
本系列我想深入探寻 AXI4 总线。不过事情总是这样,不能我说想深入就深入。当前我对 AXI总线的理解尚谈不上深入。但我希望通过一系列文章,让读者能和我一起深入探寻 AXI4。
光说不练,云玩家。这篇文章中我们就通过访问一个 AXI4 接口的 RAM 的实际操作,加深我们对 AXI4 总线的理解。
我们的实验平台是 ISE 14.7 以及 modelsim 10.2, RAM 的 ip 使用 ISE 的 block memory generator 生成,Intel 方面的工具和 ip 我不是太熟悉,但想必很多内容都是共通的。
Native V.S AXI4 ?
首先使用 ip 核生成器生成一个 AXI4 的 ip 核,我们先比较一下 Native 接口和 AXI4 接口的 RAM。
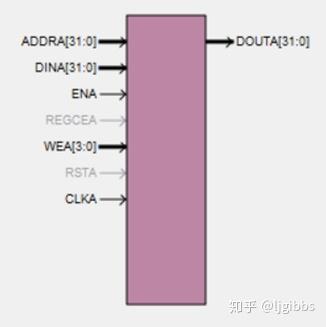
一号选手:Native
首先登场的是一号选手:Natiiiive,他有着小小的身板,地址,输入数据,输出数据,使能,时钟接口错落有致,简洁分明。小快灵是他的信仰,好用好上手是他的宣言。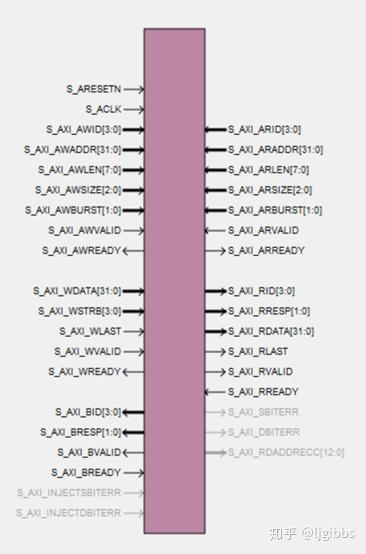
二号选手:AXI4
接下来登场的是 AXIFour,他的身板恐怕是 Native 的三倍,更大的身板,更大的力量是他的座右铭。“通用性”,“标准总线”是他挂在嘴上的口头禅
Ok,Stop,两者之间其实并不是一个竞争关系,没有孰胜孰劣的比较。Native 接口数据线更少,但不够通用,自然也没有总线的概念;AXI4 支持标准化的,通用总线访问,可以将多个 RAM 挂载到一条总线上,通过 ID 区分不同的 RAM,但接口要确实复杂地多。
AXI 总线读写 RAM 实战
首先构建 AXI4 接口的 RAM ip核,在工程中添加 ip 核文件
选择 AXI 协议,另外关于 AXI-Lite 协议将会在以后的文章中介绍。AXI-Lite 协议简化了 AXI 协议,但不支持突发传输操作。
在 Slave Option 中选择 Memory Slave,因为 RAM 作为一个存储介质,不能主动发起操作,在 AXI 传输中只能作为从机。作为从机有两种选项,Memory Slave 作为存储介质,使用完整的 AXI 总线;Peripheral Slave 不是很熟悉,在该模式下不支持突发传输。
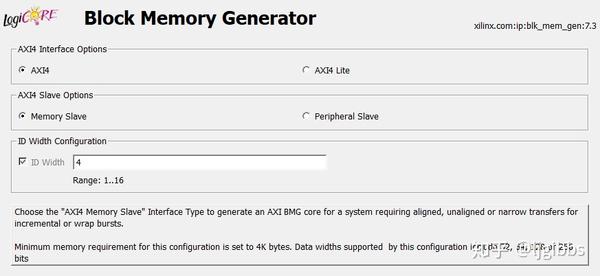
在 Memory Type 中,如果使用 AXI 总线,则只能选择单口RAM。而 Native 接口是支持多种模式的,包括 ROM,双口 RAM 等。

Native 接口下可以选择多种模式
之后选择适合的数据总线宽度和 RAM 深度即可以生成 RAM 。
在工程中为新生成的 ip 核添加 testbench。
首先是非突发传输(突发传输长度为 1 的突发传输。。)写入与读取操作,即写入地址,写入一次数据。读取操作时,也先写入数据,然后读取。下图中为了说明一些细节,进行了两次同样的流程。
Testbench 的时序部分
initial begin
// Initialize Inputs
//....初值均赋为0 除 bready 外
s_axi_bready = 1;
// Wait 100 ns for global reset to finish
#100;
// Add stimulus here
s_aresetn = 1;
repeat(2) begin
#100;
//aw channel
s_axi_awaddr = 32'b100;
s_axi_awlen = 0;
s_axi_awsize = 3'b010;
s_axi_awburst = 0;
#20;
s_axi_awvalid = 1;
#20;
//wait(s_axi_awready == 1 && s_aclk == 1);
s_axi_awvalid = 0;
#100;
//w channel
s_axi_wdata = 32'h01020304;
s_axi_wstrb = 4'b1111;
s_axi_wlast = 1;
s_axi_wvalid = 1;
#20;
s_axi_wlast = 0;
s_axi_wvalid = 0;
s_axi_wstrb = 4'b0;
#100;
//ar channel
s_axi_araddr = 32'b100;
s_axi_arlen = 0;
s_axi_arsize = 3'b010;
s_axi_arburst = 0;
#20;
s_axi_arvalid = 1;
#20;
//wait(s_axi_arready == 1 && s_aclk == 1);
s_axi_arvalid = 0;
#100;
//r channel
s_axi_rready = 1;
end
end
always #10 s_aclk = ~s_aclk;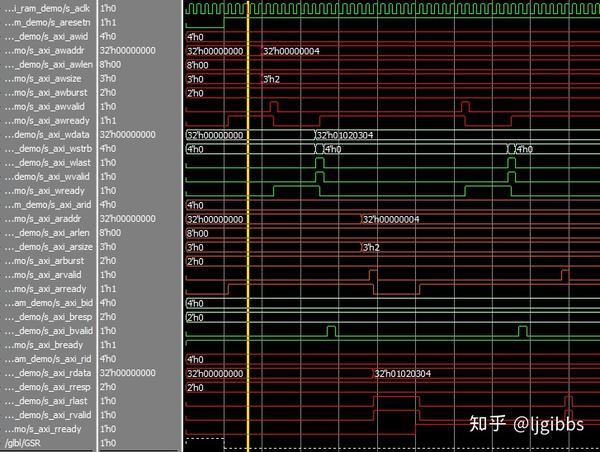
我们关注一些细节,有关 RAM IP 核的一些特性,比如当完成一次写入时,RAM 的 AXREADY 信号会拉低约 6 个时钟之后,才会拉高允许下一次地址写入发生;而 XREADY 信号则会保持低电平直到下一次地址地址写入之后,才会拉高准备接收数据。
通过实践发现了 AXI4 在读取时的一个特性,如果在读取时,将突发传输长度设为 2,突发传输宽度设为 16 位,数据总线宽度为 32 位,即通过两次 16 位传输读取写入的 32 位数据 0x01020304。实践后发现,实际上会读取两次 0x01020304,需要主机自行整理数据,因为主机实际上知道,自己读取的数据宽度是 16 位,数据总线宽度为 32 位。
读者可以通过仿真结果看到本系列之前的文章中提到,握手机制,AXI 各信号线的含义以及突发传输机制等。
接下来尝试突发传输操作
Testbench 部分
// Wait 100 ns for global reset to finish
#100;
// Add stimulus here
s_aresetn = 1;
repeat(2) begin
#100;
//aw channel
s_axi_awaddr = 32'b100;
s_axi_awlen = 8'd3;
s_axi_awsize = 3'b010;
s_axi_awburst = 2'b01;
#20;
s_axi_awvalid = 1;
#20;
//wait(s_axi_awready == 1 && s_aclk == 1);
s_axi_awvalid = 0;
#100;
//w channel
s_axi_wdata = 32'h01020304;
s_axi_wstrb = 4'b1111;
repeat (3) begin
s_axi_wdata = s_axi_wdata + 1'b1;
s_axi_wvalid = 1;
#20;
s_axi_wvalid = 0;
#20;
end
s_axi_wdata = s_axi_wdata + 1'b1;
s_axi_wvalid = 1;
s_axi_wlast = 1;
#20
s_axi_wlast = 0;
s_axi_wvalid = 0;
#100;
//ar channel
s_axi_araddr = 32'b100;
s_axi_arlen = 8'd7;
s_axi_arsize = 3'b001;
s_axi_arburst = 2'b01;
#20;
s_axi_arvalid = 1;
#20;
//wait(s_axi_arready == 1 && s_aclk == 1);
s_axi_arvalid = 0;
#100;
//r channel
s_axi_rready = 1;
end
end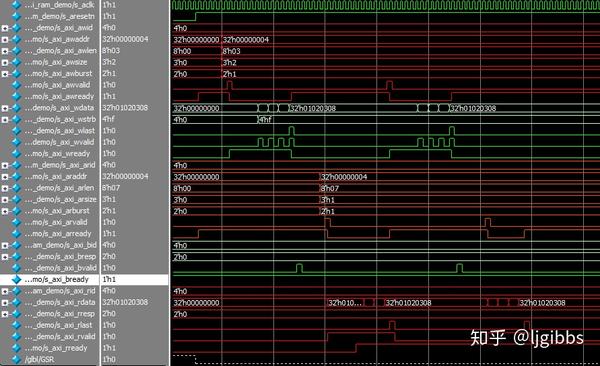
突发传输类型为 INCR,写入时,突发传输长度为 4,宽度为 32 位;读取时长度为 8,宽度为 16 位,仿真的结果和预期一致。
结语
光说不练假把式,本文结合本系列之前的文章,进行一次 AXI4 总线访问 RAM 的实战。之前我也只使用过 datamover ip 来访问 AXI4 总线,这也是我第一次直接操作 AXI4 总线。本文中的例子是一个基础的举例,之后还会进行更多的仿真,比如进行多 RAM 挂载在一条总线上的操作。
更多AMBA协议相关文章请关注极术专栏Arm AMBA 协议集
| 文件名 | 大小 | 下载次数 | 操作 |
|---|---|---|---|
| hello_axi.pdf | 2.15MB | 128 | 下载 |
| IHI0022E_amba_axi_and_ace_protocol_spec.pdf | 1.92MB | 495 | 下载 |

