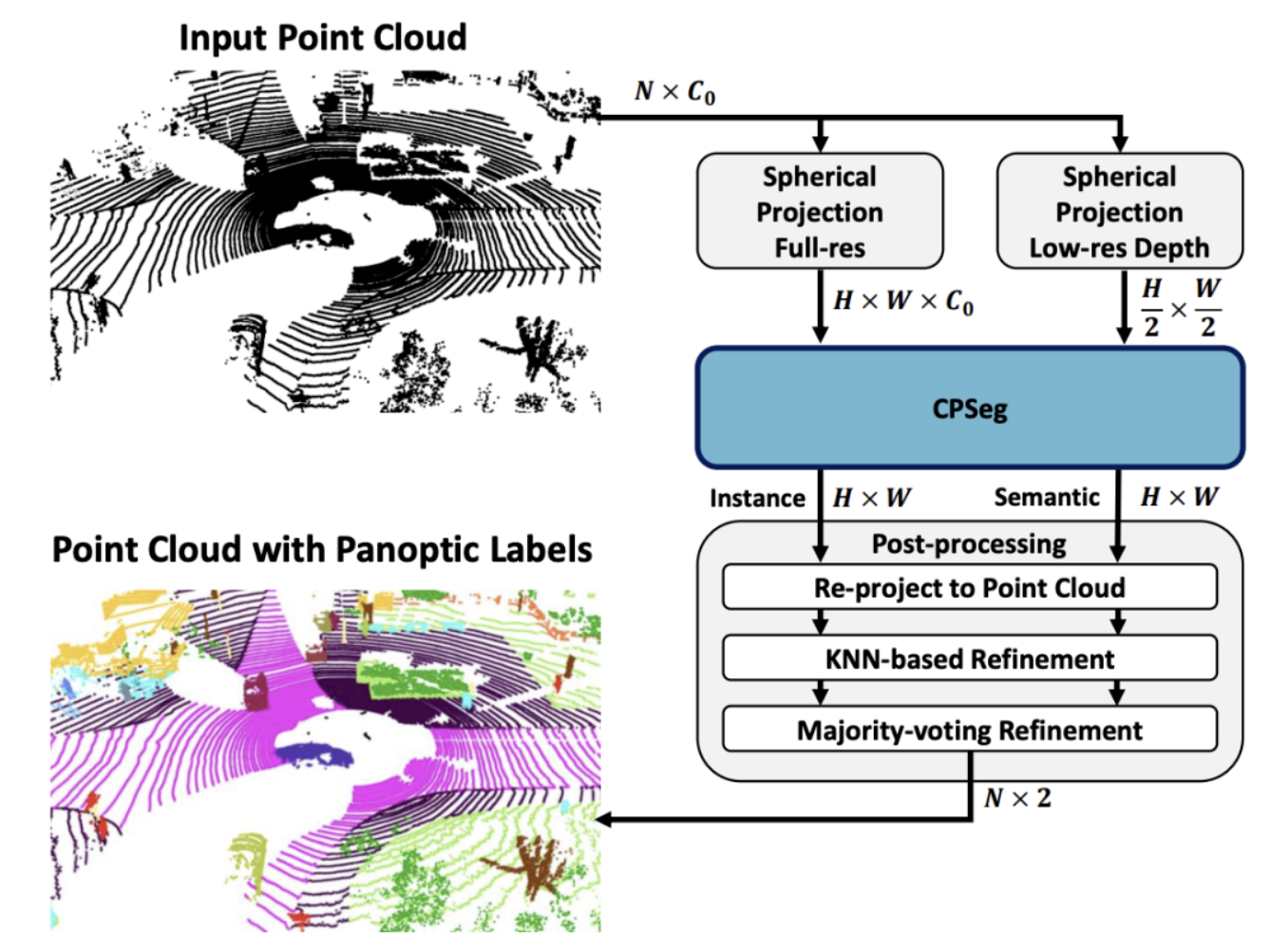
激光雷达作为自动驾驶车辆主要的感知传感器之一,其主动测距性、不受环境光照影响的特点,使得点云成为感知算法的核心“燃料”,有关点云的感知算法研究一直方兴未艾。其中,基于点云的语义分割和全景分割则吸引着广泛的研究兴趣。
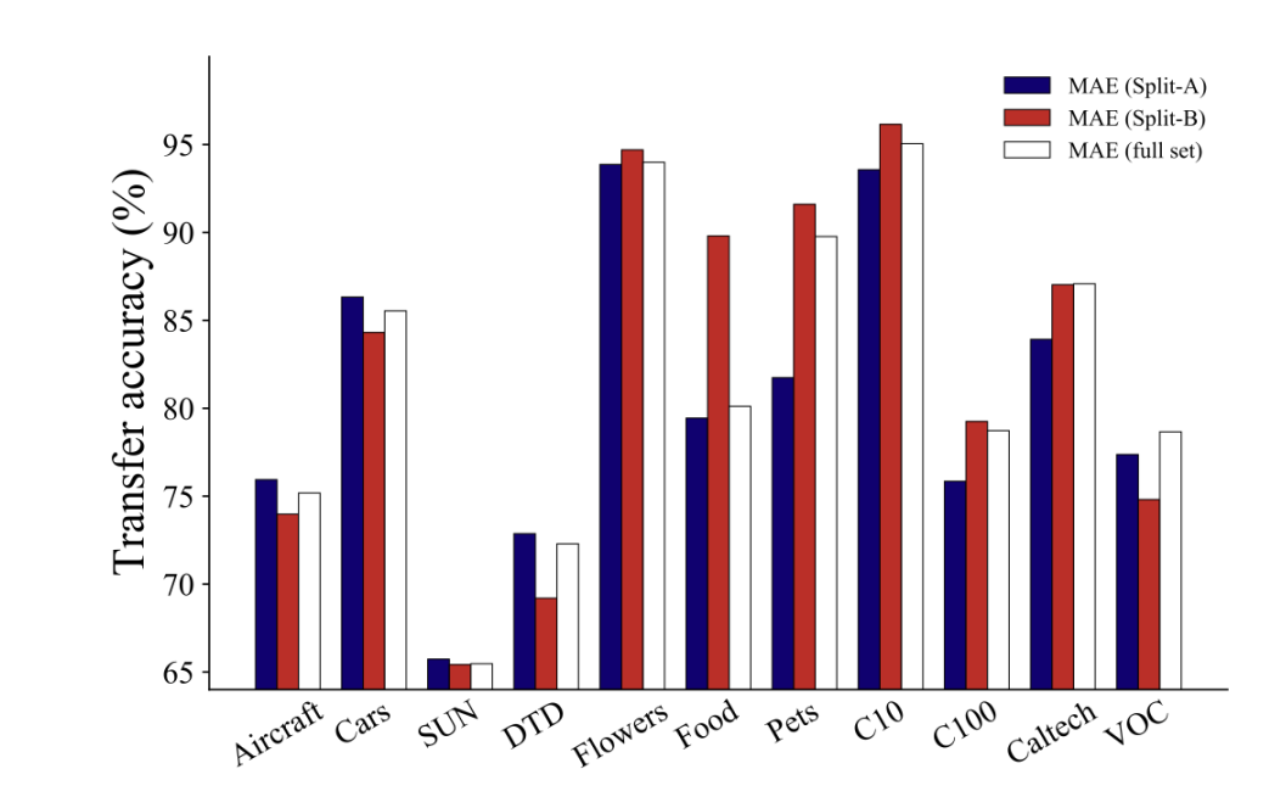
大型语言模型如ChatGPT的成功彰显了海量数据在捕捉语言模式和知识方面的巨大潜力,这也推动了基于大量数据的视觉模型研究。在计算视觉领域,标注数据通常难以获取,自监督学习成为预训练的主流方法。然而,在自监督预训练中,是否数据越多越好?数据增广是否始终有效?华为诺亚方舟实验室与香港科技大学的研究团队近期发现:
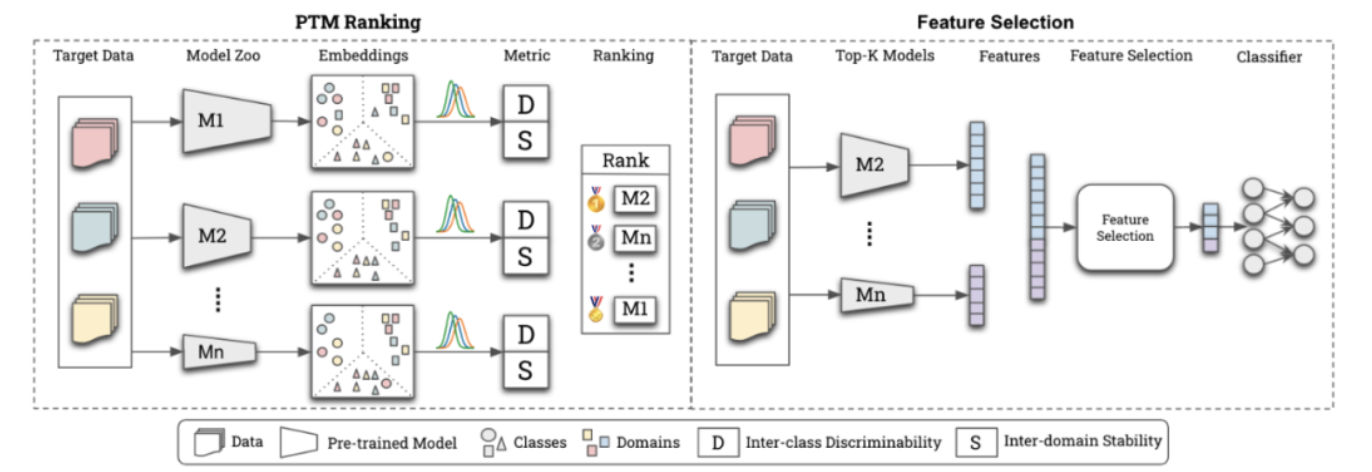
分布外泛化(OOD)问题在实际中无处不在,现有AI方法OOD能力欠缺是阻碍其大规模应用的一大瓶颈。当前,可以公开获取的预训练模型能力强,数量大,种类多,为解决OOD问题提供了新的可能性。华为诺亚方舟实验室AI基础理论团队近期提出了一种利用模型库技术(Model Zoo)解决OOD问题的框架ZooD,主要分为模型挑选和模型融合...
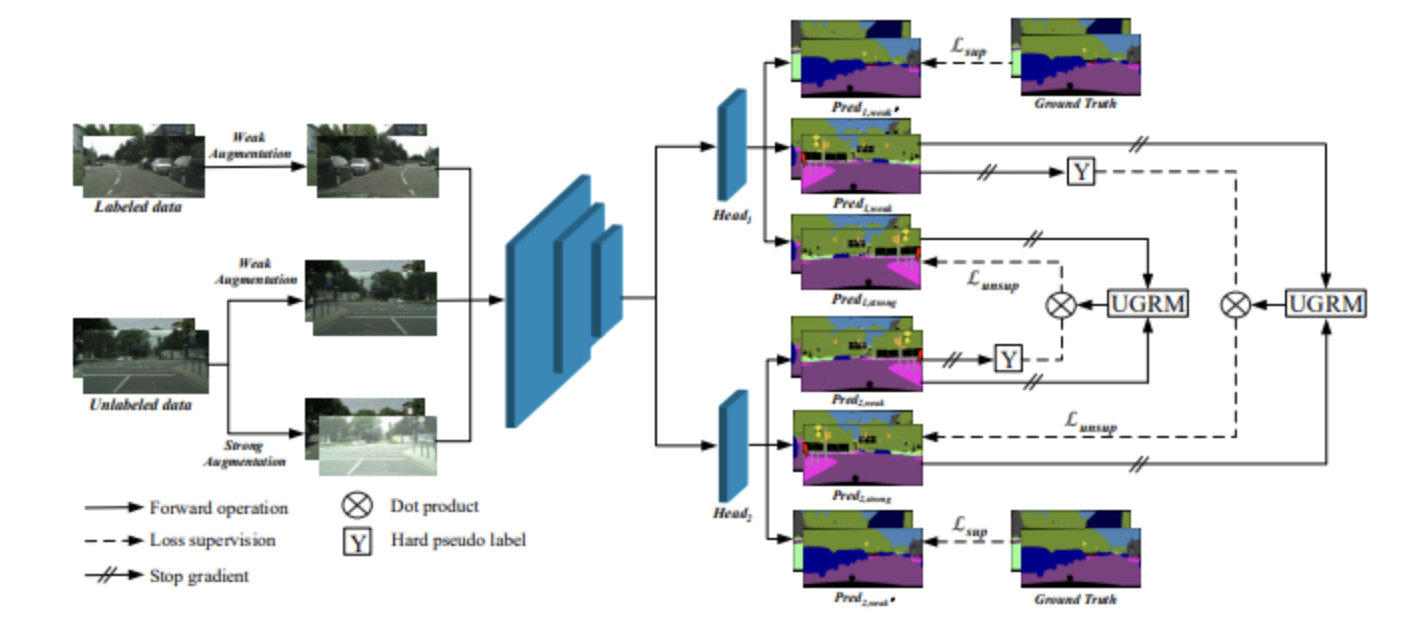
华为诺亚方舟实验室自动驾驶研究团队的最新自主研究成果《UCC: Uncertainty guided Cross-head Co-training for Semi-Supervised Semantic Segmentation》发表在计算机视觉领域的顶级会议CVPR 2022。本研究以深度神经网络为依托,面向半监督语义分割,针对现有文献对半监督语义分割中伪标签中噪声高、类别不平衡以及标注...
随着AR/VR、数字人等技术及应用的崛起,人体动作捕捉相关的研究越来越受到学术界和工业界的关注,尤其是基于单目视觉的方案,因其便携易用而引起更多的关注。近日,华为诺亚方舟实验室计算机视觉团队提出了新的动作捕捉算法CLIFF,基于HMR网络结构,在网络输入和监督信号中引入裁剪框的全局位置,同时使用新的方法构造人...

自OpenAI GPT-3、盘古α等超大规模预训练语言模型问世以来,大模型的强大语言表征能力在AI领域掀起了新一轮革命。在大模型不断刷新各类AI任务纪录的同时,如何将其高效部署到实际产品中逐渐成为核心课题。特别是在算力受限的终端应用中,往往无法直接部署性能卓越的大模型。这一问题在多语言大模型上尤为突出,因为其较单...

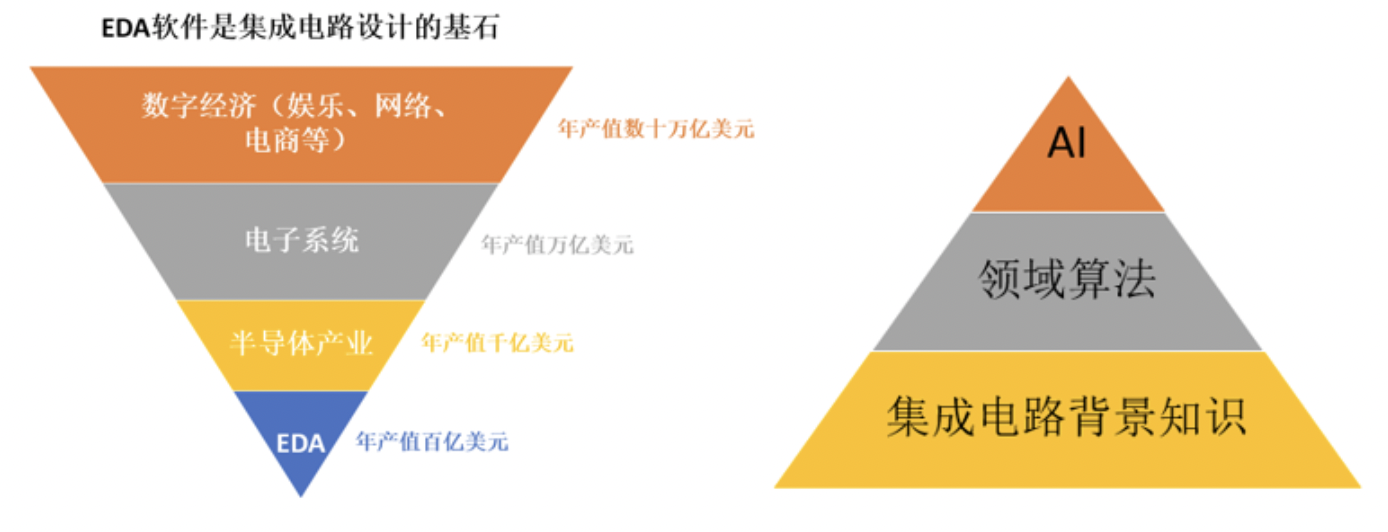
EDA(Electronic Design Automation)电子设计自动化软件作为集成电路设计的基石,是芯片设计的必需品。其百亿美元的市场支撑了年产值数十万亿的数字经济。随着AI技术的发展与渗透,当前各大EDA厂商都在积极布局AI技术,通过AI技术与领域技术结合,以实现更大规模参数优化和更精确芯片建模,攻克EDA设计难题。
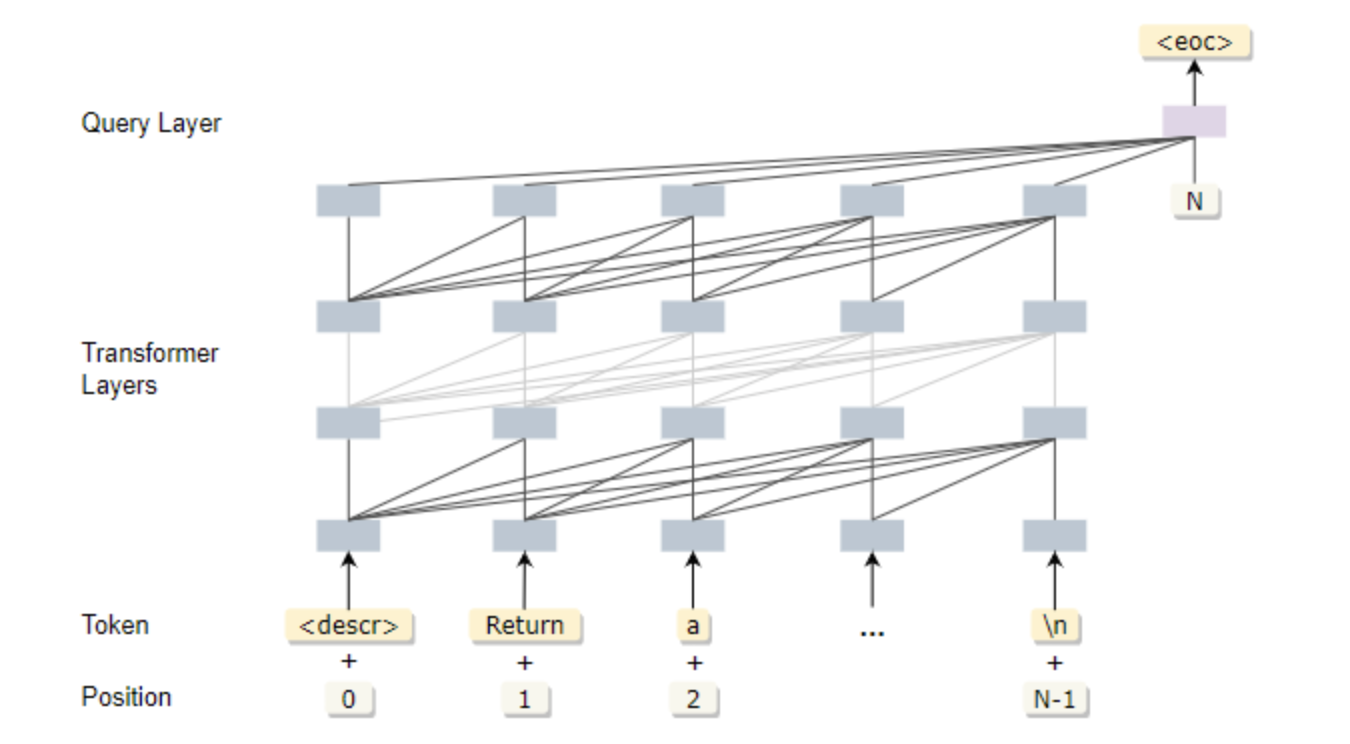
基于预训练的生成技术在自然语言处理中获得了极大的发展,包括OpenAI GPT-3、华为【盘古α】等在内的文本生成模型展示出惊人的创造力,其能力远超以往模型,并逐渐成为序列生成的一种基本范式,显示出巨大的商业潜力。基于这种范式,研究人员开始尝试将语言生成模型引入软件工程领域,并在代码生成与补全上取得突破进展,...
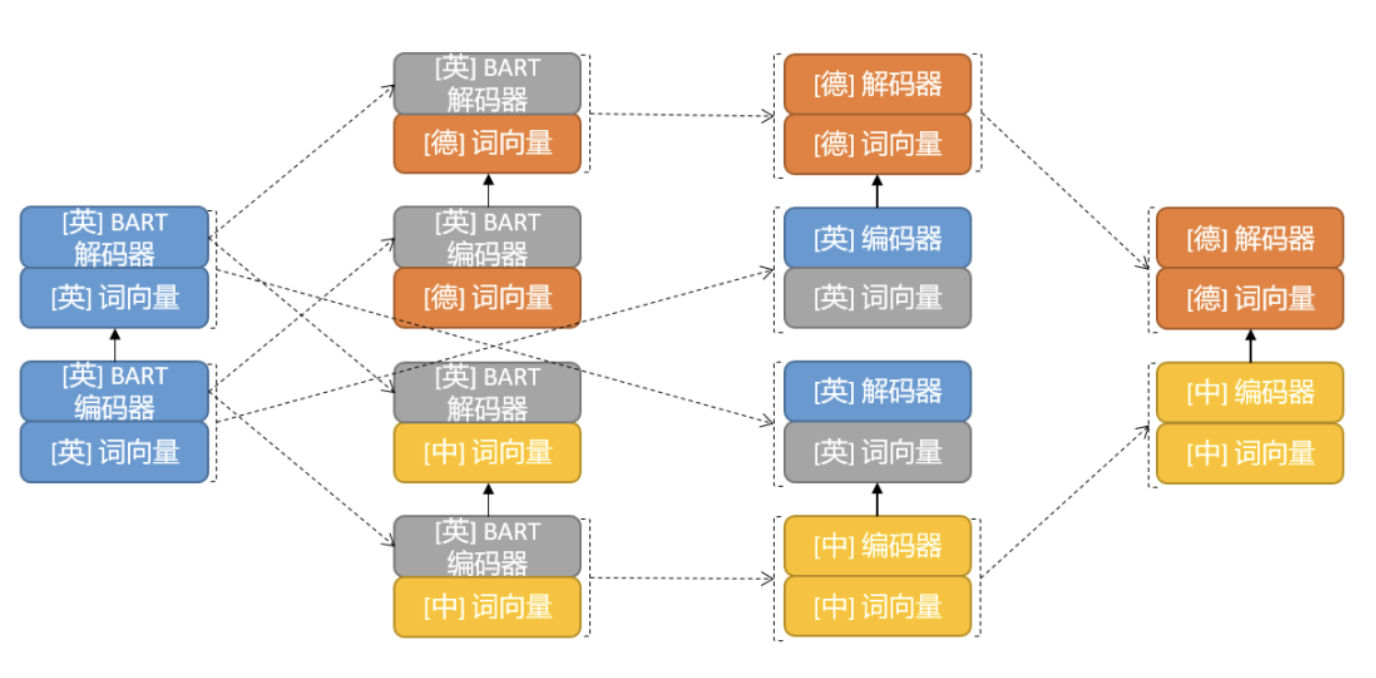
机器翻译的成功仰赖大规模的平行语料,而平行语料里英文的高比例造就了以英文为中心的机器翻译服务现状。其他语言之间的互译如何破局?三角翻译可能是一个答案。华为诺亚方舟实验室发表于ACL 2022的论文《Triangular Transfer: Freezing the Pivot for Triangular Machine Translation》提出了一种基于迁移学习的三角翻...
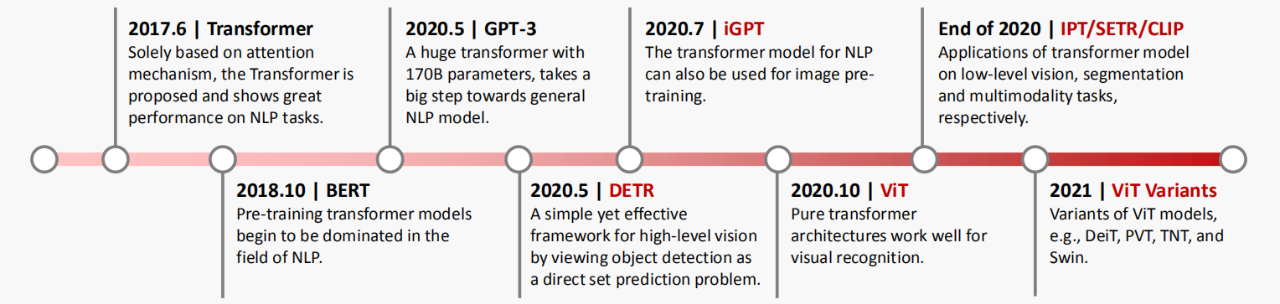
2021年对计算机视觉来说是非常重要的一年,各个任务的SOTA不断被刷新。这么多种Vision Transformer模型,到底该选哪一个?新手入坑该选哪个方向?华为诺亚方舟实验室的这一篇综述或许能给大家带来帮助。
多模态大模型如OpenAI的CLIP,谷歌的ALIGN等最近掀起了新一轮大规模多模态学习的浪潮,这些模型在各种下游任务体现了出色的开放域零样本能力,是下一代通用人工智能的可能之路。这些大模型的成功很大程度上依赖于预训练数据集的支持,但是中文开源数据规模大的基本没有,阻碍了中文多模态大模型的发展与应用。

近年来,强化学习在工业界和学术界受到广泛关注,在理论研究和实际应用方面均取得了瞩目的成就。然而强化学习目前尚存在诸多挑战问题亟待解决,包括数据利用率低,策略及知识迁移受限,多智能体强化学习信度分配等问题。在NeurIPS 2021中,诺亚方舟实验室强化学习方向共有7篇论文被接收。以上述挑战问题为起点,从有模型...
华为诺亚实验室的研究员们联合高校提出一系列用于高效视觉Transformer的网络架构和模型压缩算法,包含高效Transformer架构、视觉Transformer剪枝、量化以及知识蒸馏。相关技术已陆续发布,可以用于不同需求和场景,能给现有视觉Transformer带来模型精度、模型大小、计算复杂度等方面的增益。下面将一一介绍这些方面的系...
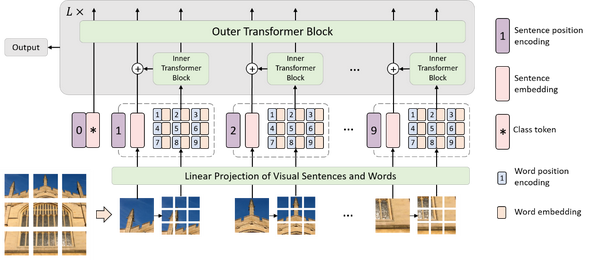
来自华为诺亚方舟实验室,北京大学以及悉尼大学的研究者们提出了一种底层视觉任务上的预训练Transformer模型IPT,相比于传统的卷积神经网络,IPT模型在超分辨率、去噪、去雨等多项任务上取得了SOTA表现,并取得了大幅提升。

一年一度的计算机视觉顶会IEEE计算机视觉及模式识别大会CVPR录用结果最近公布。据悉,今年CVPR投稿量与论文接收量相对往年继续上升,有效投搞量达7015篇,接收论文1663篇,接收率23.7%,与往年相比略有上升。

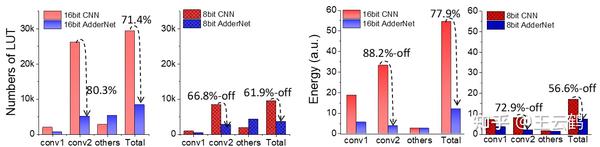
华为诺亚研究员联合中科院深圳先进院、悉尼大学提出加法网络极简硬件架构,相比乘法网络,加法网络硬件电路面积节省67.6%-71.4%,功耗降低47.85%-77.9%。论文提出了一个新型的加法网络量化方法,8bit/16bit量化无损。同时,针对加法网络的特性,设计了一种极简硬件架构,能够大幅降低电路面积和功耗,性能远超乘法网络、...
来自华为诺亚方舟实验室、北京邮电大学以及香港科技大学的研究者们提出了一个新的轻量模型范式TinyNet。相比于EfficientNet的复合放缩范式(compound scaling),通过TinyNet范式得到的模型在ImageNet上的精度要优于相似计算量(FLOPs)的EfficientNet模型。例如, TinyNet-A的Top1准确率为76.8% ,约为339M FLOPs,而Ef...
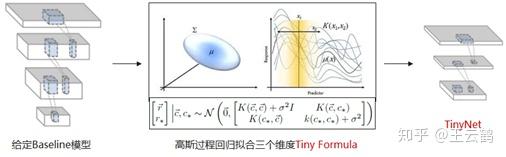
华为诺亚方舟实验室联合悉尼大学发布论文《Kernel Based Progressive Distillation for Adder Neural Networks》,提出了针对加法神经网络的蒸馏技术,ResNet-34和ResNet-50网络在ImageNet上分别达到了68.8%和76.8%的准确率,效果与相同结构的CNN相比持平或超越,该论文已被NeurIPS2020接收。

内容来自各类真实的面试经历,整理清晰\~\~希望通过这些问题,能够让大家学习更有方向,而不是单纯把这些问题都背会了!另外,内容会继续完善,欢迎你在评论区说出你遇到的高频面试题!来源:[链接]
61、给出某个一般时序电路的图,有Tsetup,Tdelay,Tck->q(Tco),还有 clock的delay,写出决定最大时钟的因素,同时给出表达式。T+Tclkdealy>Tsetup+Tco+Tdelay;Thold>Tclkdelay+Tco+Tdelay; 保持时间与时钟周期无关