
上一篇简述了Tengine如何适配ncnn模型,其实本质上Tengine算是一个新的IR,可对各种框架进行适配,虽然不同框架对不同算子有不同的实现方式,但是经过Tengine团队的不懈努力,可以支持nchw与nhwc的计算格式。
现在Tengine开源部分的算子分别对于不同的平台分为arm32,arm64,ref,x86。其中arm32与arm64是针对端侧平台的算子优化,以arm汇编和arm neon为主来进行计算部分的优化,可以大大提高计算效率。X86则是针对Convolution和FullyConnected层在x86平台上进行加速。优化部分只针对需要大量计算的算子,对于其余的算子则是通过加载reference算子来实现。那么现在问题来了,那么多平台,如何对相同算子进行调度则是一个问题。
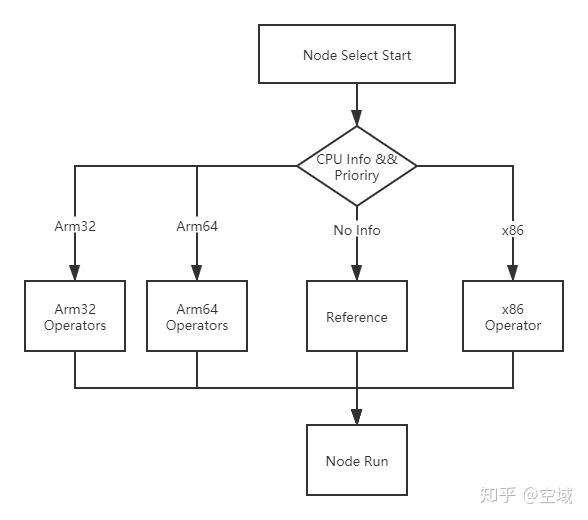
Tengine 算子调度流程图
上图则表述了Tengine是如何判断相同算子在不同平台的调度。
在Tengine框架内部,每一个类别都有自己独有的注册列表,例如arm32有自己的init.cpp,arm64也有自己的init.cpp来进行注册。在运行Tengine的时候,Tengine首先会获取平台信息,当获取平台信息后则会进行算子部分的调度。
NodeOps* NodeOpsRegistryManager::RealFindNodeOps(const CPUInfo* cpu_info, Node* node)
{
NodeOps* ops;
if(cpu_info != nullptr)
{
// search cpu_type
int master_cpu = cpu_info->GetMasterCPU();
const std::string& cpu_model = cpu_info->GetCPUModelString(master_cpu);
ops = FindNodeOps(cpu_model, cpu_info, node);
if(ops)
return ops;
// search arch
std::string cpu_arch;
int int_arch = cpu_info->GetCPUArch(master_cpu);
if(int_arch == ARCH_ARM_V8)
{
cpu_arch = "arm64";
}
else if(int_arch == ARCH_ARM_V7)
{
cpu_arch = "arm32";
}
ops = FindNodeOps(cpu_arch, cpu_info, node);
if(ops)
return ops;
}
// search x86
#if CONFIG_ARCH_X86
ops = FindNodeOps("x86", cpu_info, node);
if(ops)
return ops;
#endif
// the final search: reference
ops = FindNodeOps(REF_REGISTRY_NAME, cpu_info, node);
return ops;
}上述代码则展示了Tengine对于不同平台的的算子调度部分。
在进行Tengine框架运行的时候则可以通过不同的环境变量设置来进行算子的调度。Tengine实现算子的步骤是首先实现Reference算子,在保证能正常工作的情况下在进行针对性的算子优化,例如对arm32与arm64,所以性能算子可以直接在Reference中找到对应算子。变相的可以理解Reference算子是各种平台优化算子的基础。如果出现模型运行错误的情况,则可以首先运行Reference算子来进行debug。对于如何调度如下:
export OPS_REGISTRY=reference
export OP_NAME=Convolution以上两条指令则是可以把Convolution算子设置在Reference,以此类推,如果对性能算子中的任何一个报有怀疑,则可以先用reference来进行验证。同样,对于初学者而言,c++当然比汇编要容易理解啦。
刚刚所说了Reference算子是包含了所有算子,那么如果区分相同算子是调用性能算子还是功能算子呢?这就涉及到两方面,第一则是上述所说的平台信息选择,第二则是算子中设置的优先级部分,以Convolution算子为例,如下为在Reference中的算子选择函数:
const int default_prio = 1500;
...
...
...
NodeOps* SelectFunc(const CPUInfo* cpu_info, Node* node)
{
RefConv* ops = new RefConv();
return ops;
}
} // namespace RefConvolutionOps
void RegisterRefConv2d(void)
{
NodeOpsRegistryManager::RegisterOPImplementor(REF_REGISTRY_NAME, "Convolution", RefConvolutionOps::SelectFunc,
RefConvolutionOps::default_prio);
}如下为在arm32中Convolution的选择函数:
const int default_prio = 500;
...
...
void RegisterConv2dFast(void)
{
if(!NodeOpsRegistryManager::RegisterOPImplementor("arm32", "Convolution", conv_fast::SelectFunc,
conv_fast::default_prio))
LOG_ERROR() << __FUNCTION__ << " :Regist OP failed for prio[" << conv_fast::default_prio << "]\n";
}
上述在arm32中的default\_prio = 500 优先级设置高与Reference中的default\_prio = 1500,则表明在算子调度时优先选择arm32中的Convolution算子。
好啦,Tengine简单的算子调度介绍到此结束啦。
附带Tengine Github链接
https://github.com/OAID/Tengine
推荐阅读
初次尝试Tengine 适配 Ncnn FP32 模型
更多Tengine框架相关请关注Tengine-边缘AI推理框架专栏 及作者知乎(@空域)

