
前面我们介绍了 WebRTC 音频 3A 中的声学回声消除(AEC:Acoustic Echo Cancellation)的基本原理与优化方向,这一章我们接着聊另外一个 "A" -- 自动增益控制(AGC:Auto Gain Control)。本文将结合实例全面解析 WebRTC AGC 的基本框架,一起探索其基本原理、模式的差异、存在的问题以及优化方向。
作者|珞神
审校|泰一
前言
自动增益控制(AGC:Auto Gain Control)是我认为链路最长,最影响音质和主观听感的音频算法模块,一方面是 AGC 必须作用于发送端来应对移动端与 PC 端多样的采集设备,另一方面 AGC 也常被作为压限器作用于接收端,均衡混音信号防止爆音。设备的多样性最直接的体现就是音频采集的差异,一般表现为音量过大导致爆音,采集音量过小对端听起来很吃力。
在音视频通话的现实场景中,不同的参会人说话音量各有不同,参会用户需要频繁的调整播放音量来满足听感的需要,戴耳机的用户随时承受着大音量对耳朵的 “暴击”。因此,对发送端音量的均衡在上述场景中显得尤为重要,优秀的自动增益控制算法能够统一音频音量大小,极大地缓解了由设备采集差异、说话人音量大小、距离远近等因素导致的音量的差异。
AGC 在 WebRTC 中的位置
在讲 AGC 音频流处理框架之前,我们先看看 AGC 在音视频实时通信中的位置,如图 1 展示了同一设备作为发送端音频数据从采集到编码,以及作为接收端音频数据从解码到播放的过程。AGC 在发送端作为均衡器和压限器调整推流音量,在接收端仅作为压限器防止混音之后播放的音频数据爆音,理论上推流端 AGC 做的足够鲁棒之后,拉流端仅作为压限器是足够的,有的厂家为了进一步减小混音之后不同人声的音量差异也会再做一次 AGC。
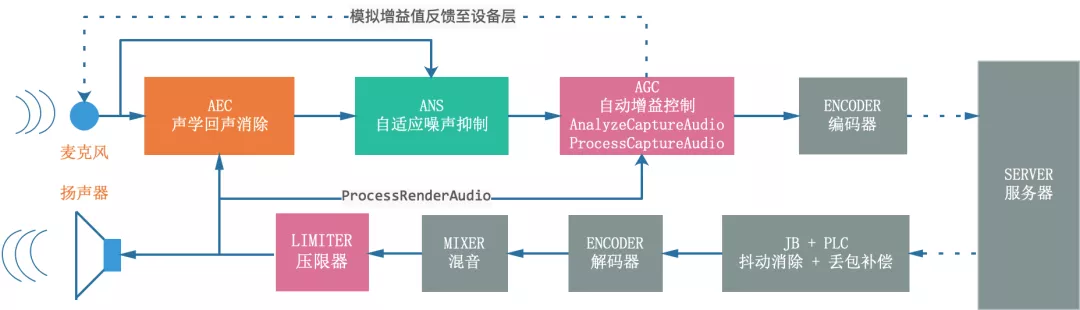
图 1 WebRTC 中音频信号上下行处理流程框图
AGC 的核心参数
先科普一下样本点幅度值 Sample 与分贝 dB 之间的关系,以 16bit 量化的音频采样点为例:dB = 20 * log10(Sample / 32768.0),与 Adobe Audition 右侧纵坐标刻度一致。
幅度值表示:16bit 采样最小值为 0,最大值绝对值为 32768(幅度值如下图右边栏纵坐标)。
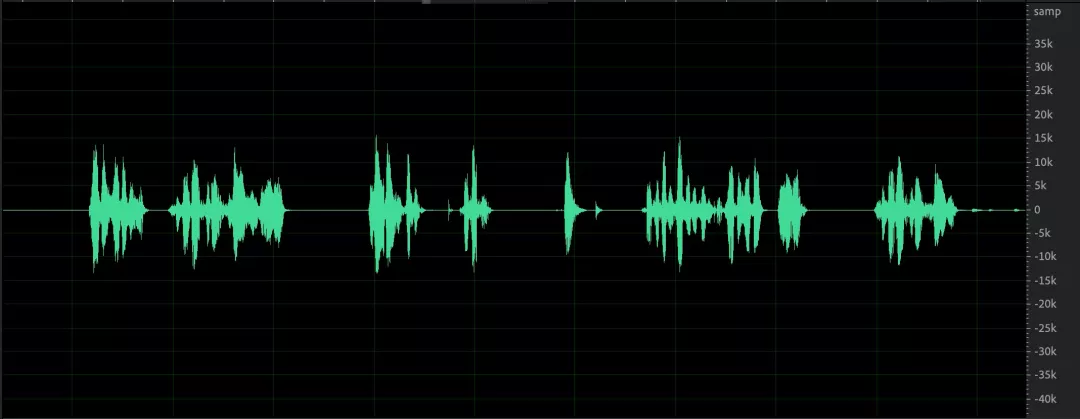
分贝表示:最大值为 0 分贝(分贝值如下图右边栏纵坐标),一般音量到达 -3dB 已经比较大了,3 也经常设置为 AGC 目标音量。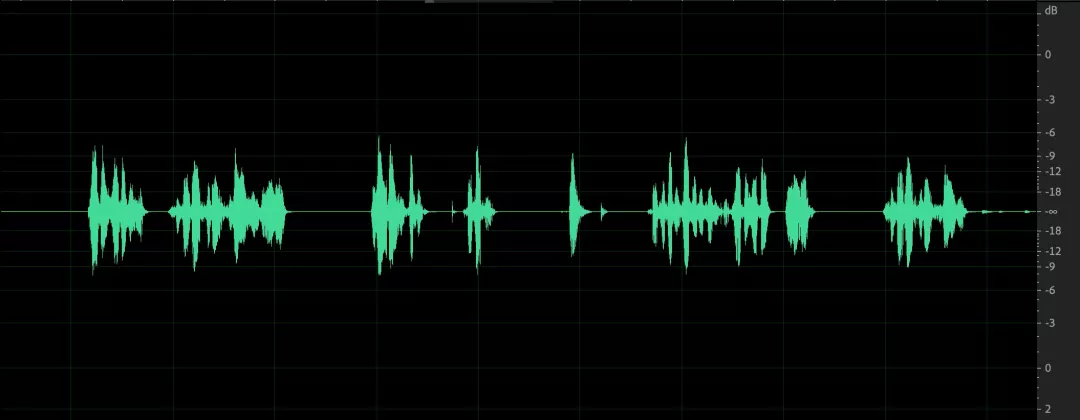
核心参数有:
typedef struct {
int16_t targetLevelDbfs; // 目标音量
int16_t compressionGaindB; // 增益能力
uint8_t limiterEnable; // 压限器开关
} AliyunAgcConfig;目标音量 - targetLevelDbfs:表示音量均衡结果的目标值,如设置为 1 表示输出音量的目标值为 - 1dB;
增益能力 - compressionGaindB:表示音频最大的增益能力,如设置为 12dB,最大可以被提升 12dB;
压限器开关 - limiterEnable:一般与 targetLevelDbfs 配合使用,compressionGaindB 是调节小音量的增益范围,limiter 则是对超过 targetLevelDbfs 的部分进行限制,避免数据爆音。
AGC 的核心模式
除了以上三个核心的参数外,针对不同的接入设备 WebRTC AGC 提供了以下三种模式:
enum {
kAgcModeUnchanged,
kAgcModeAdaptiveAnalog, // 自适应模拟模式
kAgcModeAdaptiveDigital, // 自适应数字增益模式
kAgcModeFixedDigital // 固定数字增益模式
};以下我们会结合实例从基本功能,适用场景,信号流图以及存在的问题等方面阐述这三个模式。
固定数字增益 - FixedDigital
固定数字增益模式最基础的增益模式也是 AGC 的核心,其他两种模式都是在此基础上扩展得到。主要是对信号进行固定增益的放大,最大增益不超过设置的增益能力 compressionGaindB,结合 limiter 使用的时候上限不超过设置的目标音量 targetLevelDbfs。
固定数字增益模式下仅依靠核心函数 WebRtcAgc_ProcessDigital 对输入信号音量进行均衡,由于没有反馈机制,其信号处理流程也是极其简单,设置好参数之后信号会经过如下流程:
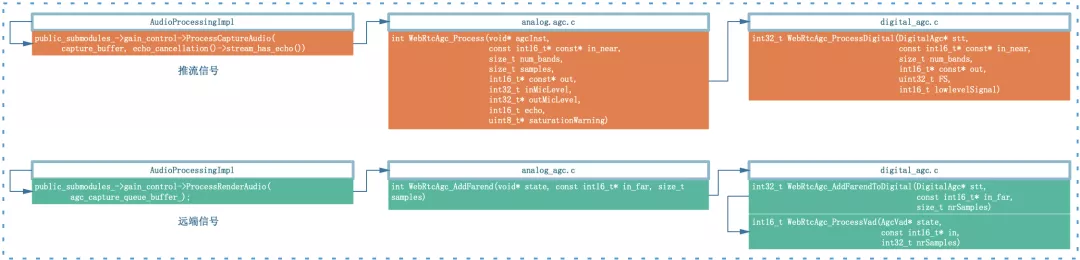
固定数字增益模式是最核心的模式,主要有如下两个方面值得我们深入学习:
语音检测模块 WebRtcAgc_ProcessVad 的基本思想
在实时通信的场景中,麦克风采集的近端信号中会存在远端的信号的成分,流程中会先通过 WebRtcAgc_ProcessVad 函数对远端信号进行分析,在探测实际近端信号包络的时候需要剔除远端信号这个干扰项,避免因残留的回声信号影响了近端信号包络等参数的统计。最传统的 VAD 会基于能量,过零率和噪声门限等指标区分语音段和无话段,WebRTC AGC 中为粗略的区分语音段提供了新的思路:
计算短时均值和方差,描述语音包络瞬时变化,能够准确反映语音的包络,如图 2 左红色曲线;
// update short-term estimate of mean energy level (Q10) tmp32 = state->meanShortTerm * 15 + dB; state->meanShortTerm = (int16_t)(tmp32 >> 4); // update short-term estimate of variance in energy level (Q8) tmp32 = (dB * dB) >> 12; tmp32 += state->varianceShortTerm * 15; state->varianceShortTerm = tmp32 / 16; // update short-term estimate of standard deviation in energy level (Q10) tmp32 = state->meanShortTerm * state->meanShortTerm; tmp32 = (state->varianceShortTerm << 12) - tmp32; state->stdShortTerm = (int16_t)WebRtcSpl_Sqrt(tmp32);计算长时均值和方差,描述信号整体缓慢的变化趋势,勾勒信号的 “重心线”,比较平滑有利于利用门限值作为检测条件,如图 2 左蓝色曲线;
// update long-term estimate of mean energy level (Q10) tmp32 = state->meanLongTerm * state->counter + dB; state->meanLongTerm = WebRtcSpl_DivW32W16ResW16(tmp32, WebRtcSpl_AddSatW16(state->counter, 1)); // update long-term estimate of variance in energy level (Q8) tmp32 += state->varianceLongTerm * state->counter; state->varianceLongTerm = WebRtcSpl_DivW32W16(tmp32, WebRtcSpl_AddSatW16(state->counter, 1));计算标准分数,描述短时均值与 “重心线” 的偏差,位于中心之上的部分可以认为发生语音活动的可能性极大;
tmp32 = tmp16 * (int16_t)(dB - state->meanLongTerm); tmp32 = WebRtcSpl_DivW32W16(tmp32, state->stdLongTerm); state->logRatio = (int16_t)(tmp32 >> 6);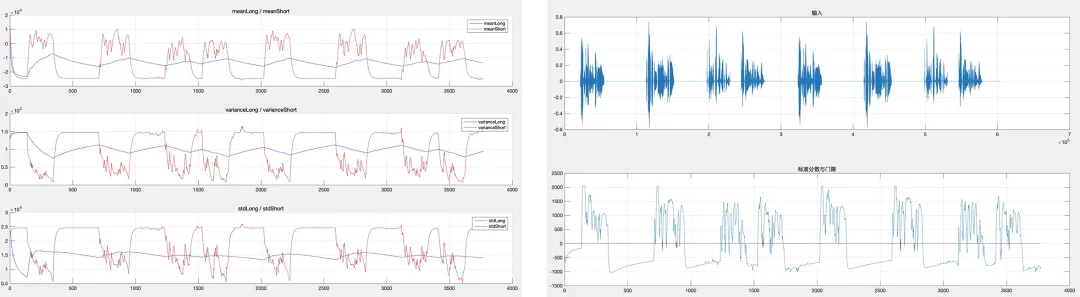
图 2 左:长短时均值与方差 右:输入与 vad 检测门限WebRtcAgc_ProcessDigital 如何对音频数据进行增益
- 个核心参数都是围绕固定数字增益模式展开的,我们需要搞清楚的是 WebRTC AGC 中核心函数 - WebRtcAgc_ProcessDigital 是如何对音频数据进行增益的。
根据指定的 targetLevelDbfs 和 compressionGaindB,计算增益表 gainTable;
/* 根据设置的目标增益与增益能力,计算增益表gainTable */ if (WebRtcAgc_CalculateGainTable(&(stt->digitalAgc.gainTable[0]), stt->compressionGaindB, stt->targetLevelDbfs, stt->limiterEnable, stt->analogTarget) == -1) { return -1; }这一步中增益表 gainTable 可以理解为对信号能量值(幅值的平方)的量化,我们先固定 targetLevelDbfs,分别设置 compressionGaindB 为 3dB~15dB,所对应的增益表曲线如下,可以看到增益能力设置越大,曲线越高,如下图。
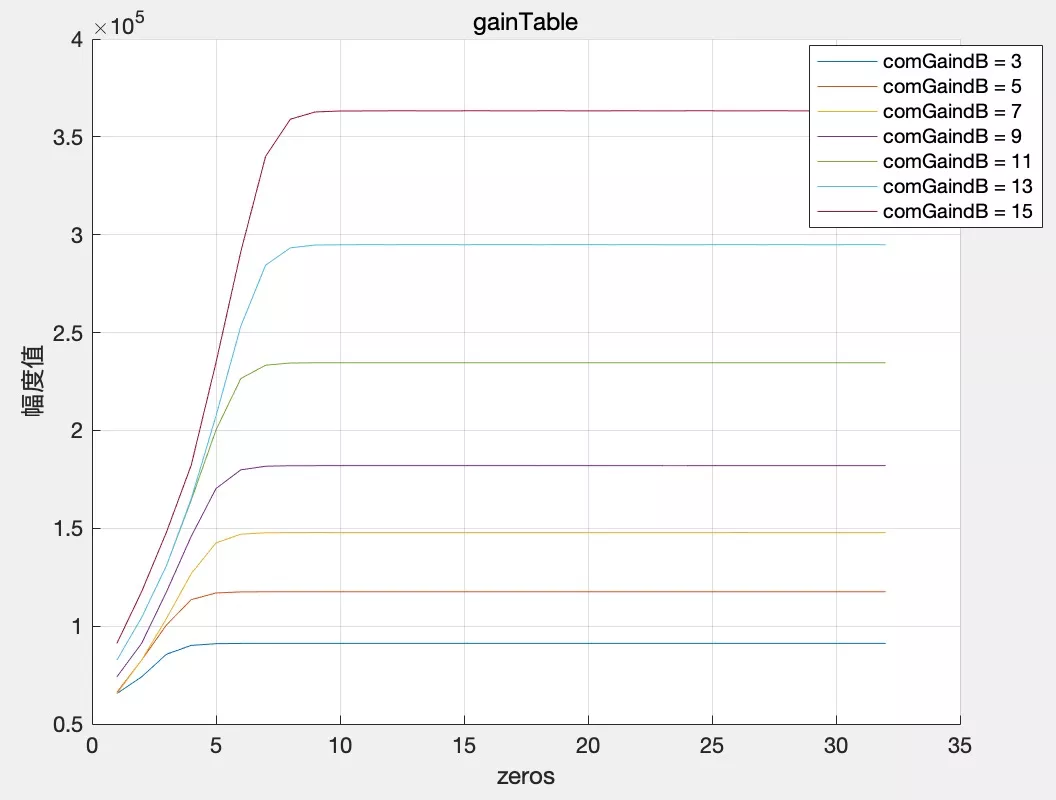
大家可能会好奇增益表 gainTable 的长度为什么只有 32 呢?32 其实表示的是一个 int 型数据的 32 位(short 型数据的能量值范围为 [0, 32768^2] 可以用无符号 int 型数据表示),从高位到低位,为 1 的最高位具有最大的数量级称为整数部分 - intpart,后续数位组成小数部分称为 fracpart。因此 [0, 32768] 之间的任意一个数都对应数字增益表中的一个增益值。接下来我们讲讲如何查表并应用增益值完成音量均衡。
/** 部分关键源码 */
/** 提取整数部分和小数部分 */
intPart = (uint16_t)(absInLevel >> 14); // extract the integral part
fracPart = (uint16_t)(absInLevel & 0x00003FFF); // extract the fractional part
......
/** 根据整数部分和小数部分生成数字增益表 */
gainTable[i] = (1 << intPart) + WEBRTC_SPL_SHIFT_W32(fracPart, intPart - 14);- 根据输入信号包络在增益表 gainTable 中查找增益值,并应用增益到输入信号;
基于人耳的听觉曲线,AGC 中在应用增益是是分段的,一帧 160 个样本点会分为 10 段,每段 16 个样本点,因此会引入分段增益数组 gains,下述代码中描述了数字增益表与增益数组的关系,直接体现了查表的过程,其思想与计算增益表时相似,也是先计算整数部分与小数部分,再通过增益表组合计算出新的增益值,其中就包含了小数部分的补偿。
// Translate signal level into gain, using a piecewise linear approximation
// find number of leading zeros
zeros = WebRtcSpl_NormU32((uint32_t)cur_level);
if (cur_level == 0) {
zeros = 31;
}
tmp32 = (cur_level << zeros) & 0x7FFFFFFF;
frac = (int16_t)(tmp32 >> 19); // Q12.
tmp32 = (stt->gainTable[zeros - 1] - stt->gainTable[zeros]) * frac;
gains[k + 1] = stt->gainTable[zeros] + (tmp32 >> 12);下述代码是根据分段增益数组 gains,右移 16 位后获得实际的增益值(之前计算增益表和增益数组都是基于样本点能量,这里右移 16 位可以理解成找到一个整数 α,使得信号幅度值 sample 乘以 α 最接近 32768),直接乘到输出信号上(这里的输出信号在函数开始已经被拷贝了输入信号)。
/** 增益数组gains作用到输出信号,完成音量均衡 */
for (k = 1; k < 10; k++) {
delta = (gains[k + 1] - gains[k]) * (1 << (4 - L2));
gain32 = gains[k] * (1 << 4);
// iterate over samples
for (n = 0; n < L; n++) {
for (i = 0; i < num_bands; ++i) {
tmp32 = out[i][k * L + n] * (gain32 >> 4);
out[i][k * L + n] = (int16_t)(tmp32 >> 16);
}
gain32 += delta;
}
}我们以 compressionGaindB = 12dB 的曲线为例,上图为计算的数字增益表 gainTable 的实际值,下图为右移 16 位之后得到的实际增益倍数。可以看到 compressionGaindB = 12dB 时,整数部分最大增益为 3,理论上增益 12dB 实际上是放大了 4 倍,这里整数部分最大可以乘上 3 倍,后续再由小数部分补充剩余的 0~1.0 倍,从而可以防止爆音。简单举两个例子:
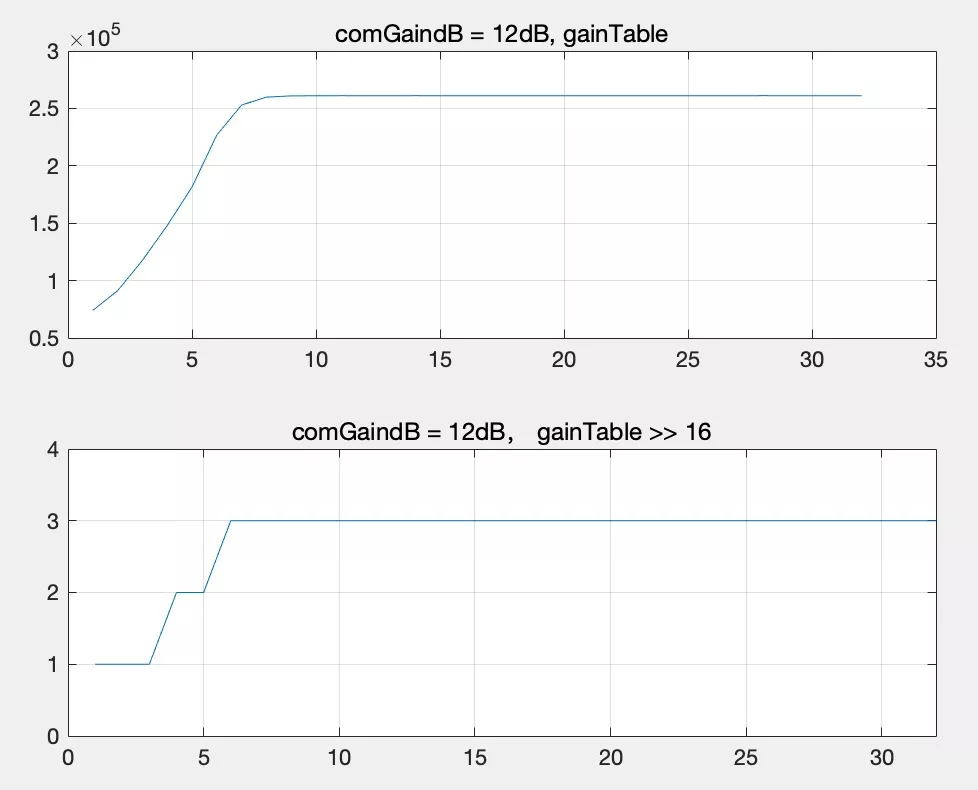
A. 幅度值为 8000 的数据,包络 cur_level = 8000^2 = 0x3D09000,通过 WebRtcSpl_NormU32 ((uint32_t) cur_level); 计算得到前置 0 有 6 个,查表得到整数部分增益为 stt->gainTable [6] = 3,即 8000 可以大胆乘以 3 倍,之后增益倍数小于 1.0 的部分由 fracpart 决定;
B. 幅度值为 16000 的数据,包络 cur_level = 16000^2 = 0xF424000,通过 WebRtcSpl_NormU32 ((uint32_t) cur_level); 计算得到前置 0 有 4 个,查表得到整数部分增益为 stt->gainTable [4] = 2,此时会发现 16000 * 2 = 32000,之后均衡到目标音量的过程由 limiter 决定,细节这里不展开。
简单说就是,[0, 32768] 中的任何一个数想要增益指定的分贝且结果又不超过 32768,都能在数字增益表 gainTable 中找到确定的元素满足这个要求。
关于目标增益 targetLevelDbfs 和 Limiter 的应用在 WebRtcAgc_ProcessDigital 以及相关函数中均有体现,这里就不展开阐述,大家可以走读源码深入学习。
下面我们用几个 case 来看看固定数字增益模式的效果和存在的问题,先固定设置 targetLevelDbfs = 1, compressionGaindB = 12。
1. 采集音量较小,均衡后改善不明显;
设备采集音量 - 24dB, 均衡后音量只有 - 12dB,整体音量听感上会觉得偏小;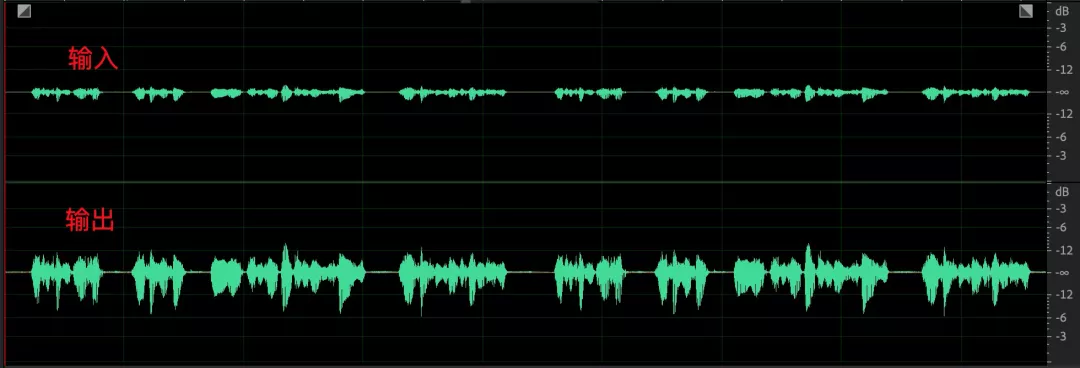
2. 采集音量较大,底噪明显增强;
设备采集音量 - 9dB, 均衡后音量达到 - 1dB,整体音量听感上正常,但语音帧间起伏减小,主要是无话段的噪声部分得到较大提升。这个情况下主要的问题就是当采集音量本身就比较大时,如果环境噪声较大,且降噪能力不强时,一旦 compressionGaindB 设置较大,那么语音部分会被限制在 targetLevelDbfs,但是无话段部分底噪会得到全量的提升,对端参会人可以听到明显的噪声。
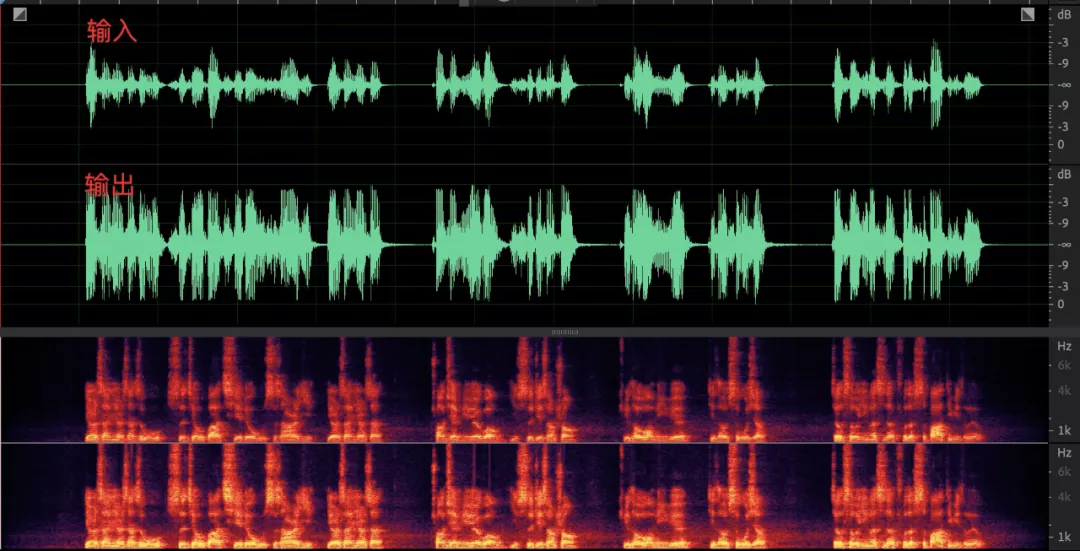
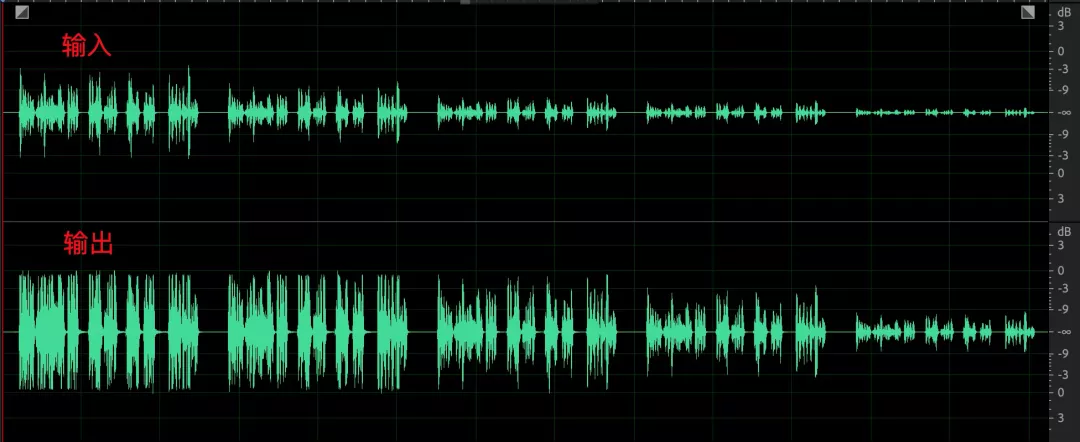
3. 采集声音起伏较大(以人为拼接的由大到小的音频为例),均衡后依然无法改善;
自适应模拟增益 - AdaptiveAnalog
在讲自适应模拟增益之前,我们需要明确 PC 端影响采集音量的功能:
PC 端支持调节采集音量,调节范围为 0~1.0,WebRTC 客户端代码内部映射到了 0~255;
/** 以mac为例,麦克风灵敏度被转成了0~255 */ int32_t AudioMixerManagerMac::MicrophoneVolume(uint32_t& volume) const { ...... // vol 0.0 to 1.0 -> convert to 0 - 255 volume = static_cast<uint32_t>(volFloat32 * 255 + 0.5); ...... return 0; }- 绝大多数 windows 笔记本设备内置了麦克风阵列,并提供麦克风阵列增强算法,降噪的同时还会额外提供 0~10dB 的增益(不同机型范围不同,联想的设备增益高达 36dB),如图 3;
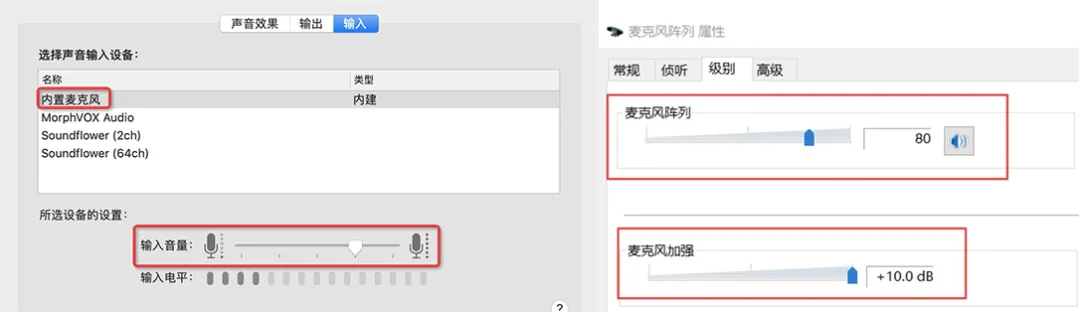
图 3 左:MAC 端模拟增益调节 右:Windows 端麦克风阵列自带的增益能力
由于控制音量的模块过多,导致 PC 端 AGC 算法更加敏感。线上很多客户设置的默认值并不合理,这会直接影响音视频通话的体验:
- 采集音量过大会导致噪声被明显提升,人声爆音;
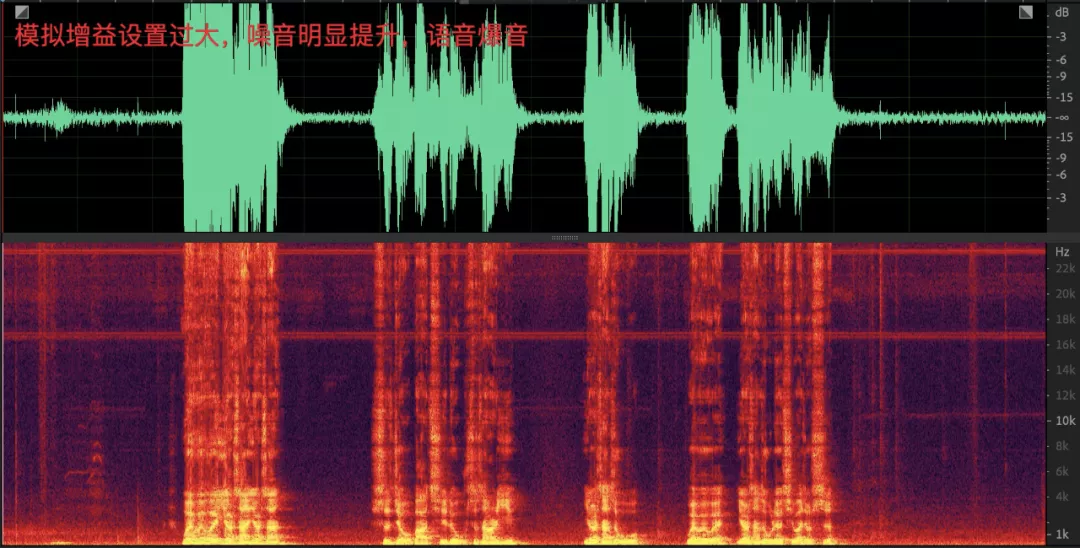
- 采集音量过大会导致播放的信号回采到麦克风之后有较大的非线性失真,对回声消除算法是不小的挑战;
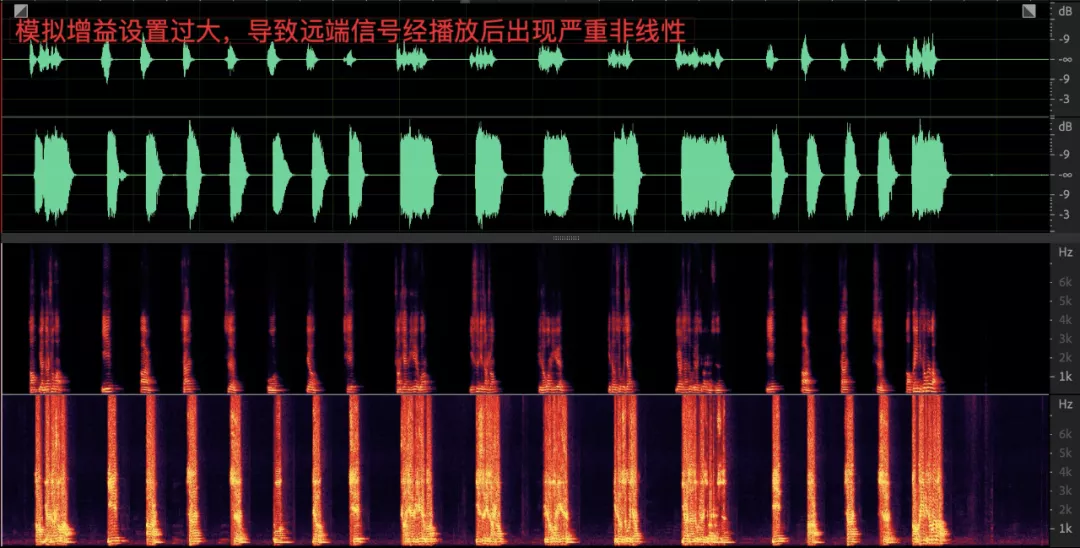
- 采集音量过小,数字增益能力有限导致对端听不清;
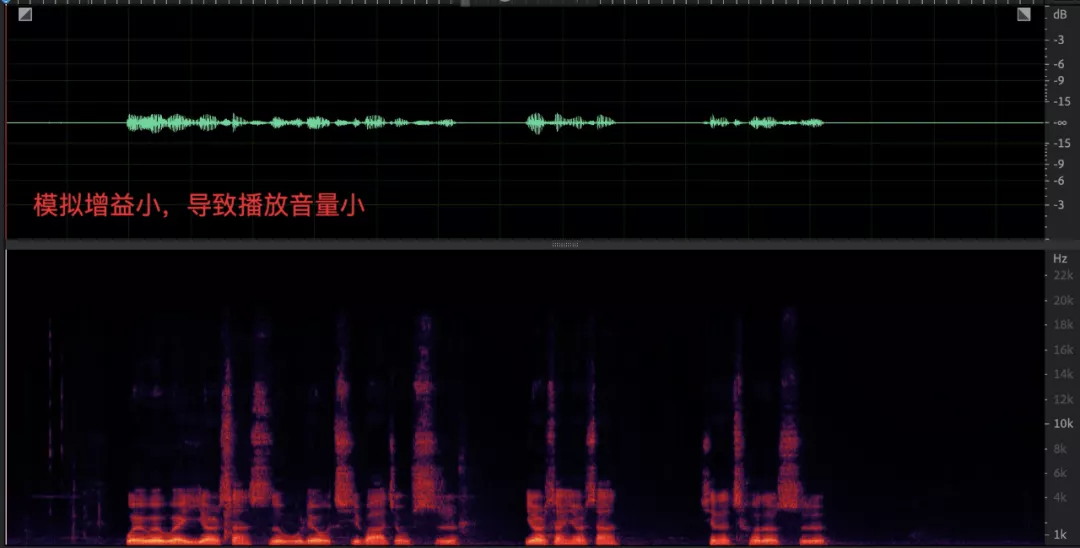
绝大多数用户在察觉到声音异常后并不知道 PC 设备还具备手动调节采集增益的功能,依赖于线上用户(尤其是教育场景很多是小学生)自己去调节模拟增益值几乎不可能,将模拟增益值动态调节的功能做到 AGC 算法内部更可行,配合数字增益部分将近端信号均衡到理想的位置,因此,WebRTC 科学家开发设计了自适应模拟增益模式,通过反馈机制来调节原始采集音量,目标就是与数字增益模块相互配合,找到最合适的麦克风增益值并反馈给设备层,使得近端数据再经过数字增益之后达到目标增益,音频数据流框图如下:
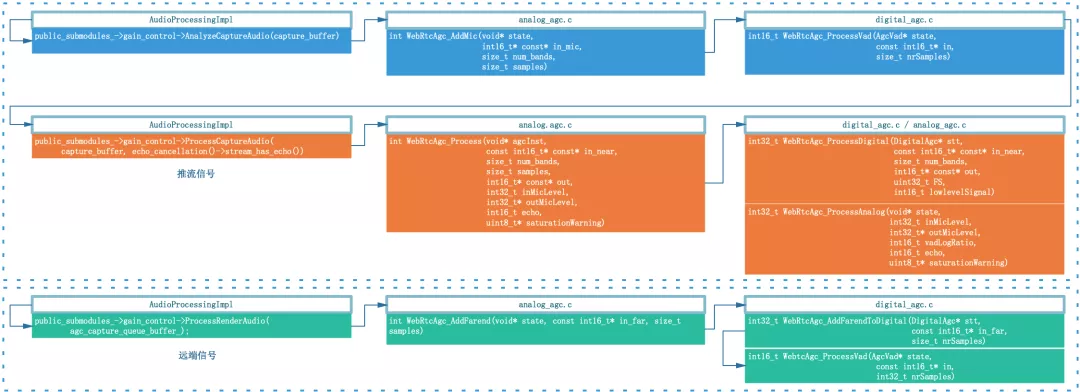
在固定数字增益的基础上主要有两处新增:
在数字增益之后,新增了模拟增益更新模块:WebRtcAgc_ProcessAnalog,会根据当前模拟增益值 inMicLevel(WebRTC 中将尺度映射到 0~255)等中间参数,计算下一次需要调节的模拟增益值 outMicLevel,并反馈给设备层。
// Scale from VoE to ADM level range. uint32_t new_voe_mic_level = shared_->transmit_mixer()->CaptureLevel(); if (new_voe_mic_level != voe_mic_level) { // Return the new volume if AGC has changed the volume. new_mic_volume = static_cast<int>((new_voe_mic_level * max_volume +static_cast<int>(kMaxVolumeLevel / 2)) / kMaxVolumeLevel); return new_mic_volume; }有些设备商麦克风阵列默认设置比较小,即使将模拟增益调满采集依然很小,此时就需要数字增益补偿部分来改善:WebRtcAgc_AddMic,可以在原始采集的基础上再放大 1.0~3.16 倍,如图 4。那么,如何判断放大不够呢?上一步中模拟增益更新模块最终输出实际为 micVol 与最大值 maxAnalog(255) 之间较小的那个:
*outMicLevel = WEBRTC_SPL_MIN(stt->micVol, stt->maxAnalog) >> stt->scale;即根据相关的规则计算得到的实际值 micVol 是有可能大于规定的最大值 maxAnalog 的,也就意味着将模拟增益调整到最大也无法达到目标音量,WebRtcAgc_AddMic 会监控这种事件的发生,并会通过查表的方式给予额外的补偿。
增益表 kGainTableAnalog:
static const uint16_t kGainTableAnalog[GAIN_TBL_LEN] = {
4096, 4251, 4412, 4579, 4752, 4932, 5118, 5312, 5513, 5722, 5938,
6163, 6396, 6638, 6889, 7150, 7420, 7701, 7992, 8295, 8609, 8934,
9273, 9623, 9987, 10365, 10758, 11165, 11587, 12025, 12480, 12953};
// apply gain
sample = (in_mic[j][i] * gain) >> 12; // 经过右移之后,数组被量化到0~3.16.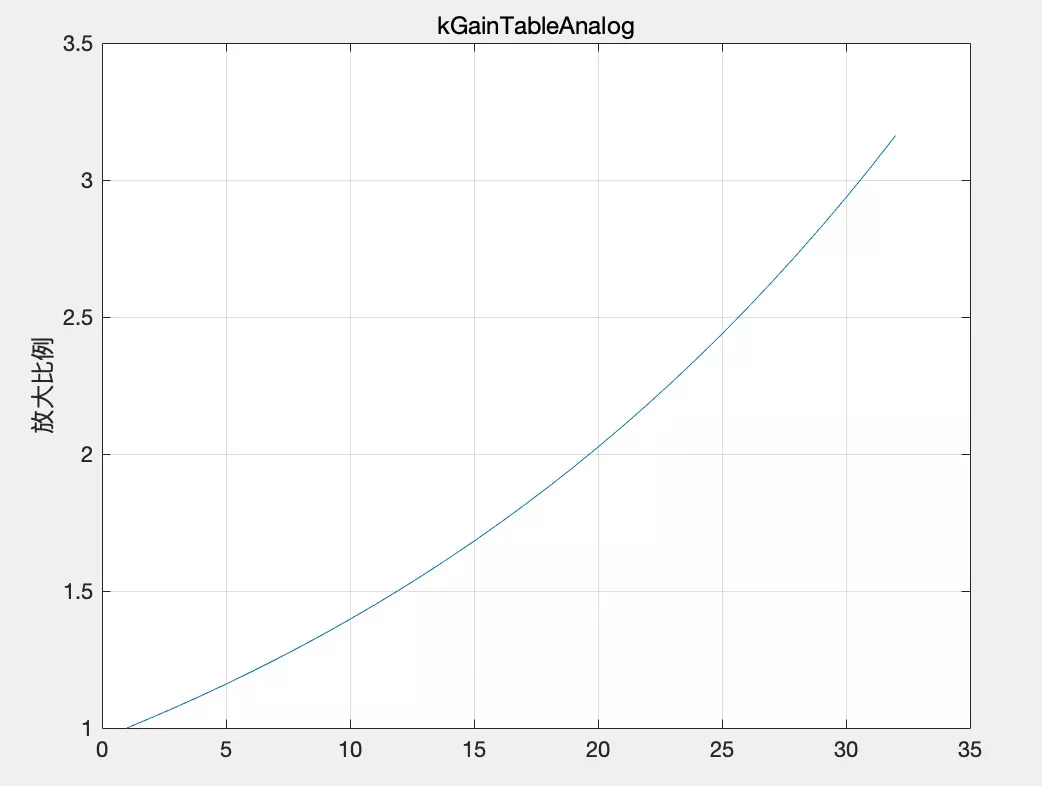
图 4 增益表的增益曲线
每次以 1 的固定步长补偿输入信号,gainTableIdx = 0 表示放大倍数为 1 倍,即什么也不做。
/* Increment through the table towards the target gain.
* If micVol drops below maxAnalog, we allow the gain
* to be dropped immediately. */
if (stt->gainTableIdx < targetGainIdx) {
stt->gainTableIdx++;
} else if (stt->gainTableIdx > targetGainIdx) {
stt->gainTableIdx--;
}
gain = kGainTableAnalog[stt->gainTableIdx];
// apply gain
sample = (in_mic[j][i] * gain) >> 12;存在的问题:
- 无语音状态下的模拟值上调行为;
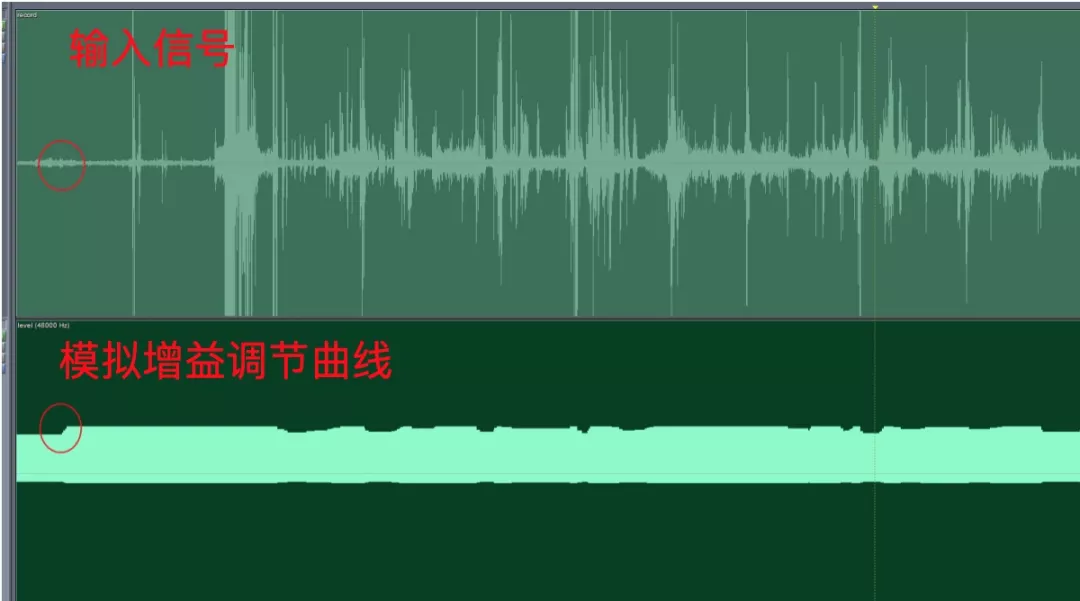
- 调整幅度过大,造成明显的声音起伏;

- 频繁调整操作系统 API,带来不必要的性能消耗,严重的会导致线程阻塞;
- 数字部分增益能力有限,无法与模拟增益形成互补;
- 爆音检测不是很敏感,不能及时下调模拟增益;
AddMic 模块精度不够,补偿过程中存在爆音的风险爆音。
自适应数字增益 - AdaptiveDigital
基于音频视频通信的娱乐、社交、在线教育等领域离不开多种多样的智能手机和平板设备,然而这些移动端并没有类似 PC 端调节模拟增益的接口。声源与设备的距离,声源音量以及硬件采集能力等因素都会影响采集音量,单纯依赖固定数字增益效果十分有限,尤其是多人会议的时候会明显感受到不同说话人的音量并不一致,听感上音量起伏较大。
为了解决这个问题,WebRTC 科学家仿照了 PC 端模拟增益调节的能力,基于模拟增益框架新增了虚拟麦克风调节模块:WebRtcAgc_VirtualMic,利用两个长度为 128 的数组:增益曲线 - kGainTableVirtualMic 和抑制曲线 - kSuppressionTableVirtualMic 来模拟 PC 端模拟增益(增益部分为单调递增的直线,抑制部分为单调递减的凹曲线),前者提供 1.0~3.0 倍的增益能力,后者提供 1.0~0.1 的下压能力。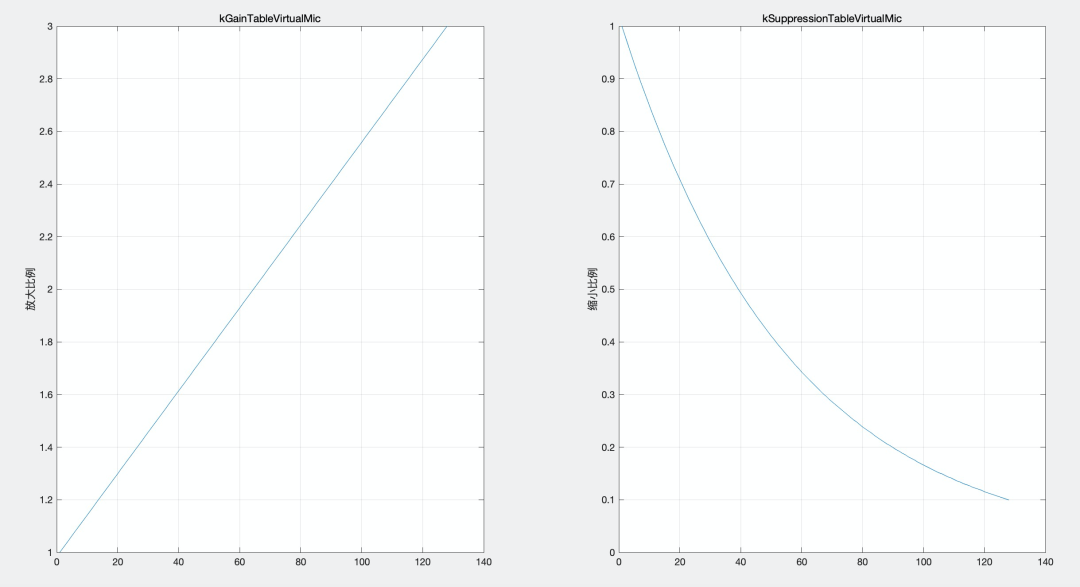
图 5 增益曲线与抑制曲线
核心逻辑逻辑与自适应模拟增益一致。
- 与自适应模式增益模式一样,依然利用 WebRtcAgc_ProcessAnalog 更新 micVol;
根据 micVol 在 WebRtcAgc_VirtualMic 模块中更新增益下标 gainIdx,并查表得到新的增益 gain;
/* 设置期望的音量水平 */ gainIdx = stt->micVol; if (gainIdx > 127) { gain = kGainTableVirtualMic[gainIdx - 128]; } else { gain = kSuppressionTableVirtualMic[127 - gainIdx]; }应用增益 gain,期间一旦检测到饱和,会逐步递减 gainIdx;
/* 饱和检测更新增益 */ if (tmpFlt > 32767) { tmpFlt = 32767; gainIdx--; if (gainIdx >= 127) { gain = kGainTableVirtualMic[gainIdx - 127]; } else { gain = kSuppressionTableVirtualMic[127 - gainIdx]; } } if (tmpFlt < -32768) { tmpFlt = -32768; gainIdx--; if (gainIdx >= 127) { gain = kGainTableVirtualMic[gainIdx - 127]; } else { gain = kSuppressionTableVirtualMic[127 - gainIdx]; } }- 增益后的数据传入 WebRtcAgc_AddMic,检查 micVol 是否大于最大值 maxAnalog 决定是否需要激活额外的补偿。
音频数据流框图如下:
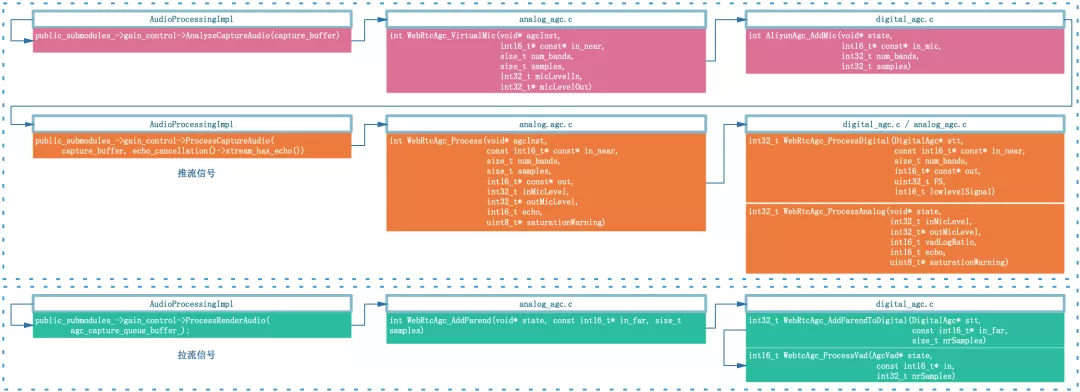
存在的问题与自适应模式增益相似,这里需要明确说的一个问题是数字增益自适应调节灵敏度不高,当输入音量起伏时容易出现块状拉升或压缩,用一个比较明显的例子说明:遇到大音量时需要调用压缩曲线,如果后面紧跟较小音量,会导致小音量进一步压缩,接着会调大增益,此时小音量后续如果接着跟大音量,会导致大音量爆音,需要 limiter 参与压限,对音质是存在失真的。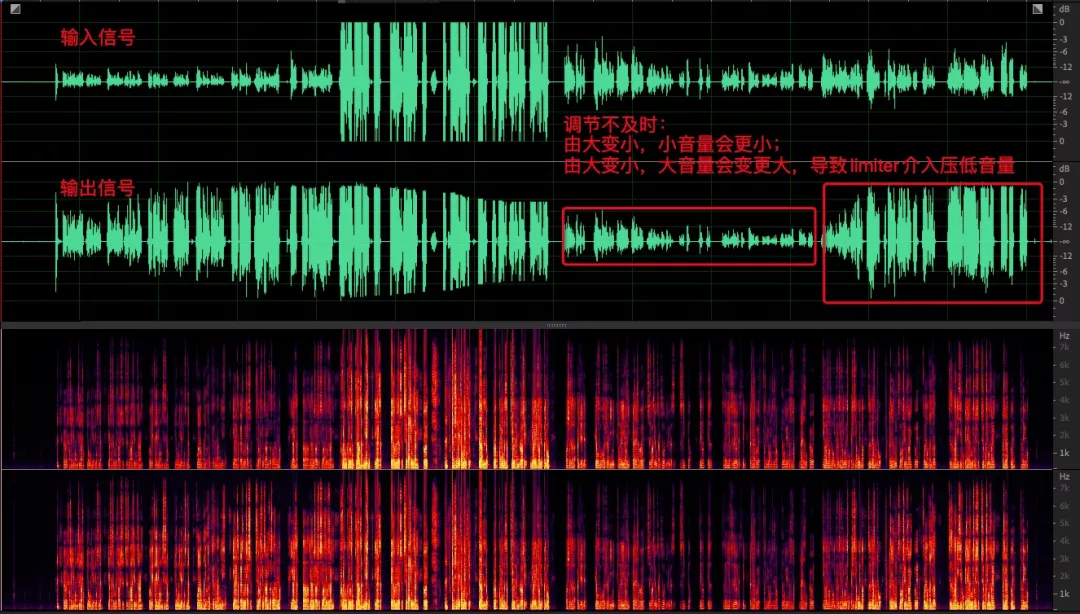
总结与优化方向
为了更好的听感体验,AGC 算法的目标就是忽略设备采集差异,依然能够将推流端音频音量均衡到理想位置,杜绝音量小、杜绝爆音、解决多人混音后不同人声音量起伏等核心问题。
针对上述章节提到的各个模式存在的问题,有如下几点启示:
- 模拟增益调节,必须修复调节频繁,步长过大等问题;
- AddMic 部分精度不够,可以提前预判,不要等到检测到爆音再回调;
- PC 端数字增益和模拟增益模块上是相互独立的,但是效果上应该是相互补偿的;
- AGC 对音量的均衡不应该影响 MOS,不能因为追求灵敏度放弃了 MOS。
另外,代码中很多位运算初读起来比较容易劝退,希望大家抓核心代码,形成整体框架后多实践,再吸收消化。
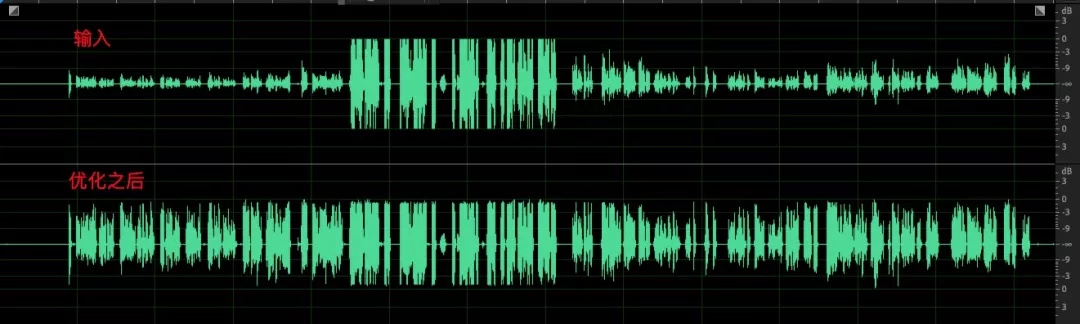
最后,让我们看看优化后的效果:
- 模拟增益调节之后,采集的音频信号音量存在起伏,经过数字部分均衡后音频包络保持较好,音量整体一致;
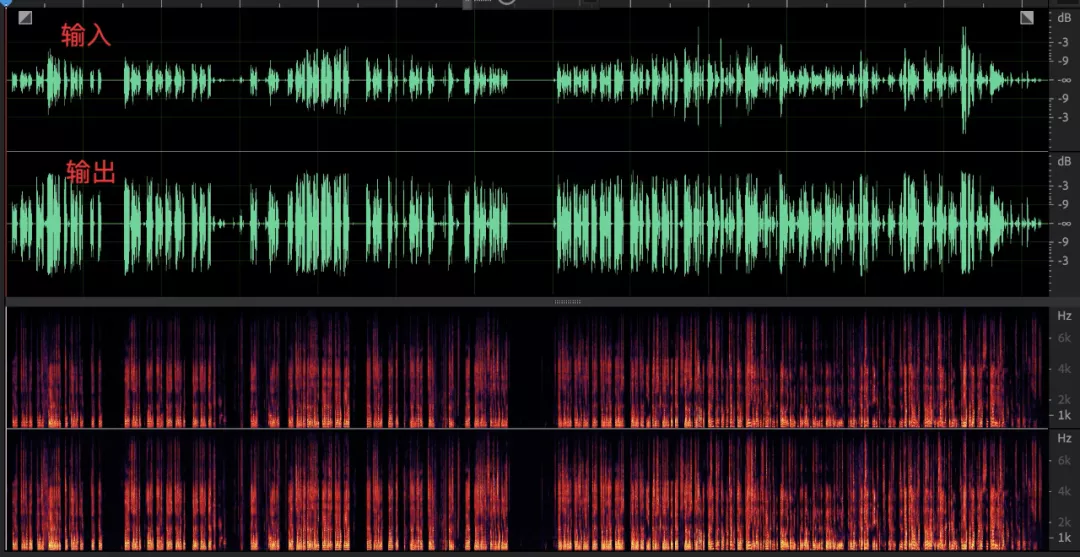
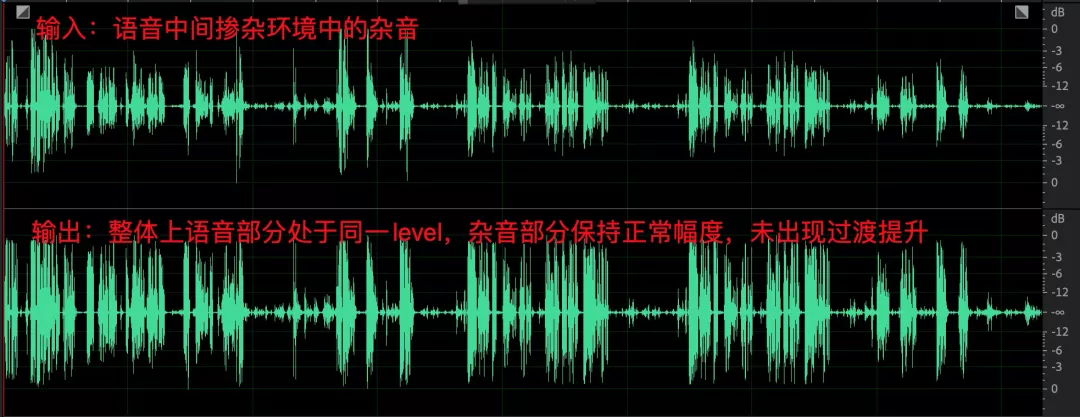
- 语音和环境中的杂音,经过 AGC 之后语音部分音量起伏减小,杂音部分未见明显提升;
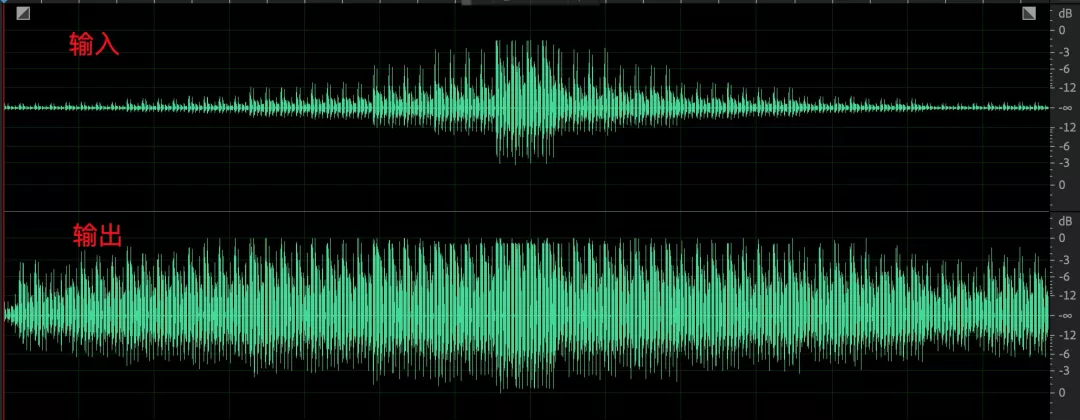
- 一个比较极端的 case,小语音部分最大提升了 35dB,收敛时间保持在 10s 以内。
「视频云技术」你最值得关注的音视频技术公众号,每周推送来自阿里云一线的实践技术文章,在这里与音视频领域一流工程师交流切磋。公众号后台回复【技术】可加入阿里云视频云技术交流群,和作者一起探讨音视频技术,获取更多行业最新信息。

