频后处理和编码上的决策有一些成果,并且想持续做下去。现在的 RDO 一直是针对于视频编码的,而视频前面有前处理、视频后面有后处理,所以在针对有视频要处理的情况下,编码的 RDO 需要决策编码的码控。
此外,我们在推广的时候很多客户不愿意接受主观评价,在给客户推广的时候,客户一般就看一下 VMAF、PSRN 和 SSIM 是怎么样的,但这个对我们的主观质量、算法演进是不利的。那么,基于主观、 生成和处理的背景下,能适应的质量评价标准究竟是什么?这是需要不断思考的问题。
这就是我全部的分享。谢谢大家!
「视频云技术」你最值得关注的音视频技术公众号,每周推送来自阿里云一线的实践技术文章,在这里与音视频领域一流工程师交流切磋。

