
以下有部分公式,如果无法显示,请访问原文链接
从本文开始,之后的三四篇我们都将沐浴在数学的海洋里,拼命地扑腾,这个系列我会尽力以通俗易懂的方式来讲述这些数学知识。
1 函数
1.1 一次函数
在数学函数中最基本、最重要的就是一次函数。也就是函数之基础、根本。它在神经网络的世界里也同样重要。
1.1.1 一元一次函数
这个函数可以用下面的式表示。$a$被称为斜率(用来控制直线的方向),$b$被称为截距(用来控制直线和原点的偏移)
$$y=ax+b(a、b为常数,a\neq 0)$$
当x、y两个变量满足上述公式时,就称为变量y和变量x是一次函数关系。
有两个变量$x$和$y$,如果对每个$x$都有唯一确定的$y$与它对应,则称$y$是$x$的函数,用 $y=f(x)$ 表示。此时,称$x$为自变量,$y$为因变量。
一次函数的图像是直线,如下图的直线所示。
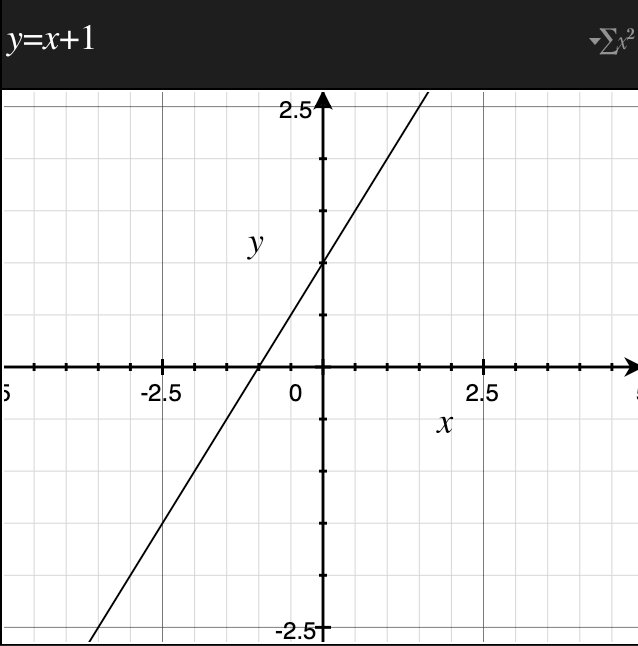
示例:一次函数$y=2x+1$的图像如下图所示,截距为 1,斜率为 2。

1.1.2 多元一次函数
上面我们说的$y=ax+b$中有一个变量x,我们称为一元,如果有多个变量,我们就称为是多元的,比如下面的式子。(有几个变量就是几元的,也可以理解为维度)
$$y=ax_1+bx_2+...+c(a、b、c为常数,a\neq 0,b\neq 0)$$
当多个变量满足上述公式时,也称为变量y与变量是一次函数关系。
就像我们之前说的神经元的加权输入$z$就可以表示为一次函数关系。如果把作为参数的权重$w_1、w_2、...、w_n$与偏置$b$看作常数,那么加权输入$z$h和$w_1、w_2、...、w_n$就是一次函数关系。
$$z=w_1x_1+w_2x_2+...+w_nx_n+b$$
1.2 二次函数
1.2.1 一元二次函数
刚刚我们接触了一次函数,下面说说二次函数。二次函数很重要,像我们经常使用的代价函数平方误差就是二次函数。二次函数由下面的式表示。
$$y=ax^2+bx+c(a、b、c为常数,a\neq 0)$$
二次函数的图像是抛物线,如下图所示。我们会发现抛物线的凹凸(开口朝向)是通过上方式子中$a$的正负来决定的。
- 当$a>0$时,抛物线向上开口,向下凸起
- 当$a<0$时,抛物线向下开口,向上凸起。
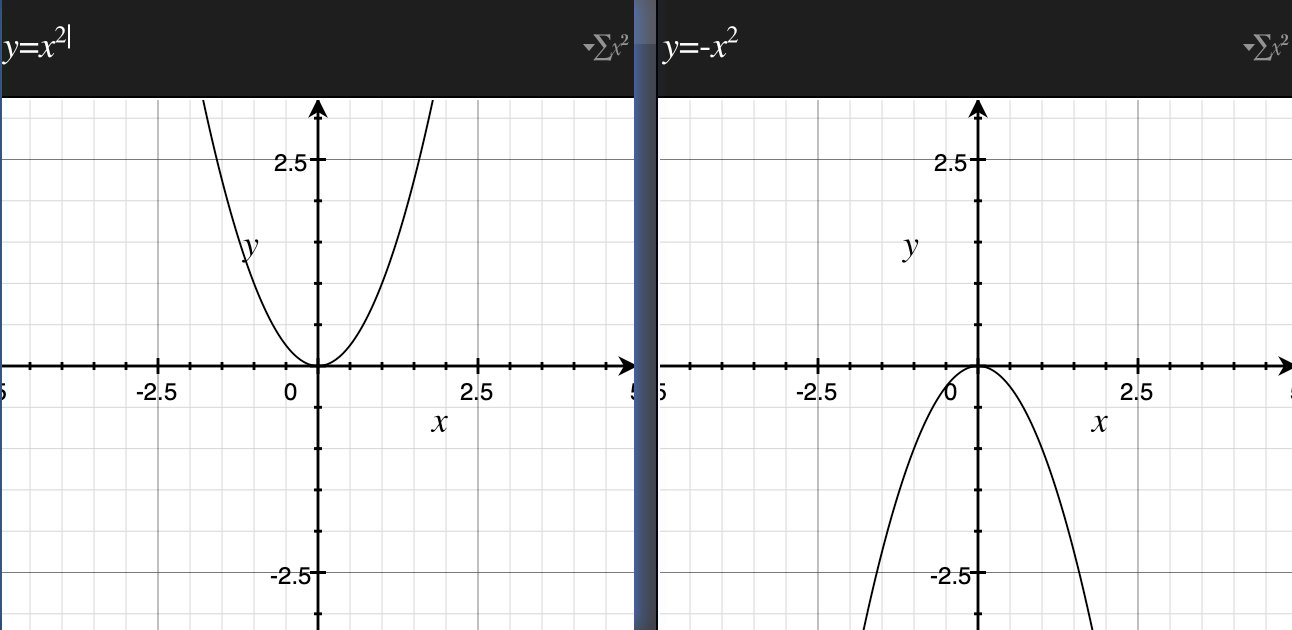
所以当$a>0$时该函数的$y$存在最小值。(该性质是后面讲的最小二乘法的基础)
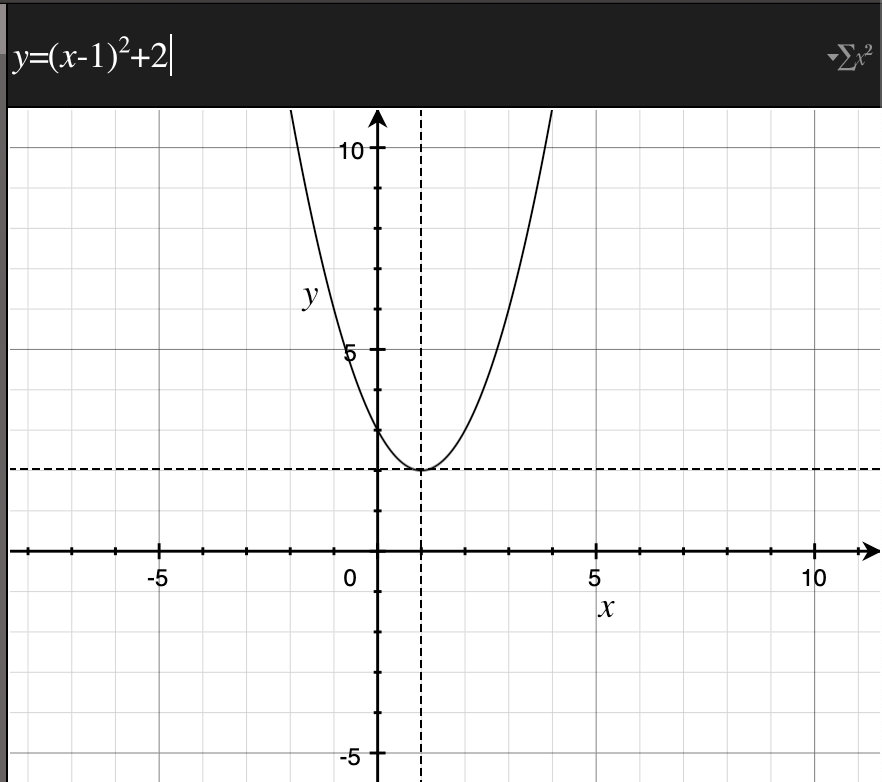
示例:二次函数$y=(x-1)^2+2$的图像如右图所示。从图像中可以看到,当$x=1$时,函数取得最小值$y=2$。
1.2.2 多元二次函数
在我们实际的神经网络中需要处理更多变量的二次函数,这些二次函数统称多元二次函数,学会了一元二次函数,那么多元二次函数就不会太难了,下面我们以一个二元二次函数进行举例。
就像我们使用的代价函数平方误差c就是多元二次函数:
$$C=(x_1-t_1)^2$$
1.3 单位阶跃函数
之前,我们已经接触过它了,还记得吗,作为生物界神经元的激活函数。下面我们再说一遍吧。
单位阶跃函数,在原点处不连续,也就是在原点处不可导,由于这两个性质,所以单位阶跃函数不能成为主要的激活函数。
$$u(x)=\left\\{ \begin{matrix} 0\quad (x<0) \\\\ 1\quad (x\ge 0) \end{matrix} \right\\} $$
单位阶跃函数的图像如下:

1.4 指数函数
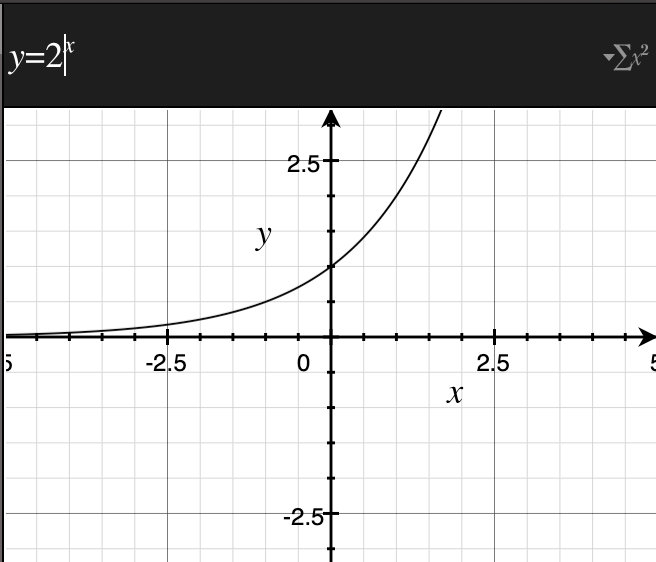
什么是指数函数呢?我们之前讲了一次函数和二次函数,其实只要把变量放到幂的位置,其实就是指数函数了,具有以下形状的函数称为指数函数,常数$a$被称为函数的底数。
$$y=a^x(a为正的常数,a\neq 1)$$
指数函数的图像是类似于撇的一种样式,如下所示
上面说到底数,就不得不说自然常数$e$,又叫纳皮尔数或欧拉数,它和派$\pi$类似,是一个无限不循环小数,它的值如下
$$e\approx 2.71828...$$
1.4.1 sigmoid函数
上面说到自然常数e,那么就不得不提到大名鼎鼎的自然指数函数$e^x$,它在数学界有自己的标识exp或exp(x)
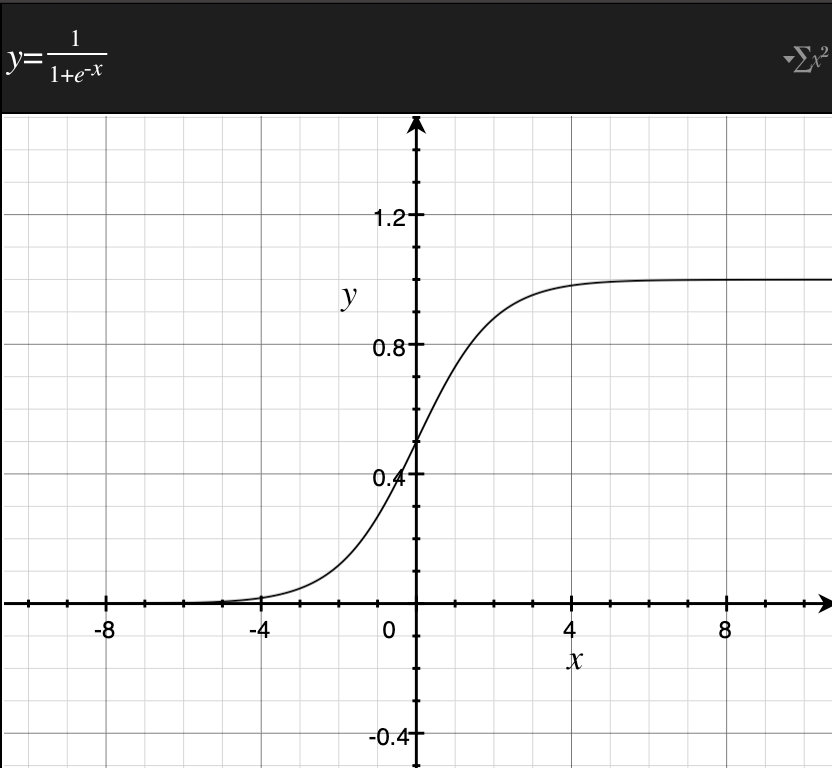
而我们这里所要讲的是包含自然指数函数的复合函数sigmoid函数,它是神经网络中很具有代表性的激活函数。它的公式如下
$$\sigma (x)=\frac { 1 }{ 1+{ e }^{ -x } } =\frac { 1 }{ 1+exp(-x) } $$
通过下方的图像,我们可以看到,这个函数是光滑的,这就代表着这个函数处处可导,函数的取值在(0,1)区间内,那么这个函数值就可以用概率来解释
1.5 正态分布的概率密度函数
在计算机实际确定神经网络时,我们需要首先给权重和偏置设定初始值,这样神经网络才能进行计算。而这个初始值怎么取呢,这个时候我们就会用到一个非常有用的工具,叫做正态分布,这里就不长篇大论的解释啥是正态分布了,它也没什么高大上的地方,就是概率分布中的一种分布方式,但是这个分布方式是及其复合人类和自然界的,有兴趣的朋友可以去深入了解下。在这里只说一下,我们在给神经网络分配权重和偏置时分配一个服从正态分布的随机数,会比较容易取得好的结果。
正态分布是服从下面的概率密度函数的概率分布。公式如下
$$f\left( x \right) =\frac { 1 }{ \sqrt { 2\pi \sigma } } { e }^{ -\frac { { (x-\mu ) }^{ 2 } }{ 2{ \sigma }^{ 2 } } }$$
- 常数$\mu$:期望值(平均值)
- $\sigma$:标注差
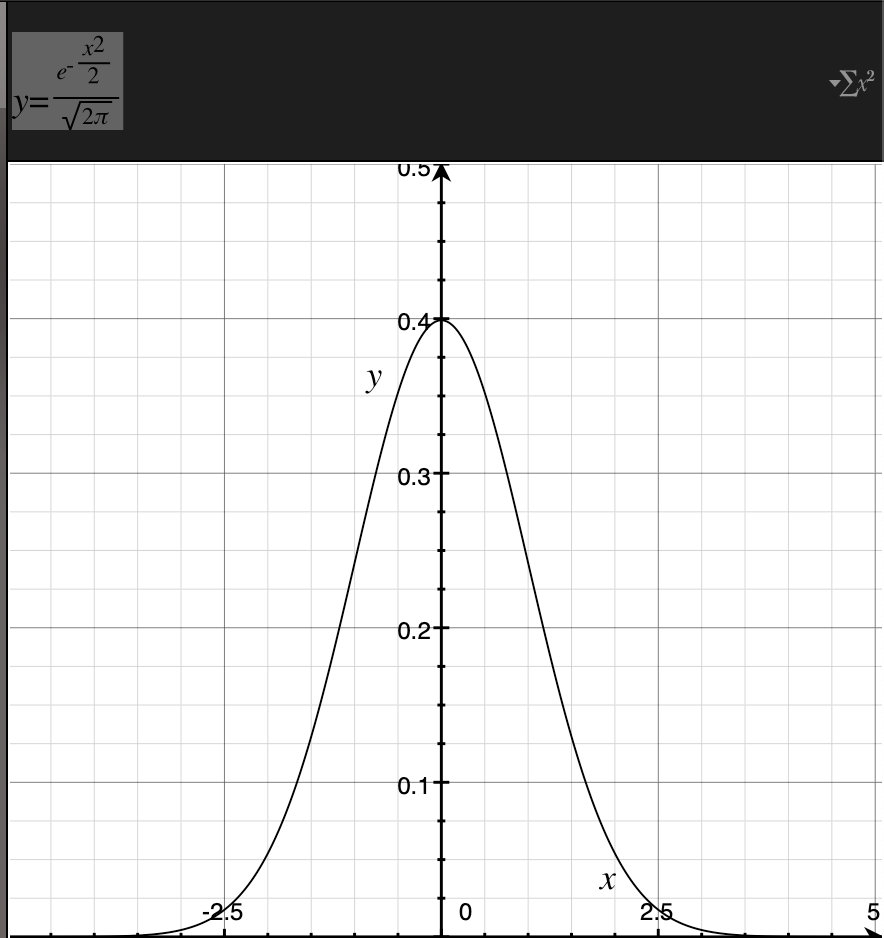
它的图像如下,由于形状像教堂的钟,所以被称为叫钟形曲线

示例:试作出期望值$\mu$为0、标准差$\sigma$为1 的正态分布的概率密度函数的图像。
$$f\left( x \right)=\frac { 1 }{ \sqrt { 2\pi } } e^{ -\frac { x^{ 2 } }{ 2 } }$$
2 数列
2.1 数列的含义
数列就是数的序列,比如下面就是偶数列的数列
$$2,4,6,8,...$$
数列中的每一个数都被称为项,排在第一位的项叫做首项,排在第二位的项叫做第2项,以此类推,排在第n位的项叫做第n项(是不是有点废话),神经网络中出现的数列都是有限的数列,这种数列叫做有穷数列,在有穷数列中最后一项称为末项,数列中的数量称为项数,而像上面的偶数列是无穷数列
示例:考察下面的有穷数列的首项,末项以及项数
$$1,3,5,7,9$$
这个数列的首项是1,末项是9,项数是5
2.2 数列的通项公式
数列中排在第$n$项的数通常用$a_n$表示,这里$a$是数列的名字,可随意取。当想要表达整个数列时,使用集合的符号来表示,如$\left\\{a_n\right\\}$
将数列的第$n$项用一个关于$n$的式子标书出来,那么这个式子被称为通项公式,比如偶数列的通项公式就是下方的式子
$$a_n=2n$$
示例:求以下数列$\left\\{b_n\right\\}$的通项公式
$$1,3,5,7,9$$
通项公式为$b_n=2n-1$
在神经网络中,神经元的加权输入和输出可以看成数列,比如使用下方的展示方式:
- 加权输入:第$l$层的第$j$个神经元的加权输入用$z_j^l$
- 输出:第$l$层的第$j$个神经元的输出用$a_j^l$
2.3 数列与递推关系式
除了通项公式外,数列还有另外一种表示方式,就是用相邻的关系式来表示,这种表示法被称为数列的递归定义
一般,如果已知首项$a_n$以及相邻的两项$a\_n、a\_{n+1}$的关系式,那么就可以确定这个序列,这个关系式叫递推关系式
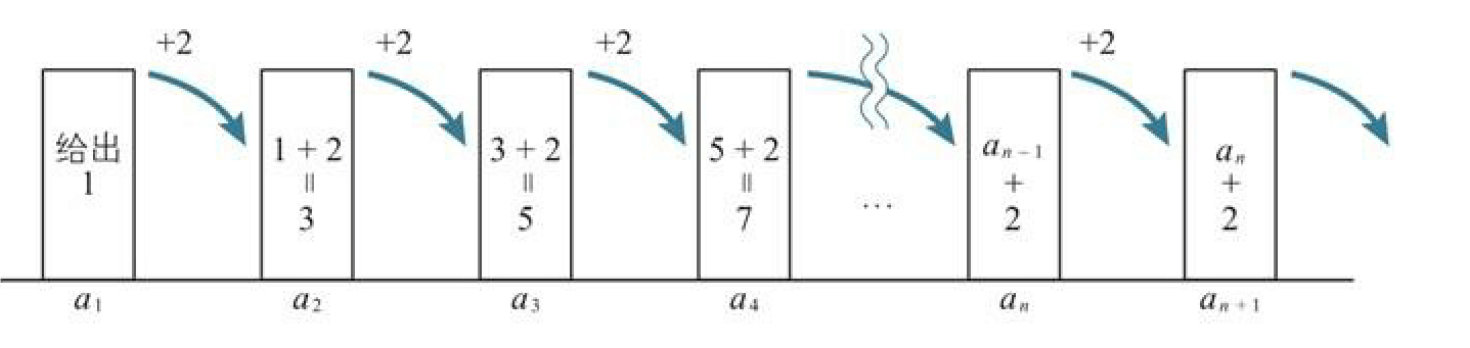
示例:已知首项$a_1=1$以及关系式$a\_{n+1}=a\_n+2$,可以确定以下数列,这个关系式就是数列的递推关系式。
$$a\_{1}=1\\\\a\_{2}=a\_{1+1}=a\_{1}+2=1+2=3\\\\a\_{3}=a\_{2+1}=a\_{2}+2=3+2=5\\\\a\_{4}=a\_{3+1}=a\_{3}+2=5+2=7\\\\...\\\\a\_{1}=1,a\_{n+1}=a\_{n}+2$$
2.4 联立递推关系式
下面我们演示一个问题,这个算法就是神经网络中的误差反向传播中所用到的数列的解题算法联立递推算法。
示例:求以下两个地推关系是定义的数列前3项,其中$a_1=b_1=1$
$$\begin{cases} a\_{ n+1 }=a\_{ n }+2b\_{ n }+2 \\\\ b\_{n+1}=2a\_{n}+3b\_{n}+1 \end{cases}$$
解题:
$$\begin{cases} a\_{ 2 }=a\_{ 1 }+2b\_{ 1 }+2=1+2\times 1=5 \\\\ b\_2=2a\_1+3b\_1+1=2\times 1+3\times 1+1=6 \end{cases}$$
$$\begin{cases} a\_{ 3 }=a\_{ 2 }+2b\_{ 2 }+2=5+2\times 6+2=19 \\\\ b\_{ 3 }=2a\_{ 2 }+3b\_{ 2 }+1=2\times 5+3\times 6+1=39 \end{cases}$$
像这样,将多个数列的递推关系式联合起来组成一组,称为联立递推关系式。在神经网络的世界中,所有神经元的输入和输出在数学上都可以认为是用联立递推式联系起来的。例如,我们来看看之前文章中看过的一个神经元的图片
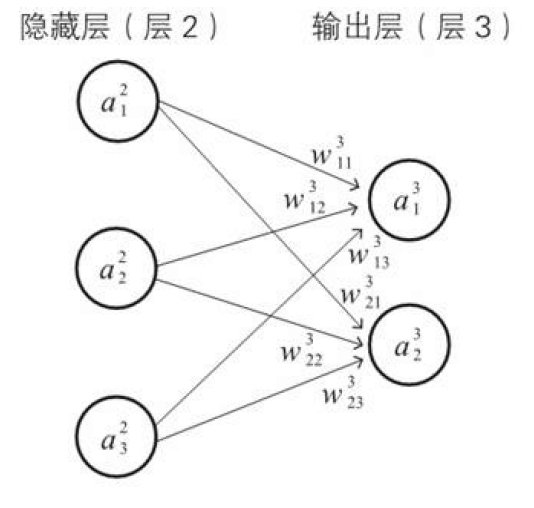
在箭头前端标记的是权重,神经元的圆圈中标记的是神经单元的输出变量。于是,如果以$a(z)$为激活函数,$b_1^3$、$b_2^3$为第3层各个神经元的偏置,那么以下关系式成立:
$${ a }\_{ 1 }^{ 3 }=a({ w }\_{ 11 }^{ 3 }{ a }\_{ 1 }^{ 2 }+{ w }\_{ 12 }^{ 3 }{ a }\_{ 2 }^{ 2 }+{ w }\_{ 13 }^{ 3 }{ a }\_{ 3 }^{ 2 }+{ b }\_{ 1 }^{ 3 })$$
$${ a }\_{ 2 }^{ 3 }=a({ w }\_{ 21 }^{ 3 }{ a }\_{ 1 }^{ 2 }+{ w }\_{ 22 }^{ 3 }{ a }\_{ 2 }^{ 2 }+{ w }\_{ 23 }^{ 3 }{ a }\_{ 3 }^{ 2 }+{ b }\_{ 2 }^{ 3 })$$
根据这些关系式,第3层的输出$a_1^3$和$a_2^3$由第2层的输出$a_1^2$、$a_2^2$、$a_3^2$决定。也就是说,第2层的输出与第3层的输出由联立递推关系式联系起来。我们之后学的误差反向传播就是将这种观点应用在神经网络中。
为什么要将联立递推应用在神经网络中呢?
其实是因为对比计算冗长的偏导关系式,计算机更加擅长计算递推关系。
评论请转至原文链接
本文来自纳兰小筑,本文不予回复,评论请追溯原文

