本篇文章为此芯Armv9 AI PC开发套件瑞莎“星睿O6”资料/产品介绍/教程等汇总文,持续更新,欢迎关注。

编程、模型、手工
在我工作中曾经帮助一些客户定位和解决芯片SoC硬件,CPU挂死问题这类疑难杂症。这类问题在被报告的时候,通常表现为软件不正常工作,例如Linux kernel RCU stall(CPU多核系统中其中一个核挂死,其RCU资源无法释放,不能响应中断,传导到其他核,进而导致整个Linux系统RCU hang)。再如系统多次开关机后,系统运行不正常。...

Arm KleidiAI是一个利用arm CPU向量扩展指令(包括NEON MLA, dot product, i8mm矩阵乘,SME2 outer product, SME2 multi-vector等)加速AI应用中的GEMM, GEMV,矩阵转置,量化运算的uKernel (micro-kernel)软件库。

引言:告别,无休的memcpy, memset软件优化。Three instructions are all you need

SME2在SME的基础上,通过加入multi-vector(多向量)支持更好地平衡之前的向量计算和矩阵乘计算加速,提高向量处理能力和矩阵乘运算逻辑的重用性。SME2也加入了压缩机器学习的数据格式的支持

Arm CPU是当今AI赋能软件的关键,它解释,处理和执行指令。Arm指令集作为硬件和软件的接口,它指示处理做什么和怎么做。Arm指令持续进化以满足现代计算的需求,包括AI的兴起,机器学习和芯粒技术的使用,高级安全威胁。持续创新保证了arm的普及,普适性能,能效,安全和开发者灵活性。为了确保开发工作与快速发展的市场...

理解本文需要具备SME2构架预备知识,建议先阅读之前文章。本文先介绍如何利用INT8整型类型SME2 outer product and accumulate指令实现的矩阵乘。

(国庆之后的仅有的一天周末天气不佳,大部分时间用来码文,尽快完成这些arm CPU对AI/ML序列文章... 写文章太累了)

这条指令将第一个SVE2源向量中每128-bit看作2x8有符号8位整数矩阵, 第二个SVE2源向量中每128-bit的8x2有符号8位整数矩阵,然后将第一个SVE2源向量中的2x8矩阵与第二个SVE2源向量中的对应的8x2矩阵进行矩阵乘,生成的2x2 32位整数矩阵乘积累加到目标向量中的32位整数矩阵累加器中。使用SVE2 Int8 Matrix Multiply进行矩阵...

前文讲了Arm用于加速AI, ML应用的向量和SME指令,本文介绍如何使用这些指令来实现矩阵乘。A(M x K)矩阵和B (K x N)矩阵的矩阵乘(得到C矩阵 M x N)可以表达为:

为了进一步利用向量寄存器,在向量运算中执行更多的乘加(MAC)操作。Armv8.6-a引入了矩阵乘(Matrix Multiply)指令。这些指令相当于取A矩阵的两行放在向量Vec_A中,取B矩阵的两列放在向量Vec_B中,矩阵乘指令执行:

Arm为在各类技术领域运行无处不在的人工智能 (AI) 奠定了坚实的技术基础。Arm 始终专注于快速地进行架构演进,确保arm生态系统能够适应未来的技术趋势和不断变化的计算需求。过去二十多年来,Arm 一直致力于为 AI 创新奠定基础,先是在 Armv7 架构中引入了高级单指令多数据 (SIMD) 扩展,初探机器学习 (ML) 工作负载,再...

内存与ZA tile行或列之间的存取操作指令,以及SVE Z 寄存器和ZA tile 行或列之间的移动指令

最近本人写了一篇介绍Arm Scalable Matrix Extension (可伸缩矩阵扩展,SME)的文章,[链接]。此为中文版,也加入了部分Introducing Armv9 Scalable Matrix Extension for AI Innovation on the Arm CPU [链接]内容。

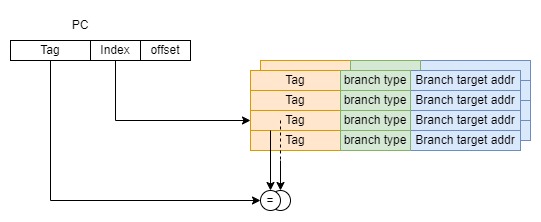
现代CPU须在指令预取pipeline stage具备性能良好的分支预测器,以给pipeline后端供应充足有效的指令。大多数CPU会使用 BTB(Branch Target Buffer)或BTAC(Branch Target Address Cache),Global History Buffer 和 RAS(Return Address Stack) 等部件来分别预测程序中分支语句和函数返回的跳转地址,较新的CPU还可能采...
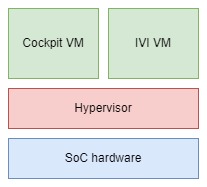
汽车SoC芯片上一般采用虚拟化技术来隔离多个虚拟机,在同一硬件平台上运行多个系统,例如一个虚拟机运行IVI Linux/Android系统,另一个虚拟运行Cockpit系统。通过虚拟化技术可以实现在同一SoC硬件平台上的资源隔离分区,如CPU核的分配,物理内存的分配和隔离,外设的分配等。汽车产品上一般是采用Type 1的hypervisor虚拟...
随着人工智能(AI)的崛起和安全威胁加剧,计算的需求持续加强。因此,世界上各种设备核心的基础计算架构的持续演进显得尤为重要。这就是为什么我们的工程团队向Arm架构中添加新的功能和技术,然后软件团队确保软件尽可能无缝地利用这些未来的功能和技术。