
作者:李凡
来源:https://zhuanlan.zhihu.com/p/51600261
何为 RAM
RAM -> Ramdom Access Memory ,随机存取存储器。何为随机存取。举个不准确的例子:和上篇文章中的 FIFO 进行对比。对于 FIFO 来说,只有读写两个操作,只能顺序读写。但对于 RAM 来说,同样的读写操作,用户可以在读写时指定读写的地址,实现对整个存储器的乱序(随机)读写访问。
何为 BRAM
BRAM -> Block RAM,花名:块 RAM。
FPGA 中有两种 RAM 资源,另一种 RAM 资源为 Distributed RAM,Distributed RAM 经过综合工具综合,通过多级 LUT 查找表资源级联实现,那么一个 Distributed RAM 可能(综合工具实际应该不会)是由天南地北,相隔很远的 LUT 级联实现的,故名分布式。分布式 RAM 可以利用丰富灵活的 LUT 资源,可以根据使用情况灵活配置,适合对 RAM 延迟要求不高的场合,毕竟并不是"真正"的 RAM。(其实物理上也是真正的 RAM,但不是专用的)
那么 Block RAM 相比分布式 RAM,就是一位专业选手了,BRAM 是 FPGA 厂商在逻辑资源之外,给 FPGA 加入的专用 RAM 块资源。相比分布式 RAM,RAM 块内部以及与逻辑资源之间经过特意的布局布线,使 BRAM 具有很高的运行速度,确定的低延迟周期,但有限的资源数量。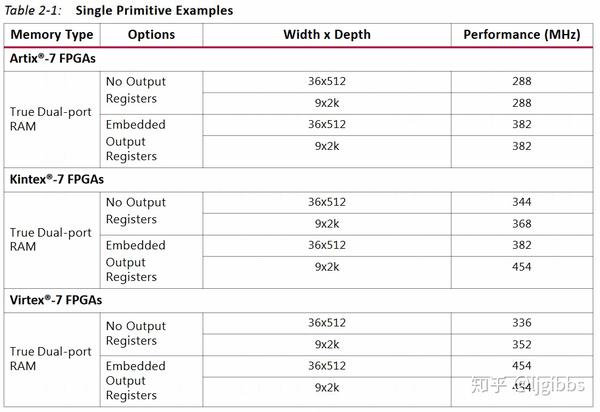 本土主要说明速度,W*D 并不是资源总数。
本土主要说明速度,W*D 并不是资源总数。
在网络通信,数字信号处理中应用中,BRAM 都是最重要的资源之一,实现高速数据的缓存,当前最高端的型号拥有近 200MB 的 BRAM 资源。
Nice to Meet BRAM Memory Generator
在 Vivado 中,使用 BRAM Memory Generator 可视化工具生成 BRAM ip 核。
通过在 Ip catlog 中搜索 BRAM,就可以打开 Generator
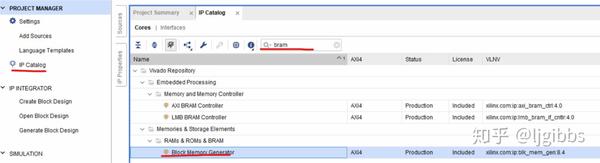
块/分布式 RAM 有独立的生成工具。可以从 AXI4 一栏了解到该 IP 对 AXI4 协议的支持情况。支持 AXI4,AXI4-Lite,AXI-Stream 或者不支持。(但在 Vivado 中似乎已经没有不支持 AXI4 的 IP 核)
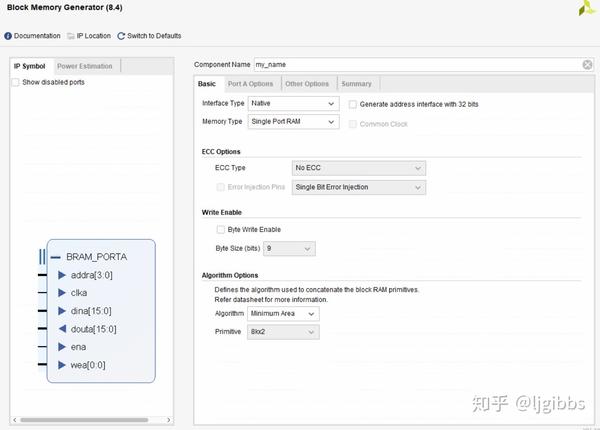
在界面上方的组件名称中,可以设置 IP 核的模块名,并会告诉你某些名字和保留字冲突,不能使用。这里实名吐槽 ISE,在选择 IP 核之前得先确定名字,之后不能改,而且有些无法使用的模块名,还不会提醒。
世界上没有两个完全相同的 ip 核,但它们很多特性是类似的。比如 BRAM 同样支持两种接口类型:Native 或者 AXI4,和 FIFO 一样,本文使用 Native 接口进行讲解,关于 AXI4 协议,可以通过作者的其他文章了解。(就不放链接了啊)
Native 接口
Native 接口分为三类:
- 时钟,复位信号
- 读写地址与数据
- 写使能与 RAM 使能
时钟自不多说,对于 IP 核来说时钟好比,水之于鱼,游戏业务之于腾讯的营收。复位信号是可选的。
读写地址的宽度可以基于 RAM 的深度,log2(深度),也可以固定为 32 位。
RAM 写使能有效时,可以写入数据。在使用 always enable 模式下,读取在每个时钟上升沿有效,不需要额外的使能信号。不然的话 RAM 在读写时都需要 ena 使能信号有效。
Memory 类型
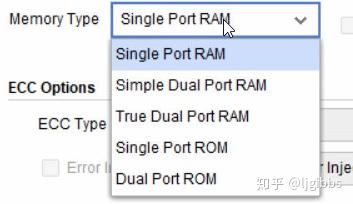
总体上 Memory 按照类型可以分为 RAM 和 ROM,ROM 预置了数据,在使用中只能被读取,不能写入,ROM 实现的物理结构与 RAM 类似,相当于一个只能读取的 ”RAM”。一般用于存放一些固定的参数,比如 FIR 滤波器的参数等等,在使用过程中只需要读取,不需要也不能修改。
按照端口的数量有单端口以及双端口之分,双端口来自于同时对 RAM 进行读写的需求。一边将等待处理的数据从端口 A 输入 RAM,另一端口 B 读取数据进行处理,可以实现高效的数据流式处理,尤其适用于图像的行缓存处理。双端口 RAM 相较于 FIFO ,有可以映射地址以及多次重复利用数据的优势。在新的数据写入之前,可以多次从一指定位置读取旧数据。
双端口 RAM 又可以分为 Simple/Ture 双端口,这方面似乎有点复杂,将在后续的文章中详细分析。本文将主要介绍单端口 RAM 的使用。
读写冲突避免
对于一个 RAM 的读写时序来说,写入时,写使能有效,写入 din 端口上的数据到 addr 端口地址中。读取时,直接从 dout 端口上获得输出 addr 地址上的数据。那么当写使能有效时,用户同时进行读取操作,读取到新数据还是旧数据。这取决于 RAM 的工作模式。
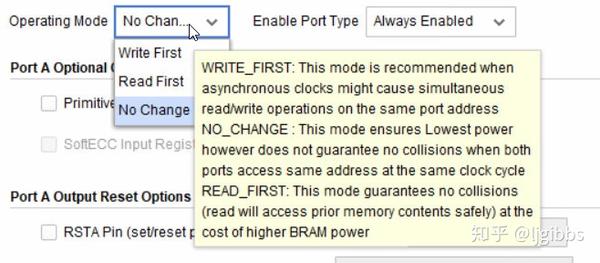
工作模式分为三类:写优先,读优先以及 no change。
写优先,在读写时钟异步的情况下,推荐使用。该模式会保证写操作优先发生。
读优先,该模式以消耗更多 BRAM 资源的前提下,保证每次读操作读取到的都是先前的数据。输入数据会首先被缓存,与此同时在输出总线上输出先前值,一个周期的延迟之后,再输出输入数据。
写入期间数据不变,该模式很“佛性”,在写入期间数据不变,对读写冲突不闻不问,但优点在于节约 BRAM 功耗。
后文将结合仿真,对三种工作模式再进行详细介绍。
PORT 的其他设置
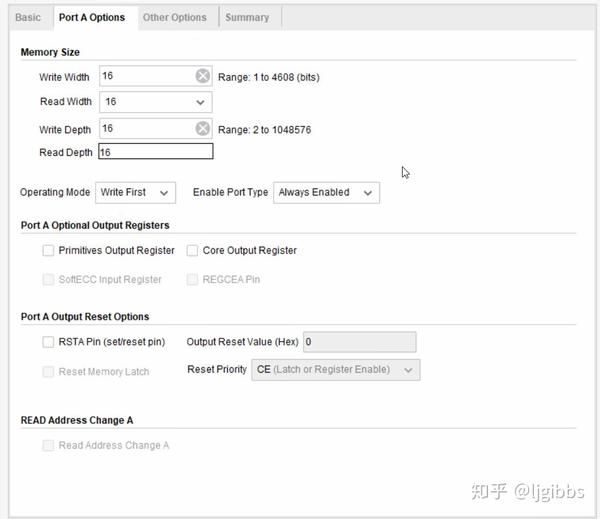
该选项卡中配置 RAM 的宽度与深度;以及是否设置 RAM 使能端,是否设置复位端以及复位后的初试值。
另外重要的一点是配置 RAM 的输出寄存器。共有两个选项 Primitive / Core Output Register。两个选项可以各自选择,都是为输出端添加一级寄存器,不同在于前者在 Port 内部添加寄存器,而后者是在 Port 外部添加寄存器。自然而然,每一级的寄存器都会增加一个周期的读延迟,从初始的 1 周期读延迟,最高可以增加到 3 周期读延迟。
添加寄存器虽然会增加延迟周期数,因为输出信号经过了打拍,但可以减少时钟到数据时间(即从时钟上升沿开始,直到数据出现在输出端口上的时间),改善时序。至于两者之间的区别,本文暂不做讨论。(作者目前也没什么了解)
在 其他选项 中可以为 RAM 指定初始值,类似于 ROM。
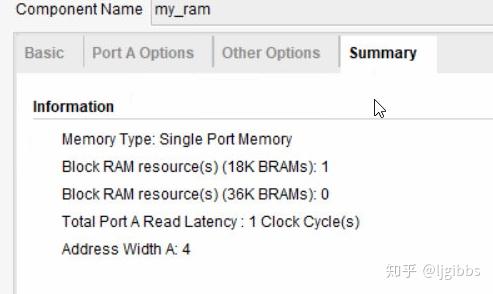
我们的数据宽度为 16,深度也为 16 ,但还是使用了一个最小的 18K BRAM实现,着实有些浪费。但 BRAM 使用时的特点就是这样,最小使用单位 9K/18K (取决于器件)。如果想要完全用尽一个 BRAM 块,可以将宽度设为 18,深度设为 1024 。或者较小的 RAM 使用分布式 RAM 实现。
开始仿真
首先,我们观察 RAM 的读延迟。(之前的描述有误,感谢指出的读者 @yq)
将使能端 ena 置高,通过置高写使能信号 wea 一个周期,在时钟上升沿完成一次写入操作。可以观察到,地址总线写入 0x1,在时钟上升沿到来之前准备好了使能信号和地址信号。时钟沿上升沿到来后,完成一次写入操作。

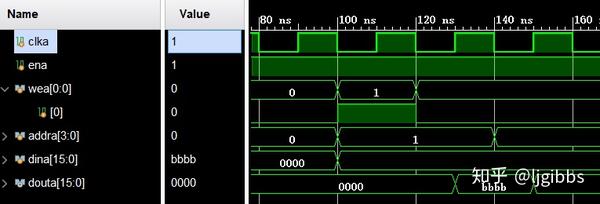
将使能信号和地址在时钟上升沿到来之前准备好
在完成了对地址 0x01 的写入后,就可以通过读取地址 0x01 来观察 BRAM 的读延迟了。
这张仿真图中,读取地址为 0x01,可以观察到在时钟上升沿到来后,经过了 100ps 的延迟之后,0x01 地址上的数据 0xbbbb 出现在 dout 上。

这 100ps 的延迟意味,如果用户逻辑在将地址准备好后之后的第一个上升沿读取数据,那么读取到的数据就是错误的,必须等待下一个时钟上升沿才能够进行读取。从下图手册中的时序说明也可以看到这个延迟。
Latch 代表是 primitive 的输出,reg1 代表的是经过一级输出寄存器后的输出

ena 使能端为低时,会失能 RAM 的读写操作。
ena 信号置低之前,写操作完成,但读操作被失能。

单/双端口 RAM 的应用
在单端口 RAM 中,通常的应用可能是,先进行一系列写入,再进行一系列读取,循环反复。但也可以对一个地址,写入,读取,地址递增,再循环反复。这样的操作类似 FIFO,意义不大。
单端口 BRAM 的应用主要用于缓存,比如需要缓存一些数据,首先将所有数据放入 RAM 中,之后根据需要从不同的地址中取出数据进行运算或者处理。单端口适合读取和写入分时进行的应用。在这类应用中,不会交错进行读取写入。
连续的写入,读取操作可以使用双端口的 RAM 实现,双端口 RAM 有各种独立的地址通道和数据通道,可选各自独立的时钟。
双端口 RAM 的应用很广泛,这里举一个图像处理中的例子。
在图像处理中,图像卷积是一项基本的操作。卷积操作中,需要在将新数据缓存到 RAM 中的同时,从 RAM 中取出旧数据进行卷积运算。这时候读写逻辑控制是分开,双端口提供两套读写控制接口,适合这类读写逻辑相独立的场合。但需要注意的是读写冲突问题,在图像卷积操作中,通过将写地址固定为读地址- 0x2,解决冲突问题。
这里推荐一篇有关 FPGA 图像处理的文章。
https://zhuanlan.zhihu.com/p/38946857
输出寄存
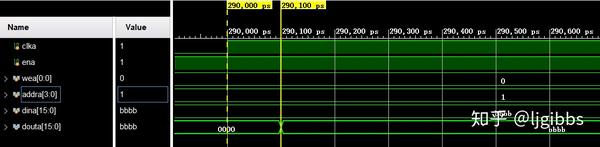
在增加了一级输出寄存器后,如 primitive 输出寄存器后,dout 的数据会出现在地址就绪后的第二个时钟上升沿之后,100 ps 的延迟之后。笔者目前对输出寄存器的作用也还不甚了解。
工作模式
这里通过一个简单的例子,比较了 no change ,read first 以及 write first工作模式。
首先是 no change 模式,在写入期间,输出保持不变,所谓 no change。输出端口上原本为地址 0 的数据:0xaaaa,当地址 1 和地址 2 开始写入时,输出端口保持不变,在写入结束时刻,本来经过 1 /2个周期的延迟,应该输出地址 1 /2上的值:0x1111/0x2222,但是都没有,输出端口保持写入发生之前的地址 0 的数据:0xaaaa。
凡是写入期间,输出保持不变。
只在写入结束后,经过 1 个周期,输出地址 3 上的数据:0x3333 。可见,该模式的特点就是在写入时,保持输出端口不变,但会在读写冲突期间,无法读到地址 1 和地址 2 上的正确数据,读到的都是错误的数据 0xaaaa,地址 0 上的数据。

接下来是 write first 写优先模式,可以看到该模式下,写数据和将数据输出到输出总线上是同时进行的。在向地址 1 和地址 2 写入数据的同时,在对应时刻,经过一个周期延迟后,仍然正确地输出了地址 1 和地址 2 中,但注意,输出的是刚写入的新值。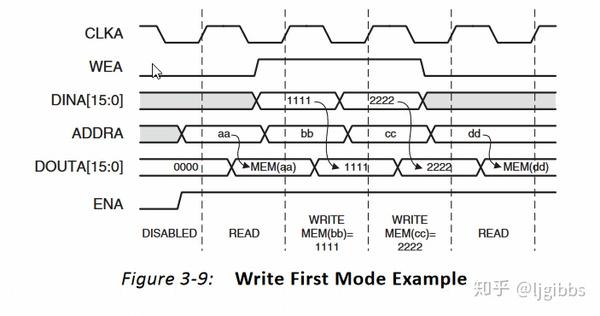
最后是 read first 读优先模式,从时序上来看,读优先模式和写优先模式类似,同样接收输入的同时,按照时序将数据输出,但不同在于,写优先模式输出的是写入的新值,而读优先模式输出的是在写操作发生之前的旧值,这种不同,实际上是通过将旧值缓存实现的。下图中 0xbbbb,0xcccc 分别为地址 0x1,0x2 中原有的旧值,在向地址 0x1,0x2 写入新值,它们在dout 上被输出。
read first 模式



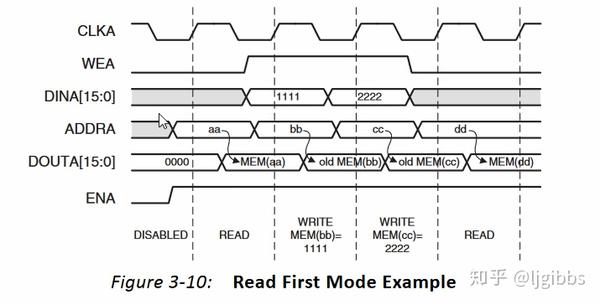
工作模式总结
实际上,一般不会选择 no change 模式,因为会有错误读取的可能性。根据需求选择 write/read first 即可。当然,最好还是避免冲突访问。
关于文档
岔开下话题,讲讲作者在写文章之前或者使用 ip 核遇到问题时,是怎么解决的。其实无他,你一方面可以 bing 一下,找到类似本文的讲解性文章,试图解开疑问。或者,你可以通过 ip 核的官方手册了解到一些 ip 核的基本特性。在 ip 核配置界面,选择左上方:
可以调转到 DocNav 中对应的手册,如果软件中打不开的话,就在手册的图标上右键,选择在浏览器中打开。open docu in Browser
一般在 PG Product Guide 中,看一下第一部分的概述和第四部分的 ip 核配置界面参数即可,可以之后有问题了,再回去细看别的部分。 当然都是英文的,这没什么办法,可以借助一些翻译工具,有道之类,据说还挺好用的。
当然都是英文的,这没什么办法,可以借助一些翻译工具,有道之类,据说还挺好用的。

结束语
本文从 RAM 开始,简单介绍了各项概念,并介绍了 BRAM ip 核配置的部分参数与选项。通过仿真对单端 RAM 读延迟,使能以及读写冲突情况下的工作模式的验证与学习,末了,简单讨论了翻阅 PG 的一点儿经验。希望能对读者有帮助,有任何问题,我们评论区见。
在后续的文章中,会继续讨论 RAM 的实际使用以及双端口 RAM 的仿真。
参考资料
推荐阅读
关注此系列,请关注专栏FPGA的逻辑

