
记忆网络(MemNN)是神经网络的重要分支,在问答领域有广泛应用。其计算特点更符合人类记忆和思考的过程,相比传统RNN、LSTM等模型具有更好的长期记忆能力,最近的关注度也很高。本文首先阐述了MemNN的网络特点,进而分析其架构设计中的难点,主要针对其存储过大、带宽高、稀疏计算三个方面,结合ISCA相关论文的论述,提出一些可能的解决方案和思考方向,希望对今后的AI加速器设计有所启发。
作者:MikesICroom
原文:https://zhuanlan.zhihu.com/p/81176067
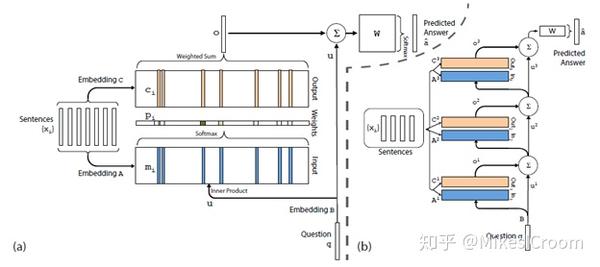
memory network(MemNN),也叫memory-argumented neural network,2014年由Facebook的工程师提出。这种特殊的网络有很强的上下文信息感知和处理能力,非常适合信息提取,问答任务等人工智能辅助领域。不同于传统的前馈网络CNN,RNN等将训练集压缩成hidden state进行存储的方式,这类方法产生的记忆太小了,在压缩过程中损失了很多有用信息。而MemNN是将所有的信息存在一个外部memory中,和inference一起联合训练,得到一个能够存储和更新的长期记忆模块。这样可以最大限度的保存有用信息,下图是一个简单的MemNN的流程示意图。
通过描述性的语言解释下MemNN的运行过程。首先输入的内容(input story sentences)经过加工和提取储存在外部memory中。问题提出后,会和上述内容一起通过embedding过程产生question,input和output三部分,相当于在理解问题和内容的相关程度。然后通过inference过程,寻找和问题最相关的内容语句,再提取语句中和问题最相近的单词,最终产生答案A。在这个过程中,输入内容几乎是完整的保存和使用的,而不是像RNN那样压缩成数据量较少的中间状态,因此信息的完整性是比较好的。同时inference使用的是full connection连接和softmax归一化,很容易在传统的深度学习优化算法和硬件上获得较好的加速效果。
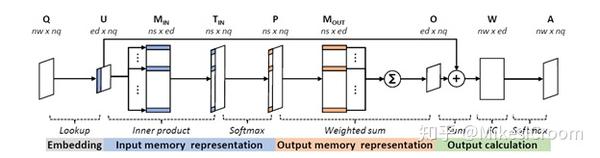
具体到细节,MemNN主要包括2种操作:embedding和inference。前者是将输入转化成中间状态的计算过程,而inference是通过多层神经网络来推断语句和问题的相关性。story经embedding过程产生2个矩阵:input 和output matrix,把输入语句转化为内部存储的向量,这一步会使用通常NLP的词向量转化方法。问题输入给MemNN网络后,会通过inference计算得到和上述内部向量之间的相关性,具体是三个步骤。
首先“input memory representation”过程会计算问题向量和input matrix的点积后归一化,得到和input matrix维度一致的概率向量p,即问题和各记忆向量的相关程度。这一步的运算是矩阵乘累加和softmax。
第二,“output memory representation”过程将output matrix按概率向量p进行加权求和,得到输出向量o,相当于选取了相关性最高的记忆向量组合。这一步主要是矩阵点积。
最后一步“output calculation”是将输出向量转化为所需答案的格式,得到各单词相对答案的概率,运算是全连接型的矩阵乘累加。
上述只做行为级的描述,相关步骤的公式可以参考论文[1]。
经过上述分析,我们可以总结下MemNN的计算特点并从架构角度分析其可能存在的问题。首先,也是最明显的,MemNN对输入内容的保存没有经过大幅度的压缩,信息完整性很高,这样在问答推理上相比RNN等压缩模型很有优势,不过带来的问题就是存储空间会随着内容的增大而线性增加,对片上存储的压力较大。而片上存储不足的直接后果就是内存带宽需求的增加。第二,运算几乎都是矩阵乘累加或者点乘,这一点和RNN是比较类似的,这样在同等运算强度下,对数据量的需求要高于卷积,也就是对带宽的需求更大;第三,由于MemNN计算的特点是从story生成的多个向量中选择相关性最大的产生答案,因此中间结果矩阵会是一个很稀疏的矩阵,只有相关性较强的部分才有值,其他不相关的几乎都是0,这样的话通常的密集运算加速器(如TPU等)效果就不好了,需要软件和硬件着重考虑如何进行稀疏性的优化。
可以看出,对于MemNN来说,现有的ASIC加速器并不能很好的优化上述问题,因此在计算效率上应该是没有GPU强的,这也是GPU这种SIMT结构适应性更强的优势。如何在硬件上同时高效支持CNN和MemNN这两种差别较大的模型,还有比较长的路要走。今年的ISCA论文中,有一篇是针对MemNN进行优化,尽管主要在算法层面,但可以在一定程度上给未来的通用AI加速器作为参考。
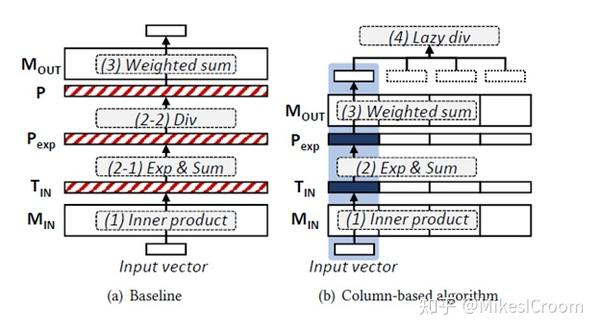
针对MemNN存储较大的优化方法利用了input memory representaion计算的可交换性。通常的计算是先乘累加在softmax,由于softmax是一个除法运算,分母是固定的,因此可以利用乘法分配律,将矩阵乘累加拆成若干个部分单独执行,这样归一运算和求和计算就很好的分开了,具体公式可以参考论文[2]。针对后者,我们不需要一次性的算完e^n后再和Mout做乘法,而是将其分组(N),每组内部先完成全部的求和,这样一次运算对存储的需求就只有之前的1/N了,如果正好全部放在片上cache中,那么组内运算就不需要进行内存的替换。再配合ping-pong预取下一组的数据,可以完美的将数据预取和计算并行起来,大大降低了传统计算中数据反复替换的损失。这一点很有启发,AI加速是软硬一体的紧密结合体,算法设计中应该充分利用数据的局部性,尽可能将一组数据和计算都在片上完成,组与组之间提高并行性。硬件应提供相应的并行化设计和调度方式,方便软件进行优化。两者相辅相成。
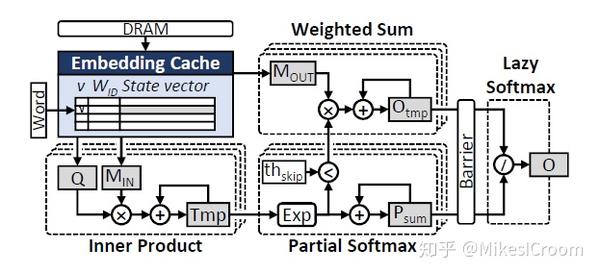
其他两种方法没什么特点,一个是针对稀疏性提出的根据阈值丢弃运算,这个主要在软件层面,CPU和GPU会比较容易实现;另一个是针对embedding matrix是常量的特点,设计了一个dedicated cache专门存放input和output matrix,类似于独立的weight cache,进行数据分隔式存储,减小对计算中间结果的干扰。最后使用FPGA做了一个硬件实现,比CPU算法高了6倍。这个加速比并不算高,主要原因是对于cache替换的优化在CPU和FPGA上的提升是差不多的;而稀疏矩阵的加速效果FPGA甚至会低于CPU;至于embedding cache,我个人感觉作用不大。因此FPGA主要就是运算单元数量和某些ASIC算法(softmax)上的优势了。因此该方案并没有很好的利用MemNN的特征,不是一个很好的解决方案,论文中也只是一带而过的介绍。
总结一下,MemNN的运算特点决定了它并不能在当前的AI硬件加速器中获得很好的提升。这突出了TPU类ASIC加速器算法适应狭窄的缺点,也几乎是目前所有面世的AI加速器的局限。之前在“AI芯片的趋势”一文中提到了灵活性,对于AI算法而言,更需要软硬一体层面的紧密配合,甚至要超过在CPU和GPU这类通用处理器上的所能做的极致。在这一点上,目前的AI加速器设计还有很多可以改进之处。
[1] Sainbayar Sukhbaatar, et, al. "End-To-End Memory Networks", NIPS, 2015,
[2] Hanhwi Jang, et, al, "MnnFast: A Fast and Scalable System Architecture for Memory-Augmented Neural Networks", ISCA 2019
推荐阅读
更多AI处理器架构设计的技术干货,欢迎关注公众号MikesICroom,
同时欢迎关注AI处理器架构设计专栏。

