自监督的表征学习领域近几个月来获得了显著的突破,特别是随着Rotation Prediction, DeepCluster, MoCo, SimCLR等简单有效的方法的诞生,大有超越有监督表征学习的趋势。然而,相信做这个领域的研究者都深有感触:1)自监督任务复杂而多样,不同方法各有各的专用训练代码,难以结合、复用和改进;2)评价方案不统一,不...
无监督的去遮挡和场景分解这个问题从18年底就开始思考了,因为并没有之前的工作很好地定义场景去遮挡这个问题,更别说解决,更别说用无监督的方法解决,所以前期踩了不少坑。那为什么要用无监督呢?有监督当然能解决,但是太没有挑战性了(划掉),因为amodal mask(包括可见的和被遮挡的区域)的标注是很困难的,具有较...
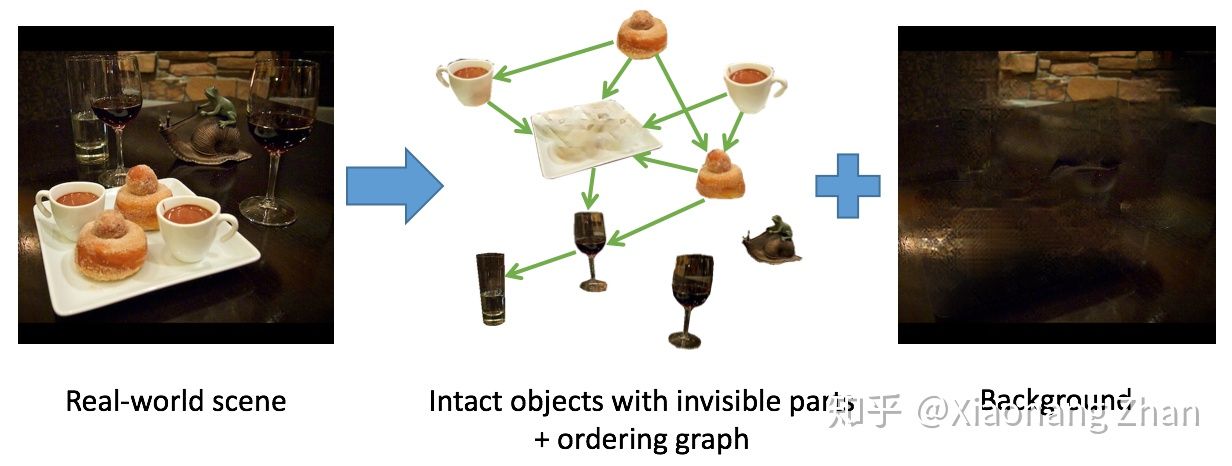
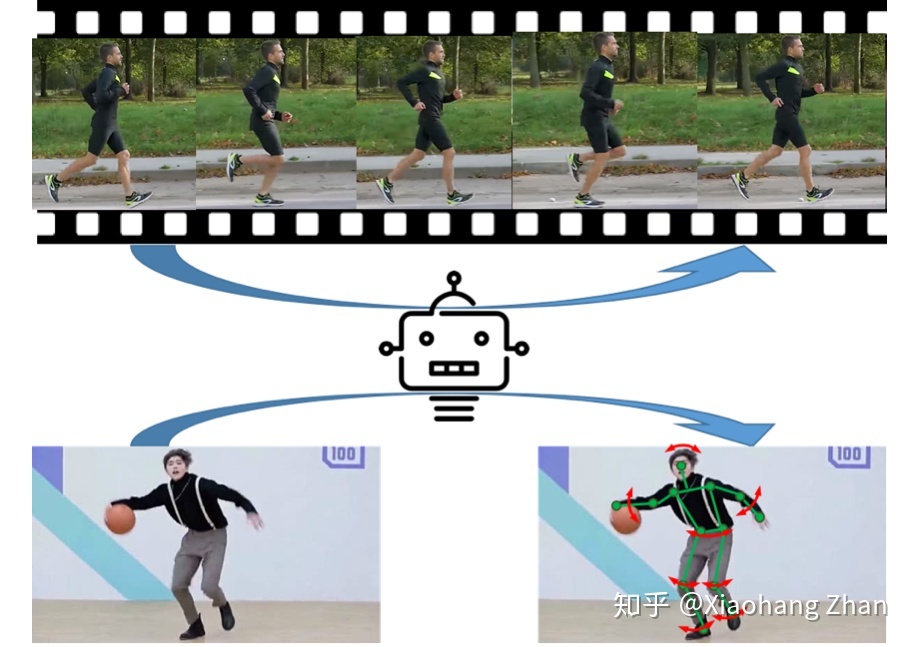
在Long Beach开CVRP中途抽空写了一下我们这次被接收的工作:Self-Supervised Learning via Conditional Motion Propagation [1] 的一些心得。这里我用一种intuitive的方式来分享这篇文章的思路来源,希望能对读者有所启示。本文首发知乎作者:Xiaohang Zhan
人脸识别也许是最成功也最先到达瓶颈的深度学习应用。在go deeper, more data,higher performance的思想指导下,模型更深了,数据却越来越难增加。本文首发知乎作者:Xiaohang Zhan



