

编者按
2022年可以说是AIGC技术的元年,LLM领域的GPT和图像领域的Stable Diffusion,都属于行业的颠覆性技术。在图像领域,业界出现了如DALLE,Midjourney等基于简单描述文本生成图像的模型和工具。美图在2022年以来,发布了多项AIGC相关应用,LiveVideoStackCon 2023深圳站 邀请到了美图 影像研究院李骈臻老师分享相关经验。
文/李骈臻
整理/LiveVideoStack
可以说,2022年是AI生成内容(AIGC)技术的元年。无论是自然语言处理领域的GPT,还是图像领域的Stable Diffusion,都是颠覆性的技术。在图像领域,我们看到了如DALLE,Midjourney等能够根据简单描述文本生成图像的模型和工具。我们也看到了许多由AI生成的、堪比插画师的图像。
在大模型技术潮流的推动下,美图正在积极抓住图像领域的机会。在过去的一年里,美图发布了许多与图像AI生成对抗(AIGC)相关的功能,并取得了一些成果。然而,当我们转向视频领域,由于处理数据量明显提升,加上视频数据本身存在的时序相关性,我们在视频生成的稳定性和部署方面面临着许多挑战。今天,我将向大家介绍美图在视频领域的AIGC功能——AI动漫的落地探索案例。

接下来,以三个章节展开说明,第一个章节是美图在AIGC方面的应用,这个章节主要给大家展示一下美图在过去一年在AIGC领域的一些功能探索,第二个章节是给大家介绍一下AI动漫功能的意义和挑战。面对这些技术挑战,第三个章节,我会详细的给大家讲一下我们在功能研发过程当中的一些技术探索。
01
美图在AIGC方面的应用
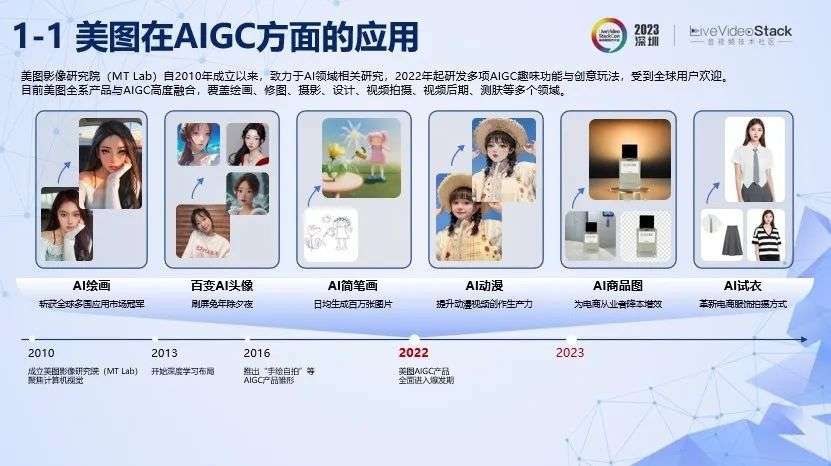
在介绍AI动漫之前,先给大家介绍一下美图在AIGC方面的一些应用。
我们的技术研发机构,全称是美图影像研究院,我们成立于2010年,致力于AI邻域相关技术的研究。2022年起我们研发了多项AIGC趣味功能和创意玩法,受到全球用户欢迎。目前美图全系产品与AIGC高度融合,覆盖绘画、修图、摄影、设计、视频拍摄,视频后期,测肤等多个领域。
从时间线来看2022年也是AIGC产品大规模应用的一年。

接下来给大家介绍一下我们做的一些具体功能。
左边展示的是我们基于AIGC技术开发的AI画面拓展的修图功能。通过这个功能,我们能够基于原始图像的阴影、反射和纹理信息,填补图像之外的内容,从而获得非常真实的画面扩充效果。
右边展示的是AI写真功能, 通过Few-shot Learning(少样本学习)个性化训练方案生成用户形象,AI基于用户形象模型,5分钟内即可快速生成场景、妆容和造型,为用户提供一套高级写真。

这张左边展示的是AI商品图,无需布置专门的拍摄场景,也不需要渲染处理,只需随手拍摄商品图,即可实现自动抠图,并根据商品类型自动生成与之匹配的场景图。支持自动识别产品类型并给到相应场景推荐,以保证更具个性化和适配度的场景效果。
右边展示的是AI换装,基于超大规模衣服数据库训练的2D图像分析与匹配系统,可以快速准确地定位衣服类型和关键特征,通过精准的人体重建系统,实现重建人体模型与衣服,抽取细粒度的3D特征。此外,可实现海量虚拟模特生成,精准控制模特各项特征。
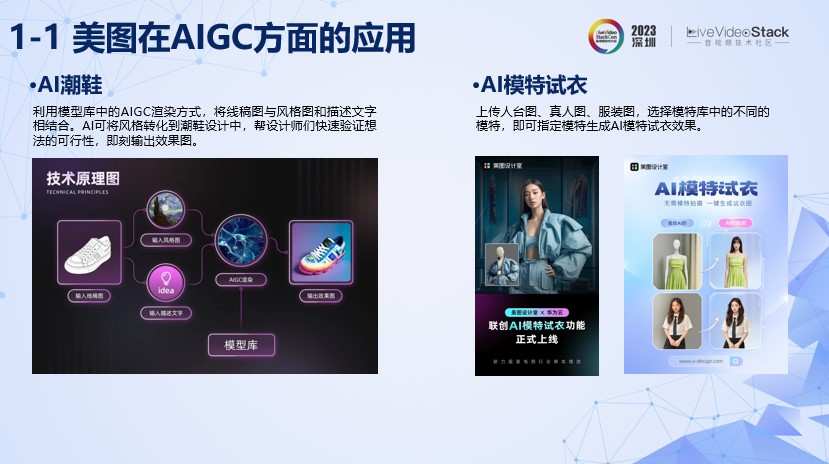
这张左边展示的是AI潮鞋,利用模型库中的AIGC渲染方式,将线稿图与风格图和描述文字相结合。AI可将风格转化到潮鞋设计中,帮设计师们快速验证想法的可行性,即刻输出效果图。
右边展示的AI模特试衣,上传人台图、真人图、服装图,选择模特库中的不同的模特,即可指定模特生成AI模特试衣效果。

最后这张左边展示的是AI绘画效果,AI绘画是美图2022年底发布的二次元图像生成技术,有别于一般图生图应用,免去了用户手动输入提示词的烦恼。
右边展示的是AI动漫效果,联合多种检测算法的引导生成算法并创新性地结合了多帧渲染技术,从而保证所生成的视频内容更符合用户输入的原图内容且能够获得稳定的视频风格化渲染效果。
02
AI动漫功能的意义和挑战

接下来介绍一下AI动漫的功能意义和挑战。
这部分我会主要讲一下我们为什么要做AI动漫这个功能以及当时研发过程面临的一些挑战。

首先介绍一下研发背景,我们22年底推出AI绘画功能后, 收到的反响很不错。在多个国家应用商店得到总榜第一的成绩,从中我们可以发现到用户对于图片创意创作的需求旺盛,所以很自然会希望把图片的功能移植到视频上。
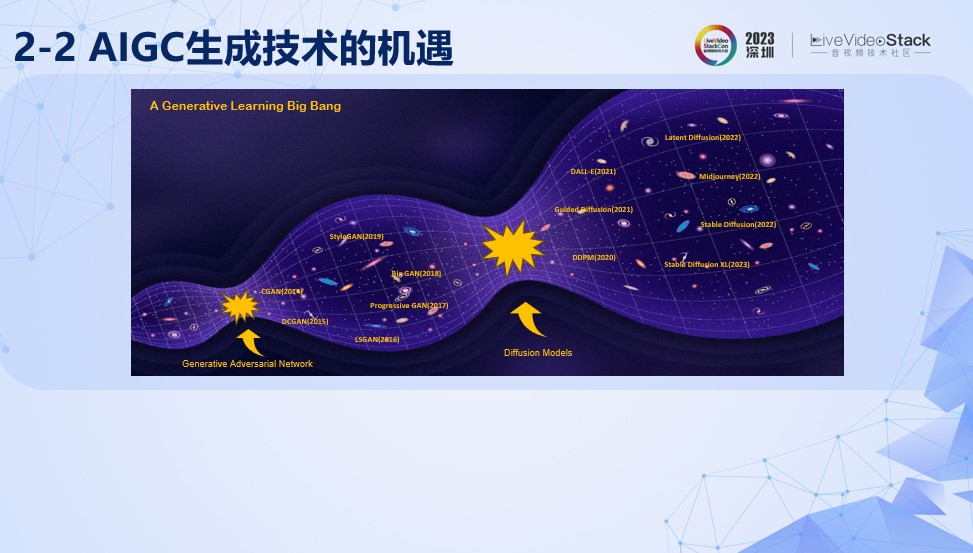
第二个是技术背景,AIGC生成技术的机遇。
生成式学习是深度学习一个重要的分支,回顾过去十年,生成式学习的发展迎来了两个大爆炸式发展的奇点。
第一个奇点是生成对抗网络的提出,对抗生成模型是一种受博弈论思想启发的生成模型,它生成器和判别器两部分组成。生成器的目标是产生逼真的数据,而判别器则尝试区分生成的数据和真实数据。这两个网络在训练过程中相互竞争:生成器不断学习如何更好地模仿真实数据,而判别器则努力更准确地识别真伪。随着训练的进行,生成器变得越来越擅长制造逼真的数据,判别器也变得越来越擅长识别。
这其中产生了很多优秀的算法,例如CGAN(将标签信息引入判别器和生成器,作为生成条件),DCGAN(引入转置卷积,进一步提高生成质量),StyleGAN(在隐空间latent space 上对生成结果进行编辑,生成出以假乱真的人像照片)等。
第二个奇点是扩散模型的提出,扩散模型是一种深度学习算法,核心思想是先将数据(如图像)逐渐加入噪声,直至完全随机化,然后再逐步学习去除这些噪声,以恢复原始数据。
其中比较有代表性的有DDPM(它通过逐步引入并去除噪声来生成高质量的数据),Latent Diffusion(通过在latent space上执行diffusion过程,极大提升了提升生成的效率)还有不得不说的SD,Stable Diffusion(通过组合VAE,预训练text encoder和Unet,实现latent-based diffusion方案,极大地提高了文本引导生成的效率和稳定性)。
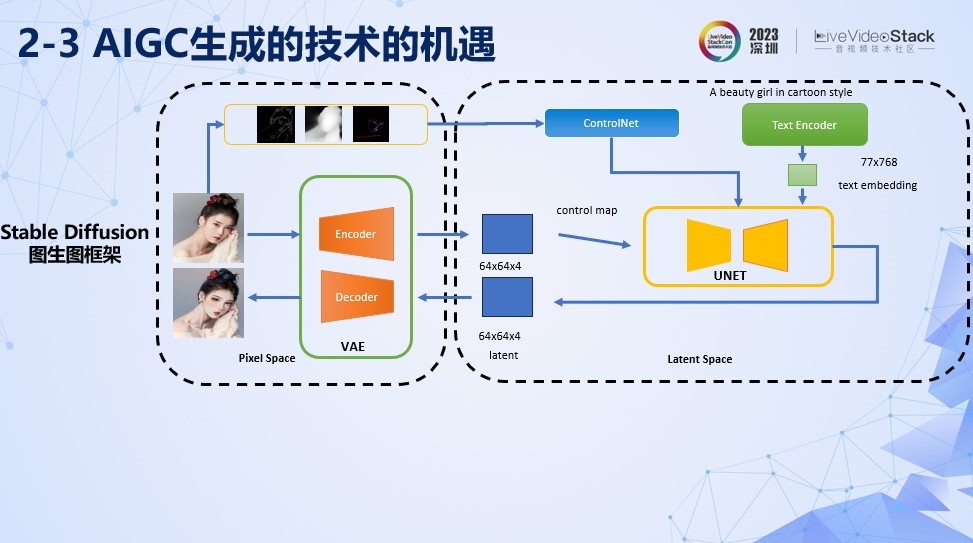
由于这次分享的方案都是基于SD基础框架上的做的一些探索。所以这个框架图会比较高频出现,简单跟大家介绍一下Stable Diffusion的结构。
上图是Stable Diffusion的一个图生图的框架图。SD主要可以分为像素空间Pixel Space和隐空间Latent Space。像素空间上通过VAE的Encoder对图像信息进行压缩得到隐空间上面的编码Latent Code。另外蓝色的部分是Controlnet,通过对图像信息,例如深度,边缘的提取,通过Cross Attention模块注入到Unet当中。Text Encoder 通过对我们给定的文本信息进步编码也是通过Cross Attention模型注入到Unet当中。然后在隐空间执行加噪和逐步去除噪声的过程,最终得到符合文本信息描述,且一定程度上面符合图像信息约束的生成图片。

我们在启动这个项目的时候大概是在2月初立项,当时视频生视频的市场的商业竞品可以说是比较空白。市场上缺少相关竞品,直到3月底,Runway才发布vid2vid模型Gen-1,Gen-1是通过给定模版风格和用户编解文本的视频生视频方案。
这是一段我们跑Gen-1生成的视频,给定的prompt是“a girl is dancing with red hair, anime style,fine detail,4k”,生成出来的视频基本上符合文本描述,但是细节和美观度不够理想。而这种让用户进行文本-视频创作的方式,对于用户学习成本很高,叠加成片率低下,会进一步导致用户调参门槛变高。
我们总结了当时这种方案的特点: 第一个是调参门槛高,成片率低;第二个是生成视频比图片的数据量有了明显的量级增长,导致生成时间变长,用户体验不好。
03
AI动漫功能的技术探索

面对上述提到的问题,我们做了一些技术上的探索。
针对成片率偏低的问题,我们做了一些生成稳定性的探索,比较好的提高了成片率;针对生成视频时候过长,影响用户体验的问题,我们提出了一种分片。另外, 由于AI动漫是一个模板化的创意玩法的功能。针对工具侧,设计师需要调参出可用模版,快速上线,让用户保持新鲜感。针对这个问题,在流程化探索部分,我们会说明一下我们的调参流程化方案。最后,给大家分享一下我们在这个项目中的一些收益和展望。

在生成稳定的探索中,我们主要会围绕视频内容理解层面的探索和时域一致性的探索展开,最后会给大家介绍一下长视频的生成策略。
其中第一个部分视频内容理解层面的探索经验,会为大家介绍我们三个阶段的探索。

在AI动漫生成的过程,我们希望减少用户使用门槛,避免用户输入文本调参效果,所以需要提取出原视频的文本信息。但是这些视频模型通常需要非常大的算力,而且描述的质量也不能很好保证。我们首先将视频理解的问题转化为对视频关键帧的理解上。如图所示,通过关键帧的检测,得到可以反映到每个片段场景的关键帧。

对于图文内容匹配模型的选型,我们主要调研了业界比较常用两个算法,CLIP和BLIP2,其中CLIP是模型通过对比学习的方式,来训练网络理解图像和文本之间的关系,而BLIP2通过联合预训练好的文本模型和图像模型,采用自监督训练的方式,改善他们的理解和对应关系。

经过对比,我们发现BLIP2给出的文本描述会更符合图片内容。这里展示了两个对比的结果。
左图中CLIP误识别了女孩手握橙子,导致生成结果出现错误。BLIP-2的结果更符合图片的描述。
右图中CLIP误识别了女孩手在面颊上,导致生成结果出现问题。BLIP-2的结果显然更好一些。

即使使用了描述比较准确的BLIP2模型,我们发现,在某些场景,还是会出现一些描述错误的情况。例如左图中,对于女性年龄的描述。右图中,对于婴儿和女孩的误识别。

此外,对于男性一些生理特征,例如胡子的错误描述。对于人脸五官的局部特征,眼睛的开闭状态描述。
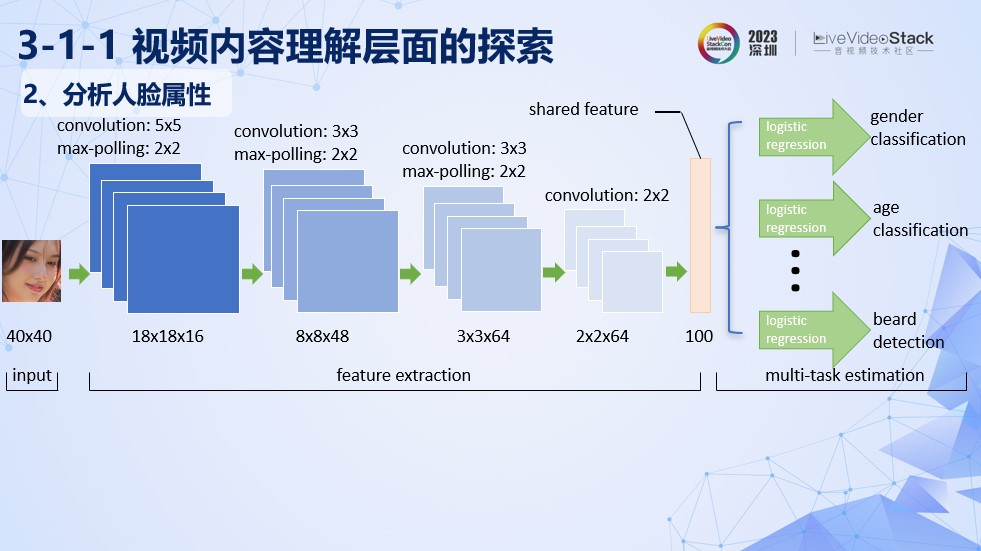
针对这些误识别的情况,我们在初版上线方案使用的是通过识别网络对人脸属性进行提取。图中是一个基本的识别网络框架。在特征提取部分,我们采用了共享特征的方式,在逻辑输出层采用了多任务的方式,进一步降低了计算的成本。我们输出的特征有性别、年龄、是否包含胡子等。


经过人脸特征对文本的修正,对图片的描述准确度有了比较好改善,满足了上线需求。图中展示了部分优化前后的对比效果,生成出来的结果可以看到带有更多原图的特征。
尽管采用了人脸修正,可以很大程度减少文本描述的问题。但是单纯通过Prompt的控制,是无法很精细的控制人脸ID以及用户的神态。所以我们提出了注入人脸特征的方式进一步的解决像不像的问题。
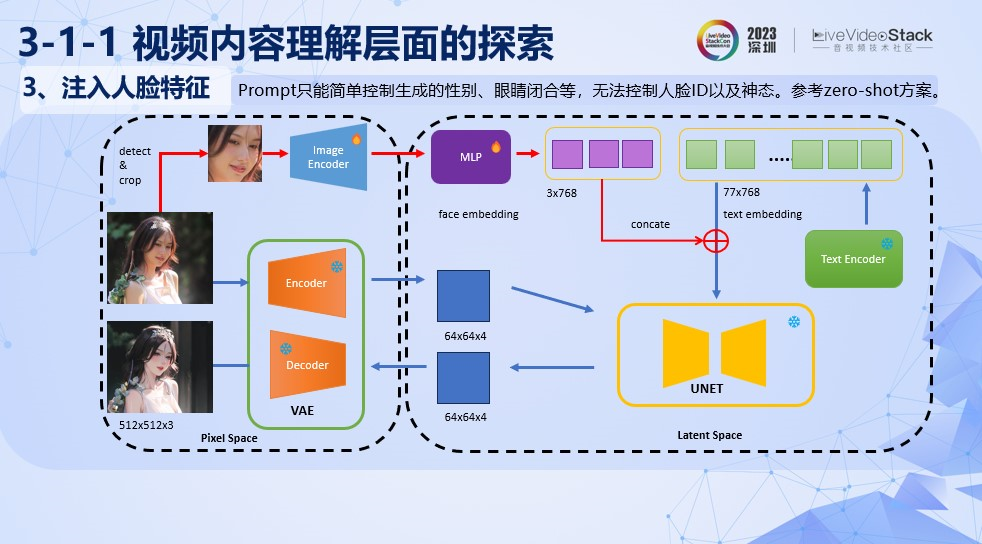
我们的方案是通过增加人脸的特征提取和Mapping模块。人脸特征提取是通过训练Image Encoder让局部人脸在生成过程的ID Loss尽可能和原图相近。增加Mapping负责把这个图像的特征映射与Text Embedding的特征维度一致的向量上面。在训练过程中Stable Diffusion原来的各部分模块参数是freeze住的。

通过引入这个ID特征注入模块,生成的结果有了进一步的提升,可以看到在小孩的场景上,原来眼影过重的问题得到缓解。这个拿福字女孩的脸型更像原图了,下面穿白色衣服的女生,眼睛神态更加忠于原图。
至此,视频内容理解层面探索的介绍就告一段落。

接下来会介绍一下我们对于时域一致性方向上的探索。这部分会着重对比几个我们调研过的视频生成的方案。
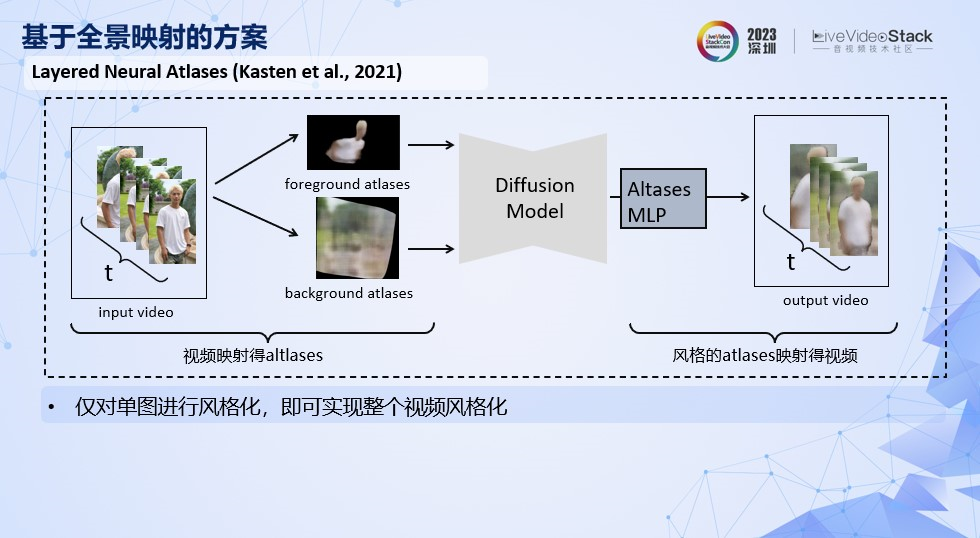
第一个是基于全景映射的方案。全景是意思是全景图,这类方案是通过训练网络得到视频前背景的全景映射图,仅对前景或者背景的全景图进行风格化,得到局部风格化的效果。典型的算法有Layered Neural Atlases。
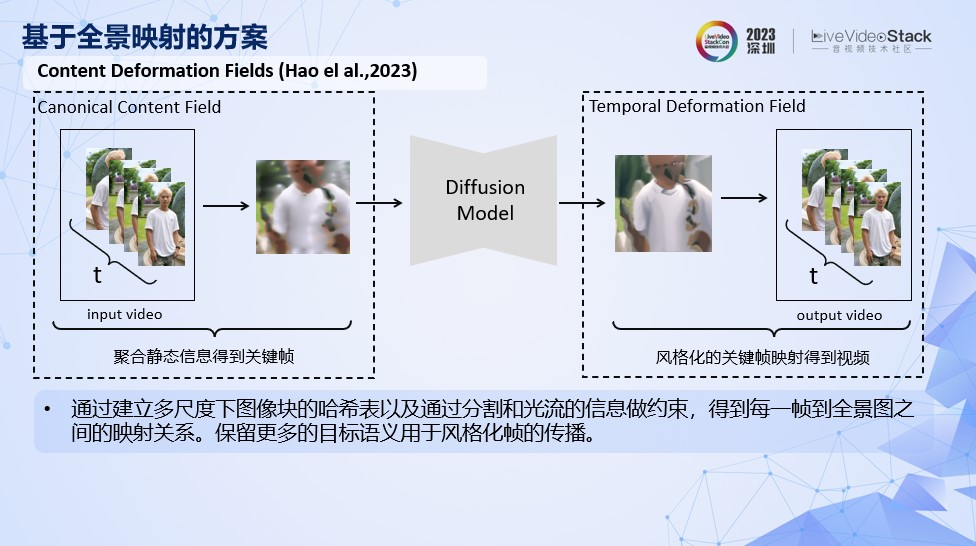
今年8月中有一个新的算法也是类似方案,CoDeF ,Content Deformation Fields,它是通过建立多尺度下图像块的哈希表以及结合分割和光流信息做约束,得到视频每一帧到全景图之间更好的映射关系。这种方案相比altas图保留了更多目标语义信息用于风格化传播。

最后总结一下基于全景的映射方案,这种方案优点是训练成本低,在简单的场景可以表现出优秀的稳定性。缺点是难以处理复杂场景的视频,风格化算法受限于关键帧的压缩效率。
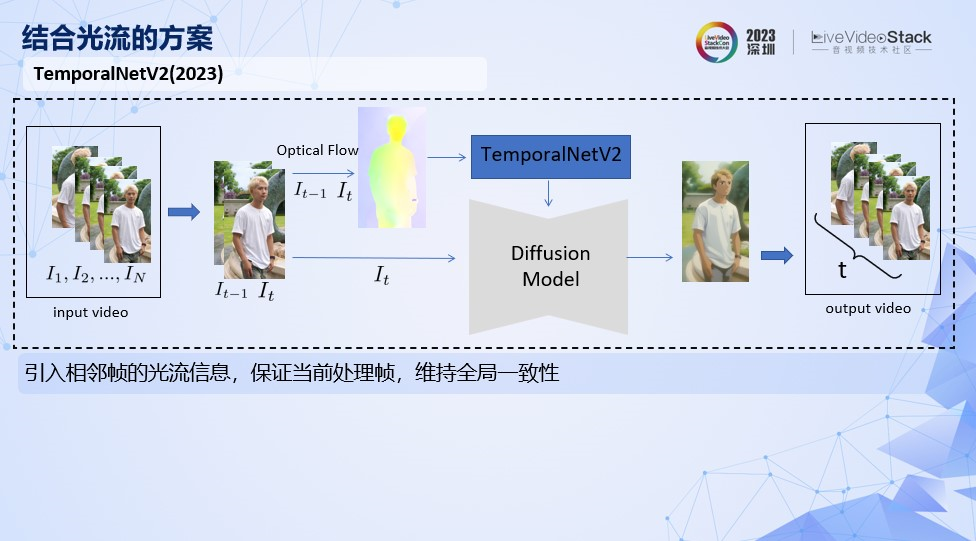
第二种是结合光流的方案。
这里比较典型的是代表是temporalNetV2,通过引入相邻帧的光流信息,保证当前处理帧,维持全局的一致性。

我们看一下这种方案的效果,比全景图方案有了一些改善,但是还是有比较明显的闪烁问题。
这种基于光流的方案,优点是无需训练,在简单场景有比较好的一致性。缺点是无法捕捉时间跨度大的帧间关系。

第三种是多帧渲染方案。
这种方案是源于webui社区的一个流行方案,首先风格化生成第一帧,然后当前风格帧的输出,通过拼接前一帧的结果,使用局部重绘的方式得到。

我们可以看一下单帧渲染和多帧渲染的对比。多帧方案有了比较明显的稳定性提升,但是背景内容还是会比较跳,而且前景中人物的特征例如头发颜色和肤色保持得不是很好。
这里小结一下多帧方案的特定,首先多帧只是粗暴的在空余中对齐纹理信息,信息利用率低。然后带风格图的组合在风格映射过程中会导致风格差异,例如左右两张图拼接的是风格化后的前一帧,特征映射的过程中并不是原图的映射,会引入一些风格上的差异。
最后这样多图拼接的Diffuse过程耗时比较长,成本较单图生成提高了很多。
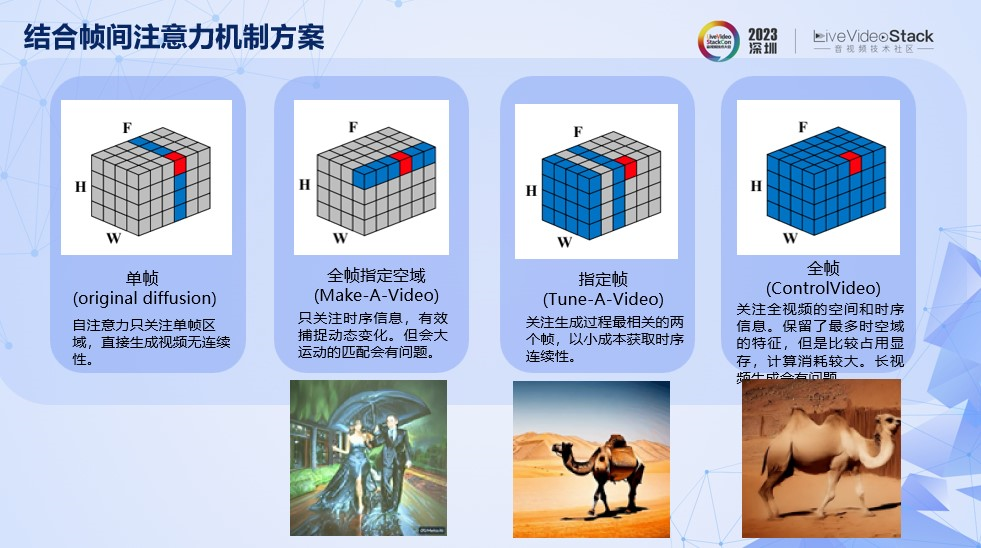
第四种是结合帧间注意力机制的方案。
这个方案可以分为以下四种形式,第一种是只考虑当前帧的自注意力,上面提到的三种方案大部分属于这种形式,没有考虑到时序特征的注意力。
第二种是指定某些关键帧的方式,关注生成过程最相关的两帧或者多帧,以小成本获取时序连续性,典型的代表有Tune-A-Video。
第三种是利用全部帧信息,但是只考虑局部空域,典型的方案有Make-A-Video,这种方法只关注时序信息,但是只考虑局部区域上的搜索,对于大运动匹配会有问题。
第四种是考虑全部帧的时空域信息。保留了最多时空域的特征,但是搜索会比较耗时。典型的代表是ControlVideo。
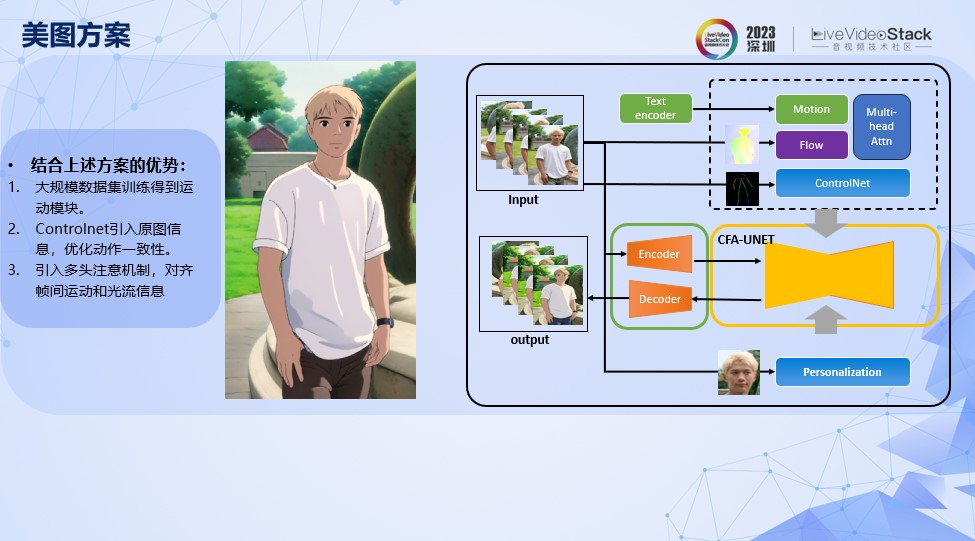
我们结合了部分上述方案的优势,提出CFA(Cross Frame Attention)模块,通过大规模数据训练帧间注意力机制。
通过结合光流和Controlnet,优化动作的一致性。
引入多头注意力机制,对齐帧间运动和光流信息。

这里展示一下前面讲到的方案和我们方案的效果对比。无论是前景的肤色,发际线,发色都能保持一致。而且背景的还原和一致性也非常好。
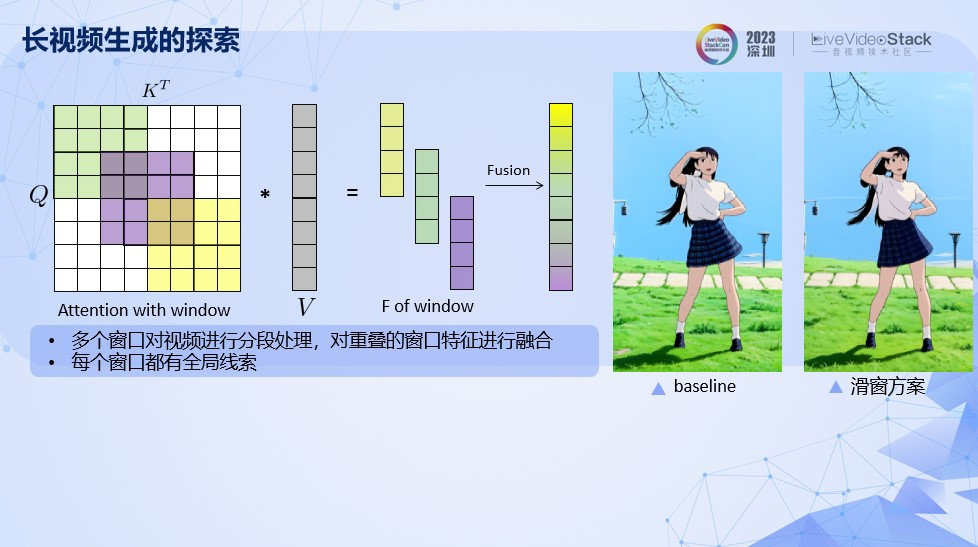
最后给大家讲解一下我们如何做到长视频的生成,由于考虑帧间信息的生成机制,需要占用比较高的显存,我们原来只能在V100,32GB显存的机器上运行16帧的视频生成。但是生成时间过短显示很难满足用户对于视频生成效果需求。
我们通过多个窗口对视频进行分段处理,对重叠区域的窗口特征进行融合,这样使得每个窗口都可以得到视频全时域上的信息。
左边的视频是多段视频直接生成的结果。可以看到段与段之间会产生明显的跳变。右边的视频是多段视频滑窗生成的结果,可以看到视频没有明显的过渡边界。
通过这个方案,我们成功把生成视频的时长从小于2s拓展到20s以上。

上述跟大家介绍了生成稳定性的探索,但是单个视频的生成时间还是比较长,我们还需要优化一下功能的用户体验。
第一个优化体验的方式是补帧算法。

原始视频帧率大多超过24fps,如果每帧都生成,单帧1080p生成的时长是20s左右,耗费的时间也是很长的。所以我们采用固定抽取10帧的方案,然后通过补帧算法,生成30fps的效果。

补帧的效果对比其他开源方案的效果。可以看到在头发细节的还原上,我们的效果是优于其他方案的。
最后即使做了插帧的优化,生成10s视频的100帧的时长大约需要半小时,显然用户很难接受的,也不利于效果的传播。所以我们使用了线上部署的视频分片处理方案,加速视频生成。
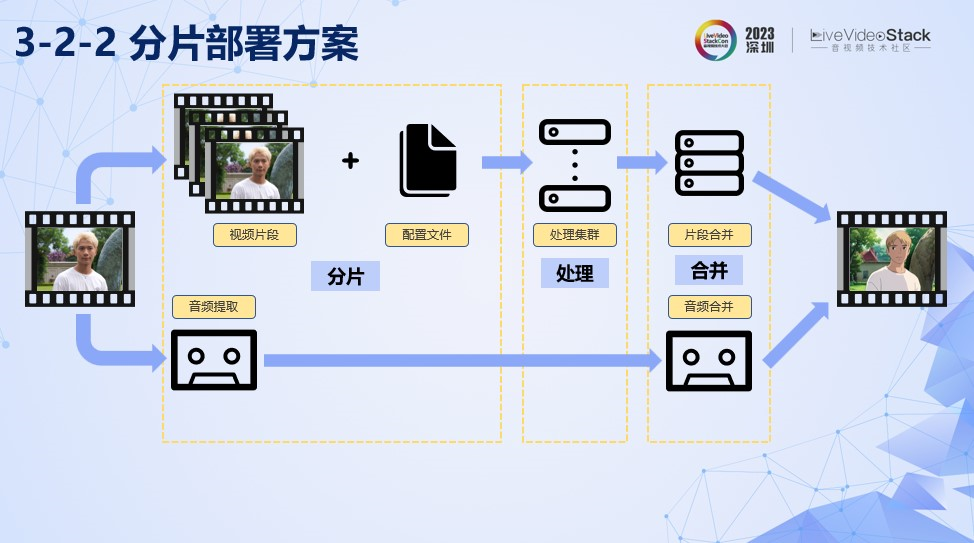
分片处理的pipeline如图,通过分开音视频的处理,在视频的路径中,我们先将视频进行分片并且执行前处理,得到视频片段和风格配置。然后通过片段处理集群,对这些数据进行并行处理,最后通过片段合并算法,合并各个风格片段,并且加入上述提到的补帧算法,得到完整的风格视频。
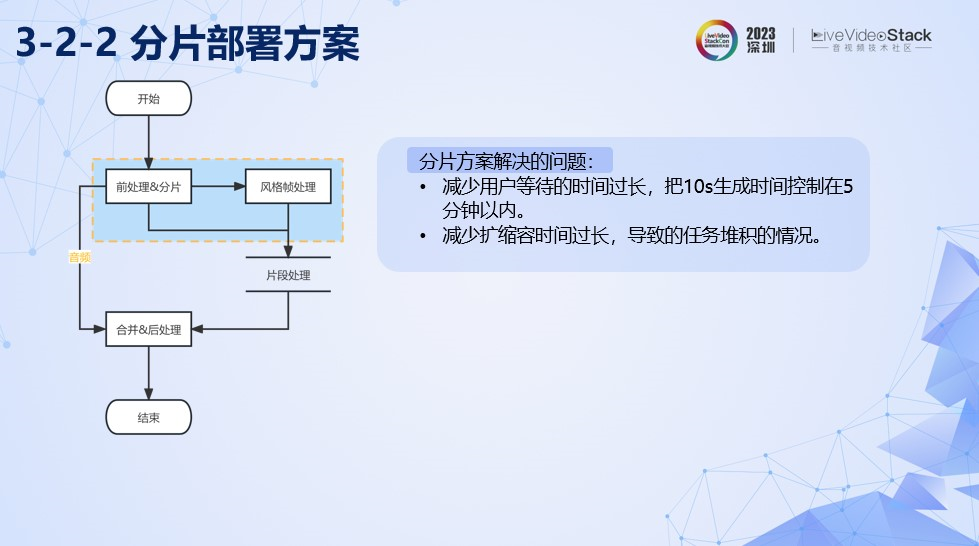
分片方案解决了用户等待的时间过长的问题我们最终把10s时长视频的生成的时间控制在5分钟以内。此外也有效避免扩缩容时间过长,导致任务堆积的问题。
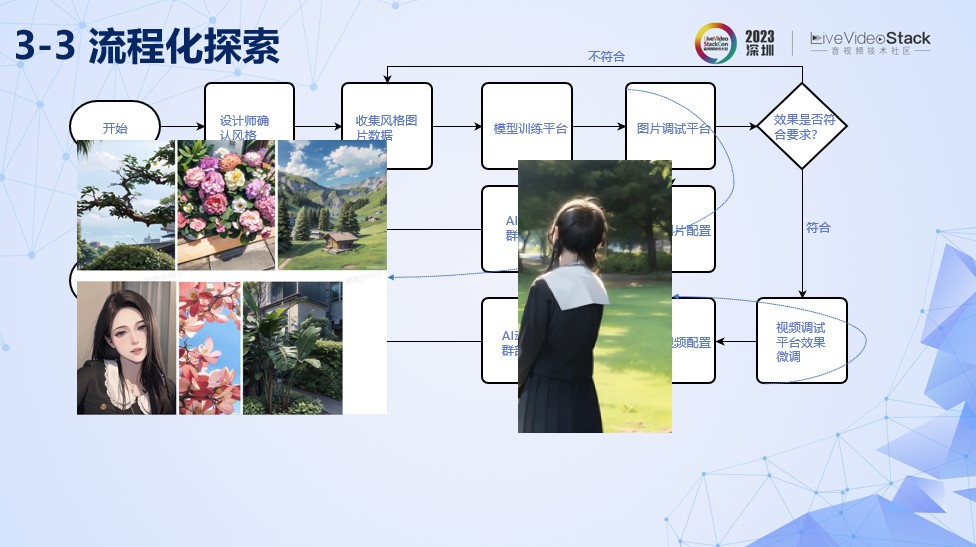
由于AI动漫功能是一个模板化的风格化玩法,所以需要设计师高效生成模版,保持用户新鲜感。我们对工具侧做了一个流程化探索。由于视频调参总是比较耗时的,我们采用调参图片的方式,一开始设计师确定上线风格。然后收集相关风格的图片数据,搭建风格训练平台,让设计师可以训练相应风格的模型。最后通过图片调试平台得到风格效果,对于风格不符合预期的效果,设计师会补充收集相应场景的风格数据训练。对于符合效果的模型,我们会放到视频调试模型进行微调,最后导出视频配置或者图片配置,部署到图片或者视频的集群中。调参图片总是比调参视频高效的,这里我们解决图片和视频配置一致性的问题,是的视频配置和图片配置可以复用以保证相同的调参效果。

通过这个流程化的管理, 上线效率有了很大提升,目前可以保证1-2周推出一个新效果的节奏。
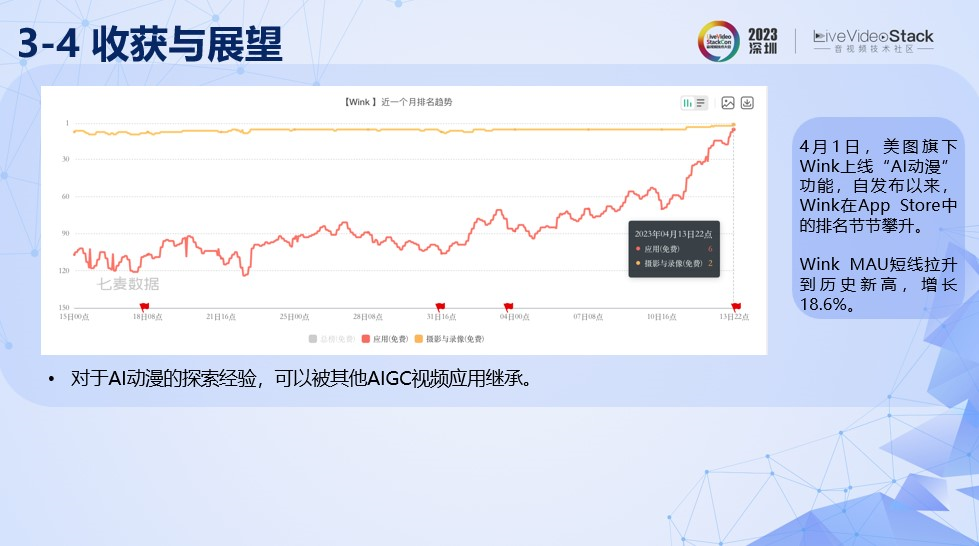
最后,给大家介绍一下AI动漫项目对于我们的收获与展望。
首先,业务层面上,自从美图旗下Wink App上线AI动漫功能以后,Wink在App Store排名节节攀升,从总榜90左右的位置到最高峰时排总榜第6,摄影与录像排名第2。Wink MAU短线拉升到历史新高,增长18.6%。最后,对于AI动漫的探索经验,可以被其他AIGC视频应用所继承。

最后跟大家分享一下我个人对AI动漫功能的看法。
这张冰山图,我把冰山部分比喻成目前AI动漫功能,冰山底下潜藏着巨大应用方向CG动漫制作的智能化。那目前AI动漫功能能否替代现在CG动画的制作呢?答案是否定的。AI动漫从玩法功能到专业功能面临一个比较大问题:非建模方式难以做到CG那样的稳定性。
这里展示的一段CG动画制作的过程,其中打开冰箱后,物体的惯性运动模拟,是通过建模的方式进行精确计算得到。如何把AIGC技术引入到CG动漫制作的工作流当中,是非常值得我们去探索的问题。

这个视频展示了一段CG动画,其中3D模型使用了stability.ai 在10月发布了一个Preview功能, 通过文本创作3D模型草稿。我相信通过类似这种的AI建模技术,AI才能真正介入到CG动画制作的工作流当中。挖掘冰山底下的巨大价值。
以上是我分享的内容,感谢大家!

