
//
编者按:在视频云升级、直播行业走向成熟的大背景下,金山云如何通过整合边缘云和相关计算能力,保持在行业的重要位置?LiveVideoStack 2023上海站邀请到金山云的朱岩老师,和大家分享金山云在直播架构方面的演进以及在边缘计算场景下的探索。
文/朱岩
整理/LiveVideoStack
视频云是一个极其“高效”的行业,金山云也很早加入了直播场景的 “技术升级”行列。今天和大家分享金山云在直播架构方面的演进以及后续在边缘计算场景下的探索。
我的分享分为以下内容:①回顾金山云直播的演进过程,②分析金山云直播能够和边缘云计算擦出什么火花,③最后进行总结。
-01-
金山云直播1.0—刀耕火种
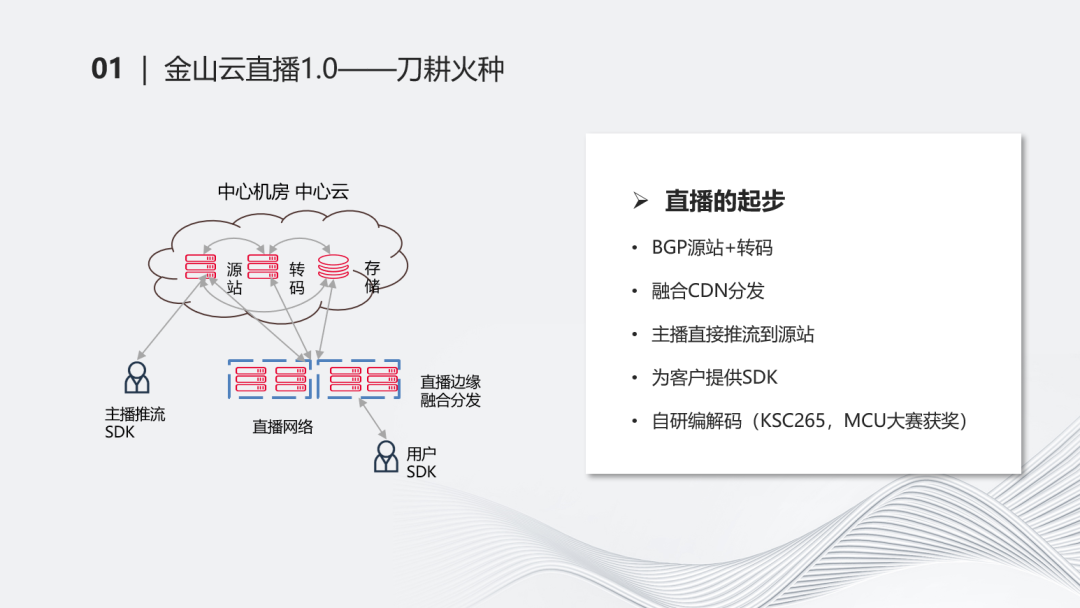
首先看直播的情况。最早在2014、2015年,金山云开始做直播相关的业务。最早的时候是一个比较简单的架构,我们称之为刀耕火种。左边这张图,主要是BGP源站+转码的能力,融合CDN分发,为客户提供SDK的能力。主播直接通过推流的方式把内容推流到源站,再通过边缘场景进行融合分发。
在这个过程中比较有亮点的是,当时我们自研了KSC265编码器,获得了MCU大奖。但是整体的架构是比较简单的,这也是很多直播架构开始时的样子。
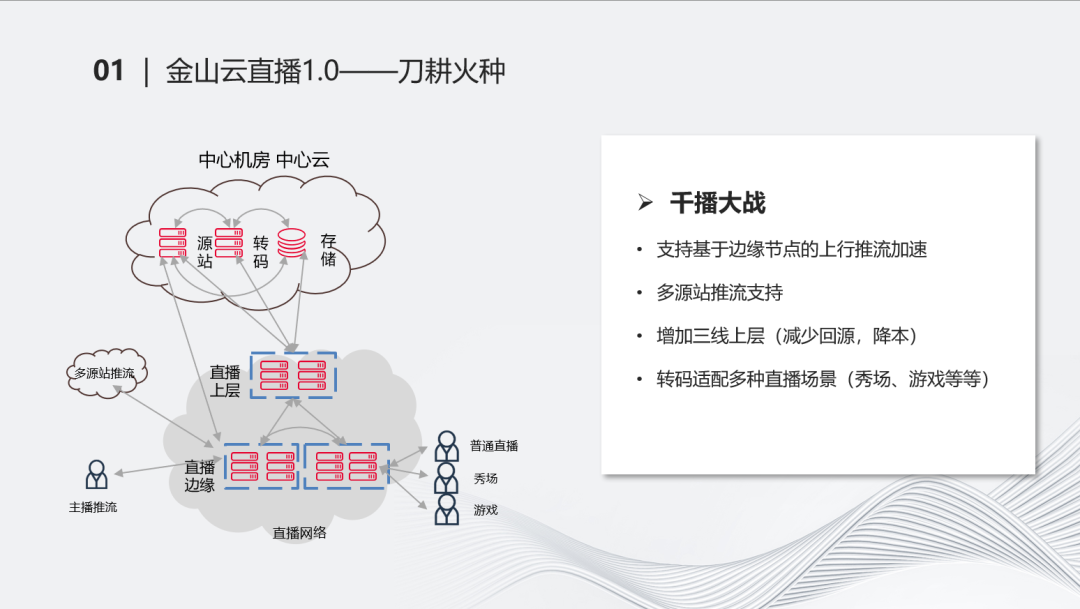
伴随着直播开始,紧接着到来的就是千播大战。我们增加了直播上层,加入这一层后减少了回源成本,提高了很多命中率。同时我们逐步支持边缘推流的方式,使得这种推流加速效果更好一些。
很多的客户、友商加入进来后,我们需要把流同时推到不同的源站上,所以我们在推流的时候也要做一些源站的多流推流支持。在这个时期,我们的转码做了很多相关场景的适配,例如秀场、游戏等等,不同的场景有不同的转码诉求。这个时期的直播(架构)比较像后续直播,分为上层、源站、边缘层几个场景。
-02-
金山云直播2.0——关注质量与成本
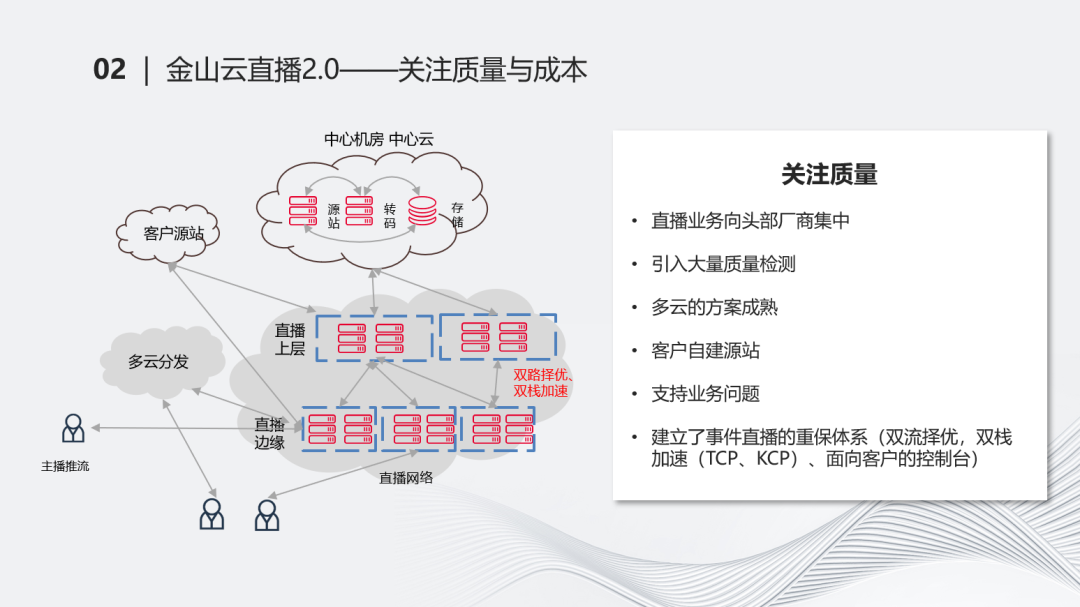
紧接着,进入到更升级的状态,大家开始关注质量和成本。这个时期,直播开始向头部的厂商集中。千播大战以后,很多其他的厂商开始逐渐聚拢起来,字节逐渐开始成为直播的头部。这个时期,一方面是直播集中开设后,我们接触的甲方逐渐开始关注质量。我们引入了很多质量检测的方法,包括额外的第三方检测的内容。另一方面,在多云分发的场景下,我们也融合起来了。例如金山云的直播与其他云的方案融合起来去实施。整个过程是我们逐渐把它做成熟的过程。从业务向头部厂商集中开始,客户也开始自己建源站,自己做这些源站的内容。所以我们也要把直播的流推到其他的源站上。
在接触很多的客户后,我们发现直播的特点和点播不太一样。点播是大家殊途同归的状态,没有固定标准,但最后的标准长得极其一致。直播的标准化没有那么强,不同的客户接进来之后会面临着业务支撑的问题,统一性并没有很强。在这个时期,我们也关注了很多业务支撑的问题。基于这些质量和业务的问题,我们也建立了很多重保体系。像事件直播,如重大赛事、重大发布的直播,做了很多诸如像双流择优,双栈加速这些能力。最后在访问上层的时候,我们其实是从两个甚至多个上层上去访问数据。即使出现网络的抖动或信息中断的情况,我们也可以保证关键直播不中断。同时,引入TCP、KCP这些协议的能力,可以使得每一帧都能有及时的响应。整个过程都在不断地强调质量、可靠、稳定性的能力。
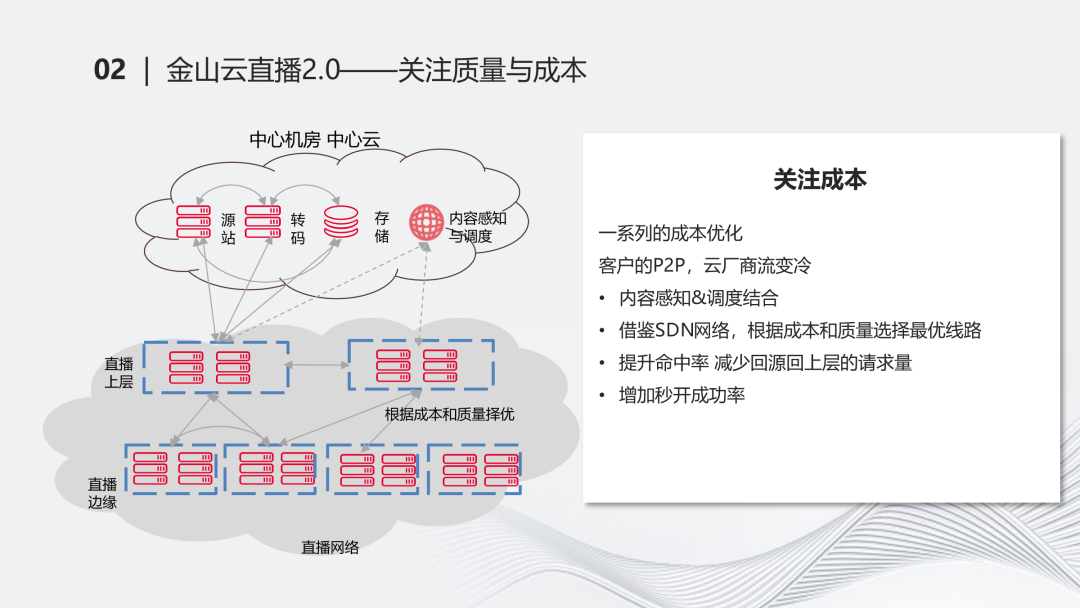
关注完质量后,也要关注成本。我们做了一系列成本的优化。在这个时期,客户也开始做P2P速的能力。我们云产商这部分直播的量会从很热的状态会变成比较冷的情况,这种情况下,在成本上会比较受限。我们加入了内容感知和调度结合等能力,最终可以调度到每条流。每条流可以从需要来回穿梭的过程转化为直接指到相关的上层上去,降低了回源或者向上层请求流量的情况。
借鉴了SDN网络的能力,根据成本和质量择优选择链路,在成本允许的情况下,我们会选择更优的链路,这实际是从树状结构开始往网状结构过渡的过程,秒开成功率等也有了更好的效果。“我们向冷流要成本,向热流要质量。”冷流带来了很多成本问题,在不够热或回源率访问上层时,它的频率会比较高。但是热流更容易缓存到相关的流,冷流就比较难。所以我们向冷流要成本,把冷流做重要的优化。热流在成本上不容易深入优化,在这时向热流要相关质量的能力。
-03-
金山云直播3.0——质量、出海、RTC
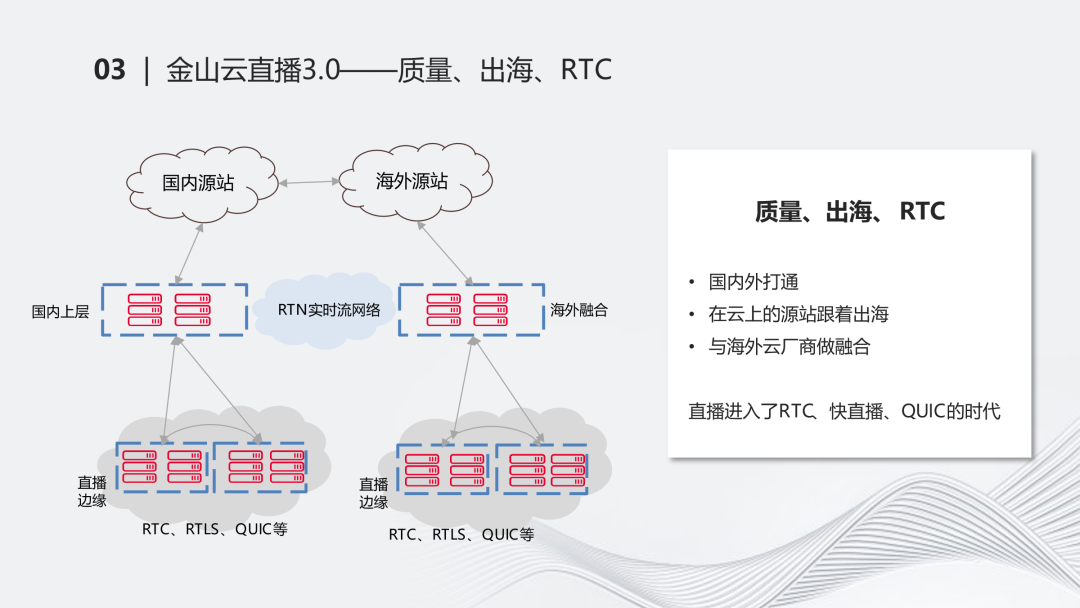
紧接着,我们跨到了疫情时期。这段时期RTC爆火,我们当时做了几件事情。第一是直播的出海。这个过程中,我们面临的是整个海外源站和国内源站打通的问题,在海外怎么建设网络,以及和海外的相关的厂商进行融合的问题。一方面,我们在海外不一定能自建网络,需要和海外的融资商进行融合。另一方面是回国的情况比较艰难,所以和国内外的打通、云上的出海比较困难。我们及时做了RTC相关的产品和调用,这个时期,直播也进入了RTC、快直播的时代。原来的直播可能延迟十几秒,在RTC这个时代我们可以做到秒级的延迟。海外对QUIC会更加友好。基于UDP的协议在海外受的限制较少,我们逐渐增强了QUIC的能力。现在,金山云的QUIC在业内和大家不分伯仲。QUIC本身在国内比较受歧视,国内对于UDP的限制比较多,QUIC目前在国内并没有完全发展起来,但我们在国内也有了不少应用的场景。
-04-
金山云直播4.0——架构成熟 整合边缘云能力
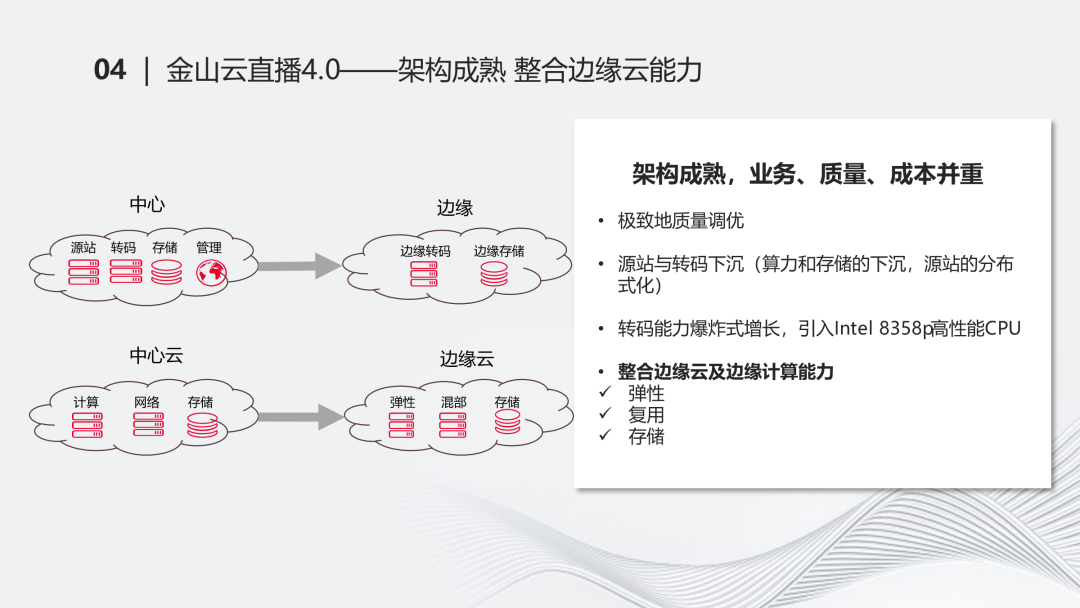
从整体上看,从最早做直播时一个普通源站和一个融合边缘的情况,到逐渐把它上层,网络、出海、RTC这些协议加速能力后,最后围绕着质量、成本,直播逐渐成熟起来,形成了比较完善的体系,有完整的产品能力。同时在质量、成本上也有完整的监控体系。最终,在各种协议层面上,我们支持了基本上市面上所有的协议。在这个时候,直播就逐渐走向了成熟。
直播架构走向成熟后,我们下一步其实还在升级。在升级什么呢?是我们想到的一些思路,我们逐渐把它从中心往边缘进一步下沉。架构成熟后,无论是业务、质量、成本,都还得重视。所以我们做了质量调优,大概有一百多项。
从中心往边缘下沉的思路,实际上也是边缘计算在做的。比如把源站转码这部分下沉,算力、存储这部分也逐渐下沉下来。我们本身的存储在源站时一直处于中心云的场景下,但从成本的角度要求我们在边缘的场景下也有存储。源站逐渐呈分布式化,而不是集中在一两个中心云的场景下。同时我们也希望利用边缘计算的能力,使边缘计算的弹性、复用、存储的能力有更深度的整合,让直播业务不再是孤军奋战的状态。
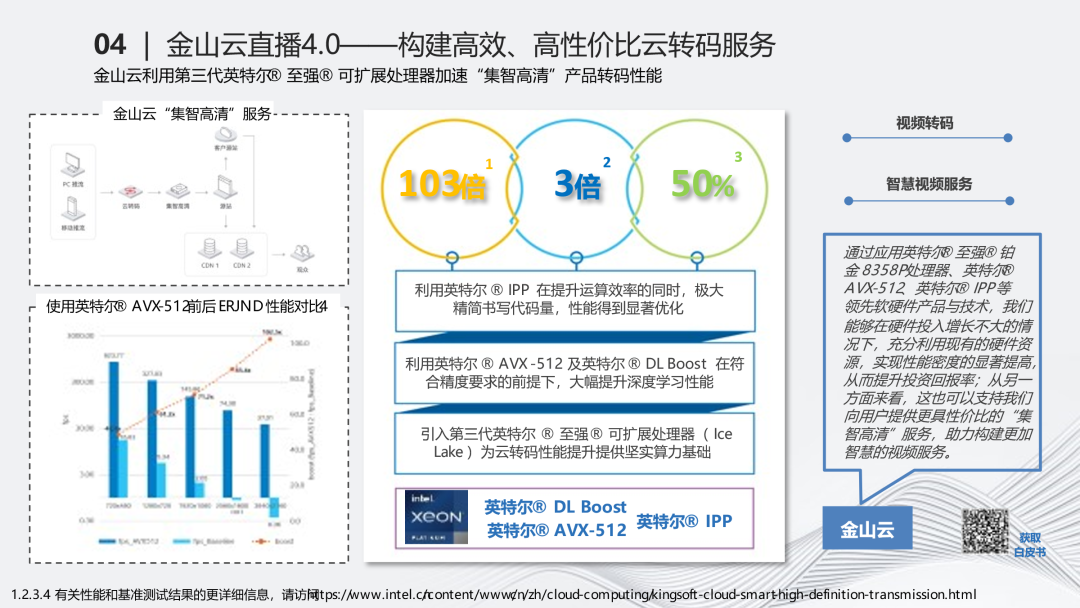
在这个过程中,转码的流量有了爆炸式的增长,增加了很多倍。我们引入了诸如像英特尔8358这类高性能计算的能力的CPU,帮助我们解决了转码、边缘计算的问题。英特尔的这些CPU实际上有很高的CPU密度,比如8358P达到了128核的状态,它的下一代8458P达到了160核。在CDN的场景下用这种CPU的次数不多。因为在CDN的场景下,更多的是大流量转发,对核数的要求不高。但对于高性能计算的场景,无论是计算密度或本身计算的单核效能都显得很重要。单核的效能,转码对延迟很敏感,核多的时候,主频下来后会影响转码的延迟性。8358和8458比较好地兼容了两者的能力。另一方面,在边缘计算的场景下,也需要很多核。在计算类的场景下,更多需要的是核多,而不是很专业的系统。核越多,越有利于我们在资源上做更好的运营和售卖的能力。
-05-
边缘计算时代
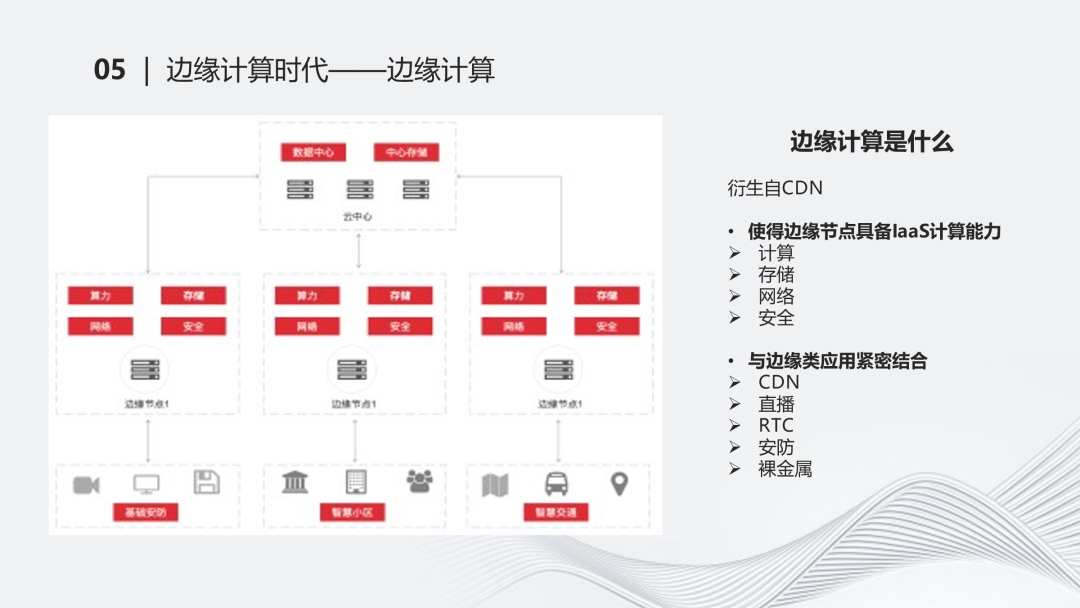
从中心到边缘,我们从中心云的源站转码、存储,逐渐转变为缘的转码和存储。从中心云的计算存储能力下放到边缘云的能力,能够提供弹性、混部、存储的能力。金山云很早就开始卷边缘计算了。边缘计算一开始衍生自CDN,使我们在边缘节点具备laaS的能力,像计算、存储、网络,包括相关的安全的场景,包括它的应用场景,如CDN、直播、RTC等。这些场景都是比较成熟的。对云边协同的资源管控,金山云支持虚机、容器、裸金属。这一系列的能力都是完全具备的。这样的能力使得我们在直播和边缘计算的场景下能够擦出一些火花,把资源或相关的逻辑融合起来。
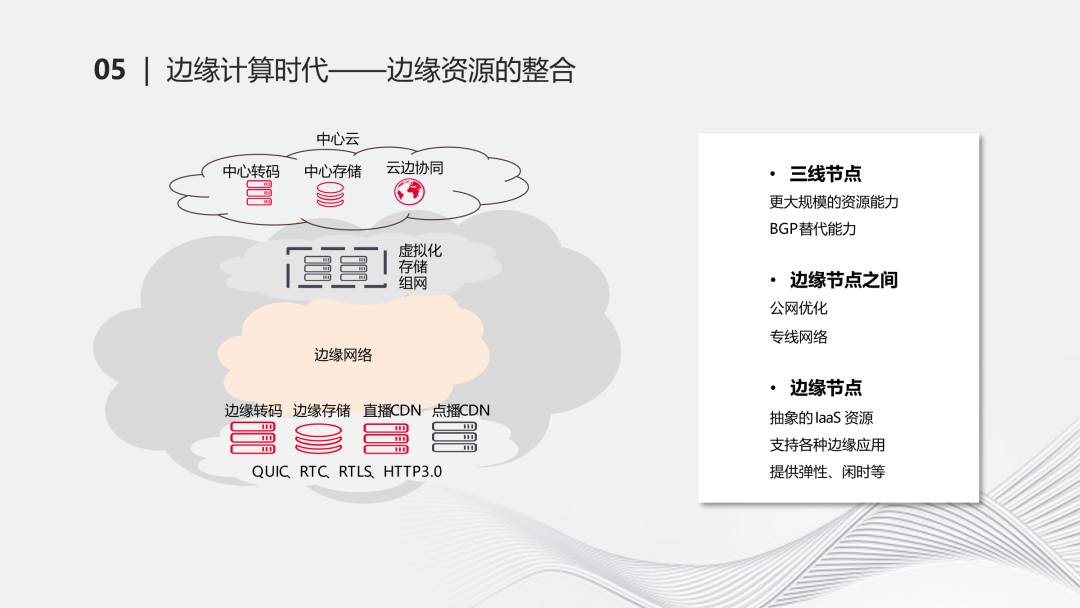
边缘计算发展到现在,从中心云到上层的三线节点到下层的边缘节点形成了几个层次。在三线节点可以提供更大规模的资源能力,因为它的覆盖和节点规模可以更大一些,可以具备BGP替代能力。同时,边缘节点之间通过公网的优化、链路的选择,让中间的边缘网络连起来。这一点是比较重要的,因为边缘层面和上层之间存在交互,把一个孤立的点单独放置,能力会很有限,但是如果把它们都连起来,在资源层面和调度层面上可以具备更多的想象力。在最底下的边缘层面上,我们主要把它抽象为laaS资源,支持各种边缘应用,提供弹性、闲时等能力。
对于业务而言、对于边缘云场景而言,其实还有一个额外的逻辑,即通过虚拟化的能力,能够把整个边缘云的资源进行抽象。这部分在当今这个技术升级的时代是比较重要的。通过虚拟化的能力,本质上是把大量可闲置的资源进行再一次抽象,抽象为粒度比较细的CPU内存的能力。这个概念其实并不新鲜,但要把它践行下去需要一些决心。
举几个例子。例如我们可以通过云计算的能力为直播提供一些弹性的场景,通过刚才提到的存储能力,可以为直播提供诸如错峰、成本节省的场景。混部可以更好利用边缘云的能力以及相关的闲置资源,在机器用率或成本上也会有更好的提升。
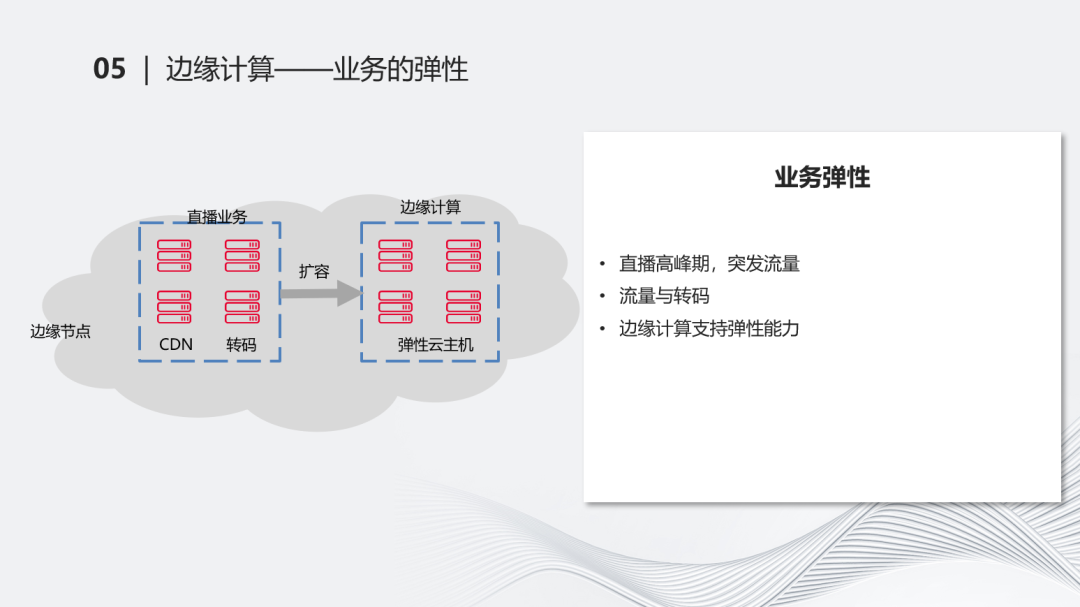
业务的弹性能力,例如在直播和边缘计算混合在一个节点上后,可以利用边缘计算的弹性能力对它进行一些扩容。直播常会面临一些甜蜜的烦恼,例如在晚高峰时期有一些用量突发进来,这对云服务厂商而言是好事,相当于客户引入了更多流量。但如果基于传统的资源规划的逻辑去考虑,它是固定数量的机器和算力,在这种情况下,我们遇到这种流量突增,很难在当天晚上或五分钟后能够找到合适的资源,这时资源的弹性就显得比较重要。
同样的,流量分发和转码的能力如果在这种突发情况下,我们把它的弹性接得好,客户的满意度会更好,也会对我们带来更好的营收状况。所以边缘计算通过弹性云主机的能力可以很好地提供相关的弹性支持,虽然不是百分之百,但至少能提供相当一部分。
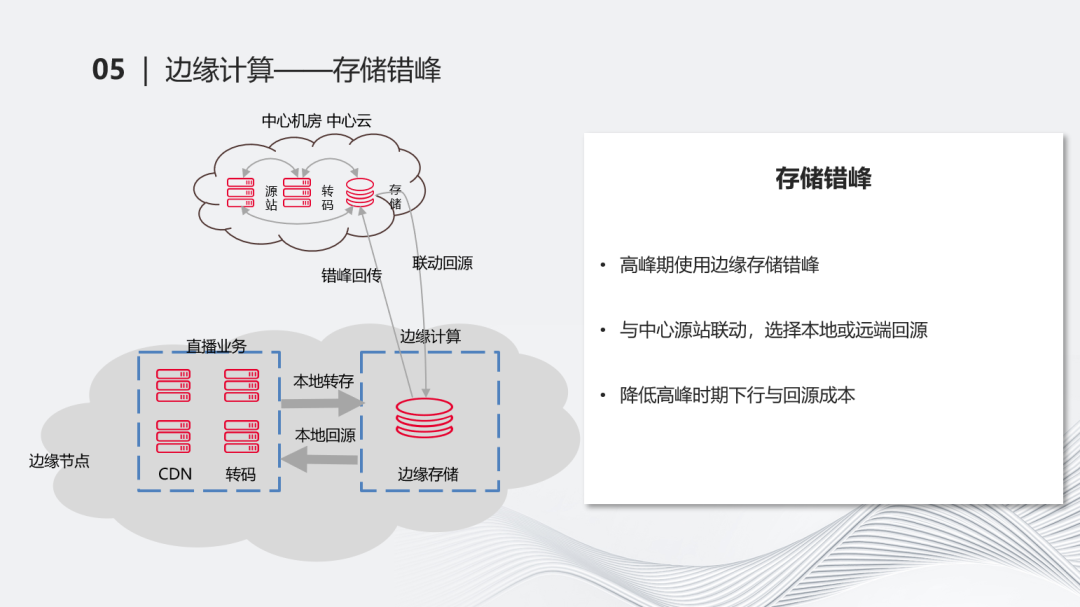
另外一方面是存储方面的错峰。金山云的边缘计算已经做了分布式的对象存储,即在整个分步的环境下,在全网的场景下,我们提供了统一命名空间的对象存储能力。对直播来说可以做一些错峰回传和联动回源的能力。例如在高峰期,把相关的流推到边缘节点的存储上,就可以降低很多在高峰期下行带宽的能力,这样对于诸如95计费的能力而言,能够起到很好的降稳作用。当我们在访问源站的存储时,这个数据可能本身还存在在边缘存储这个点上,所以我们需要和边缘云的存储能力进行联动,使得我们在访问中心存储时能够把它指到边缘存储的位置上来,相当于有一个路由,通过一些能力能够把这个数据最终调到边缘存储上。这是一个典型的错峰逻辑,基于这种逻辑,进一步节省了在直播高峰期上下行的带宽能力。
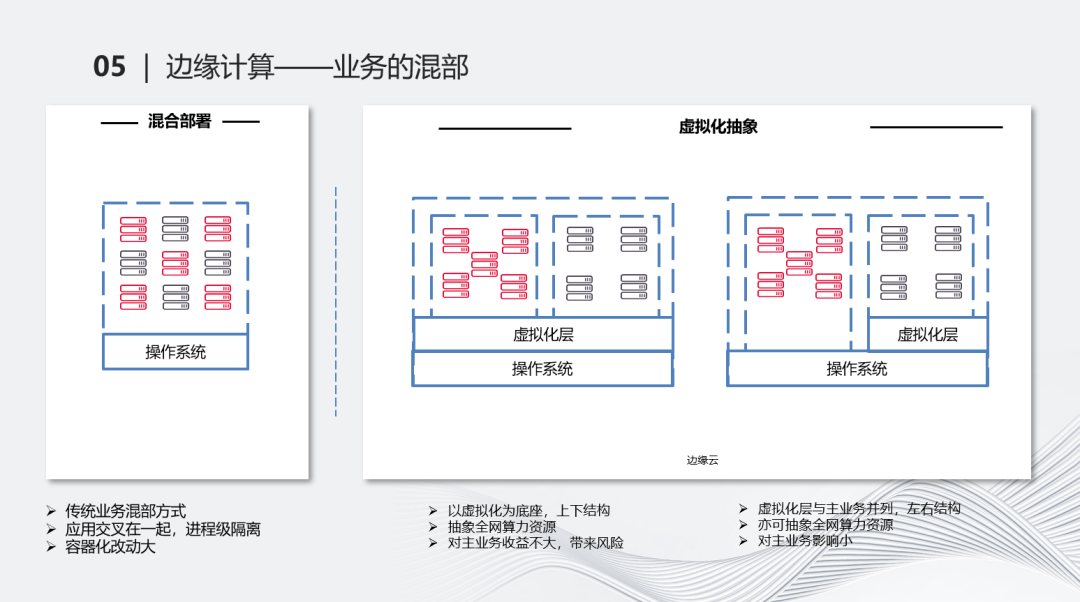
第三个是混部的能力。伴随着资源升级,自然就会想到混部。混部是一个持续了很久的case,它的最大目的是尽量复用资源。
传统的混部就像左边这张图,应用跑在操作系统上,红色和黑色的两个业务交叉混部在一起,主要是进程级的隔离。这种混部本身没有问题,但它一方面确实会涉及到一些业务相关的改造,另一方面,如果把它放到一个更大的角度去看,它的通用性会有一些影响。例如把这两个业务进行混部,没有问题,但如果想把它通用化,相当于每个业务都要做一次这种混部的调整,成本比较高。进程级的隔离在对外场景下隔离程度不够,相互有很多影响。我们也考虑过对业务进行容器化的改造,但需要把每个组件都进行容器化调整,再逐步上线,尤其是这些业务可能承接着很重要的业务流量,风险较高,改动成本也很大。
虚拟化在一个维度上,本质是解决了资源的抽象问题,同时抽象的层次足够低。在这个场景下,它的通用化会非常好。如果能够把边缘云的几万台机器的能力再做一次抽象,显然可以升级出更多的资源。
右边的图就是虚拟化抽象的基本逻辑,在这基础上又分为两个思路。左边是一个特别正常的思路,在操作系统上有一个虚拟化层,在这上面跑了很多云主机,分别把两个业务放在不同的虚拟机里面。但这还是会面临类似的问题,有些业务直接迁到虚拟层上后,大家会很怀疑这个虚拟层是否足够健壮,是否能够支撑复杂或高负载的业务。这种做法有助于提高整体整合能力,但业务风险比较高。尤其是在虚拟化的场景下,做不好就可能出现相互打架的情况,高负载的情况下更有可能。这种上下结构会面临的问题是,边缘计算的业务收益可能很大,但对上面跑的其他业务收益不一定会很大。
于是我们想了另一个思路,把上下结构变为左右结构,即把主业务或比较健壮成熟的业务、承接很大业务量的业务,我们并不把它完全虚拟化出来,而是在它隔壁建一个虚拟化层。它们同时跑在一个机器上,通过例如c group的能力,也可以对主业务进行基本的资源管控和限制。同时,在隔壁抽象一个虚拟化层后,本质上是把它抽象成了CPU和内存,进行了一次再抽象和封装,这样可以让两种业务更加相安无事。这种抽象的能力最终可以把全网的资源都抽象出来后进行的对外售卖,可以有很多细粒度的能力进行售卖,还可以售卖一些闲时的能力,在不影响自有业务的情况下爱,尽最大可能把资源压榨出来。
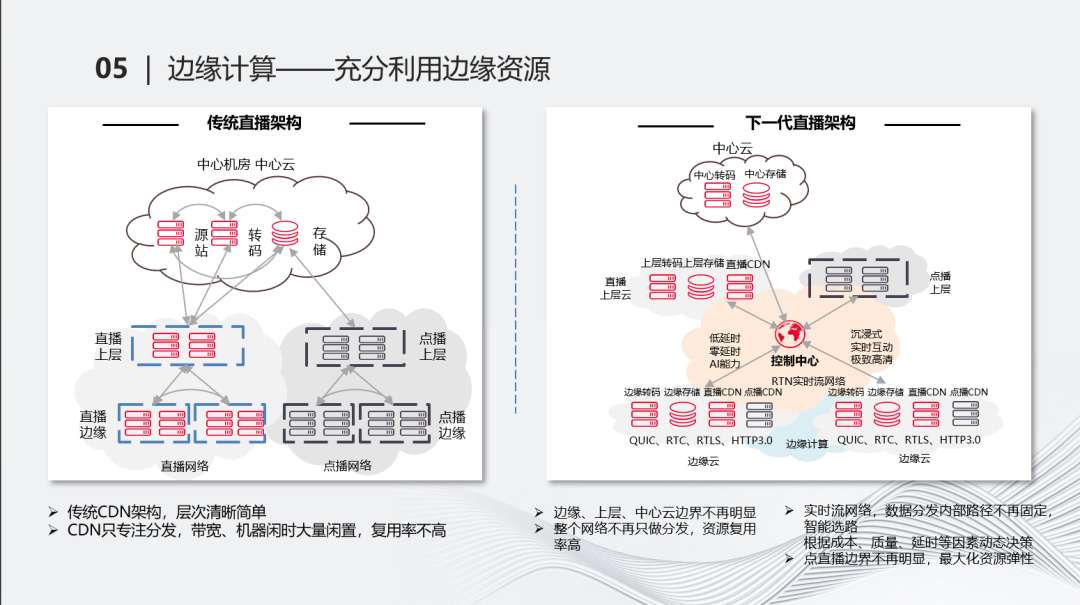
直播和边缘计算可以有一些更好的结合的点。传统的这种CDN架构,层次比较清晰,更多专注在分发。单打独斗,资源的闲置、复用能力等都会有影响。当我们把它融合起来后,它本身是一个更复杂的逻辑,也不一定是树状结构,更倾向于是网状结构。整个网络不一定只用于分发,资源的复用率会比较高。当用到存储、混部的能力,就可以进一步技术升级。根据质量、成本、延时的动态决策,使整个直播的边界感、上中层的边界感会越来越模糊,使它更像一个网络而不是树状结构。
通过这种弹性的能力,可以解决各种直播突增的效能问题。通过对CPU内存级的抽象,可以解决各类混部门槛降低的问题,增强通用化。通过边缘对象存储的能力,可以给错峰、缓存提供更好的支持。同时我们可以最大化高效使用,利用闲时能力。直播的实时转码不一定合适,点播的闲时转码更合适。本质上是利用边缘计算提供的计算存储网络能力,给直播做更多的助力。
-06-
总结与思考

最后总结一下:直播经历了刀耕火种、千播大战、质量优先、成本为王的时代,包括和厂商进行深度合作、引入更高效低成本的资源的时代,逐渐走向成熟。和边缘云、相关计算能力进行整合,使我们在共享资源和弹性能力上获得进一步提升,得以在这场技术升级中取得新收获。

