
//
编者按:从2019年初在线实时K歌玩法开始兴起,提出了许多不同于直播、会议、语聊房、离线K歌场景的新要求,像是音质、耳返、延迟、实时对齐等等。撕歌作为一个创业团队,如何在有限的资源下把握住K歌体验的关键,同时想办法降低成本,是一个比较大的挑战。本次分享将分四个部分,第一部分介绍撕歌在线K歌的技术方案选型,主要考虑了哪些因素,实践中有哪些优势;第二部分介绍撕歌在迭代过程中都尝试过哪些技术方向来优化体验;第三部分会针对优化效果做检验;第四部分会聊聊语聊房卡房卡麦的问题归因及解决方案。
文/程乐
编辑/LiveVideoStack
大家好,今天我主要介绍撕歌在在线K歌方向上的技术优化点。我看到之前LiveVideoStackCon上是有做过关于K歌多维度打分方面的内容,而我今天分享的重点则是在工程优化方向。

首先大概介绍下这次分享的内容。
本次分享有四个部分,第一部分是撕歌从开始做到现在在技术方案上的变化,也会讲到如何比较客观地评估第三方服务商;第二部分是本次分享的重点,会将我们在开发迭代过程中遇到的关键点和坑分享出来,内容包括在线K歌重要的优化点;第三部分是对第二部分优化的评估,即做完优化之后如何从数据上体现出来;第四部分简单分享下遇到用户恶意卡房卡麦的情况,如何来规避和解决。
-01-
撕歌的K歌技术方案选型
首先是第一部分。
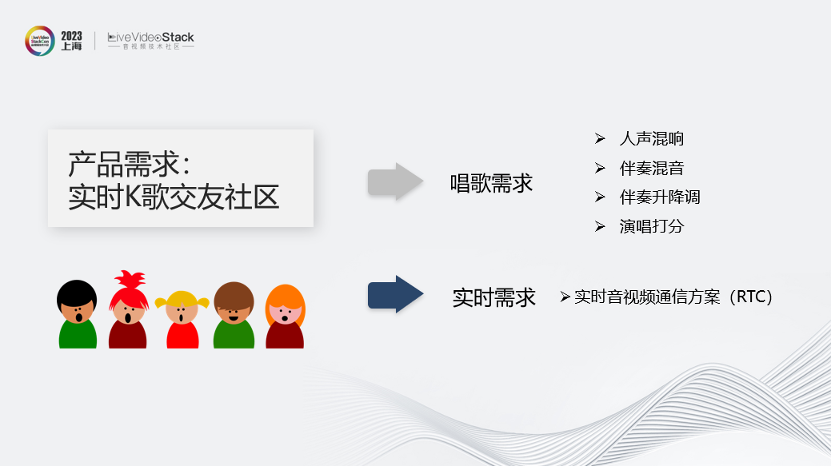
撕歌的需求定位是“实时K歌交友社区”,这就包含了两个方面,一个是唱歌,一个是实时。
唱歌需求,就是App播放伴奏,用户跟着伴奏来演唱,演唱人声要有混响或其他音频效果,然后人声要跟伴奏混音再传给房间内的其他用户。伴奏要能升Key降Key,有些场景下也要能知道用户唱得好不好,需要有个客观的演唱打分能力。这部分跟离线K歌的需求是重叠的。
再看另一个实时需求,这部分就要求用户演唱混音后的声音要能实时传给房间内的其他用户,这就需要引入实时音频通信的能力,也就是RTC。
唱歌需求这块有之前做直播SDK的经验,我们自己是能做的,但是RTC服务这块门槛会高一些。

应该说从一开始我们就没有考虑过自建RTC方案,虽然说把开源的WebRTC拉过来改一改跑通这个事情不难,但是要提供稳定的商业服务,需要的开发成本和时间成本也是很不划算的。
我们一开始是使用全套RTC商业方案跑通业务,验证业务可行性。2019年时各家RTC的重点还都是在教育和会议场景,对K歌场景的支持非常有限。
在跑通之后就遇到了一些痛点:
一个是Android端耳返延迟过大,以及人声伴奏不同步的问题,还有就是外放场景下回声消除的效果比较差。
再后来想要接多家RTC的时候,发现体验差异比较大且接入成本也比较高,这里面主要有这几个点:
一是不同RTC适配同一个Android机型,java/openSL ES/AAudio采集配置可能是不一致的,耳返效果、声音效果以及声音延迟都会存在差异。
二是为了避免混响等音效差异,音效也还是需要自行实现的,且需要接入到RTC厂商的C++层来避免延迟过大。
三是各家RTC厂商宣传的几行代码完成集成,或者说可以无缝迁移,在实践中各家SDK中名称相同的接口,其实际行为差异可能会比较大。因此尽量减少用到的RTC SDK接口是可以有效降低对接成本的。
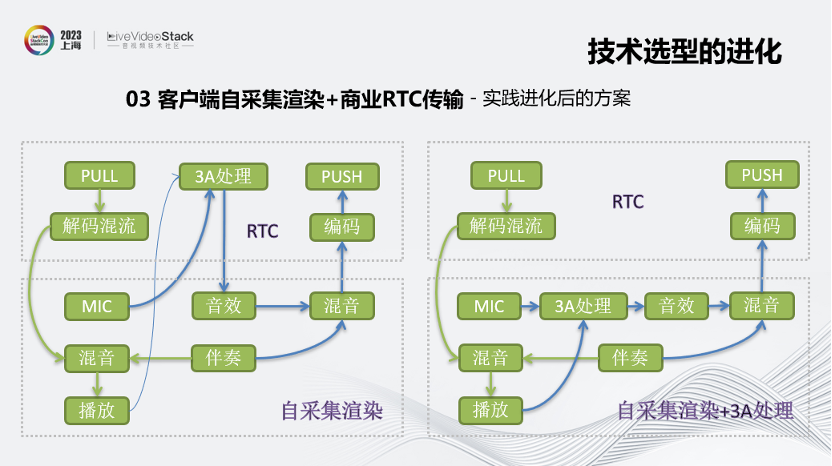
我们在第二阶段就采用了一种新的集成方式,也就是客户端自采集渲染加商业RTC传输的方案。
这里也存在两种不同的集成方式,一个是用RTC厂商的3A处理,一个是自研的。
左图是用RTC厂商的3A处理。下框中的部分是我们自采集渲染部分做的事情,上框中的部分则是RTC厂商做的。
我们来看一下这个方案下的音频数据流。先看推流,MIC采集到的声音会先送到RTC厂商的SDK中,经过3A处理,再送回来做音效处理,并跟伴奏做混音,然后再送给RTC厂商的SDK做编码和推流。
再看拉流,我们从RTC SDK拉取解码混流后的音频,跟本地伴奏做混音,然后播放出来,这就是整条的音频流向。
再看右图,跟左图非常类似,只是3A处理也放在我们这边来做,RTC厂商那边只负责推拉流和编解码。
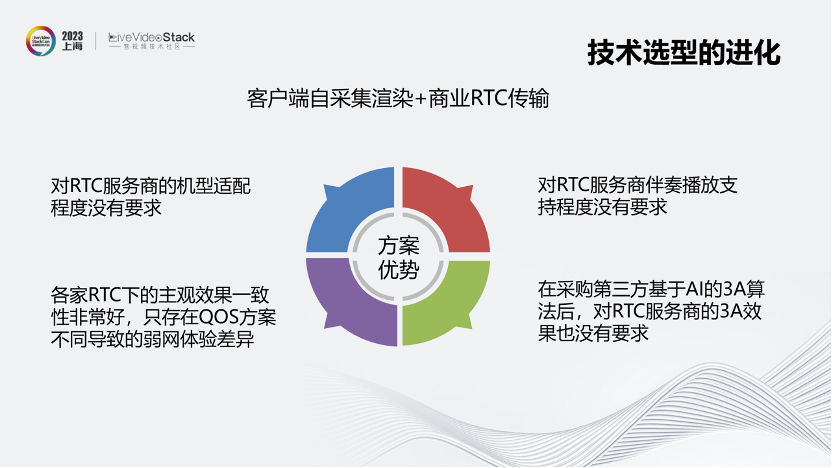
上述方案的优势在于,对RTC服务商的机型适配程度没有要求,在伴奏播放支持程度方面:支持伴奏格式,封装、编码、加密等;伴奏预加载,本地缓存,QUIC协议支持等。
除了技术和用户体验之外,对我们意义更大的是带来了议价优势:多家RTC可以在线上同时共存,用户基本上是无感的;我们也可以自由切量,对各家RTC的依赖比较小,更容易获得议价优势。

在RTC选型标准上,首先是参考业界口碑,另外就是建立可信的对比测试。
目前我们在对比测试项目上比较关注音频3A处理效果和音频传输效果两个方面,如图所示。

为了达到测试的能力,我们搭建了一个低成本的音频实验室,实现标准化测试使结论可重复,尽量多的自动化以提高测试效率,以及尽量降低成本。

我们在音视频实验室标准化方面也做了一些努力。首先是隔绝外部噪音;另外统一测试物料及方法。

另外需要关注弱网环境的标准化,使用的是NUC小主机+Linux ATC低成本方案。
现有的问题是不同时段存在偏差,因为我们目前实际还是共用办公室网络,环境无线信号复杂,相互干扰。
对应的解决方案是可以考虑给测试单独拉一条宽带,在热点上用5G频段,并在网络对比测试均同时间交替运行3x3组。
-02-
基于自采集渲染的技术优化

第二部分是这次分享的重点,会把我们在做实时在线K歌过程中遇到的困难以及解决方案分享给大家。

首先我会为什么要做优化,接下来介绍做了哪些方面的优化。

首先,不同于离线录歌,实时K歌无法做异步后期处理。

另外,不同于单纯的语聊和会议场景,实时K歌对于3A处理和传输音质的要求更高。

最后,不同于直播K歌,在线K歌的麦上占比有绝对优势,并且年轻用户为主,中低端设备占比较高。
另外就是机型兼容挑战,直播场景可以针对主播设备做适配和推荐,但实时K歌场景需要尽量兼容更多的机型和效果。

接下来就介绍我们具体做了哪些优化。
首先是耳返优化。iOS端问题较少,后台反馈中占比较大之一就是Android用户对耳返的吐槽。目前Android端的两种解决方式分别是接入厂商的硬件耳返,以及使用openSL ES或AAudio借口实现低延迟音频通路。前者存在耳返效果跟实际端测到的效果不一致的问题,另外手机厂商维护上比较乏力;而后者因不同机型差异较大,大部分延迟不达标。我们通过建立耳返白名单,符合延迟要求的再放入白名单内。
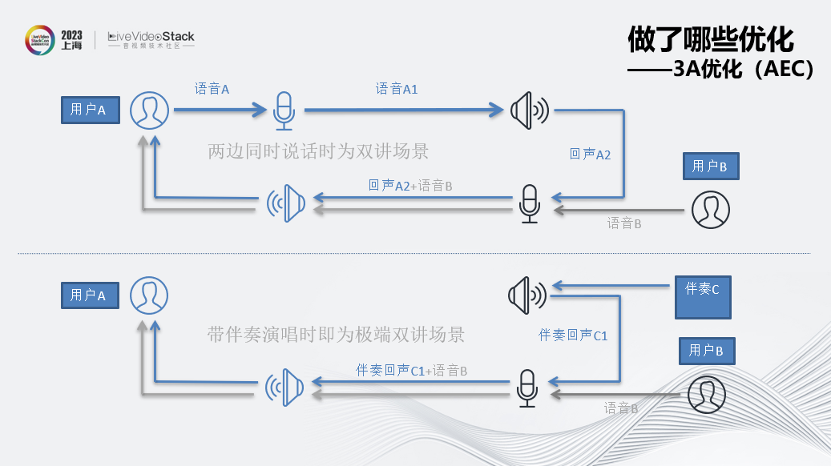
其次是3A优化(AEC)。图中上侧所示是AEC场景中回声产生的原因,下侧是K歌时的AEC场景,其默认就是极端双讲场景。

我们在不同场景中做了取舍。语聊场景下的AEC取向尽量保证不漏回声,可以接受一定程度的人声损伤;而K歌场景下的AEC取向尽量减少对人声的损伤,可以接受漏一部分回声。
在上面示例的3种声音效果中:
效果1完全没有回声残留,但是人声部分失真非常严重,也出现了明显的丢字;效果2开头会漏完整回声,人声保留比较好,后面回声被消掉的部分可以听出人声也有失真;效果3在有人声的时候会同时伴随漏回声的现象,不过整体上人声保留还不错,效果比较稳定。
综合下来,我们在K歌场景下更倾向于效果3。

接下来是耳机模式下的3A优化。戴耳机场景下大部分时候可以避免回声问题,但Android平台戴耳机不能默认关掉3A处理,导致一些串音和杂音等问题。
目前我们的方案是仅在使用软件耳返时关闭3A处理,其他情况下均开启。

然后是iOS机型的优化。
iOS不同机型系统硬件AEC的效果存在差异,iPhone13以后机型的AEC处理效果变差,我们会根据机型确定使用系统硬件AEC或软件AEC。
另外,iOS机型使用VPIO时音质会变差,不只是采集的音质,播放出来的声音也会跟RemoteIO下有比较明显的差异,应该是苹果为了AEC好做故意为之。有这个劣化点在,每个机型是要用硬件AEC还是软件AEC就需要做一个效果的综合评估。

在Android机型优化上,由于Android平台大部分机型的硬件AEC效果都不太好,就统一走软件AEC。
另外,双MIC的Android机型可以通过选取不同的MIC来降低回采回声的能量,让AEC算法更好处理。
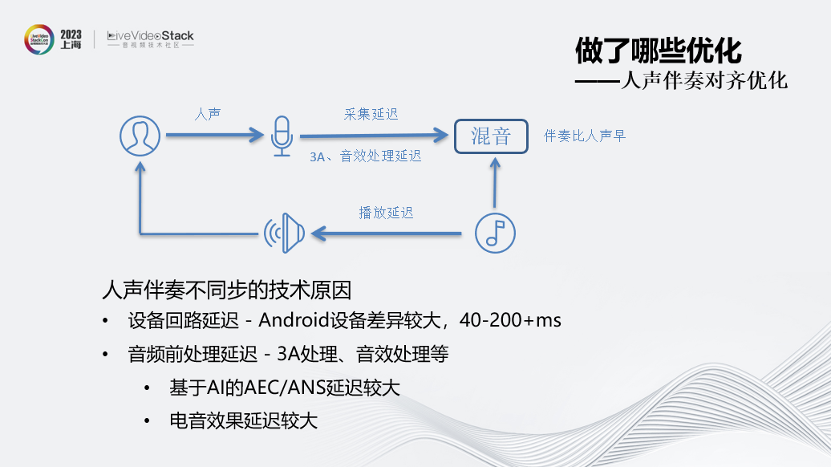
接下来介绍人声伴奏对齐方面的优化。
首先,人声伴奏不同步的技术原因是设备回路延迟、采集延迟以及音频前处理的延迟等,导致混音时伴奏比人声早。
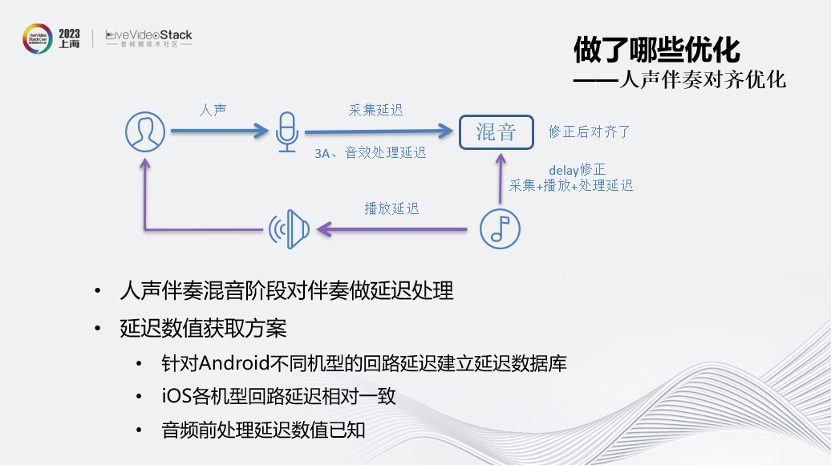
在找到问题后,解决方案就是在人声伴奏混音阶段对伴奏做延迟处理。
延迟数值获取方面,我们针对Android不同机型的回路延迟建立数据库,而iOS各机型的回路延迟是相对一致的。对不在数据库中的机型,外放时可使用AEC的延时估计数据。

在人声伴奏音量平衡方面,有以下两个要点:
*无法像离线K歌那样演唱完后整体评估人声和伴奏的响度大小,进而做平衡混音;
*尝试过实时根据伴奏响度大小对人声做调整,算法难度较大,很容易出现劣化;
我们目前采用的方向是人声伴奏分别处理,各自标定目标响度。
首先是人声处理,把最大Peak 值限制在6dB,这里面包含两方面:AGC标定,以及机型适配,包括采集配置以及音量修正系数。

第二步就是伴奏处理。实践中伴奏的响度差异可能较大,不同来源的伴奏差异更明显。
起初我们按照目标【Peak-6dB】对伴奏做重转码,但会导致一些问题,例如部分伴奏中偶然的尖峰会导致整体响度偏低,另外后来引入的版权方不允许对物料做加工和存储,导致无法使用该方案。
目前我们采用的方案是parse伴奏物料,并将parse出的参数随歌曲下发,然后客户端根据配置的目标值线性调整伴奏音量。

在声卡优化方面,我们通过关闭音频前处理及耳返,避免对音质造成损伤,另外对于支持双声道采集的声卡,使用双声道采集模式。主要方向是尽量还原声卡的输入信号,不做额外处理。
实践中我们给用户了一个声卡模式的开关,只有用户开启了声卡模式开关,且接入了3.5mm或USB音频设备,才会开启声卡模式。

在蓝牙耳机优化方面,蓝牙耳机的两种常用模式HFP和A2DP各有其特点。
HFP模式支持播放和录音,但采样率只有8k或16kHz(采集和播放都是),音质很差;A2DP模式只支持播放,但采样率可以支持44.1k或48kHz,播放音质较好。
我们在K歌模式下强制使用A2DP模式,蓝牙耳机只播放,录音则使用手机自带mic。
-03-
音频技术优化的数据化

第三部分是对第二部分的优化效果做检验。
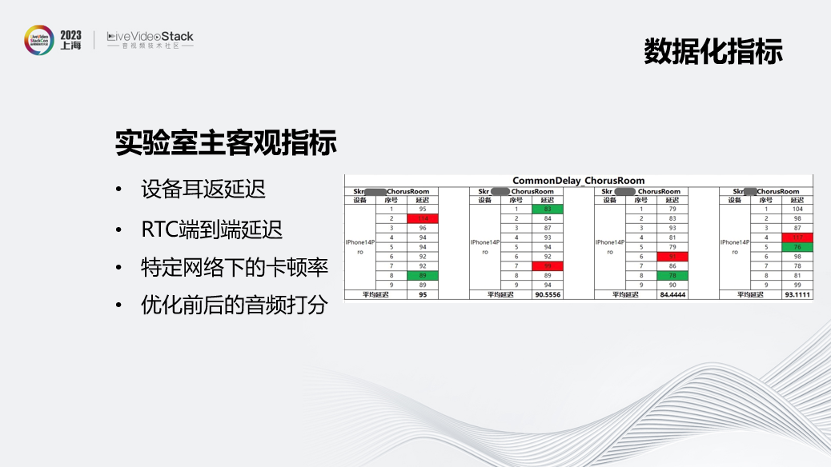
首先是建立的实验室主客观指标,例如设备耳返延迟、RTC端到端延迟、特定网络下的卡顿率以及优化前后的音频打分。
图中右侧就是各家RTC在合唱模式下的延迟数据对比。另外实验室也可以做相关的主观评价,例如新加入一种音效或者对采集渲染做优化,可以得到优化前后的数据并评价效果。

如图是线上客观指标。在RTC回调的卡顿率方面,不同厂商定义存在较大差异,只能作为相同厂商服务稳定性的参考,无法横向对比。

线上主观指标主要评价音质效果、主观卡顿情况、有无杂音等。
目前我们设立了两个指标,通过客诉率发现音频体验问题占DAU的比例,以及演唱完成后收集用户主观评分。
-04-
卡房卡麦归因及解决方案探讨

最后一部分是语聊房卡房卡麦的问题归因及解决方案探讨。

目前我们遇到两个比较典型的情况,如图所示。

那么如何解决呢?
首先,在运营侧识别到恶意卡麦的情况后,需要能及时将其封禁,封禁同时也通过RTC厂商的服务端接口将该用户踢出RTC房间。
其次,实行客户端主动保护。通过主动对比RTC和业务主播列表,发现异常上麦,调用RTC的下麦接口,并添加业务信令超时逻辑,连续多次不能同步业务信令,则主动下麦,直到业务同步恢复。
第三,服务端保底预警。服务端接入RTC厂商的回调,也维护一份RTC房间内的主播列表,发现不一致自动通知巡查人员确认,确认后做封禁。
以上就是我的分享内容,谢谢!
LiveVideoStackCon 2023音视频技术大会深圳站,诚邀您参与。
时间:2023年11月24日-25日
地点:深圳圣淘沙酒店(翡翠店)
咨询:13520771810(微信同号),ticket@livevideostack.com

