
华为诺亚方舟实验室联合北京大学和悉尼大学发布论文《Positive-Unlabeled Compression on the Cloud》,提出了基于少量数据的云端网络压缩技术,ResNet-18网络在CIFAR-10和ImageNet上分别达到了93.75%和86.00%的准确率(分别使用2%和10%的原始数据集),该论文已被NeurIPS2019接收。
论文地址:
https://papers.nips.cc/paper/8525-positive-unlabeled-compression-on-the-cloud.pdfpapers.nips.cc
开源地址:
https://github.com/huawei-noah/Data-Efficient-Model-Compressiongithub.com
研究背景
深度卷积神经网络(CNN)被广泛应用于诸多计算机视觉领域的实际任务中(例如,图片分类、物体检测、语义分割等)。然而,为了保证性能,神经网络通常是过参数化的,因此会存在大量的冗余参数、为了将神经网络直接应用于小型化移动设备例如手机、相机、摄像头等,通常需要使用神经网络压缩算法对过度参数化的原始神经网络进行压缩和加速。
传统的神经网络压缩算法通常需要完整的原始训练集来得到性能优异的压缩网络,然而在提供云端模型压缩服务时,上传这些原始训练集通常是非常耗时的。例如,用户上传一个95MB大小的ResNet-50神经网络只需要几秒钟至几分钟,但上传120GB完整的原始训练集ImageNet则需要数个小时甚至数天,从而极大的伤害用户体验。
为了解决这个问题,我们提出了一种新的基于少量数据的云端网络压缩技术,如图1。具体的我们利用用户上传的少量数据以及云上存在的大量未标记数据,通过正类与未标记学习 (PU Learning)方法从未标记数据中挑选出和用户上传的数据属于相同类别的数据,之后,使用改进的鲁棒知识蒸馏(Robust Knowledge Distillation)方法对网络进行压缩。
实验表明,我们的算法能够在使用非常少量的原始训练数据的情况下达到和使用全部数据集的压缩算法类似的准确率。
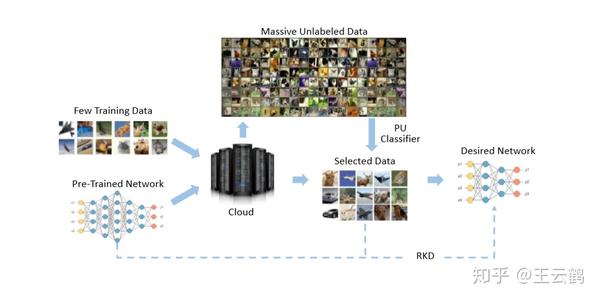
图1:本方法结构框架
使用PU分类器挑选数据
由于传输速度的限制,或基于隐私的原因,实际中我们通常只能够得到少量的训练数据,传统的神经网络压缩方法在这种情况下通常没有办法得到高性能的压缩网络。因此,本文提出了云端模型压缩方案,利用云端海量的无标签数据,使用PU分类器从中挑选出和用户上传的少量训练数据属于相同类别的数据,以便于神经网络的压缩。

事实上,由于用户数据与未标记数据的分布不同,直接使用用户上传的原始神经网络作为特征提取器并不能够达到好的效果。同时用户上传的原始神经网络是针对于传统的分类问题设计的,并不适用于PU数据的分类问题。因此我们构造了基于注意力机制的多尺度特征提取器,用于对输入数据提取特征。具体如图2所示:

图2:基于注意力机制的多尺度特征提取器
以ResNet-34为例,我们对网络的各个block提取的特征进行注意力机制变换,并学习其对应的权重向量,用于确定对于一个输入数据,应该更关注于网络哪个部分的特征。利用上述网络求取特征,并通过PU分类器进行优化,就能够完成对未标记数据的分类任务,从中挑选出和用户上传数据属于相同类别的数据。算法1是对上述方法的总结。

算法1: PU分类器选择数据
鲁棒的知识蒸馏算法
利用上个步骤得到的扩展数据集,本文使用了鲁棒的知识蒸馏方法对网络进行压缩。
注意到扩展数据集可能存在严重的类别不平衡问题,因为未标记数据集中可能存在大量的某一类别的用户数据,然而不存在或只存在很少量的另一类别的用户数据。除此之外,通过PU方法得到的扩展训练集存在噪声,因为上一步骤中从未标记数据集中挑选出的正类数据不可能达到完全准确的程度,因此我们对传统的知识蒸馏方法进行了改进。


算法2是对上述方法的总结。

算法2:鲁棒的知识蒸馏方法
实验结果
我们在CIFAR-10、ImageNet、MNIST三个数据集上分别进行了实验。
表1是在CIFAR-10数据集上的结果,我们使用了ResNet-34模拟用户上传的教师网络,ResNet-18为待压缩的学生网络。可以看到,在使用了2%的CIFAR-10训练数据集的情况下,本方法能够自动从未标记数据集中挑选出nt个数据,并使用鲁棒知识蒸馏方法对学生网络进行压缩,达到93.75%的性能,仅比使用全部数据进行知识蒸馏的压缩方法减少了0.65%的准确率。
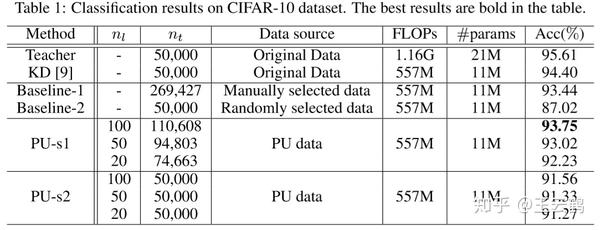
表1 CIFAR-10数据集实验结果
在ImageNet数据集上,在使用了10%的原始数据集的情况下,我们的方法达到了86.00%的top-5准确率,比使用完整训练集得到的压缩结果仅有少量下降,超过了从原始数据集中挑选50%的训练数据情况下的压缩结果。
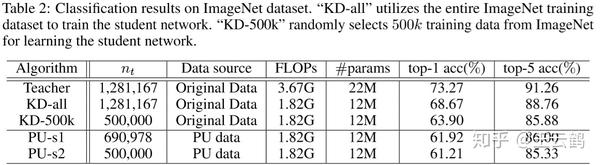
表2 ImageNet数据集实验结果
我们在MNIST数据集上进行了实验,并与其余使用少量数据的压缩方法进行了对比,可以看到我们的方法具有明显的优势。
表3 MNIST数据集实验结果

最后,我们对本方法关于类别先验的鲁棒性精心了分析,并对RKD方法进行了消融实验,证明了本方法的有效性,如图3。
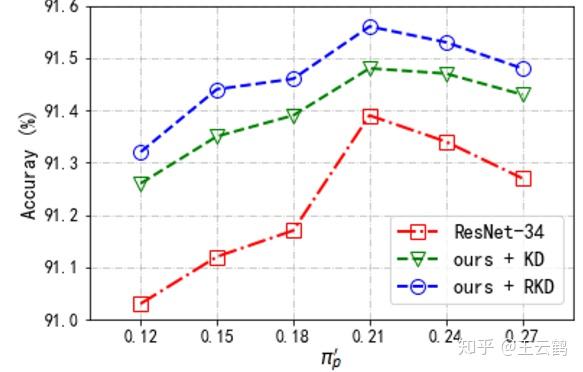
图3:使用不同类别先验在CIFAR-10上的准确率
推荐阅读
文章首发知乎,更多深度模型压缩相关的文章请关注深度学习压缩模型论文专栏。

