
之前写了关于海思NNIE的一些量化部署工作,笔者不才,文章没有写得很具体,有些内容并没有完全写在里面。好在目前看到了一些使用nniefacelib脱坑的朋友,觉得这个工程还是有些用的。为了完善这个工程,最近也增加一些一站式的解决方案。开始正题吧!
作者:Hanson
首发知乎
代码:hanson-young/nniefacelibgithub.com
一、训练
PFLD是一个精度高、速度快、模型小三位一体的人脸关键点检测算法。github上也有对其进行的复现工作,而这次要介绍的就是
PFPLD (A Practical Facial Pose and Landmark Detector),对PFLD的微改版本,笔者对其进行了一些微小的改变,名字中间多了个”屁“。其实是对pose branch进行了加强,同时让其关键点对遮挡、模糊、光照等复杂情况更加鲁棒。
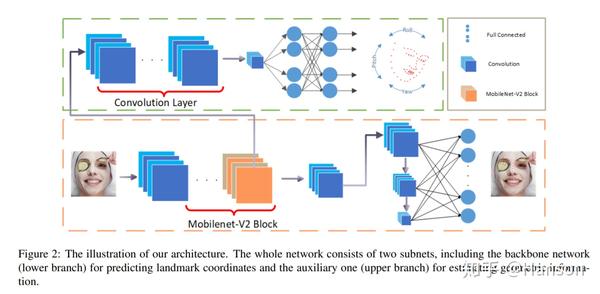
PFLD网络结构
黄色虚线囊括的是主分支网络,用于预测关键点的位置;绿色虚线囊括的是head pose辅助网络。在训练时预测人脸姿态,从而修改loss函数,使更加关注那些稀有的,还有姿态角度过大的样本,从而提高预测的精度。同等规模的网络,只要精度上去,必然是可以想到很多办法来降低计算量的。
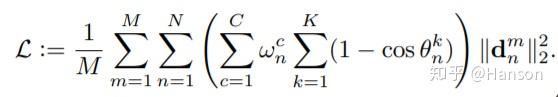
PFLD loss
直观感受,这个loss的设计模式本质上是一种对抗数据不均衡的表达,和focal loss思想是一致的。但这类思想并不是对于每种工作都能work,笔者曾经回答过类似的问题。有哪些「魔改」loss函数,曾经拯救了你的深度学习模型
接下来将介绍一些笔者对其微改的地方:
- 用PRNet标注人脸图像的姿态数据,比原始通过solvePNP得到的效果要好很多,这也直接增强了模型对pose的支持。PRNet是一个非常优秀的3D人脸方面的项目。论文也写的很精彩,强烈推荐去看。目前在活体检测领域用其渲染的depth map作为伪标签进行训练,已经成为了一种标配性的存在。所以当人脸姿态估计算法性能接近于它,证明训练的姿态已经非常不错了。如果想要得到更好的表现,用更加特殊的方法采集人脸姿态数据进行炼丹也是行得通的(吐槽:大部分开源姿态数据标注规范并不统一)。
- 在整个实验中pfld loss收敛速度比较慢,慢也是有原因的,过于重点关注少量复杂的样本,会使得对整体的grad调节不明显,因此对多种loss(mse, pfld, smoothl1 and wing)进行了对比,结果得出,wing loss的效果更加明显,收敛速度也比较快。
- 改进了pfld网络结构,让关键点和姿态角度都能回归的比较好,将landmarks branch合并到pose branch中。由于两个任务相关性较强, 这样做可以让其更加充分的影响。对于这种多任务之间正向促进的例子,通过对网络结构以及辅助监督信号的改进,可以使其结果并不会太过于依赖loss函数的设计。这并不是笔者在的主观判断,感兴趣,可以参考我之前的深度学习的多个loss如何平衡的一个回答,如有不同之处,欢迎一起讨论相关话题。
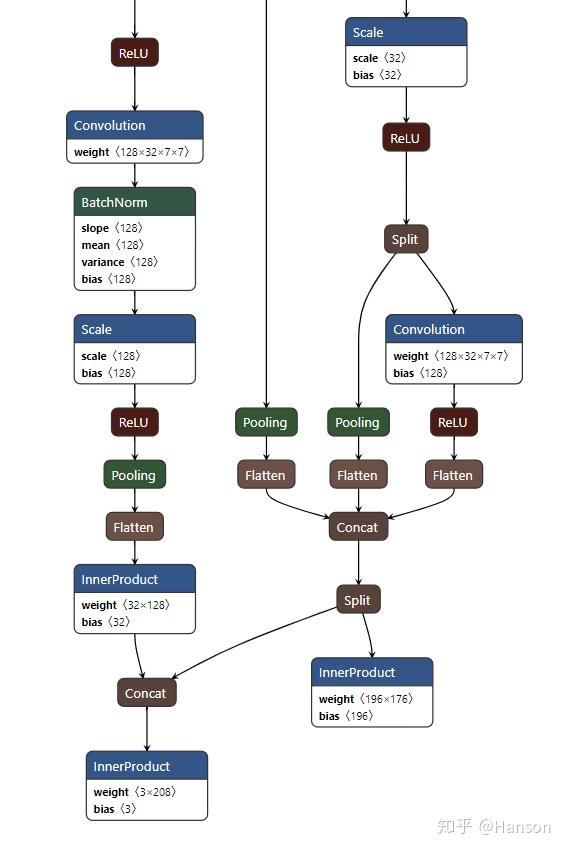
PFPLD部分网络结构
疫情当下,口罩遮挡,玄学优化,美图共赏
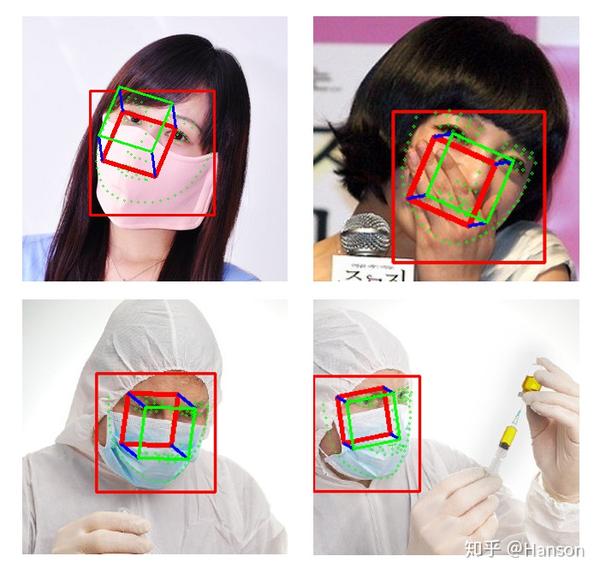
二、量化
过去一周,笔者对训练代码进行了整理,完成了多种版本的转换工作,包括
- pytorch
- caffe
- ncnn
- nnie
听说有小伙伴将这套模型跑到了ios上,说不定之后会放出来。
扯了一大堆,那开始介绍下本文最核心的NNIE。有首先我们要选择一个比较优秀的训练框架,比如,我们选择了pytorch。然后要将模型转换为caffe,那我们选择了onnx作为过度环节
python convert_to_onnx.py
python3 -m onnxsim ./models/onnx/checkpoint_epoch_final.onnx ./models/onnx/pfpld.onnx
cd cvtcaffe
python convertCaffe.py可以看得出来,经过了很少的步骤,一个被图优化过的caffe模型就出来了,包括merge bn,inplace等优化,"工具人"onnx在其中起到了很重要的作用。
之前也提到过batchnorm会对精度造成一些不知所以的影响,所以
无论我们遇到什么困难,都不要怕,微笑着面对它,消除恐惧的最好办法就是避开恐惧,避开,才会胜利,加油,奥利给!
另外,笔者自己训练模型的时候是不会考虑减均值这种操作的,只会做data\_scale处理,为什么这么做,因为放弃思考真得很香。记性不好,不想遇到问题的时候去查,也不太相信减均值能带来明显收益!
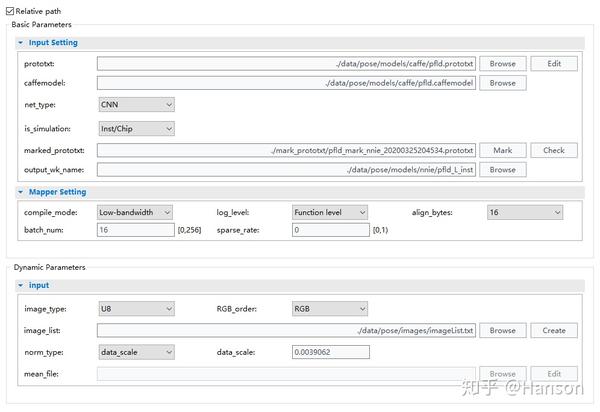
果断地只用data\_scale模式
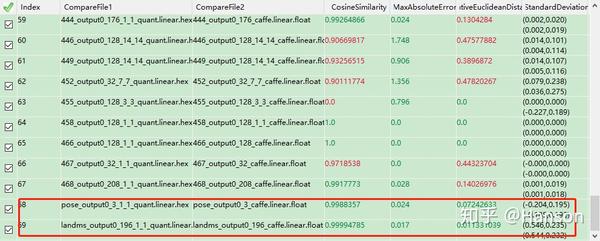
量化精度
海思NNIE模型量化部署系列:
更多模型芯片端部署,请关注嵌入式AI专栏

