
导读
以业务为导向的数据库需要满足现代化应用的需要,以 Serverless 数据库为代表,云数据库正在迅速发展成熟,并带来更好的可访问性和高可用性,还有高扩展性与可迁移性。
【墨天轮数据库沙龙-Serverless专场】邀请到亚马逊云科技高级数据库技术专家李君,为大家带来《见微知著 - Serverless 云原生数据库概览》的主题演讲。本次分享从现代应用化改造出发,介绍Serverless数据库的本质与特点,同时也介绍了亚马逊云科技的七大Serverless家族中的DynamoDB 与 Amazon Aurora Serverless 数据库,以下为演讲实录。

李君 亚马逊云科技高级数据库技术专家
为什么要进行应用化改造?
1、现代化应用程序的特性与优势**
传统的开发文化导致新产品和功能的发布周期冗长、运维效率低下、无法支持不断变化的合规性和安全规章等问题,应⽤程序现代化可以快速、⾼效且合规地⽀持业务计划。
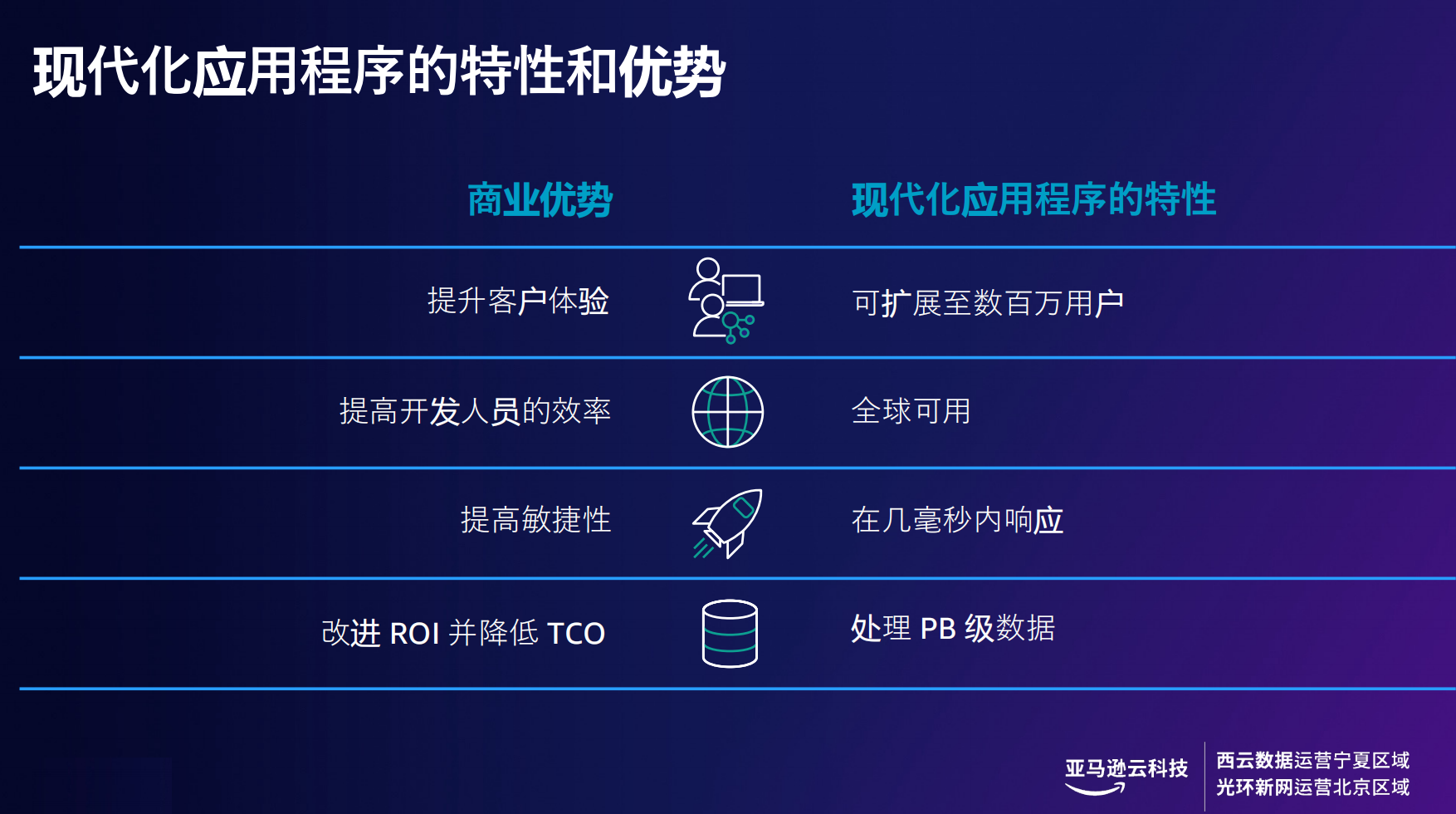
图1 现代化应用程序的特性和优势
现代数据架构从传统的Web服务器+应用程序服务器+数据库服务层的三层数据库架构转变到微服务、解耦架构,因此需要一个构建专门的数据层来满足现代应用架构。
2、亚马逊云科技无服务器数据库家族
亚马逊云科技构建了数据库家族支撑现代化应用开发,云原生系列包括 关系数据库服务Amazon Aurora Serverless,完全托管的 PB 级云数据仓库服务Amazon Redshift,支持键-值存储和文档型数据结构的NoSQL数据库服务Amazon DynamoDB,开源的宽列数据存储Amazon Keyspaces,时间序列资料库Amazon Timestream,完全托管的图形数据库服务Amazon Neptune以及完全托管的分类账数据库 Amazon Quantum Ledger Database ( QLDB ) 等七大数据库。
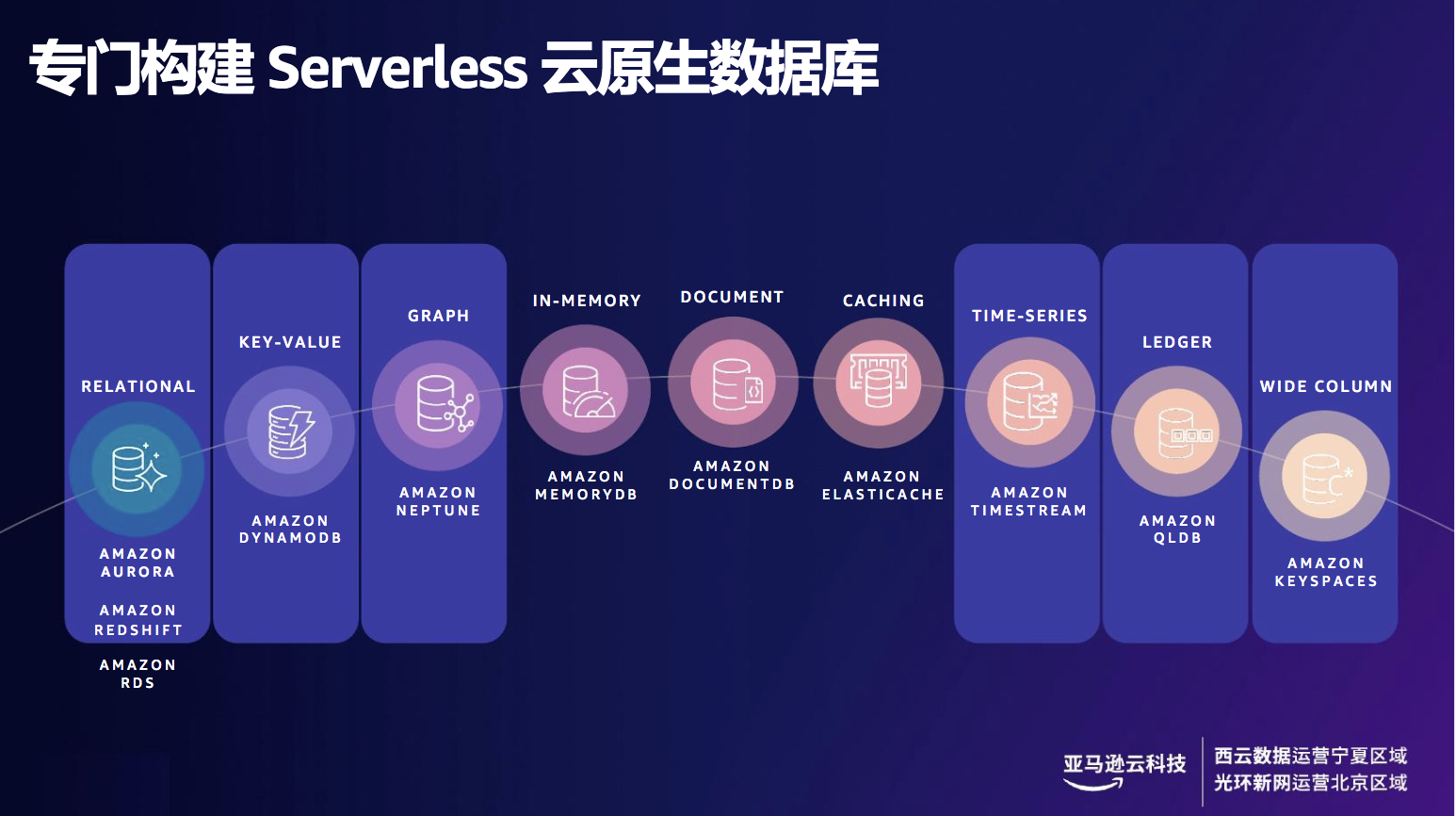
图2 亚马逊云科技Serverless云原生数据库光谱
3、Serverless 数据库介绍
2014年 亚马逊副总裁兼首席技术官 Werner Vogels 博士在 re:Invent 全球大会上发布了Lambda 服务,这项服务重新定义了云计算的 Serverless 发展理念,由此引发了Serverless 第一波浪潮。
Servereless并不是简单等于functions,它的本质为one demand scaling and pricing characterisics(按需使用、极致弹性压缩)。在新时代下,Servereless 实现随用随取,按量付费,成为与普及大众比肩的水电煤资源。
下图展示了Serverless数据库的四大特点,其中最显著的是无需管理服务器的特点,它使开发人员专注构建和运行应用。对于用户而言,最终收益体现在Serverless按使用量付费的设计上。

图3 Serverless数据库特点
Amazon Serverless 系列介绍
1、Amazon DynamoDB**
DynamoDB开创了云原生NoSQL数据库领域,亚马逊NOSQL之旅也是由它开始。
正值2004年的假日购物季,使用著名关系型数据库的 Amazon 电子商务平台由于超过负载而导致了数小时宕机。在启动COE(纠正错误是通过记录和解决问题来提高质量的过程)流程后,工程师梳理出亚马逊电商业务系统对数据库需求,70%的调用对单行进行操作,20%的调用返回单个表中的行集合。
三年后,AWS 于 2007 年发布了《Dynamo:Amazon 的高可用性键值存储》,论文介绍了 Dynamo 的设计和实现,它是一种高度可用的键值存储系统,亚马逊的一些核心服务使用它来提供“永远在线”的体验,由此DynamoDB 诞生了。
2012年,DynamoDB作为基于云的 NoSQL 数据库服务被正式发布,并于2016年位居 Gartner MQ 领导者象限。在发布的十年内,DynamoDB一直作为零层依赖项助力大多数亚马逊服务。
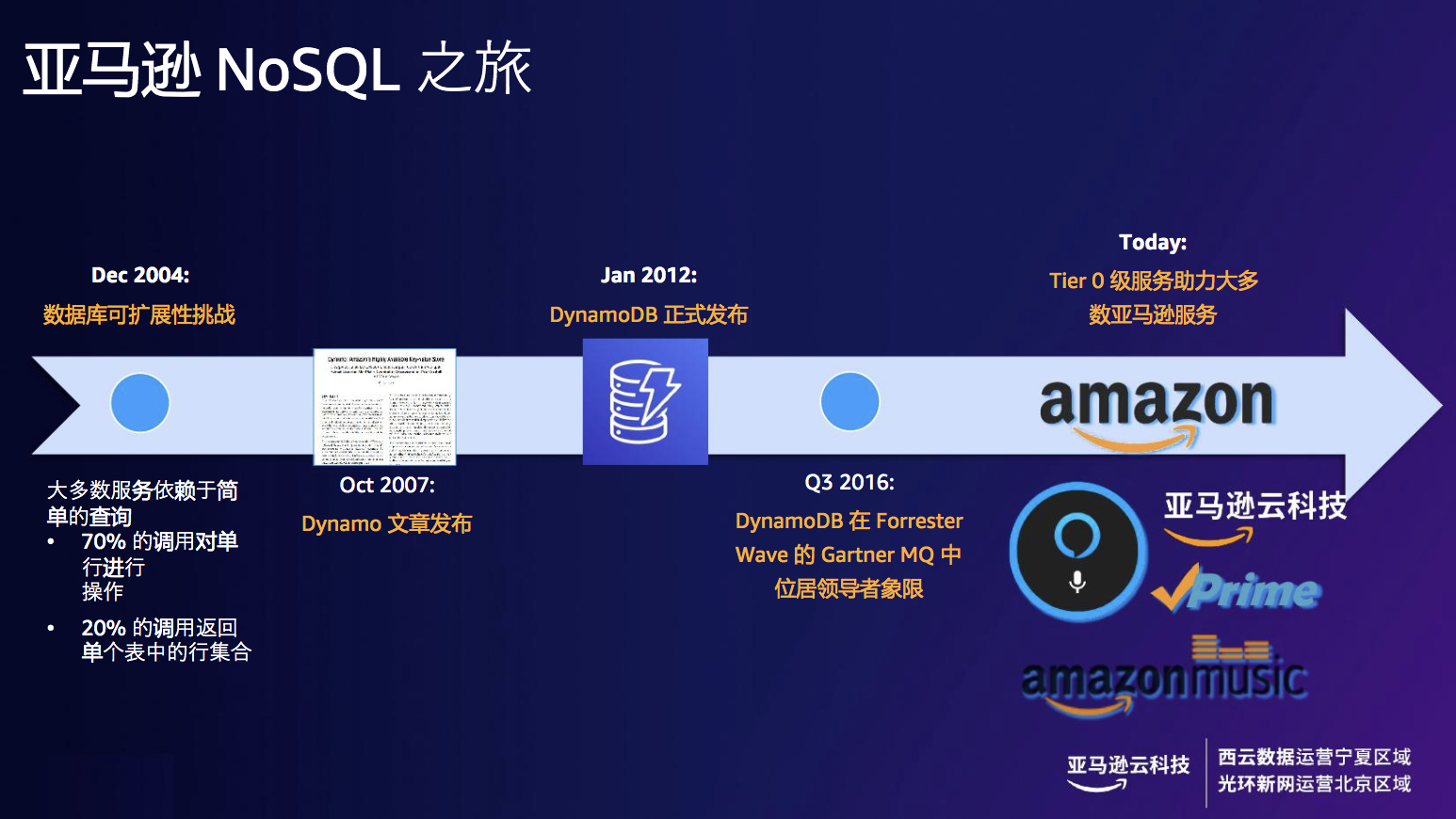
图4 Amazon DynamoDB 发展历程
Amazon DynamoDB作为快速且灵活的 NoSQL 数据库,规模没有限制,具有大规模高性能、无需管理服务器、适合大型企业、全局表的特性。
DynamoDB 能够在PB级规模下实现个位数毫秒延迟,最新2022 re:Invent keynote 上提到,DynamoDB每天收到的请求达到十万亿次,它能够真正实现全局表为应⽤程序提供多区域复制,为普通表提供99.99%的可用性SLA,为全局表(跨多个AWS region进行跨表复制)提供99.999%的可用性SLA。

图5 Amazon DynamoDB 特性
在各行各业,客户依靠DynamoDB 支持其任务关键型工作负载。
在银行和金融行业中,DynamoDB 被应用于处理欺诈侦测以及用户交易等场景。在游戏行业中,DynamoDB能够实现玩家数据无限量存储,不管是TB或是PB级别的数据,都能做到毫秒级响应延迟,相比较存储规模上升而性能对应下降的关系型数据库,DynamoDB表现出了明显的优势。对于广告技术中用户点击行为归因的场景,NoSQL数据库DynamoDB也是非常理想的选择。
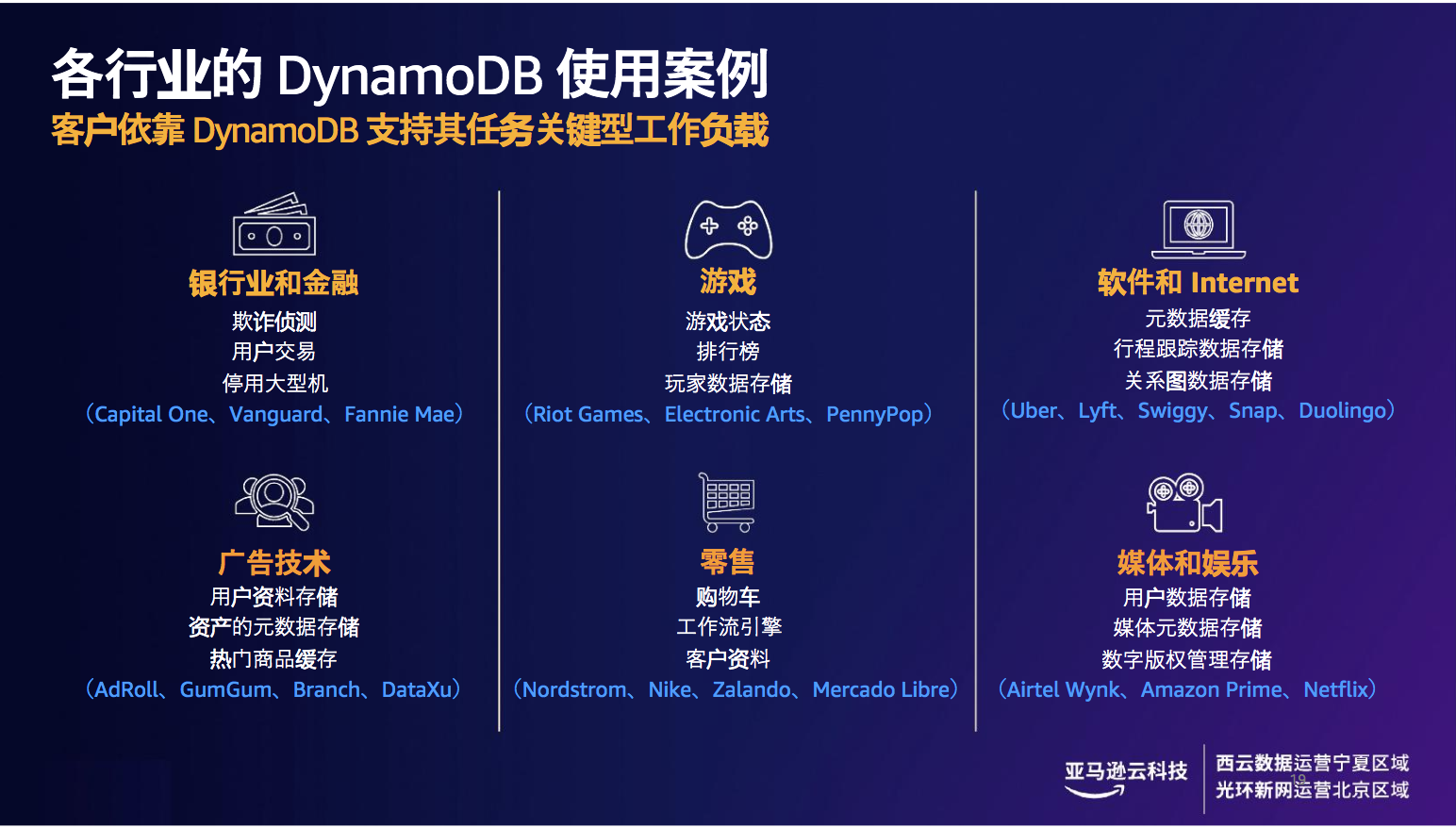
图6 各行业的Amazon DynamoDB 的使用案例以及部分可公开客户名
2、Amazon Aurora Serverless
刚才对 Serverless 数据库鼻祖ynamoDB的发展历程、特性以及使用案例做了介绍,下面就来提一提亚马逊云科技中历史增长最快的数据库服务Aurora Serverless。
Amazon Aurora是专为云环境打造的 MySQL 与 PostgreSQL 兼容型关系数据库,提供与商业级数据库相当的性能与可⽤性,但成本仅为其⼗分之⼀,具有高性能可扩展、高可用持久性、高度安全、完全托管的特性。
下图展示了Amazon Aurora 的架构,跨3个可用区的6个副本,以实现高可用性、持久性和性能,架构涉及存储和计算的分离。同时Aurora 使用 4/6 的仲裁机制解决数据库组件故障和性能降级的问题, 对于每个逻辑日志写入,当发出六项物理复制写入指令,在其中四项写入指令完成时视为写入操作成功。
下图展示了Amazon Aurora 的架构,跨3个可用区的6个副本,以实现高可用性、持久性和性能,
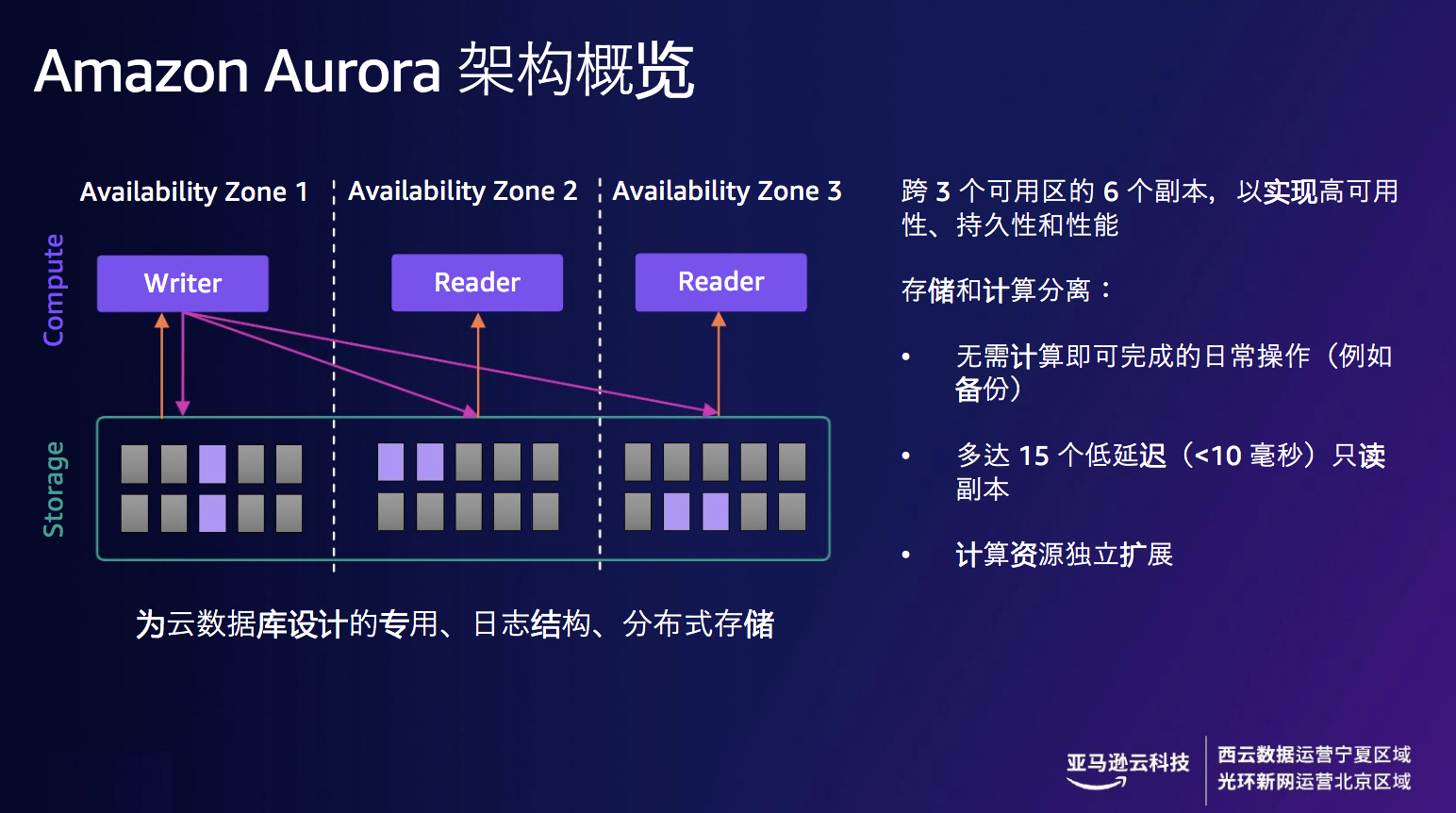
图7 Amazon Aurora Serverless 架构概览
在成本与管理负担之间找到一个平衡点,是数据库容量管理亟需解决的问题。容量不足,用户体验随之下降;按照峰值配置,成本对应上升;持续监控和扩展又会导致理困难甚至停机。
- Amazon Aurora Serverless v1
Amazon Aurora Serverless v1 是Amazon Aurora的按需自动扩展配置,能够很好解决这一痛点,warm pool(资源热池) 的设计提供按需自动伸缩配置, 根据CPU以及当前的连接数进行扩展。Amazon Aurora与MySQL 与 PostgreSQL 相兼容,MySQL GA始于2018年,PostgreSQL适于2019年。 其中Aurora MySQL容量为 1-256 ACU,最大可扩展至488 GIB RAM。
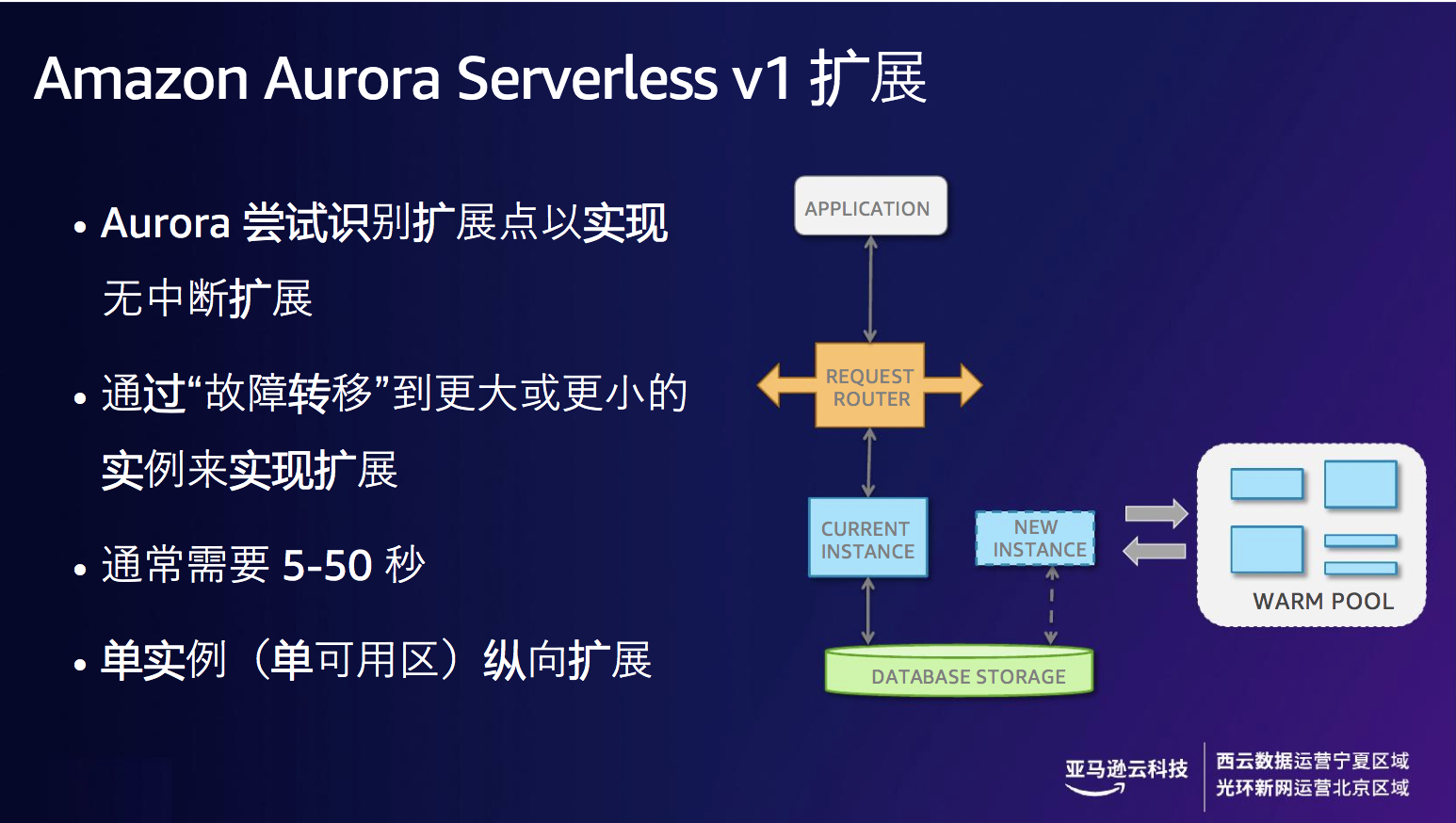
图8 Amazon Aurora Serverless v1 扩展能力
- Amazon Aurora Serverless v2
Amazon Aurora Serverless v2是 v1的升级版本,于2022年发布。它可即时扩展以支持要求最苛刻的应用程序,与为峰值容量配置相比,可节省高达 90% 的成本。同时Aurora Serverless v2 提供全面的 Amazon Aurora 功能,包括多可用区支持、全局数据库、RDS 代理和只读副本。
即时&原地扩展是Aurora Serverless v2 重点迭代的部分。它一秒内可以实现CPU和内存资源的原地扩展,正在运行的数十万项事务不会因为扩展受到影响,后端持续监控和扩展计算节点,在保持状态的同时,后台对空闲实例进行移动,Aurora Serverless v2 的收缩速度是 v1 版本的15倍。
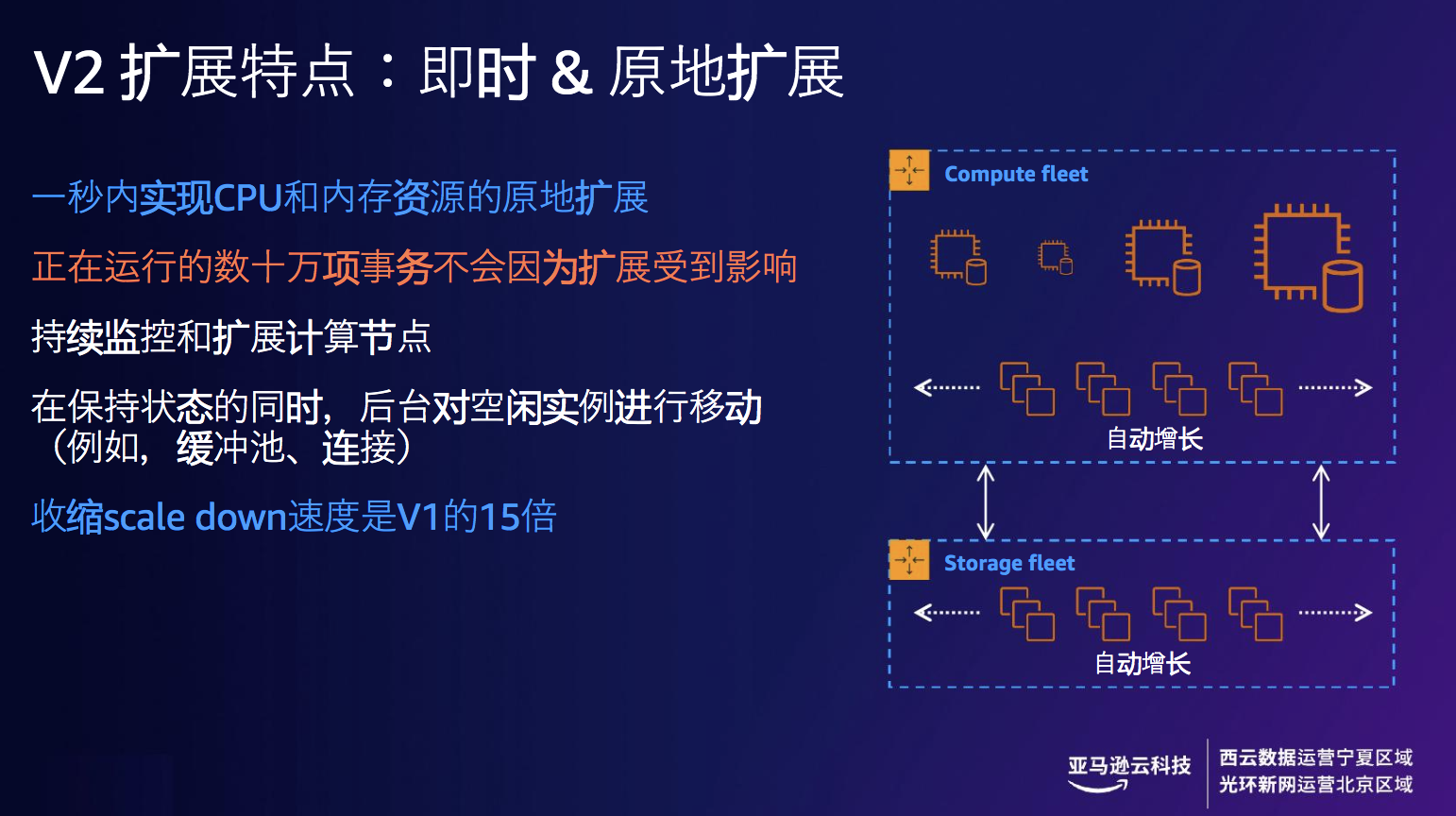
图9 Amazon Aurora Serverless v2 扩展特点
谈到Aurora Serverless v2 的扩展能力,就不得不提及它的细粒度容量以及扩展维度。
Aurora Capacity Unit(ACU)是Aurora Serverless v2 的容量测量单位,每个 ACU 都是大约 2 GiB的内存,CPU 和⽹络性能跟 预置Aurora 实例 配⽐相当, 初始容量最低可设置成 0.5 ACU (1 GiB),细粒度扩展可以⽀持 0.5 ACU 增量。Aurora Serverless v2的扩展维度包括可预测的扩展速率,CPU利用率、Memory使用情况、Network吞吐量。

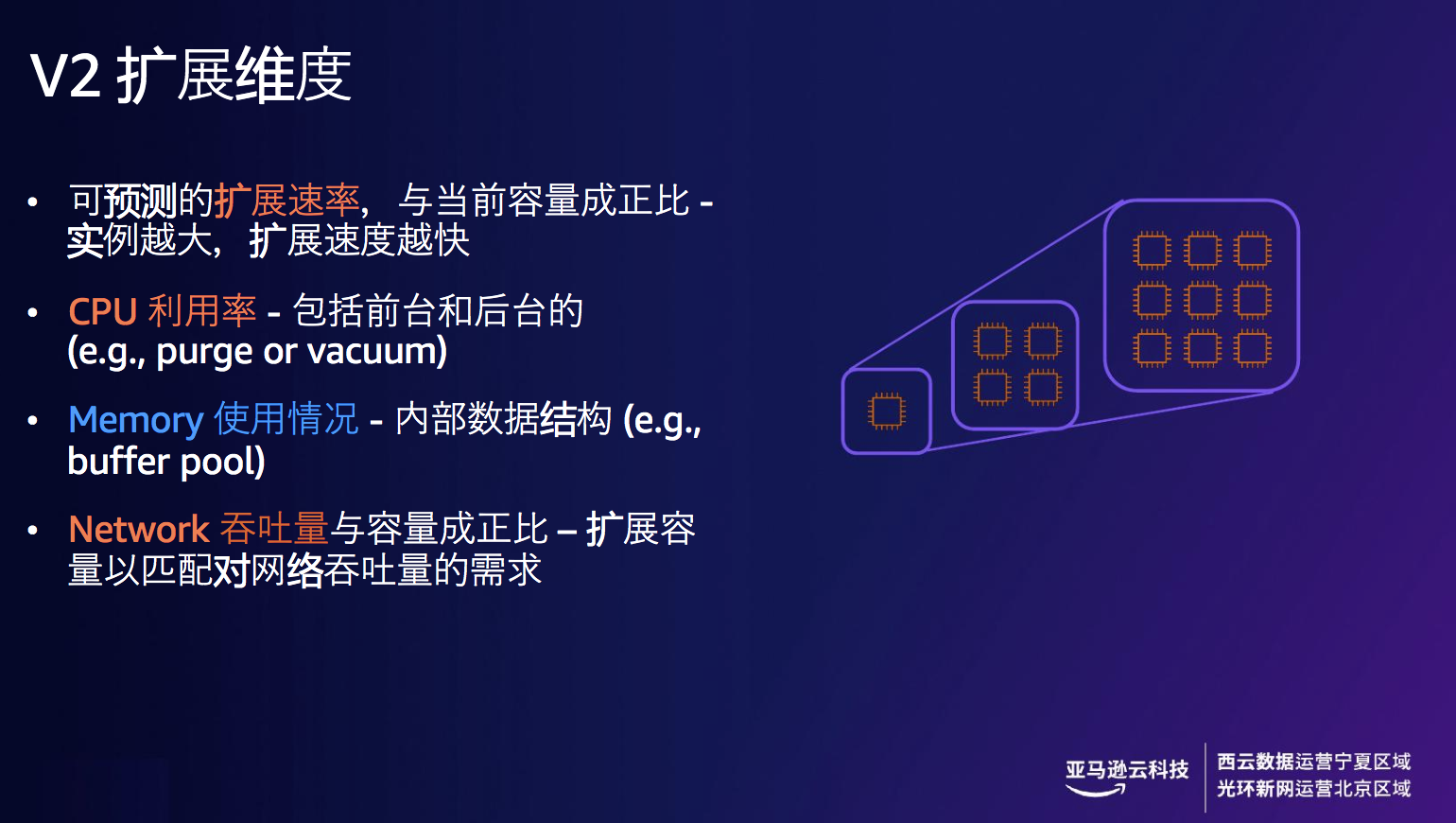
图10-11 Amazon Aurora Serverless v2 细粒度容量调整与扩展维度
Amazon Aurora Serverless v2 非常适合各种应用程序。例如,面对业务快速增长场景与海量多租户场景时,当拥有数十万个应用程序的企业,或拥有具有成百上千个数据库的多租户环境的软件即服务 (SaaS) 供应商,可以使用 Amazon Aurora Serverless v2 来管理整个SaaS应用中众多数据库的容量,同时还适用于业务吞吐量波动明显的场景,如游戏业务、电商业务、测试环境等,以及无法预估吞吐量的新业务系统。
我们推荐用户在使用Aurora Serverless v2时,与现有的预配置实例作混搭。Cluster endpoint为数据库集群的读/写连接提供故障转移支持。下图所示,写节点做预配置,两个读节点进行读写分离,当写节点出现故障,Cluster endpoint帮助及时归档在读节点上,当写节点流量上来时,可以自动瞬时向外扩展,在整个过程中共享一份cluster volume(集群共享卷)。
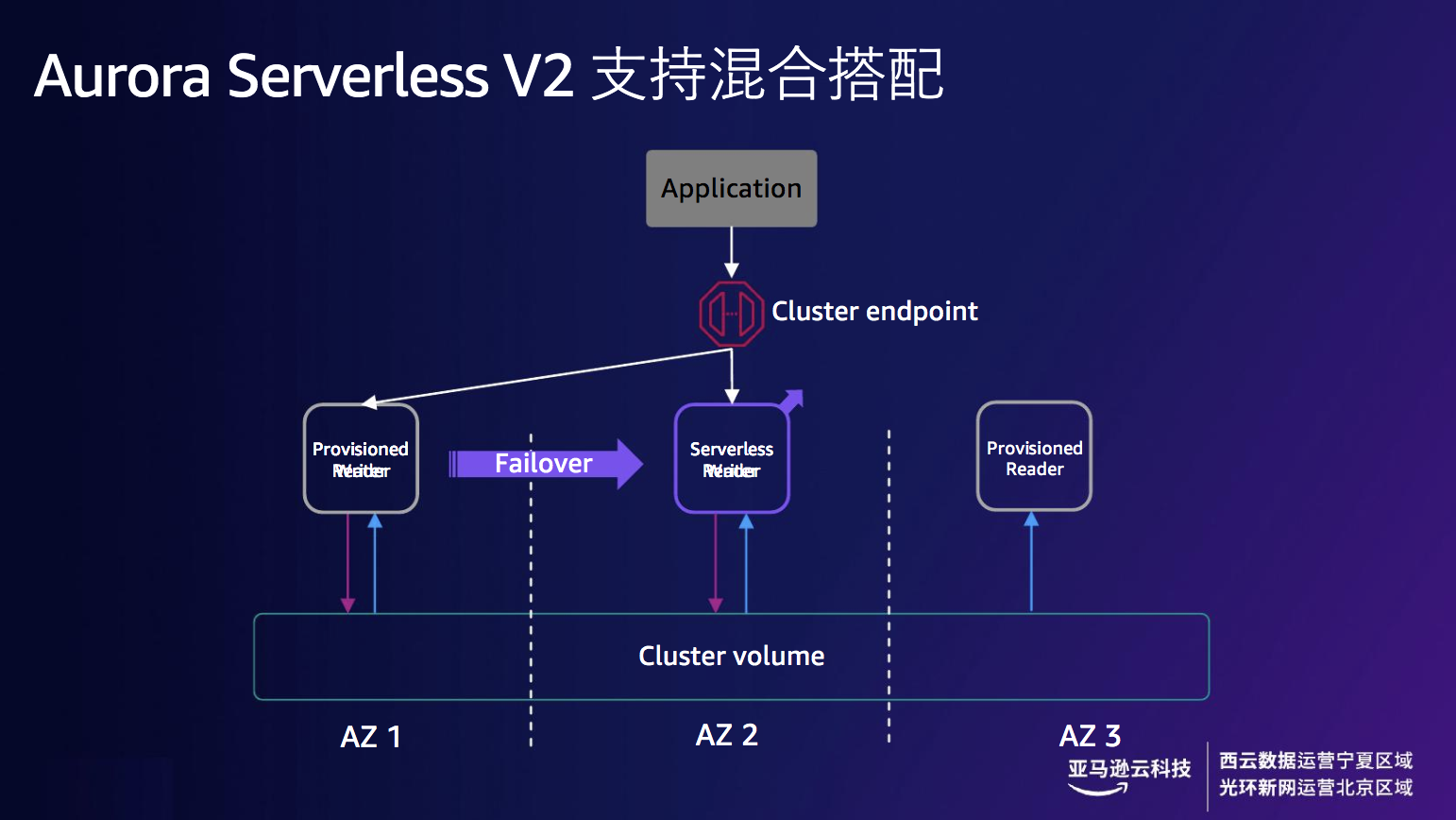
图12 Amazon Aurora Serverless v2 支持混合搭配
点击视频查看【Demo: Aurora 预置实例和Serverless V2实例的混合配置】
由于时间关系,在这里就不再一一展示亚马逊云科技Serverless七大家族的产品。用“关系型数据库做一刀切”的方法已经是过去时,选择正确的数据库可以让开发专注于构建满⾜特定业务需求的应⽤程序,帮助业务快速扩展,开发人员专注创新,以及加速产品的上市时间。
感兴趣的小伙伴可以关注下方二维码,按需学习亚马逊云科技技能。

图13 亚马逊云科技技能学习地址
我今天的分享就到这里,谢谢大家!
更多精彩内容,欢迎大家观看现场视频回放与会议资料
视频回放:https://www.modb.pro/video/7710
会议资料:https://www.modb.pro/doc/93246
- 本文为墨天轮编辑部原创首发文章,点击查看原文:https://www.modb.pro/db/591463
墨天轮技术社区正在举办【有奖问卷|墨天轮2022年数据库大调查】活动,诚邀各位朋友参与!只要以【账号登录状态】提交问卷即可获得奖励,更有机会获得大疆DJI无人机、VIP年卡、电脑支架等奖品。邀请好友填写还可以领取现金奖励!期待大家的参与!
点击即可填写:https://www.modb.pro/event/767

