编者按大部分人觉得,要想创立一家智算云公司,没有个几十亿投入几乎不可能做起来。而我们对此有不一样的看法。随着智算大模型的发展,业务系统更加庞大复杂,不同领域、不同行业的业务应用,可能千奇百怪,差异巨大。传统公有云赋能千行百业的模式,在具体的某个领域或行业,可能会力有不逮,无法充分赋能企业的业务落...
云计算市场本来已经基本定型:全球三大云服务厂商亚马逊 AWS、微软 Azure,以及谷歌云,占据了大部分市场;在国内,五大巨头占据大部分市场,分别是阿里云、天翼云、移动云、华为云和腾讯云。

编者按算力网,是否像电力网一样?算力网,的确具有类似电力网一样的“网”的特征,一边链接智算中心(类似电厂),一边触达使用算力的企业(如使用电力的工厂、大楼、社区等)。但算力网,又不能仅仅是这些。算力网,其系统的复杂度和面对的挑战要远大于电力网。如果仅考虑“网”的特征,仅关注算力调度,那么算力网的竞争...

编者按“算力调度”的概念,这几年越来越多的被提及。刚听到这个概念的时候,我脑海里一直拐不过弯。作为底层芯片出身的我,一直认为:算力是硬件的服务器和集群,他在某个地方,就是固定的;根本就不存在算力的调度,调度的应该是上层的业务软件。经过跟行业众多朋友的交流和思考后,我逐渐能够理解“算力调度”所表达的意...

编者按算力网和算力网络,是经常被大家提及的话题。有人认为,两者是一回事,就是同一件事情的不同叫法。有的人认为,两者是两回事,算力网络偏重于底层技术实现,而算力网偏重于商业模式和业务层面的算力统筹。目前,整个行业处于快速变化的阶段。许多概念,有相似之处,也有很大的不同之处。甚至同一个概念,不同人、...

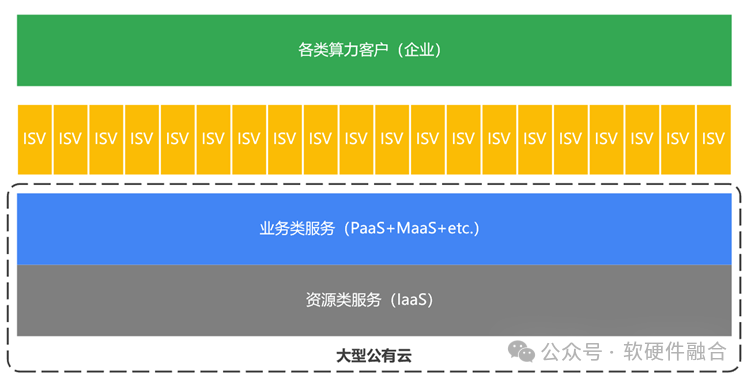
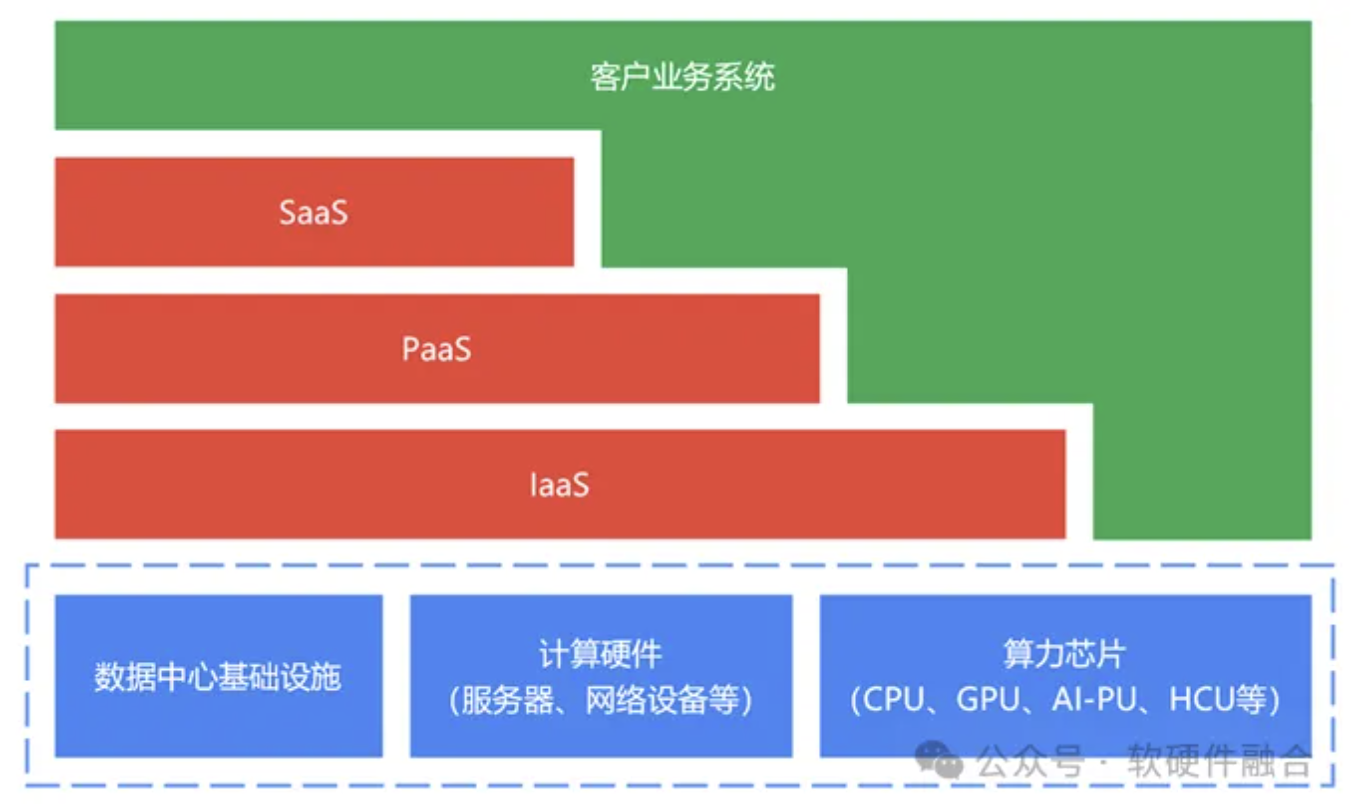
编者按通算时代,是二元模式:云计算公司提供算力,企业客户使用算力。近几年,随着智算兴起,一方面云计算相关技术、产品和业务模式已经非常成熟,另一方面智算的投入非常巨大。于是,行业开始了分工,云计算公司业务一分为二:算力建设业务版块,变成了专业的智算中心类企业;算力销售运营业务版块,则变成了算力(运...

编者按算力网络有一个美好的愿景,就是希望算力和算网,能像电力和电网一样:算力可以标准化,有统一的计量单位。类似电力计量的千瓦时,或称为度数。有很多算力中心生产算力,类似电厂生产电力。生产出来的算力,通过接入算网,最终供应给算力的客户。类似电厂的电力,通过电网接入千家万户。算力“随时随地,无处不在”...

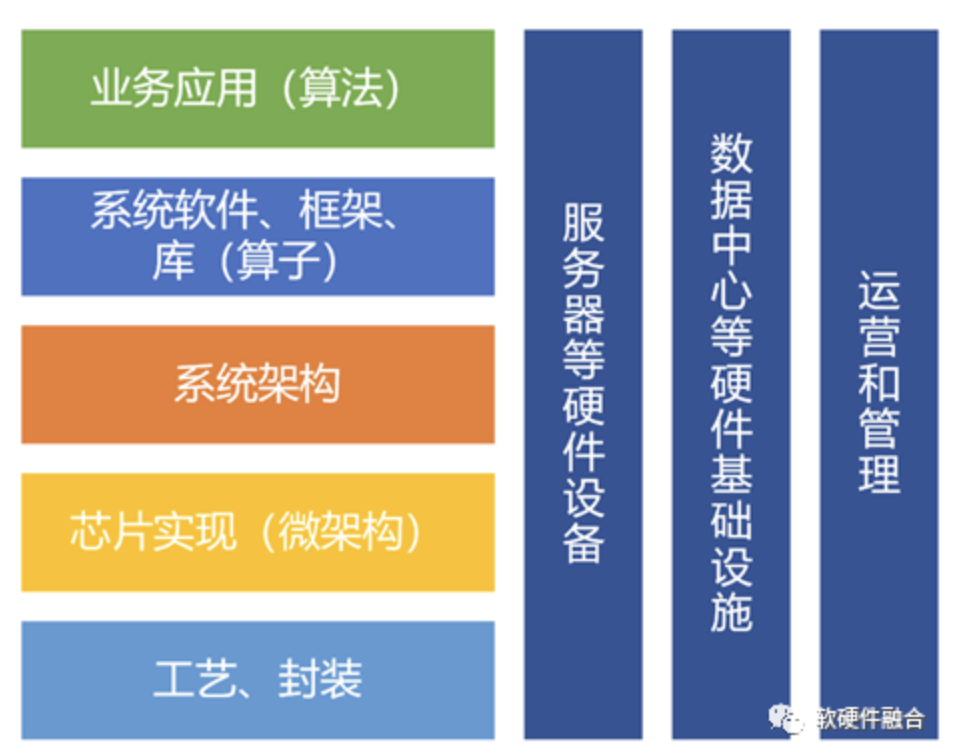
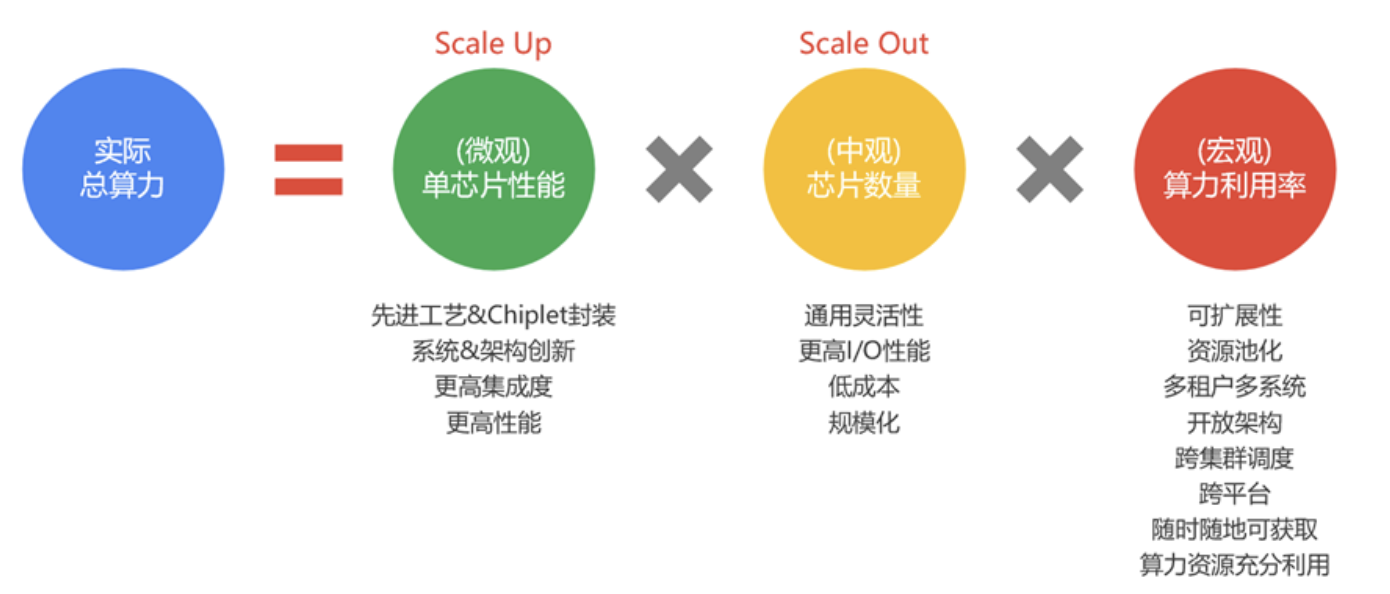
编者按随着大模型的广泛流行,GPU集群计算的规模越来越大(单芯片算力提升有限,只能通过扩规模的方式来提升整体算力),千卡、万卡已经成为主流,十万卡、百万卡也都在未来3-5年的规划中。集群计算的网络可以分为两类:南北向流量,也就是俗称的外网流量;东西向流量,也就是俗称的内网流量。集群计算的网络连接数 S = ...

编者按半个世纪以前,芯片行业只有IDM模式,芯片公司自己设计、制造并封装芯片,典型的公司如Intel、未拆分前的AMD、TI等公司。1987年,台积电TSMC成立。台积电定位芯片制造,并不涉及芯片设计。从此,芯片行业产生了分工,IDM分为了两类企业:芯片设计企业(Fabless,如NVIDIA、拆分后的AMD、高通、博通、Marvell、华为...

编者按之前文章中,我们介绍过复杂计算的概念,今天又给出了一个新的概念:融合计算。两者的区别在哪里?复杂计算是对需求的描述,而融合计算是对解决方案的描述。很多计算解决方案,聚焦具体算法、具体场景,而忽略了变化、迭代,以及平台和生态的建设:“不谋万世者,不足谋一时”。计算的软硬件演进非常快,我们在考虑...

编者按云计算已经发展了20年,是到了变革的时候了。但变革成什么样子,目前还在混沌中。未来将形成的新的业态,我们姑且称之为“算力网络”吧!趁着AI大模型的东风,智算基础设施建设如火如荼。以智算(智算”力”,是算力的一个子集)为重心,更综合更全面的算力网络和算力中心建设,24-26这几年会是一个高潮。目前,行业发...
一直以来,我都认为算力网络是行业整合的过程,通过算力网络运营商把全国的算力资源统筹到一起,形成高效的统一算力供应。但与此同时,总感觉这种模式不对。算力芯片技术日新月异,从底层芯片,到上层业务,方方面面创新迭代极为迅猛。完全统一的算力供应根本跟不上技术创新的步伐。

编者按2023年12月底,由国家发展改革委、国家数据局、中央网信办、工业和信息化部、国家能源局五部门联合印发的《关于深入实施“东数西算”工程 加快构建全国一体化算力网的实施意见》正式公布。算力网络是未来数字经济发展的核心基础设施。要想实现算力网络的伟大愿景,还有非常多的底层技术挑战需要解决。接下来若干篇系...
编者按前面专门写过一篇“软硬件融合”的系统性介绍文章,之后有很多朋友私信交流。不断汲取大家对软硬件以及软硬件相互协作方面的观点,逐步深化和完善“软硬件融合”概念和技术体系。简单总结一下。一方面,大家对未来认识的大方向是趋同的,就是“软硬件要深度结合/协同”。但另一方面,对软硬件融合观点的认识,也存在如下...
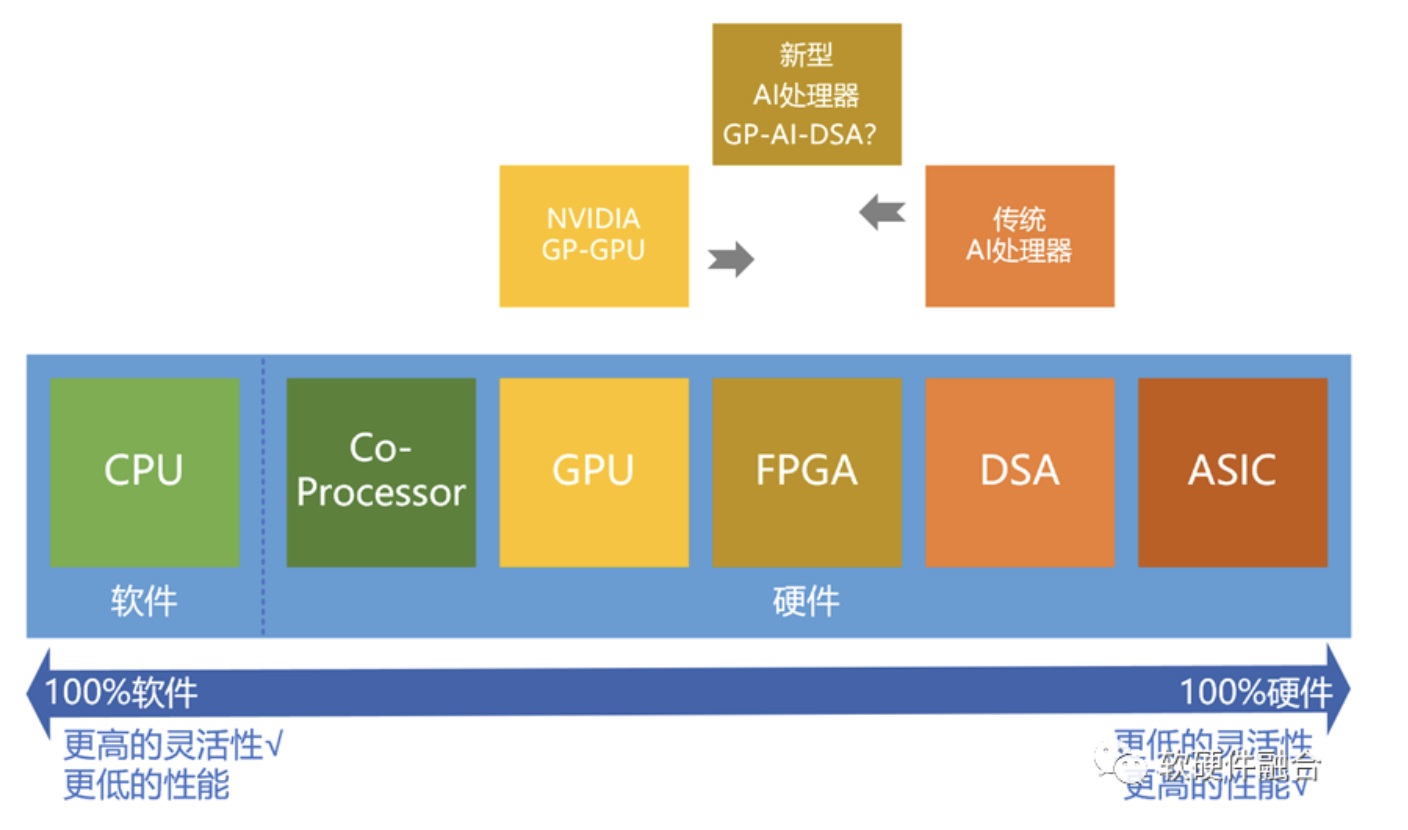
编者按AI大模型的热潮不断,预计未来十年,AGI时代即将到来。但目前支撑AI发展的GPU和AI专用芯片,都存在各种各样的问题。那么,在分析这些问题的基础上,我们能不能针对这些问题进行优化,重新定义一款能够支持未来十年AGI大模型的、足够灵活通用的、效率极高性能数量级提升的、单位算力成本非常低廉的、新的AI处理器类...
编者按作为技术类的公众号,今天这篇文章,我们聊点技术之外的一些更宏观的发展话题:)最近跟一个朋友,交流了一些不那么“纯技术”的话题:后进如何赶超先进?在交流的过程中,也引发了我对技术发展的一些更深层次的思考。关于后进赶超先进,网上有太多的文章和视频。作为常年从事计算机算力芯片相关工作的我,今天就从...
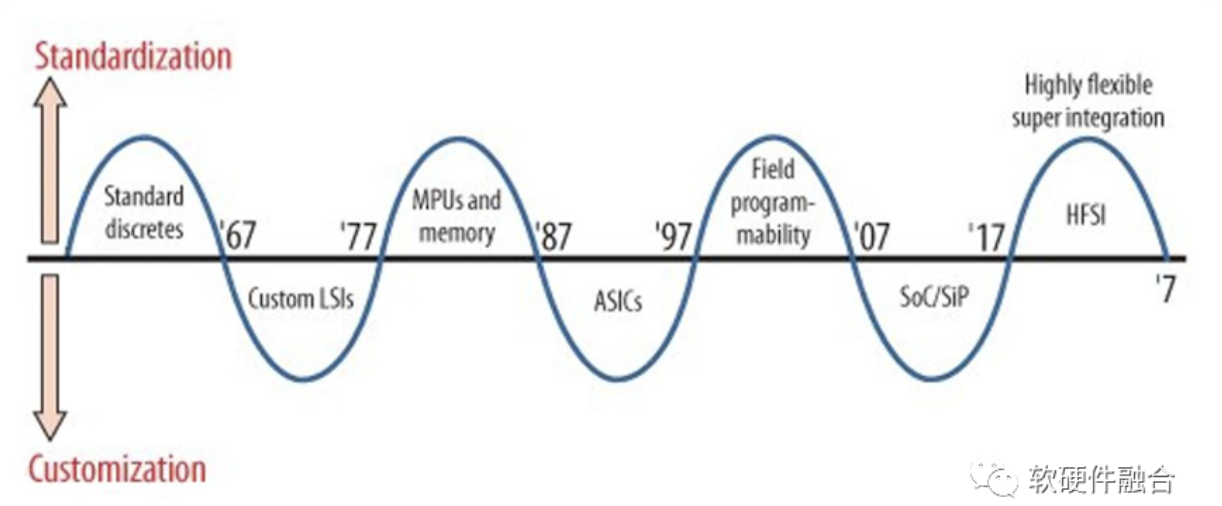
编者按大家一直有个误解,觉得通用和专用,是对等的两个选择。例如,牧本波动(Makimoto's Wave),是一个与摩尔定律类似的电子行业发展规律,它认为集成电路有规律的在“通用”和“专用”之间变化,循环周期大约为10年。我们的观点则是:相比专用,通用是更高级的能力。集成电路等各种事物发展规律的常态是通用,“通用到专...
编者按关于“弯道超车”,行业内很多人士对此嗤之以鼻,他们认为:做事情要脚踏实地,持之以恒,才有可能超越。但这两者并不矛盾:在已有的不断发展的领域,我们需要“数十年如一日”不断的努力,才有可能逐渐追赶上世界先进水平,才有可能从追赶到齐头并进甚至超越;比如航天科技领域。但在一些行业变革期,我们需要尽早布...
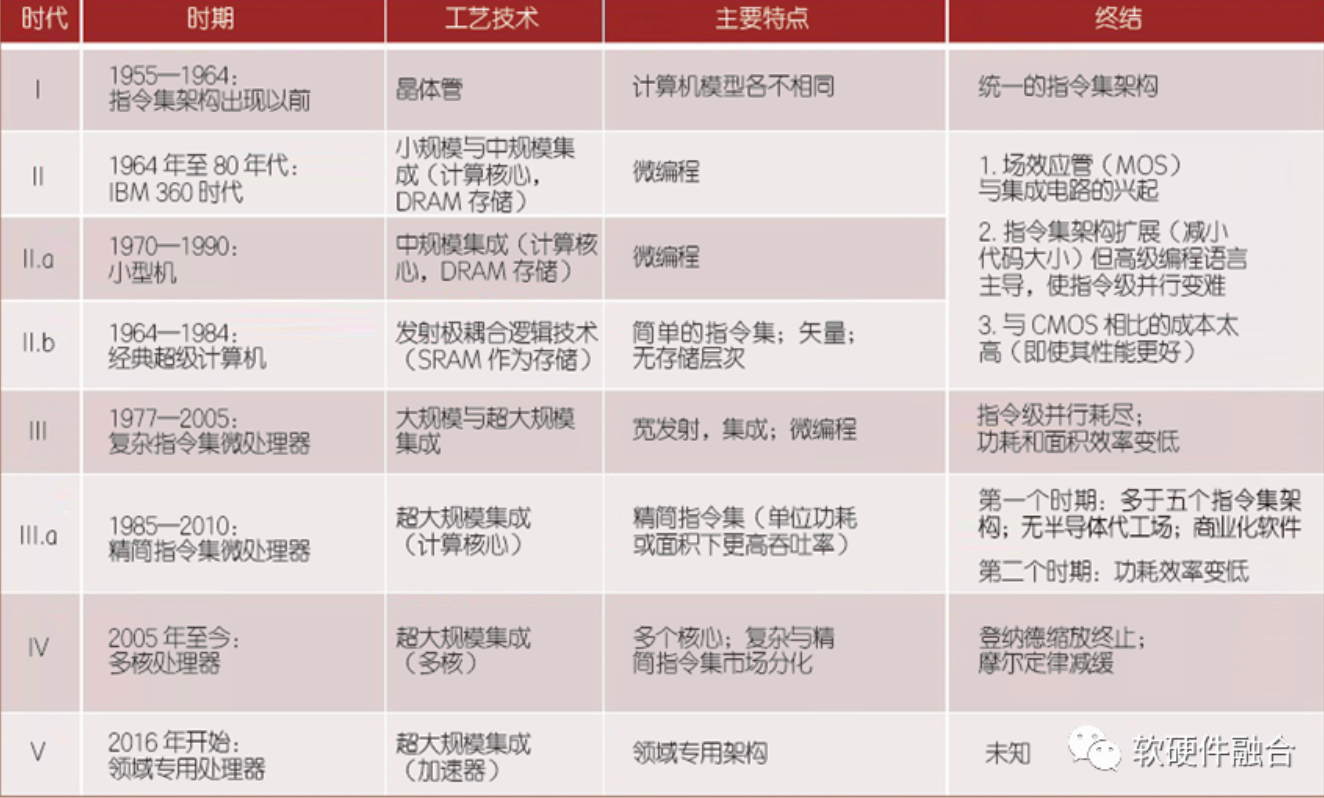
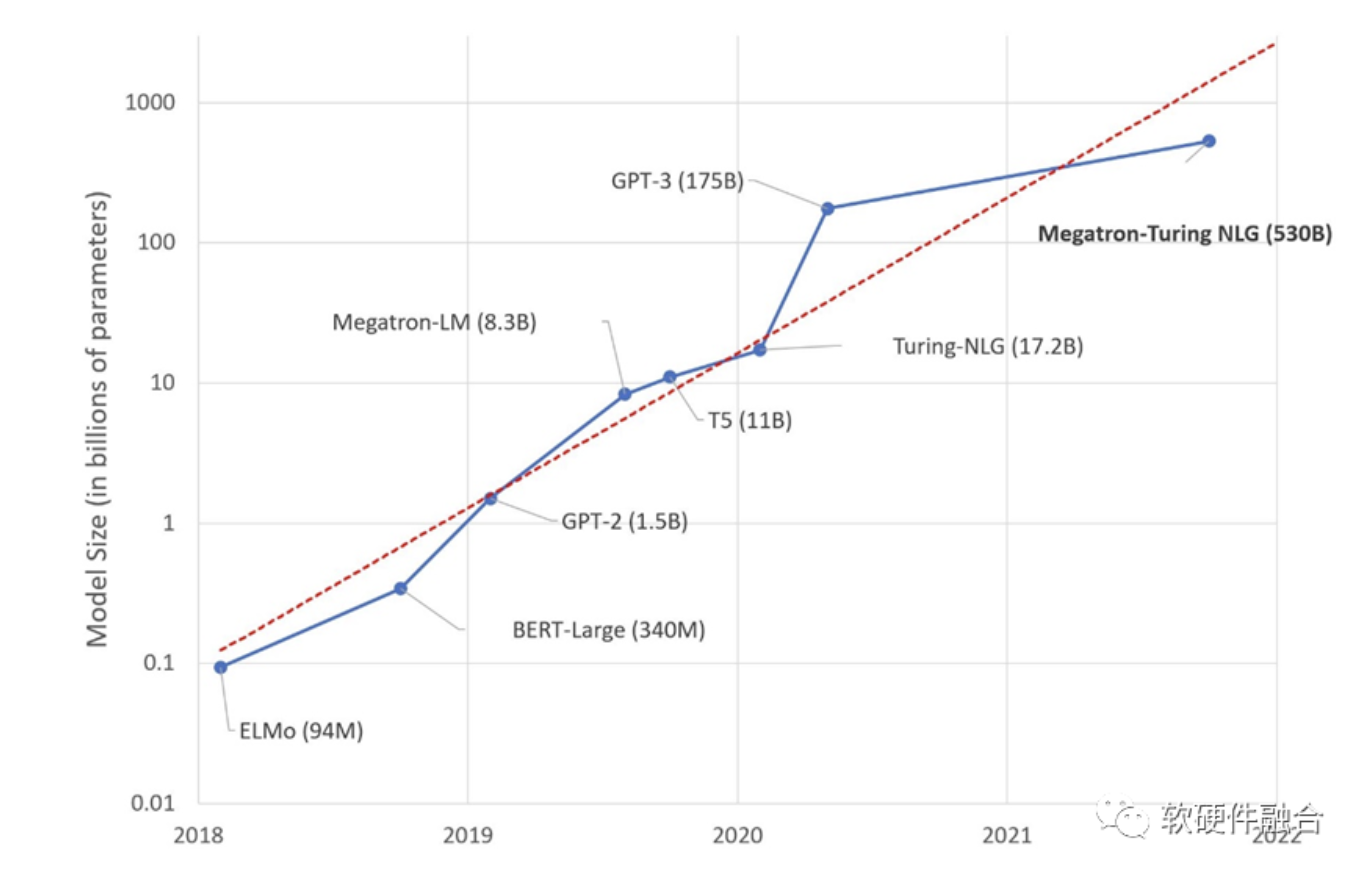
随着ChatGPT的火爆,AGI(Artificial General Intelligence,通用人工智能)逐渐看到了爆发的曙光。短短一个月的时间,所有的巨头都快速反应,在AGI领域“重金投入,不计代价”。
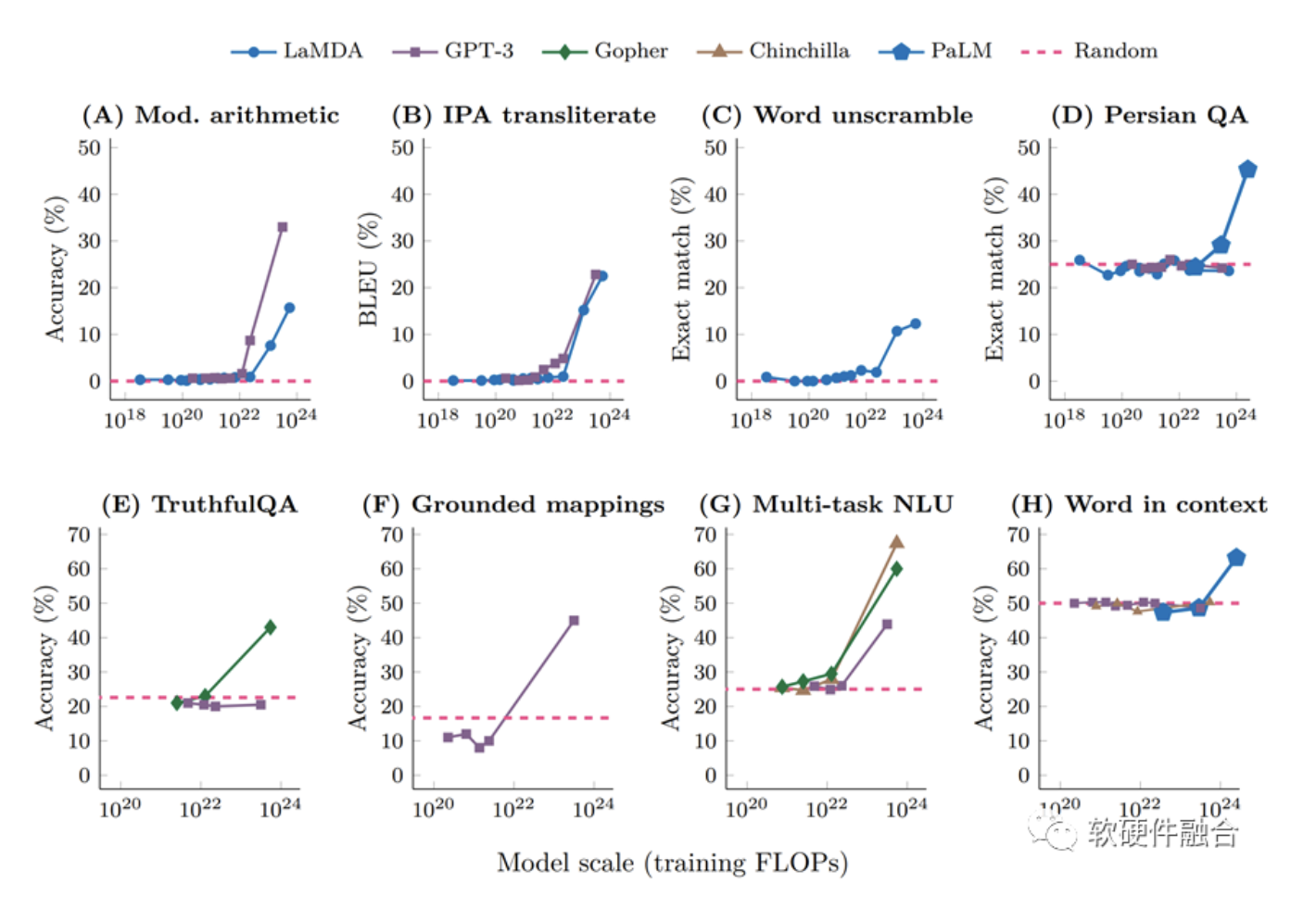
GPT等大模型为什么没有突破万亿参数?核心原因在于在现在的GPU平台上,性能和成本都达到了一个极限。想持续支撑万亿以上参数的更大的模型,需要让性能数量级提升,以及单位算力成本数量级的下降。这必然需要全新架构的AI计算平台。