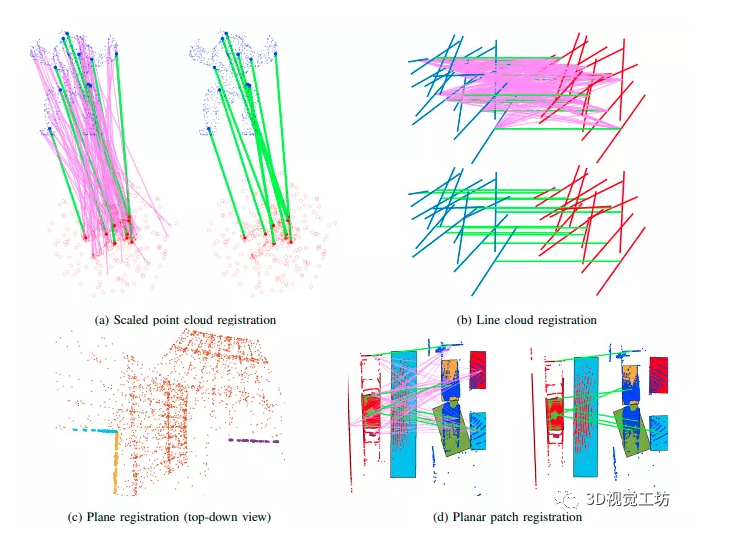
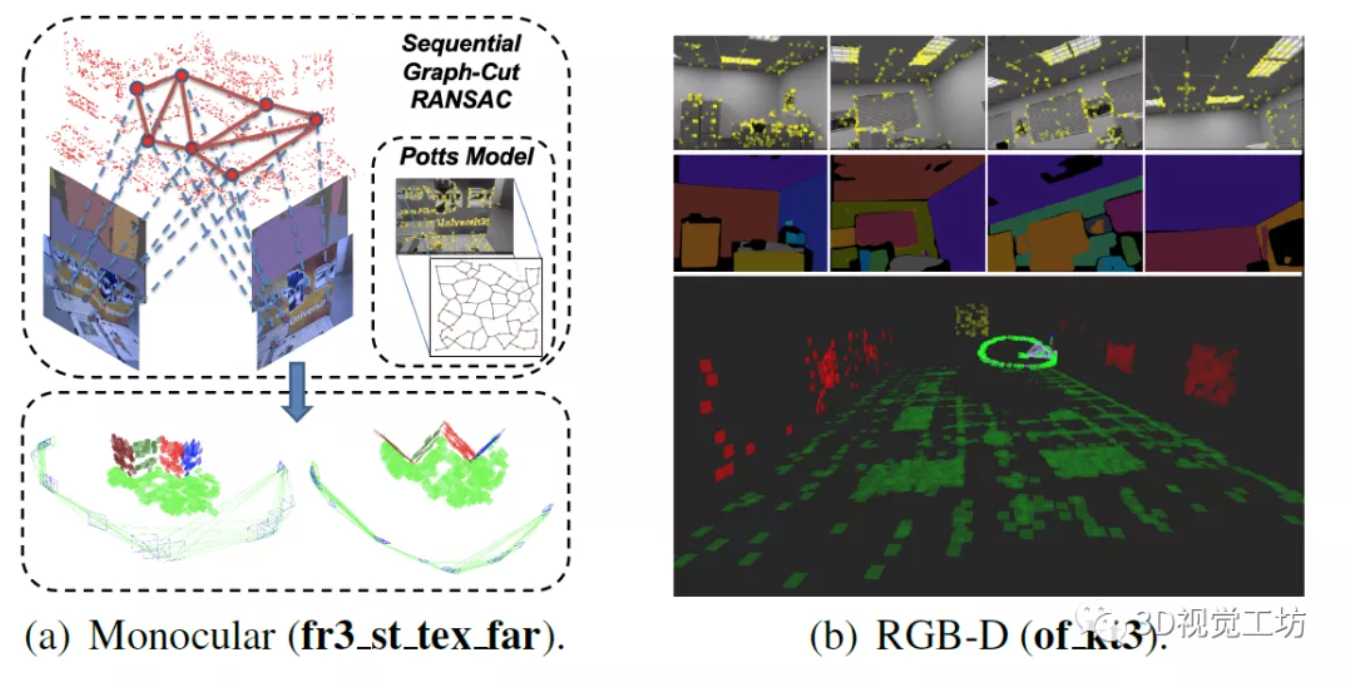
《CLIPPER: A Graph-Theoretic Framework for Robust Data Association》(ICRA 2021 ) 基于图论的点云数据关联方法,通过寻找最稠密的子图来寻找一致关联(内联),通过投影梯度上升的方法保持低时间复杂度,在斯坦福兔子的嘈杂点与990个异常值关联和仅10个内部关联关联关联的实例中,该方法成功地在138毫秒内以100%的精...
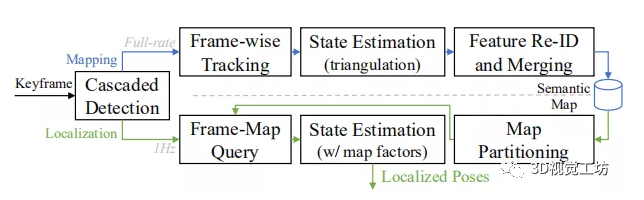
R3LIVE: A Robust, Real-time, RGB-colored, LiDAR-Inertial-Visual tightly-coupled state Estimation and mapping package

Road Mapping and Localization using Sparse Semantic Visual Features
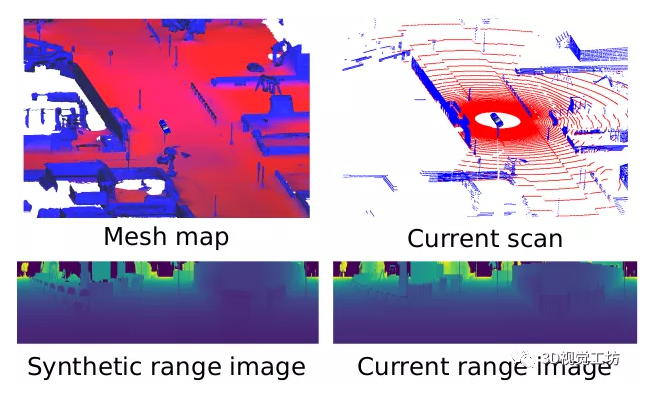
Chen X, Vizzo I, Läbe T, et al. Range Image-based LiDAR Localization for Autonomous Vehicles[J]. arXiv preprint arXiv:2105.12121, 2021. ICRA 2021,波恩大学;
作者提出了一种语义平面 SLAM 系统,该系统使用来自实例平面分割网络的线索来改进位姿估计和映射。虽然主流方法是使用 RGB-D 传感器,但在这样的系统中使用单目相机仍然面临着鲁棒的数据关联和精确的几何模型拟合等诸多挑战。在大多数现有工作中,几何模型估计问题,例如单应性估计和分段平面重建(piece-wise planar re...
在自动驾驶、机器人、AR/VR领域,越来越多的方案开始采用多相机、多激光雷达的配置来达到多传感器融合的目的。多模态传感器标定是这些系统正常运行的前提,但是目前的多模态传感器标定方案仍然很麻烦,需要大量的人工介入,不适合部署到产线上。本文提出一种多相机、多雷达系统的外参标定方案,只需要采集一帧数据即可完...

1. point-based的方法为什么有效?作者认为由于其提供了精确的位置信息。但是也一定程度上损失了效率,因为对点特征的采样和融合是非常耗时的操作。
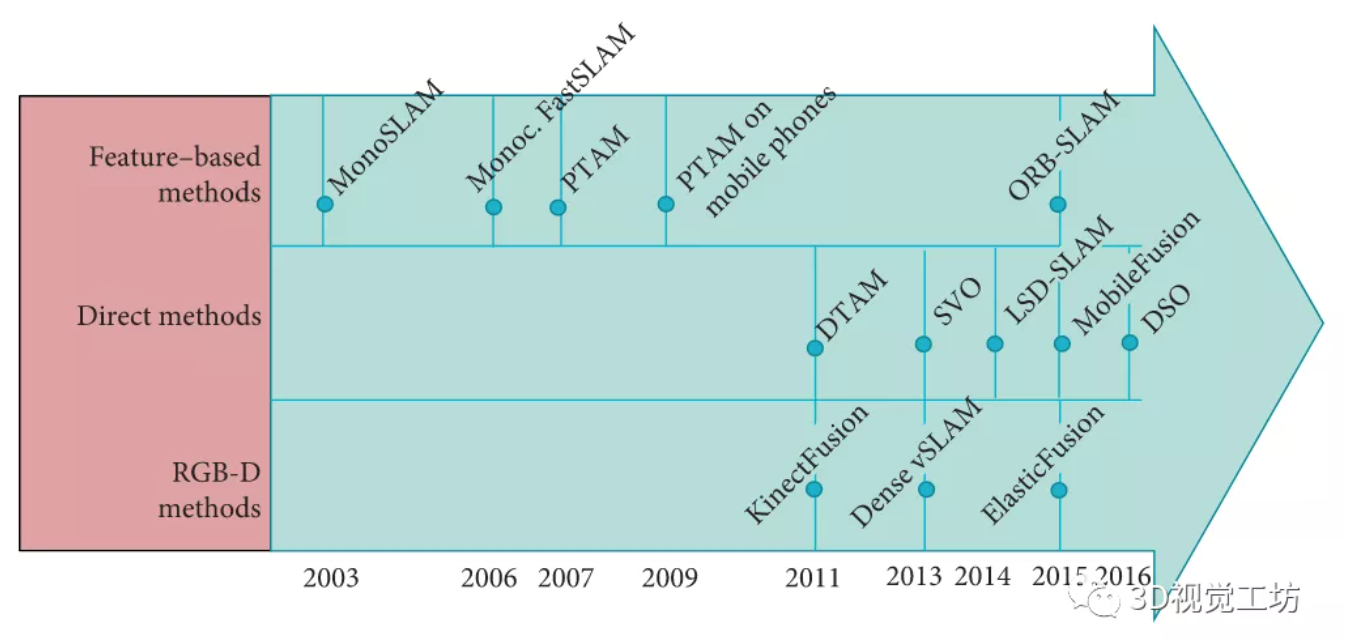
Visual and Visual-Inertial SLAM: State of the Art, Classification,and Experimental Benchmarking
Super Odometry: IMU-centric LiDAR-Visual-Inertial Estimator for Challenging Environments

本文是PatchMatchStereo[1]第二篇拾遗,主要讲解PatchMatch的深度/视差传播策略,以及在其基础上,介绍几种基于PatchMatch的改进传播策略,分别是ETH的Gipuma[2]方法和华中科技大学的ACMM[3]。不同于SGM在极线纠正之后的影像上进行同名极线(核线)上搜索,PatchMatchStereo在整个视差空间内进行搜索,既保证全局搜索的准...

专注于计算机视觉、VSLAM、目标检测、语义分割、自动驾驶、深度学习、AI芯片、产品落地等技术干货及前沿paper分享。这是一个由多个大厂算法研究人员和知名高校博士创立的平台,我们坚持工坊精神,做最有价值的事~
专注于计算机视觉、VSLAM、目标检测、语义分割、自动驾驶、深度学习、AI芯片、产品落地等技术干货及前沿paper分享。这是一个由多个大厂算法研究人员和知名高校博士创立的平台,我们坚持工坊精神,做最有价值的事~

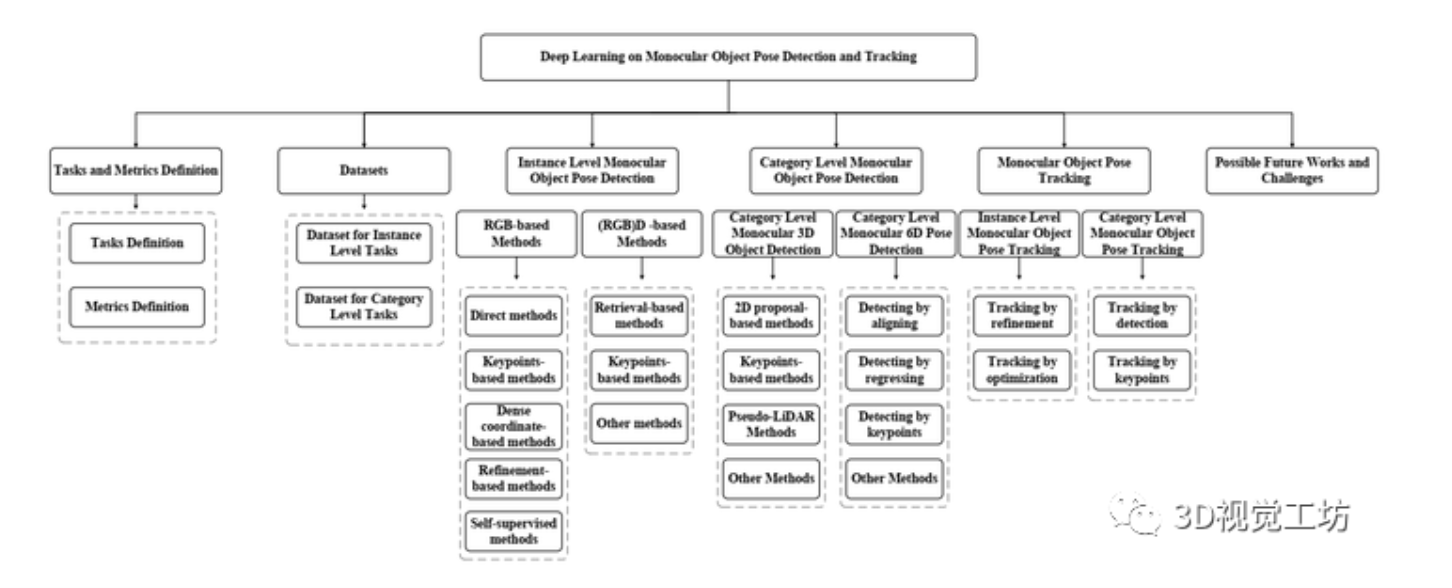
原文:Deep Learning on Monocular Object Pose Detection and Tracking: A Comprehensive Overview
解决一个优化问题,常见的优化器比如梯度下降法, 牛顿法等, 一般会先计算梯度------>再求出参数下一步更新的方向和步长。

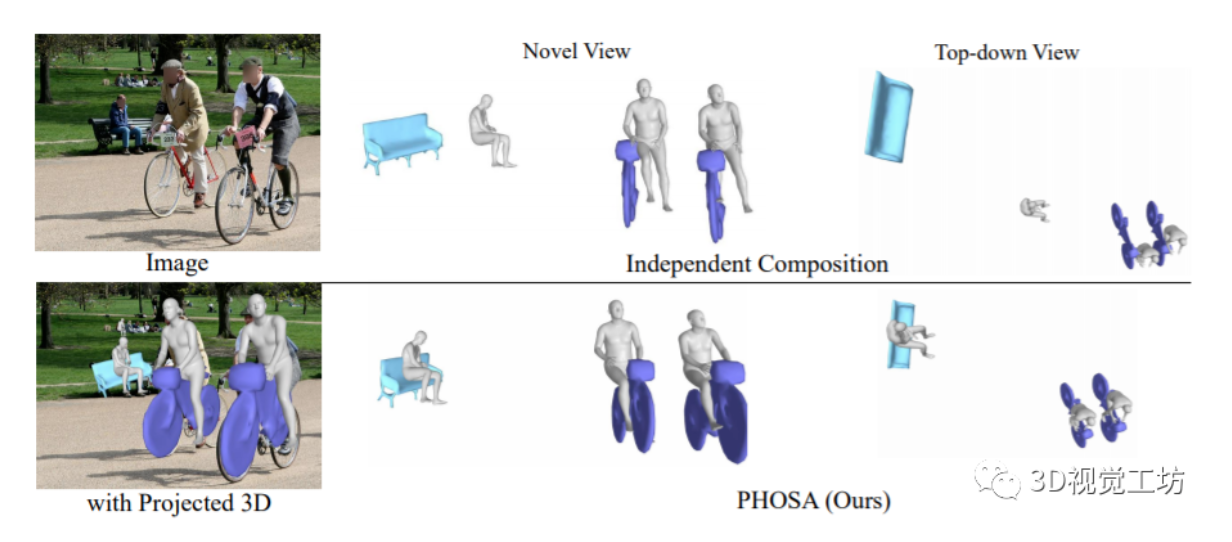
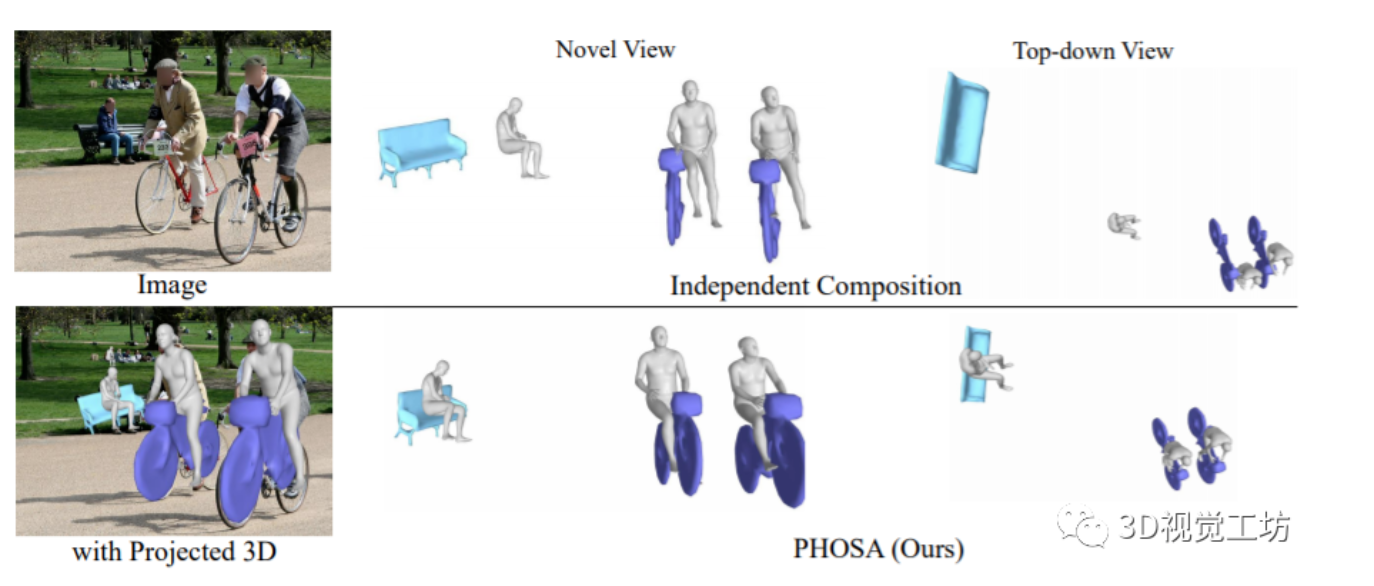
作者提出了一种能够推断出人类和物体的形状和空间排列的方法,只需要一张在自然环境中捕捉的图像,且不需要任何带有3D监督的数据集。该方法的主要观点是,将人类和物体结合起来考虑,这样会产生“三维常识”,可以用来消除歧义。验证表明,该方法可以极大地减少物体的三维空间,达到更好的效果,作者在含有人类和大型物体...
Monocular Real-time Full Body Capture with Inter-part Correlations

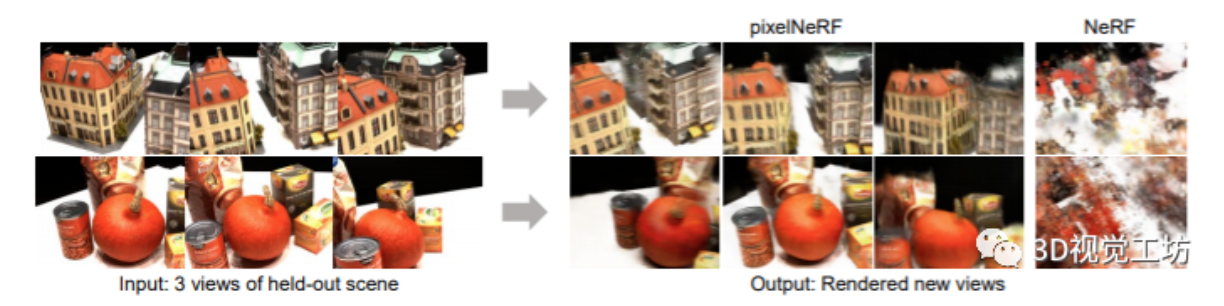
作者提出了pixelNeRF,一个只需要输入单张或多张图像,就能得到连续场景表示的学习框架。由于现存的构建神经辐射场【1】的方法涉及到独立优化每个场景的表示,这需要许多校准的视图和大量的计算时间,因此作者引入了一种新的网络架构。实验结果表明,在所有情况下,pixelNeRF在新视图合成和单图像三维重建方面都优于当前...
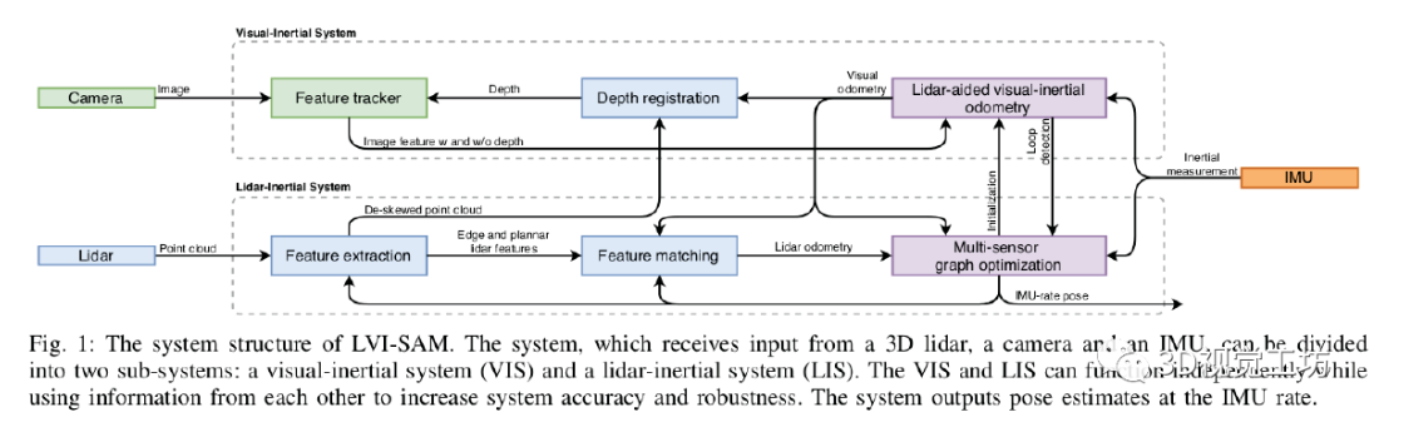
我相信很多人对激光视觉惯导融合的系统都是这样设计的,但是最难的是把自己的想法保质保量的实现出来。我们做不到但是大佬可以!
作者提出了一种能够推断出人类和物体的形状和空间排列的方法,只需要一张在自然环境中捕捉的图像,且不需要任何带有3D监督的数据集。该方法的主要观点是,将人类和物体结合起来考虑,这样会产生“三维常识”,可以用来消除歧义。验证表明,该方法可以极大地减少物体的三维空间,达到更好的效果,作者在含有人类和大型物体...
由香港大学CVMI Lab和牛津大学合作提出了一种点云上具有动态内核组装的位置自适应卷积——PAConv: Position Adaptive Convolution with Dynamic Kernel Assembling on Point Clouds,论文已被CVPR2021接收。



