
该文是香港城市大学、商汤科技、腾讯优图等联合投于CVPR2018的一篇关于动态场景去模糊的论文。它采用IIR+动态滤波器的思想进行图像去模糊。由于相机抖动、不同景深下目标运动等导致的空间可变模糊问题,这类动态模糊移除极具挑战性。尽管深度学习方法在该问题已取得了极大进步,但它们均采用网络往往比较大且耗时。作者提出一种空间可变神经网络以解决上述问题。所提方法包含三个CNN与一个RNN,RNN用于在特征图上进行反卷积操作,三个CNN分别用于计算特征图、RNN权值以及图像重建。整个网络可以通过端到端的方式进行训练,作者通过分析表明:尽管具有很小的模型,但其网络具有非常大的感受野。最后,作者通过实验定量与定性分析表明:在精度、速度以及模型大小方面,所提方法均取得了SOTA性能。
首发知乎:https://zhuanlan.zhihu.com/p/79562993
文章作者: Happy
论文链接:http://www.cs.cityu.edu.hk/~rynson/papers/cvpr18c.pdf(文章尾部可直接下载)
代码链接:https://github.com/zhjwustc/cvpr18_rnn_deblur_matcaffe
Abstract
已有基于深度学习的方法存在两个问题:(1) 权值空间不可变,很难采用一个很小的模型去估计动态场景去模糊问题;(2)尽管模糊区域较大,但仍需要大图像区域用于提升感受野,这会导致更大的模型以及更高的耗时。
为解决上述问题,作者提出一种空间可变RNN方法,其中RNN部分的逐像素权值通过CNN学习得到。它主要有以下三点贡献:
- 一种新的端到到的空间可变RNN,其中RNN部分逐像素参数通过CNN学习得到,它可以移除空间可变模糊;
- 去模糊过程可以建模为IIR模型,进一步分析了所提空间可变RNN与去模糊之间的关系,表明:空间可变RNN具有更大的感受野,可以模拟去模糊过程;
- 在公开基准数据及上对所提方法进行了定量与定性分析,均表明:在速度、精度以及模型大小方面,所提方法取得了SOTA性能。
Method
接下来,将分析一下去模糊过程为何与IIR过程(该过程可以通过RNN近似)等价,并给出了作者所涉及的空间可变RNN网络架构。
动机
给定一维信号x与模糊核k,模糊过程可以描述为:
上述过程为M阶IIR模型。将上述公式展开得到:
实际上,如果我们假设图像的边界为0,那么上述等价于对于y执行逆滤波器操作。如下图所示,很明显:逆滤波器的非0区域明显大于模糊核的非0区域。这意味着,在反卷积过程中,其应具有大感受野。



从M阶IIR模型出发,可以看到:采用IIR去模糊仅仅需要几个系数 。这意味着:只要找一个可以覆盖足够大感受野的操作,只需几个参数即可达到去模糊目的。此时的网络可以变得更小。

作者认为空间可变RNN模型可以满足上述需求。为使2D卷积具有更大的感受野,作者在连续RNN过程中插入了卷积层。以上图为例,卷积集成可以融合不同方向的滤波器信息,同时促使感受野包含更大的2D区域。空间可变RNN有如下两点优势:
- 以更少的参数获得更大的感受野;
- 其权值可以通过CNN学习得到,达到空间可变目的。
网络架构

上图给出该文所提空间可变RNN架构示意图。该网络不同模块的参数配置如下所示:
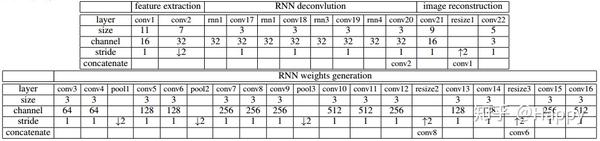
其中需要注意点的是:权值生成网络的conv3-conv11采用VGG16中前9层进行微调。为避免梯度消失并加速训练,在网络中引入了跳过连接,同时采用双线性插值取代反卷积(还可以避免反卷积产生的伪影问题)。
Experiments
在训练过程中,采用GoPro数据集,图像块大小为128,BatchSize=20,损失函数选择 ,权值初始化方法为Xavier,优化器选择Adam(0.9, 0.999),学习率为0.0001,权重衰减因子为0.000001,训练框架为Caffe,共计训练200000迭代次数。
下图给出了所提方法与其他SOTA方法的性能对比与视觉效果对比。其他更多实验结果请参考原文,这里不再赘述分析。(注:表中数据与其他论文中的数据存在差异,如Nah指标明显小于其他论文中提到的29.23/0.9162,不知何故)


Conclusion
作者提出一种新颖的端到端的空间可变RNN方法用于动态场景去模糊。作者分析了空间可变RNN与反卷积过程之间的相关性,并说明空间可变RNN可以模拟去模糊过程。相比已有CNN去模糊方法,所提RNN方法具有更小的模型更快的速度。同时作者还通过实验进行了定量与定性分析,从速度、精度以及模型大小方面,所提方法均取得了SOTA性能。
参考代码
结合作者所提供的Caffe代码,这里给出GateRecurrent模块的Pytorch实现,感兴趣者可以自行实现,这里不再进行过多罗列。后期有时间会尝试将其Caffe预训练模型转为Pytorch模式。
# according to caffe/src/layers/gaterecurrent_layer.cpp
def gaternn(inputs, weight, hor=True, reverse=False):
# according to restrict_w
weight.clamp_(-0.5, 0.5)
# reorder with hor and reverse
N, C, H, W = inputs.size()
if hor:
# N, C, H, W --> W, N, H, C
inputs = inputs.permute(3, 0, 2, 1)
weight = weight.permute(3, 0, 2, 1)
else:
# N, C, H, W --> H, N, W, C
inputs = inputs.permute(2, 0, 3, 1)
weight = weight.permute(2, 0, 3, 1)
if reverse:
inputs = torch.flip(inputs, [0])
weight = torch.flip(weight, [0])
# core.
output = torch.zeros_like(inputs)
output[0] = inputs[0] * (1 - weight[0])
for i in range(1, C):
output[i] = (1-weight[i])*inputs[i]+weight[i]*output[i-1]
# disorder with hor and reverse
if reverse:
output = torch.flip(output, [0])
if hor:
# W, N, H, C -> N, C, H, W
output = output.permute(1, 3, 2, 0)
else:
# H, N, W, C -> N, C, H, W
output = output.permute(1, 3, 0, 2)
return output
inputs = torch.randn(4, 32, 64, 64)
weight = torch.randn(4, 32, 64, 64)
output = gaternn(inputs, weight)
print(output.size())
推荐阅读:
本文章著作权归作者所有,任何形式的转载都请注明出处。更多动态滤波,图像质量,超分辨相关请关注我的专栏深度学习从入门到精通。
| 文件名 | 大小 | 下载次数 | 操作 |
|---|---|---|---|
| Dynamic Scene Deblurring Using Spatially Variant Recurrent Neural Networks.pdf | 6.37MB | 1 | 下载 |

