
ncnn在树莓派1代dsp优化和超频实验
可在不修改本文章内容和banner图前提下,转载本文
电子垃圾迎来了春天
前些日子,去海鲜市场搞来个树莓派1b+,SOC BCM2835,700MHz ARM1176JZF-S处理器,内存512M,无WiFi

树莓派1的cpu是armv6架构,不具备neon指令集,但具备dsp增强指令集
关于 arm dsp 增强指令集
早在 ARMv5TE 和 ARMv5TEJ 架构已经加入了 dsp 增强指令,有 ARM926EJ-S 实现
在 armv6 中进一步扩充了一些 8bit dsp 指令,形成更系统的 dsp 指令集
在 Cortex-M4、Cortex-M7、Cortex-M33、Cortex-M35P、Cortex-M55 等 arm 低功耗系列中也加入了 dsp 指令集,指令基本与 armv6 保持一致
arm dsp 中的关键指令 smlad 能实现 i32 += i16 * i16 + i16 * i16,适合量化神经网络中 sgemm/winograd 做加速
gcc/clang 有宏 __ARM_FEATURE_SIMD32 判定是否编译支持 dsp 指令
gcc-10.1 及更新版本支持 arm dsp intrinsics,头文件为 arm_acle.h
需要使用 inline assembly,以便兼容更老的编译器。由于 dsp 指令的操作数是整数寄存器,在debug模式编译,-fno-omit-frame-pointer 结合 -fpic 后可自由使用的寄存器不足10个,导致错误error: ‘asm’ operand has impossible constraints,需要针对此情况写成分开的inline assembly语句。相较于龙芯 loongson-mmi 使用64bit浮点寄存器,arm dsp不够灵活,寄存器压力也较大。
下面代码引用自 ncnn/src/layer/arm/convolution_winograd_dot_int8.h
#if __ARM_FEATURE_SIMD32
for (; j + 1 < inch; j += 2)
{
// fomit-frame-pointer implied in optimized flag spare one register
// let us stay away from error: ‘asm’ operand has impossible constraints --- nihui
#if __OPTIMIZE__
asm volatile(
"ldr r2, [%0], #4 \n" // int16x2_t _val02 = *((int16x2_t*)r0); r0 += 2;
"ldr r3, [%0], #4 \n" // int16x2_t _val13 = *((int16x2_t*)r0); r0 += 2;
"ldr r4, [%1], #4 \n" // int16x2_t _w02 = *((int16x2_t*)k0); k0 += 2;
"ldr r5, [%1], #4 \n" // int16x2_t _w13 = *((int16x2_t*)k0); k0 += 2;
"smlad %2, r2, r4, %2 \n" // sum00 = __smlad(_val02, _w02, sum00);
"smlad %3, r3, r4, %3 \n" // sum01 = __smlad(_val13, _w02, sum01);
"smlad %4, r2, r5, %4 \n" // sum10 = __smlad(_val02, _w13, sum10);
"smlad %5, r3, r5, %5 \n" // sum11 = __smlad(_val13, _w13, sum11);
: "=r"(r0),
"=r"(k0),
"=r"(sum00),
"=r"(sum01),
"=r"(sum10),
"=r"(sum11)
: "0"(r0),
"1"(k0),
"2"(sum00),
"3"(sum01),
"4"(sum10),
"5"(sum11)
: "memory", "r2", "r3", "r4", "r5");
#else
int _val02 = *((int*)r0);
int _val13 = *((int*)(r0 + 2));
int _w02 = *((int*)k0);
int _w13 = *((int*)(k0 + 2));
asm volatile("smlad %0, %2, %3, %0"
: "=r"(sum00)
: "0"(sum00), "r"(_val02), "r"(_w02)
:);
asm volatile("smlad %0, %2, %3, %0"
: "=r"(sum01)
: "0"(sum01), "r"(_val13), "r"(_w02)
:);
asm volatile("smlad %0, %2, %3, %0"
: "=r"(sum10)
: "0"(sum10), "r"(_val02), "r"(_w13)
:);
asm volatile("smlad %0, %2, %3, %0"
: "=r"(sum11)
: "0"(sum11), "r"(_val13), "r"(_w13)
:);
r0 += 4;
k0 += 4;
#endif
}
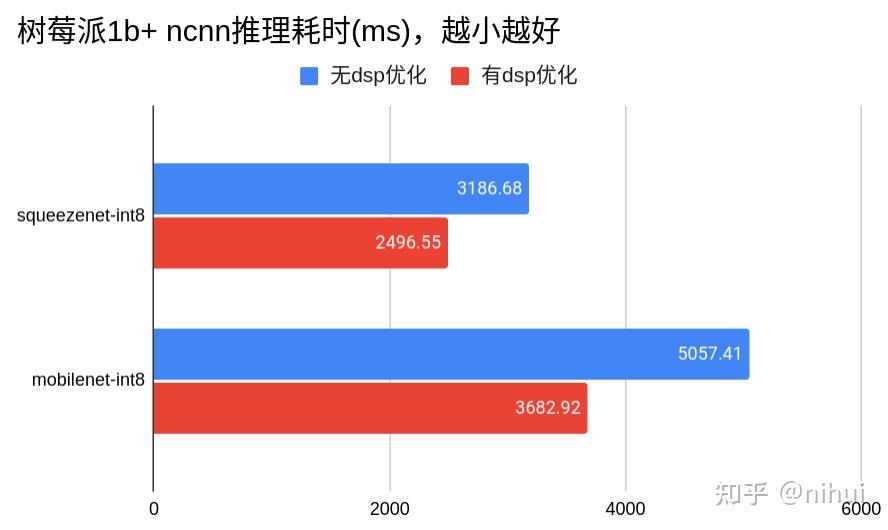
#endif // __ARM_FEATURE_SIMD32ncnn 基于 arm dsp 的优化效果
对比 arm dsp 优化效果,可看出性能提升很有限,这主要是因为 arm dsp 是 32bit simd,本身的运算能力不高(arm neon是128bit simd),并且要占用宝贵的整数寄存器资源,代码循环不能更激进的展开,也不能奢侈把数据放在寄存器中缓存

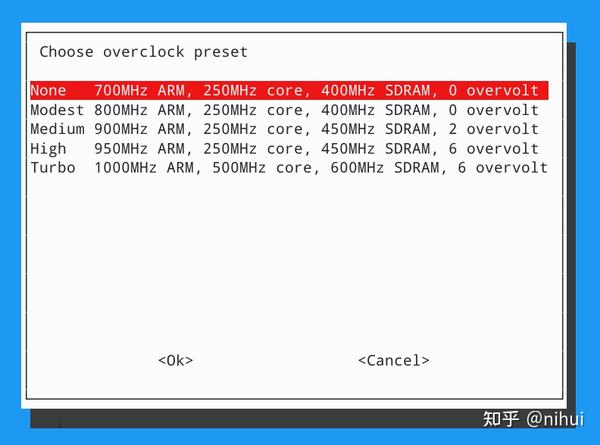
树莓派1b+ cpu 超频实验
运行sudo raspi-config,选择4 Performance Options,选择P1 Overclock,可配置超频
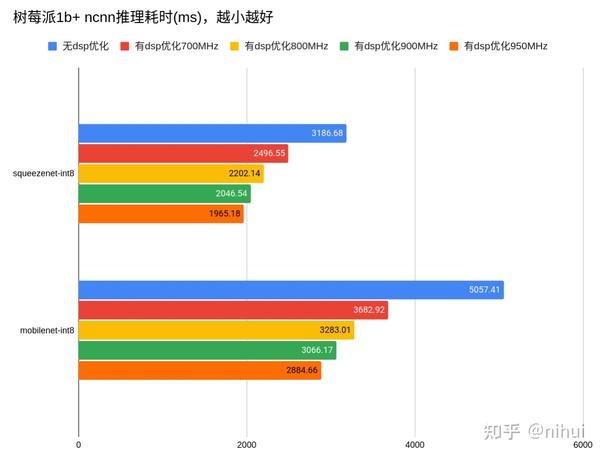
树莓派1代的cpu本身比较凉快,即使超频也依旧凉快。超频后 ncnn 推理速度更快,很棒棒!
1000MHz经常死机,故没有成绩

总结
据说目前市场上能容易获得的最强 armv6 是三星 S3C6410,但是软件生态上树莓派实在是太优秀 qwq
帮armv6优化写完后,惊喜的发现Cortex-M系列也有同样的指令集,以后可以找个Cortex-M的SOC试试效果 :)
作者:nihui
文章来源:知乎
推荐阅读
- 一种融合卷积的ViT模型
- YOLOv7官方开源 | Alexey Bochkovskiy站台,精度速度超越所有YOLO
- BoT-SORT |超越 DeepSORT、StrongSORT++ 和 ByteTrack
更多嵌入式AI相关技术干货请关注嵌入式AI专栏。欢迎添加极术小姐姐微信(id:aijishu20)加入技术交流群,请备注研究方向。

