
来自清华大学微电子所的清微智能近期推出了可重构芯片Thinker。这是一款面向语音和图像识别领域的低功耗AI加速器。本文通过thinker团队2018年在JSCC上发表的论文,深入分析其硬件设计特点和优化方案,讨论低功耗目标下硬件可重构设计的思路。当然论文的实现和商用芯片可能有些许出入,不过相信主要部份应该是可以参考的。
Summary:Thinker的算力核心(PE array)是systolic运算形式的CGRA(Coarse Grained Reconfigurable Array)结构。通过对PE array功能的指令级动态配置,实现PE array不同部分执行不同运算的异构并行计算能力。同时通过特殊的数据重排模块,以较小的带宽实现了对各可重构部分数据的供给。设计中有很多细节部分值得仔细研究,其选择的方法也很有启发性。
作者:MikesICroom
原文:https://zhuanlan.zhihu.com/p/75204118
Thinker是一款基于CGRA(Coarse Grained Reconfigurable Array)结构的加速器。传统的AI加速器通常面向DL算法的核心部分,主要是卷积和矩阵乘累加,而对其他的如pooling,normalization,softmax等运算,要么依赖CPU端进行运算,要么提供专门的硬件模块,前者性能不高,后者面积较大。Thinker的解决方案是通过对PE阵列的动态配置,以相同的硬件支持全部DL的功能。这样可以获得更好的PPA(performance,power and area),对于端上设备来说很有价值。
Thinker GTIC 2018
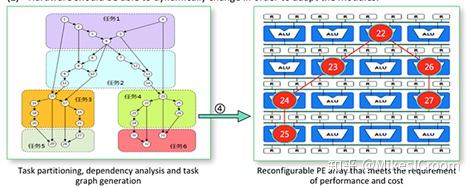
简单介绍下CGRA的结构。不同于FPGA,这是一种更高层次的可重构技术,通过指令对可编程的执行阵列进行配置,是指令级别的配置速度。整个阵列由多个执行单元(PE)构成,通过配置每个PE的连接性和运算模式来定义整个阵列的功能。这种配置主要来源于特定算法的映射,因此也被称为“软件定义硬件”。CGRA的硬件设计是相对简单的,主要的难点是如何高效的进行阵列配置,将软件模型映射在硬件上。不仅仅是功能的映射,还包括数据流的控制,相关性的处理等。这和传统的软件编程思路有很大不同,如上图[1]。Wave computing的DPU也采用 了CGRA的结构。比较而言,DPU的阵列更通用化,因此灵活性更高,但代价是编程复杂。而thinker更specific些,主要针对DL几种算法提供可配置性,这样通用性差些,但软件难度要低不少,且可以做有针对性的优化。因此在商用的进程上,thinker已经有量产的进度表,DPU起步虽然早不少,但似乎现在离商用还有一段距离。这样也体现了中美创业思路上的不同。美国那边喜欢搞一个很高大上的概念来吸引投资,直接面向最新的领域和技术,但真正能走到落地的很少。而国内则更实际,主要以更快的商业化进程为目标。对于目前国内IC业处于一个跟随者的现状来看,thinker的思路很符合当下的国情。
针对传统加速器对hybrid-NNs中非核心运算的效率不高的问题,论文描述了一种粗粒度可重构的概念,在保持卷积核矩阵乘累加的性能的基础上,通过硬件复用和重新配置,高效支持hybrid-NNs的其他运算部分。
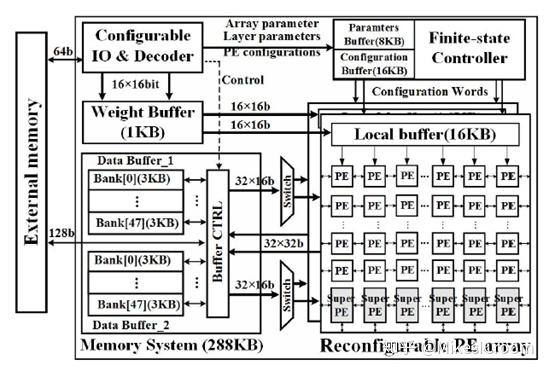
先看下整体框架。首先,这是一个协处理器的结构,需要外部的CPU通过config interface进行配置和触发。运算核心是2个16x16的MAC矩阵(PE array)。数据预先存储在左边的data buffer中,共48个bank,通过buffer control模块reorganize后,自左向右的逐拍进入PE array。权重也是预先存储在右上的weight buffer中,通过PE array上部的local buffer reorganize后自上而下进入。可以看出,Thinker的基本执行方式是类似于TPU的“systolic”执行,这样可以以较小的数据带宽,保证卷积和乘累加的运算性能。PE array的可重构是通过右上方的controller模块,将配置指令和相关数据发送到矩阵中。注意PE 有两种格式:PE和Super PE,前者占绝对多数,具体的功能如下图。
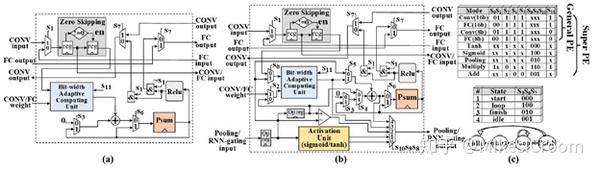
这里抛开细节不谈,简而言之,区别是Super PE支持了更多的功能,包括pooling,tanh,sigmoid,scalar multiplication and addition,and RNN-gating operation。这种思路是基于DL运算的核心是MAC,因此主要的算力模块也仅面向MAC运算,而预留少量PE支持其他的非核心操作。这是硬件设计的基本原则之一:Amdahl’s Law,对影响性能的主要部分做加速。其实这里跟之前的假设有点冲突,前面论文提到传统加速器的问题就是对DL的非MAC运算加速效果不好。看到这里,thinker其实也是主要在MAC部分做加速,而其他部分采用专门硬件特殊处理,并没有独到的方法。从设计角度,较低算力的非MAC运算的加速本来就是性价比低的部分,只要能通过提供硬件并行性,将非MAC运算的时间隐藏在MAC矩阵运算的时间之内,就能完美的解决上述问题。可以看出,thinker的论据虽然不正确,但是解决方案是合理的。
PE还有一些值得关注的细节。首先,PE可以通过配置,支持一个16x16的MAC,或者2个2x16的MAC。这是乘法器常用的复用方法:通过对乘法器前端的压缩器进行数据分隔,以及后端累加上做特殊处理,可以基本不增加硬件面积。其次是Zero masking模块,用来在输入数据为0的情况下做clock gating以节省power。Systolic 运算的特点是数据单向单步流动,因此在处理稀疏矩阵运算时,并没有办法像CPU这类控制流处理器,可以通过判断和分支,提前将含0运算剥离出去以减少运算量。换句话讲,systolic在相同尺寸的dense matrix和sparse matrix的运算时间是一样的,这是个比较大的劣势。Thinker对此没有提供解决方案,而是主要在功耗方面做了优化。我认为在这一点上,TPU也没有做的更好。一些加速器针对sparse matrix做了特殊的加速,比如DeepPhi和Cambricon。由于其运算的基本结构是2维向量MAC,因此在数据输入端增加了特殊的zero detection逻辑,将0值对应的数据过滤掉,这样就只用计算非0部分的MAC,因而对sparse matrix的运算效率会高于dense matrix。比如Cambricon在sparse开启时的算力是不开时的4倍(75% sparsity)。由于systolic是2维运算,除0的过程会使矩阵失去其运算规律,从而在控制上就不可行。现在针对systolic的sparsity主要是在算法层面,例如group sparsity,在一个group内部采用dense matrix,而group之间是sparse的,systolic仅针对group内部的MAC进行加速。
数据交互部分,thinker实现了2个144KB的local buffer,可以实现运算和存储的ping-pong操作。这个buffer size在同级别对比下不是很大。每个local buffer分成48个entry,可以提供48x16 bits的数据带宽。对于2个16x16的矩阵而言,32个entry足够了,多出来的16个entry对应的ports,就是面对PE array重构后,提供额外的数据读写通道的。而且从后边的算法描述来看,thinker还提供了一个卷积数据解压缩的方法,可以以更小的ports数实现卷积的数据供给。
论文给出了PE array执行卷积和乘累加的例子,这里画的很清楚,比TPU的论文强多了。
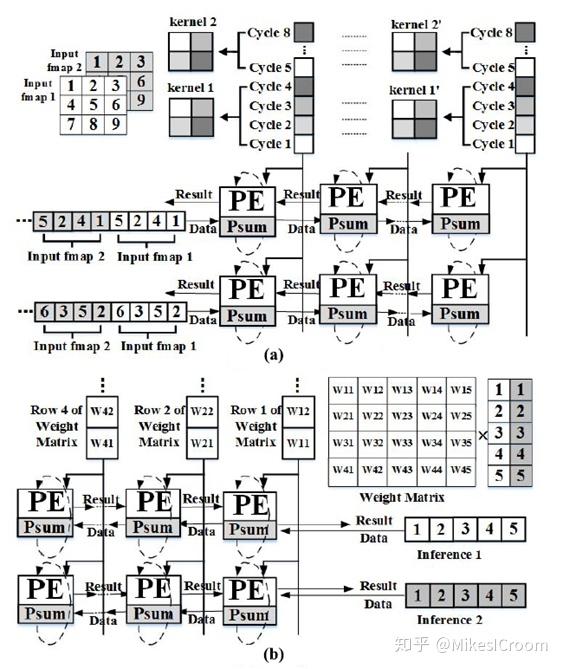
图(a)是卷积运算,数据根据kernel size,展开成1维的向量(如图中,kernel1在input fmap1上的第一次卷积覆盖的data是1、2、4、5,横向展成1维向量是1425)。Kernel根据数据展开方式也纵向展开成1维向量。运算时,数据自左向右依次进入PE array,kernel在列方向依channel分开,每列是一个channel,自上而下进入。每个PE会进行K=(kernel\_width x kernel\_height x channel\_in)次累加操作完成 ,即数据虽然在流动,但是累加结果会维持在当前PE里K次。如图例,左上第一个Psum的累加运算为(一个channel累加)
- Cycle 0:psum=0
- Cycle 1: psum=psum + 1 x K00
- Cycle 2: psum=psum + 4 x K10
- Cycle 3: psum=psum + 2 x K01
- Cycle 4: psum=psum + 5 x K11
- …. Multi channel MAC …
由于PE array中各PE执行时间的早晚不同,data和weight都是以diamond行式输入矩阵的,这点和TPU完全一致。执行完毕后,结果会沿着data输入的反方向写回data buffer。这点和TPU有所不同。TPU论文给出的写回方向是垂直于data 输入方向的。这也从侧面上表明了两者虽然都是systolic结构,但是对卷积的具体实现有所区别:TPU是weight常驻在矩阵中,data输入后在纵向进行累加,结果在最下方输出,即累加的过程是systolic的;而thinker是data和weight相交进入矩阵,在同一个PE中进行累加,这一点和systolic支持矩阵乘的方法是一致的。Weight常驻矩阵的方法当然可以极大的节省weight方向数据传输的功耗,不过thinker采用这用方法也是其架构特点决定的。首先,这种传输方式可以统一卷积和矩阵乘的硬件控制实现,简化设计复杂度。其次,注意PE array最下一排是Super PE,是用来做非卷积运算的特殊模块。如果采用TPU的方法,势必要占用最下一排的Super PE进行数据写回,这样就不能在做卷积的同时支持其他运算了,从而限制了reconfig的能力。因此算法和架构设计是相辅相成的,需要结合考虑,才能最大发挥两者的优势。当然反方向写回有一个问题,就是无法支持pipelined write back。每完成16x16个卷积运算之后,需要16个cycle把数据写回,PE array清空后,才能进行下一次的卷积运算。这样在峰值性能上,同配置下thinker的卷积算力是要略低于TPU的。不过thinker通过可重构,同时支持了卷积和乘累加的并行运算,一定程度上弥补了这个缺点。另外一点,Super PE用来执行pooling,tanh等计算的时候,数据仍然是自左向右逐拍进入的,这并不符合此类运算的特点,因此Super PE line的计算效率其实是很低的。不过这并不是问题,只要能在卷积运算的时间内完成就不会有性能损失。
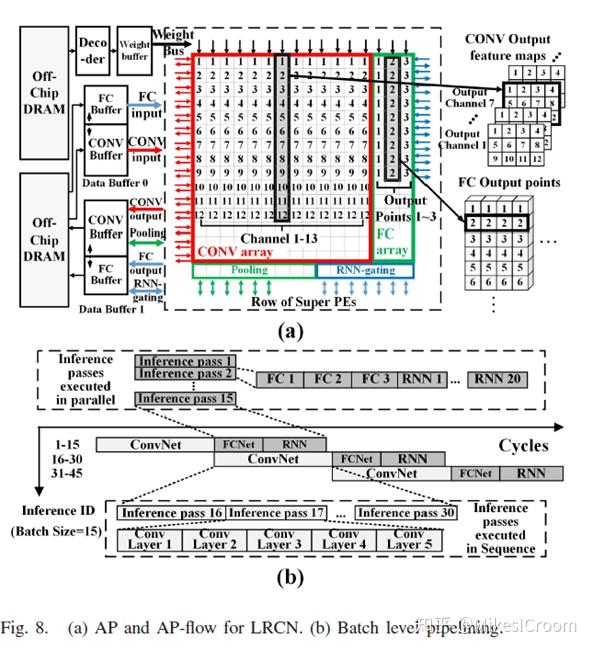
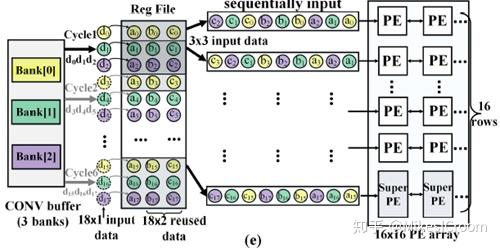
thinker并行性的基础是通过分析卷积和全连接(FC,主要为矩阵乘累加运算)的特点得到。Systolic执行卷积的特点是数据带宽要求较小而计算时间较长;FC即矩阵乘累加,因此计算量较小而数据带宽较大。可以看出两者的特征是互补的。这样启发了thinker的可重构思路:分配较多的PE给卷积运算,而分配较多的buffer entry给FC。这样平衡了两者的带宽需求和运算需求,相当于1+1>2了。由于FC占用了16个issue ports,为了减少卷积对ports数量的需求,thinker利用了数据依kernel size一维展开后,数据重复出现的特点,在issue端增加了一个Reg File模块。Data buffer输出的数据流是纯矩阵无重复的数据,经过RegFile进行重排后,形成1维展开后的数据流,如下图。这里就不再介绍具体细节了,有兴趣可以看下论文,写的很清楚。注意一个细节,由于PE array在水平方向上分成了2个部分用来分别支持卷积和FC,而两者又要并行执行,那么就需要同时输送数据给两个重构模块。这里论文隐藏了一个细节,即PE 的每行其实是有2条数据通道的,可以同时给两个PE发送数据。这样才能在硬件上实现两者的并行执行。因此,PE array的可重构数目并不是可扩展的,数据通道的数量限制了可重构模块的数量。不过thinker似乎并不想在这个方面做过多的解释,对于DL算法,同时支持卷积和FC已经足够了。因此thinker的结构不是一个scalable的框架,这样也制约了它大幅提升单核算力的能力。
上述设计思路非常有启发作用,在架构实现中,应该针对所面向的具体算法,详细分析各部分的特点,从中挖掘提高并行性的可行性。这也是DSA(Domain Specific Architecture)所推崇的设计理念,针对特定领域做特定加速。
Thinker的编程接口跟通常的coprocessor差不多,其指令对于控制CPU端而言就是数据,由后者静态或动态编译产生,发送到Thinker加速器中。虽然论文花了一些篇幅解释了如何进行软件编译和重构配置,给出了一些振奋人心的参数,然而对于CGRA所带来的软件复杂度的问题,我认为thinker是忽视了的,或者说对于研究而言是够用的,但是大规模商用后,能否提供一个高效友好的编程接口,这里并没有有说服力的答案。首先,data buffer完全暴露给软件操作,可以说更灵活,但实际上是增加了软件调度的复杂度。单核还好,如果是32核64核,高效调度众核的buffer,以及buffer内部的48个entry,不是一个容易的事。其次,从论文给出的卷积、FC、pooling等算法的可重构方案来看,高效的进行重构编译和数据调度,需要深入了解硬件结构,并没能提供一个高层的编程框架,让软件工程师可以跳出硬件具体的细节,从抽象层次进行开发。而抽象的概念,在软件领域至关重要。这也表明,thinker在CGRA的核心算法上还没有突破性的进展。不过如果我们把 thinker只看作是针对当前DL算法的DSA设计,而并非CGRA的通用加速器,这个设计是成功的,用较小的软硬件代价实现了既定目标。
总结一下,thinker是一款很有特点的CGRA结构的DSA设计。通过针对几种DL典型应用的可重构加速和并行配置,以相同的硬件配置提供了更高的性能。从官方信息来看,thinker目前的应用领域也是针对低算力低功耗的语音和简单图像识别方向,和其设计目标是很匹配的。期待未来thinker能给我们带来好消息。
图[1] 和封面来自Thinker Presentaion in GTIC 2018
其余图片来源为论文
Shouyi Yin, et al. “A High Energy Efficient Reconfigurable Hybrid Neural Network Processor for Deep Learning Applications”, in IEEE JOURNAL OF SOLID-STATE CIRCUITS, VOL. 53, NO. 4, APRIL 2018
更多AI处理器架构设计的技术干货,欢迎关注公众号MikesICroom,同时欢迎关注AI处理器架构设计专栏。

