
2019年的hotchip如期闭幕。其中很多AI相关的报告,最想了解的当然是华为的达芬奇架构。从半年前昇腾处理器的各种新闻就吊足了胃口,不过一直没有细节部分的展示。这次hotchip的presentation终于可以一窥真目了。
作者:MikesICroom
原文:https://zhuanlan.zhihu.com/p/80126455
由于没有听过现场的演讲,只能根据ppt的内容进行解读,有不对的部分,欢迎大家批评指正。这一篇主要是针对达芬奇的硬件结构。
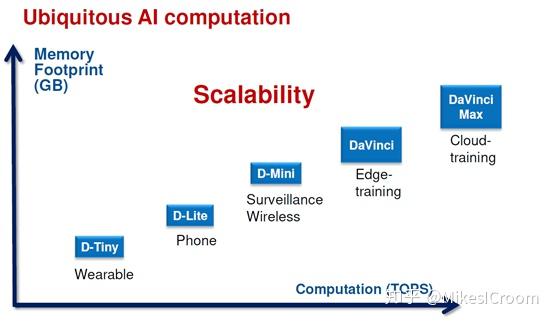
达芬奇架构追求的是一个全场景的scalable设计,以一个通用的硬件架构,实现从低端到高端的全覆盖。这是一个很宏大的目标。由于各个应用领域的具体需求不同,比如嵌入式领域对成本和功耗非常注重,移动端更关注性能和功耗的平衡,而云端是极致性能的追求者。通常来说很难有一种架构适配全部应用场景。像ARM这样的通用处理器架构,也针对应用领域的不同需求,设计了M/R/A三个系列,分别针对嵌入式、实时系统和应用领域。对于单一的application region,针对高端的A7x系列和低端的A5x系列,在流水线结构和运算单元设计上也截然不同。不过在面向深度学习的硬件加速领域,由于目前算法的原因,最小的算力需求都在数百GOPs,这远远超过了传统处理器所能提供的运算能力,最少也需要数百个MAC才能实现。这个最小数量的限制和纯运算的需求给scalable的目标提供了便利。可以看到达芬奇的设计,也是通过改变MAC数量和核心数目来实现的全场景可扩展。当然是否实现对全场景的高效支持,还是需要大规模应用后才能检验。
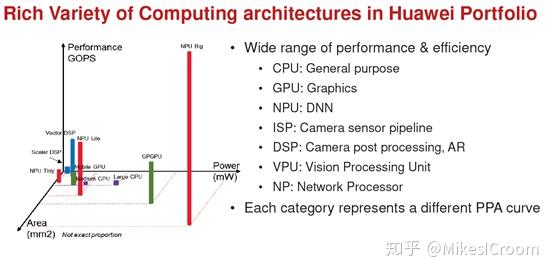
全场景的另外一层含义是不仅仅针对深度学习的典型框架进行加速,而且可以适配包括传统的机器学习在内的各种AI算法。对于不同的算法需要不同的硬件进行加速,这是一种DSA(Domain Specific Architecture)的思想。达芬奇的思路是将包括CPU,Vector、Tensor Core等多种硬件加速单元集成在一块芯片中,根据具体的应用使用不同的硬件单元进行运算。这是包括intel在内的很多芯片厂商采用的方法,如intel推崇的多核异构,一块芯片上可以集成CPU、GPU、FPGA等多种运算模块。这并不是芯片面积的浪费,而是在“Dark Silicion”影响下的硬件设计新思路,相关分析可以参考文末的延伸阅读。
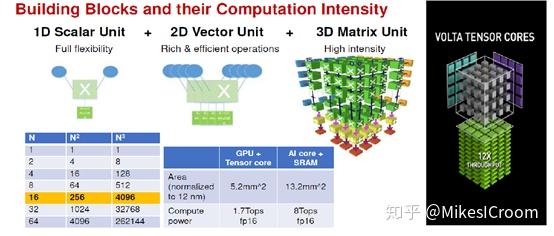
接下来我们看下达芬奇的MAC矩阵结构。这个3D Matrix Unit的结构就像是一个NVIDIA tensor core的放大版(右边黑底为NVIDIA volta tensor core结构)。由于ppt上并没有给出这种3D matrix的具体运算形式,只能合理推测应该和tensor core差不多,一个cycle执行16x16+16的矩阵乘累加操作,相当于4096次MAC运算。这个运算可要比tensor core的4x4+4大的多,硬件上也复杂的多。一个tensor core需要64个MAC可以实现,这个乘法器数量比较少,直接综合就可以。而达芬奇是4069个乘法器,这么大的规模需要很特殊的处理。推测是采用了类似systolic的方法,数据依systolic到达时间的不同呈菱形进入MAC矩阵,这样首次启动的时间较长(数十个cycle),但可以实现每个cycle得到一个16x16矩阵的运算结果。不过输入数据预处理和systolic每拍连接的硬件资源应该不小。
通过改变2D Matrix Unit中MAC的数量,可以衍生出针对高中低三个领域的不同配置。可以看到即使最小的Tiny,支持的运算规模都是8x8+8,比tensor core的规模大8倍。更大的MAC矩阵可以更好的利用矩阵乘法运算中的数据复用性,用较小的存储和带宽实现相同的算力,不过代价就是灵活性的降低。2D Matrix算法结构的基础是将卷积运算转化成矩阵乘累加,较大的MAC矩阵在运行较小的模型上的效率是比较低的。这要求达芬奇的三个架构需要分别针对大中小三种规模的模型才能发挥出最大效用。同时为了避免算力浪费,转化的矩阵应该尽可能是MAC矩阵边长的倍数,比如Davinci Max需要是16的倍数,这个比tensor core的4的倍数要求要高。因此,硬件设计是一个有得必有失的折中, NVIDIA选择了灵活,华为选择了算力。这并不能简单的判断优劣,还是老话,符合具体需求的架构才是最好的。

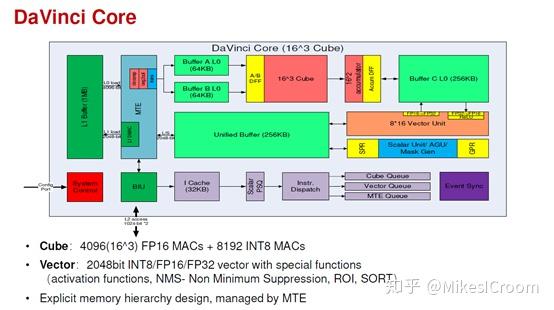
这是华为第一次秀出达芬奇架构的框图。从大的结构上看,数据从L1预取到L0后,依次发射到Cube中进行2D matrix运算,结果写到buffer C中,可以通过Vector单元进行卷积和全连接之后的后处理运算(operation fusion,和TPU以及NVDLA的结构类似),然后写回到United Buffer中等待下一次调度。最下方是控制通路,指令经Icache取得后,译码分发到Scalar,Vector和MTE三个单元中进行对应的运算。整体数据通路和寒武纪的“DINANAO”是很类似的,通过显式的内存管理调度数据进入主运算cube或后处理单元,各buffer内部空间划分出ping-pong存储块,保证数据存取的连续性。下方的控制加上scalar和vector运算,相当于集成了一个通用CPU在其中,这样的话支持任何算法都没有问题了。scalar负责控制流和简单运算,vector来解决MAC矩阵所不擅长的pooling,activation等操作,这几部分相互配合补充,很好的实现对AI算法全场景的支持。可以明显看出,最核心的运算还是在cube,主要面向流行的深度学习算法,在其他AI算法上使用vector和scalar运算,算力比cube低不少,因此这类算法的性能是低于SIMT结构的GPU的。

从寒武纪的“DIANNAO”到Google的TPU再到达芬奇,AI芯片的设计呈现出百花齐放的场景。有单一针对卷积神经网络的ASIC加速器,有支持简单编程的通用型处理器;有的通过硬件可重构进行算法映射,有的通过VLIW指令支持高并发运算;有一个超大矩阵支持大规模AI运算,有通过众核进行任务切割运算;有的作为协处理器,有的可以独立运行。可以说计算机发展史中出现的各种架构在其中都有体现。达芬奇的整体结构是经指令执行的众核系统,它将三种运算类型集成一体的思路很好的体现了专用型和灵活性,我认为是走在正确的道路上。而如何高效的使用这三种运算资源以及存储调度,这个就非常考验软件和编译的实力了。
总结一下,从硬件角度,达芬奇架构是一个混合型的设计,或者叫核内异构系统。通过集成scalar、vector和cube三类运算单元分别支持不同的AI算法场景,同时吸收了之前深度学习加速器的成功经验,这也是作为后发者的优势。全场景的通用AI处理器中,达芬奇和同领域的寒武纪、GPU的硬件结构有非常多的相似之处,对深度学习的支持也是各有优劣。而华为最大的优势其实是作为系统供应商的软硬件结合设计的能力,这一点和Google、Amazon发展自定义的AI加速器是同样的道理。通过云端收集数据进行反馈调整,反复迭代升级,不断完善硬件对基本算子的良好支持和软件编译的高效性和友好性,最终形成生态闭环。期待华为在AI领域再创辉煌。
[1]文中图片来自hotchip 2019, Huawei.Davinci presentation
推荐阅读
更多AI处理器架构设计的技术干货,欢迎关注公众号MikesICroom,
同时欢迎关注AI处理器架构设计专栏。

