
新事物总是令人愉快。这个系列文章将记录一些笔者对新东西的尝试,记录下全新的心得和见解。
作者:李凡
来源:https://zhuanlan.zhihu.com/p/73059862
最近笔者参加了研电赛上海赛区的企业命题,命题是在一块酷芯微电子的开发板及其AI加速框架的基础上,实现基于神经网络的轻量化人脸检测推断加速方案。

笔者不是很懂深度学习和 AI,这里就以一个对嵌入式软硬件都相对熟悉的开发者的角度,分享一下和 AI 硬件推断加速平台及其相应 SDK 软件开发框架的初体验。
当前 Platform 是芯片厂商们偏爱的单词,尤其是 AI Platform,厂商们反对把自己的芯片叫做 xx 芯片,而要称为XX平台。但确实有别与单一的芯片器件,所谓平台就在包括芯片成品的同时,也包括了厂商提供的软件开发工具包(SDK)等软件开发环境以及相应的文档,demo 等支持。
对于芯片厂商来说,优秀的芯片产品当然是首要的,但在 AI 为代表的一些领域中,相对较少的专利壁垒和短暂的先发优势使得这个领域中不存在绝对一马当先的产品。此时,高效,稳定,有利于提高开发效率,加快落地时间的软件生态可能是决定芯片成功与否的关键。
目前市面上有多少 AI 芯片,实际上就有多少 AI 框架。手机 SoC 厂商:高通,华为,MTK;IP 提供商:ARM,C&S ;FPGA 厂商:Xilinx,Intel;AI 芯片厂商:寒武纪等都有为自己的产品提供软件开发环境和框架。
此次拿到的酷芯微电子 AR9201 平台就搭载了一颗 AI 加速芯片,由 ARM A7 处理器核与四核 CEVA DSP 构成。用户的应用程序运行于 ARM 端的 Linux 上,网络推断计算运行于 DSP端
第一次看到板子的时候:Layout 挺漂亮的,然后怎么这个串口插座这么奇葩,用的 3.5mm 耳机插座。。。(左下角的三个 UART)

酷芯微提供的 AI 软件框架名为 ARCDNN,由一系列基于 AR9201 平台的 SDK 接口组成,并为网络的量化转换提供了相应工具。ARCDNN 分为 ARM & DSP 两部分功能,ARM 下负责为 DSP 喂入计算数据和网络参数,对网络输出的结果进行融合处理,DSP 计算功能调度;DSP 端实现网络的推断计算; ARM 和 DSP 之前通过内存进行通信。
开发资源
厂商在开发板硬件以外提供了以下软件和文档方面的支持:
- 较为完整的文档,各方面都有涉及,基本上仔细翻翻能找到 80% 需要的信息,不过对于一块无法 bing 到的板子来说,这些资料确实算不上丰富,毕竟厂商的资料和 AE 的支持是开发者能得到的全部。(自然,AE 对我们这些参加比赛的“用户”支持还是比较有限的)
- 驱动,比如摄像头以及板上外设的驱动,使得开发者在 AI 这个高层次开发上几乎不需要考虑这些基础外设驱动。
- 实现加速的 DSP 代码的二进制文件,厂商提供了一套现有的 DSP 程序,这套程序负责接收数据和参数后进行网络推断。用户也可以自己开发,通过 CEVA DSP 的 IDE,但我们这个水平 Level 也就用用厂商提供的可执行文件了。
- AI 开发框架 ARCDNN,这是重头戏,包括:
- C 语言函数库,用于 Linux 上用户程序的开发。提供了运行于 ARM 的 linux 系统与用于加速的 DSP 之间通信的函数,以及 DSP 初始化参数,启动运算,参数读取,结果提取函数等控制 DSP 的函数。
- 网络转换和量化工具,用于将 Caffe,TensorFlow 等框架生成的网络模型转换为可以卸载到 DSP 上进行计算的二进制文件(包括了网络的架构和规模),并进行量化。转换和量化过程都由工具完成,用户可以设定一些参数,这套工具对于 Caffe 有更好的支持。
- 用户应用程序的仿真环境,由于板级调试难度较大,厂商基于 Visual Studio 提供了一套仿真 DSP 的应用程序。用户可以在 VS 上开两个工程,一个程序仿真 DSP,另一个是自己开发的应用程序,仿真 ARM 端运行。通过这两个程序仿真板级的情况,进行调试。仿真环境的速度还是较慢的。
- 应用程序 Demo,在接触了一些嵌入式应用之后,越发感觉一个平台上优秀的 Demo 对用户的帮助会很大,反之亦然。酷芯提供了多个 demo,主要有,基于 MobileSSD 的物体分类网络和基于 MTCNN 的人脸检测网络。这两个网络的输入来自摄像头,将计算的结果叠加在摄像头图像上输出到 HDMI。Demo 中包括了:
- 一系列初始化和配置函数,这些函数在一般的使用中都不需要做修改。
- 图像数据的读取与裁剪等预处理步骤,可以通过使用 opencv 的图像处理函数, opencv 在 demo 中已经被编译整合,可以直接使用。
- 多网络间的输入输出交互,前级网络输出的结果,经过 resize 等后处理后再输入后级网络。我们在后续开发中完全基于了 Demo 中的对前后级间的网络数据处理的流程和结构。
- 基于 ini 配置文件的配置方式,在应用中需要对很多参数进行设置,比如网络存储的位置等等,在 demo 中整合了 ini 文件的读取程序。并且 demo 的 ini 文件也作为了我们后续修改配置文件的基础。
开发流程
在了解了厂商提供的资源后,我们来梳理下整个在开发板上进行网络移植的流程。
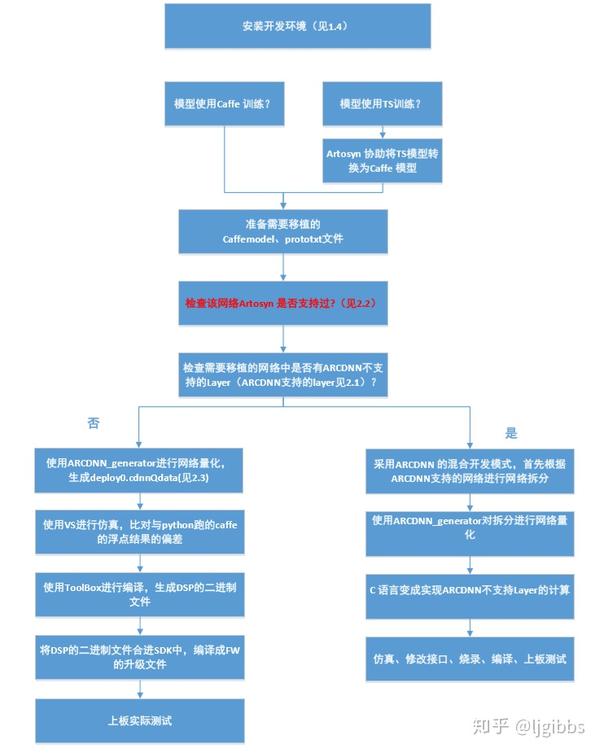
来自文档的开发流程
首先是要选择轻量化的网络,受限于存储和性能的限制,一些非轻量化的网络的帧率有限,比如 VGG16,在 INT16 下,帧率为 3。同时需要选择 ARCDNN 支持的网络或者网络完全由支持的网络层组成。
通过转换量化工具将网络转换为 ARCDNN 支持的二进制格式,在这个过程中,也会完成网络的量化工作。在这次应用中采用默认参数,没有关注量化数据宽度这些细节。从上图可以看出,转换工具对于 Caffe 的支持较好,如果是使用 Caffe 训练的 ARCDNN 支持的网络,那么通过转换工具,可以将 CaffeModel 以及 Protext 转换为 DSP 读取的 xx.cdnnQdata 二进制文件。转换后还可以通过仿真来确定量化的误差。
此时网络的转换基本完成,可以上板进行调试,也可以先在 VS 平台进行仿真,检测程序的逻辑以及推断结果的误差,无误后上板测试。
板级测试时,用 U 盘将测试使用的图片,转换后网络的二进制文件,编译的应用程序可执行文件移至板子。在配置文件中设定这些文件的路径,运行内存大小等参数。运行程序后可以得到推断程序的输出结果。这个输出结果可以是人脸的区域,或者该人脸的性别等待。一般来说开发者需要在应用程序对网络的输出进行一定转换,得到最终的结果。
关于 DSP 加速
AR9201 平台拥有 4 个 DSP 核心,但这次应用我们只用到了一个核心,我们没能完全发挥板子的性能。原因有二:内存的限制以及没有在应用层制定多核的调度机制。
平台拥有 2GB DDR内存,我们的应用中使用了 8 个网络,需要约 700 MB 内存,那么算上 Linux 所需的空间,内存就限制了我们最多使用两个 DSP 核心。
似乎 AI 框架应该负责多核的调度,所以我们为两个 DSP 分配了同样的网络任务,但实际测试上并没有加速的效果。从其他小组的加速结果来看,似乎需要用户在应用编写自己的多核调度以及通信程序才能够获得较好的加速效果,比如将相邻两帧分别分配给 DSP0,DSP1。这也是比较令我疑惑的一点,AI 框架在我的理解中应该会对多核进行分配才对。
总结
针对目前深度学习主流的框架 TF,Caffe 等等,厂商的推断加速平台都提供了相应的工具对训练的模型进行转换量化,使得用户能够快速地将网络推断任务移植到平台上。平台的硬件外设驱动也会整装待发,抽象为 API 在应用层以供调用。但面向不同的使用场景,还是要在框架的基础上开发自己的业务代码。如果要求性能较高,则可能需要对计算部分的代码进行对应的优化。
最后谈一些个人的想法,感觉应用的数量与质量对于加速平台会非常重要。如果有高质量的应用需求,那么就能推动框架和平台整体的进步,强者越强的马太效应会显现。规模较小的公司则会更关注细分市场的应用。
在这次尝试中,笔者感受到在使用加速平台的应用中,实现功能相对容易,但对功能的优化却总还是一件难事,期待之后能有机会再好好优化一番,作为尝试,可能到这里就告一段落了。
推荐阅读
关注此系列,请关注专栏FPGA的逻辑

