
本文主要内容是介绍ARMv7和v8内联汇编的一些基础知识,并且会结合两个具体例子去看下如何用内联汇编来改写原来的代码。
作者:梁德澎
首发知乎:https://zhuanlan.zhihu.com/p/143328317
对于怎么写内联汇编,网络上其实有不少资料,比如官方文档[3,4,5,6,7,8]、博客[1,2,9,10]、移动端推理框架(ncnn,Tengine,MNN,TFLite等)的源码等。或者通过反汇编查看编译器编译出来的汇编代码,这些都是可以学习的资料。
不过最重要的是要去动手实践,看文献再多都比不上自己动手写代码。
本文相关实验代码:
内联汇编基本概念
其实上层C++代码最终也是会编译成汇编代码,而且到了最底层的实现,大概流程都是加载数据到寄存器,然后进行计算,最后把寄存器的值写回内存。
而一般运行瓶颈就在于数据的加载和写出还有指令之间的数据依赖等等,所以怎么更高效的读写数据还有使相邻指令之间的数据依赖最小等等,是做优化经常都会遇到的问题,当然这个很吃经验,但是也总是会有一些套路可寻。
本节主要内容是介绍有关于armv7和v8通用寄存器和向量寄存器的相关知识和内联汇编的一些基础内容,更详细的内容下一节结合例子来说明。
arm v7 和 v8寄存器对比
首先来看下 arm v7和v8寄存器的表示和数量上的异同。官方文档[5]给出了详细的对比,这里就简单列举下v7和v8通用寄存器和向量寄存器的区别。
通用寄存器
arm v7 有 16 个 32-bit 通用寄存器,用 r0-r15 表示。
arm v8 有 31 个 64-bit 通用寄存器,用 x0-x30 表示,和v7不一样的是,这31个寄存器也可以作为 32-bit 寄存器来用,用 w0-w30 表示,其中 wn 是 xn 的低32位,如下图所示:

向量寄存器
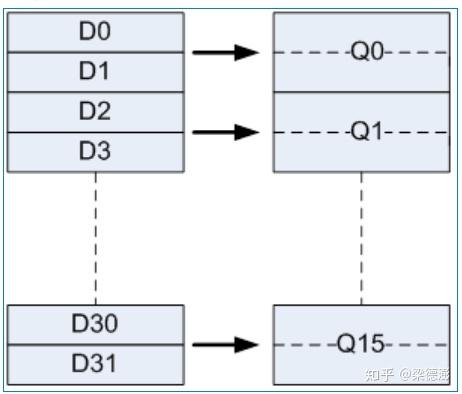
armv7 包含 16 个 128-bit 向量寄存器,用 q0-q15 表示,其中每个q寄存器又可以拆分成两个 64-bit 向量寄存器来用,用 d0-d31 来表示,对应关系:
也就是 对应 的低64-bit, 对应 的高 64-bit,如下图所示:
armv8 则有更多的向量寄存器,32个 128-bit 向量寄存器,用 v0-v31 来表示, 而其表达形式比起v7更加灵活,如下图:

每个128-bit向量寄存器可以当做:
- 包含 2 个 64-bit 元素的向量寄存器来用,表达形式是 vn.2d;
- 包含 4 个 32-bit 元素的向量寄存器来用,表达形式是 vn.4s;
- 包含 8 个 16-bit 元素的向量寄存器来用,表达形式是 vn.8h;
- 包含 16 个 8-bit 元素的向量寄存器来用,表达形式是 vn.16b;
或者每个向量寄存器也可以只用低 64-bit:
- 1 个 64-bit 元素的向量寄存器来用,表达形式是 vn.1d;
- 2 个 32-bit 元素的向量寄存器来用,表达形式是 vn.2s;
- 4 个 16-bit 元素的向量寄存器来用,表达形式是 vn.4h;
- 8 个 8-bit 元素的向量寄存器来用,表达形式是 vn.8b;

内联汇编一般格式
这节主要介绍arm内联汇编的一般格式,文档[6]给出了很详细的说明,下面简单介绍一下
__asm__ qualifiers (
// 汇编代码部分
: OutputOperands //在内联汇编代码中被修改的变量列表
: InputOperands //在内联汇编代码中用到的变量列表
: Clobbers //在内联汇编代码中用到的寄存器列表
);
qualifiers:一般是用volatile修饰词OutputOperands:在内联汇编中会被修改的变量列表,变量之间用','隔开,
每个变量的格式是:[asmSymbolicName] "constraint"(cvariablename)cvariablename:表示变量原来的名字;asmSymbolicName:表示变量在内联汇编代码中的别名,一般和cvariablename一样,在汇编代码中就可以通过%[asmSymbolicName]去使用该变量;constraint:一般填=r,具体解释见文档[6]InputOperands:在内联汇编中用到的所有变量列表,变量之间用','隔开,
每个变量的格式是:[asmSymbolicName] "constraint"(cexpression)
和输出不一样地方是,首先要按OutputOperands列表的顺序再列一遍,但是constraint用数字代替从0开始,然后才是写其他只读变量,只读变量constraint填r。Clobbers: 一般是"cc", "memory"开头,然后接着填内联汇编中用到的通用寄存器和向量寄存器"cc"表示内联汇编代码修改了标志寄存器;"memory"表示汇编代码对输入和输出操作数执行内存读取或写入操作(读写参数列表之一的变量指向的内存);
示例:
const uint8_t *src = ...;
uint8_t *dst = ...;
int neonLen = ...;
const int test = ...;
#ifdef __aarch64__ // armv8
__asm__ volatile(
// 汇编代码部分
:[src] "=r"(src),
[dst] "=r"(dst),
[neonLen] "=r"(neonLen)
:[src] "0"(src),
[dst] "1"(dst),
[neonLen] "2"(neonLen),
[test] "r"(test)
:"cc", "memory", "v0", "v1", "v2", "v3", "v4", "v5",...
);
#else // armv7
__asm__ volatile(
// 汇编代码部分
:[src] "=r"(src),
[dst] "=r"(dst),
[neonLen] "=r"(neonLen)
:[src] "0"(src),
[dst] "1"(dst),
[neonLen] "2"(neonLen),
[test] "r"(test)
:"cc", "memory", "q0", "q1", "q2", "q3", "q4", "q5",...
);
#endif
关于优化的一些个人经验
对于刚入门优化的同学,改写汇编最好先从C++改写intrinsic开始,然后再根据intrinsic的代码去改写汇编,一般intrinsic的指令和汇编指令都能对应的上,当然高手可以直接跳过去写汇编,但是对于新手建议还是一步步来。
而且比较重要的一点是,我认为算法上的改进更为重要,假设你C++算法层面代码已经定下来了,对于性能还想有更进一步的提升,那么可以尝试去写neon汇编(内联或者纯汇编),但不是说汇编是万能的,这个和你的优化经验还有算法本身的复杂度有很大关系,可能你吭哧坑次改完,发现还做了负优化,因为编译器本身也会做向量化,不要等改完汇编才发现有更优的算法实现,那么就白忙活了。
下面结合具体例子在遇到相关知识点的时候,再去介绍详细,同时会对比arm v7和v8汇编指令的异同。
具体例子:
例子一、两个数组加权和
第一个例子是两个数组对应元素加权和,例子足够简单,方便讲解改写汇编的一些思路。 下面代码为了可读性会相应的作简化,完整代码见:
https://github.com/Ldpe2G/ArmNeonOptimization/tree/master/armAssembly
先来看下C++的实现:
bool arrWeightedAvg(const float *arr1,
const float arr1Weight,
const float *arr2,
const float arr2Weight,
const int len,
float *resultArr) {
for (int i = 0; i < len; ++i) {
resultArr[i] = arr1[i] * arr1Weight + arr2[i] * arr2Weight;
}
return true;
}
第一步、改intrinsic
对于intrinsic代码是兼容armv7和v8的,所以不同架构之间迁移也方便,不需要改代码:
bool arrWeightedAvgIntrinsic(const float *arr1,
const float arr1Weight,
const float *arr2,
const float arr2Weight,
const int len,
float *resultArr) {
int neonLen = len >> 2;
int remain = len - (neonLen << 2);
// 这里向量化主要思路是循环内每次
// 处理4个元素的加权和
// 所以neonLen是数组长度len除4
// 而剩下的尾部元素按正常处理
float *resultArrPtr = resultArr;
const float *arr1Ptr = arr1;
const float *arr2Ptr = arr2;
// 因为一次处理4个元素
// 所以权值要拷贝4份放到
// 一个float32x4_t类型变量中
// 也相当于是128-bit向量寄存器
float32x4_t arr1Wf4 = vdupq_n_f32(arr1Weight);
float32x4_t arr2Wf4 = vdupq_n_f32(arr2Weight);
for (int i = 0; i < neonLen; ++i) {
// 分别读4个数组元素
float32x4_t arr1f4 = vld1q_f32(arr1Ptr);
float32x4_t arr2f4 = vld1q_f32(arr2Ptr);
// eltwise乘法
arr1f4 = vmulq_f32(arr1f4, arr1Wf4);
arr2f4 = vmulq_f32(arr2f4, arr2Wf4);
// eltwise加法
float32x4_t resultf4 = vaddq_f32(arr1f4, arr2f4);
// 写结果
vst1q_f32(resultArrPtr, resultf4);
arr1Ptr += 4;
arr2Ptr += 4;
resultArrPtr += 4;
}
// 处理尾部元素
for (; remain > 0; remain --) {
*resultArrPtr = (*arr1Ptr) * arr1Weight + (*arr2Ptr) * arr2Weight;
resultArrPtr ++;
arr1Ptr ++;
arr2Ptr ++;
}
return true;
}
intrinsic指令字面上的意思也很好理解,下面简单解释下数据和计算指令类型的格式:
- 向量数据类型格式:
<type><size>x<number of lanes>_t
比如float32x4_t,<type>=float,<size>=32,<number of lanes>=4
支持的向量数据类型:

还有向量数组类型: <type><size>x<number of lanes>x<length of array>_t
比如
struct int16x4x2\_t
{
int16x4\_t val[2];
};
- 向量指令格式:
<opname><flags>_<type>
比如vmulq_f32,<opname>=vmul,<flags>=q,<type>=f32
下面说下该怎么查阅文档,比如搜索文档[3]先定位到P241,这一章都是解释 intrinsic 指令的用法,比如搜vadd,如下图所示
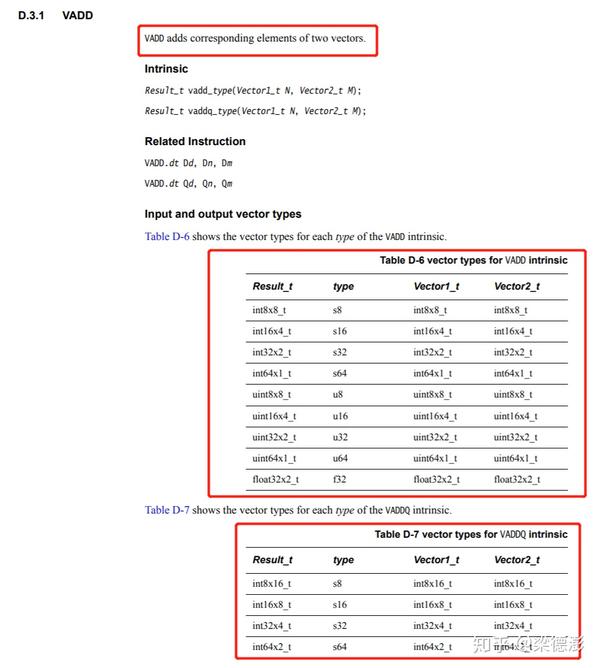
找到了对于指令的解释,还有操作数类型的支持,看着这个表格就能很好的写代码。
第二步、for循环改do-while形式接着改汇编
下面进入正题,看下怎么改写为内联汇编,
首先要把for循环改成do-while的形式,一般人写代码的思维都是用for循环,而汇编层面循环的实现形式和do-while很像,是在循环结尾判断循环是否结束,没结束就跳转到循环开头的地址继续计算。
bool arrWeightedAvgIntrinsic(const float *arr1,
const float arr1Weight,
const float *arr2,
const float arr2Weight,
const int len,
float *resultArr) {
......
// float32x4_t arr1Wf4 = vdupq_n_f32(arr1Weight);
// float32x4_t arr2Wf4 = vdupq_n_f32(arr2Weight);
// for (int i = 0; i < neonLen; ++i) {
// ......
// }
float32x4_t arr1Wf4 = vdupq_n_f32(arr1Weight);
float32x4_t arr2Wf4 = vdupq_n_f32(arr2Weight);
do {
float32x4_t arr1f4 = vld1q_f32(arr1Ptr);
arr1Ptr += 4;
float32x4_t arr2f4 = vld1q_f32(arr2Ptr);
arr2Ptr += 4;
arr1f4 = vmulq_f32(arr1f4, arr1Wf4);
arr2f4 = vmulq_f32(arr2f4, arr2Wf4);
float32x4_t resultf4 = vaddq_f32(arr1f4, arr2f4);
vst1q_f32(resultArrPtr, resultf4);
resultArrPtr += 4;
neonLen --;
} while (neonLen > 0);
......
}
其实这个例子for改do-while很简单,因为循环体内部并没有用到变量i和neonLen。
然后就可以开始改写成汇编了:
armv7汇编
bool arrWeightedAvgAssembly(const float *arr1,
const float arr1Weight,
const float *arr2,
const float arr2Weight,
const int len,
float *resultArr) {
int neonLen = len >> 2;
int remain = len - (neonLen << 2);
float *resultArrPtr = resultArr;
const float *arr1Ptr = arr1;
const float *arr2Ptr = arr2;
#ifdef __aarch64__ // armv8
......
#else // armv7
__asm__ volatile(
// 下面两句代码对应
// float32x4_t arr1Wf4 = vdupq_n_f32(arr1Weight);
// float32x4_t arr2Wf4 = vdupq_n_f32(arr2Weight);
"vdup.f32 q0, %[arr1Weight] \n"
"vdup.f32 q1, %[arr2Weight] \n"
// 可以简单理解对应 do
"0: \n"
// pld 这个指令是可以让编程
// 人员指示cpu说,这段内存未来可能会用到
// 让cpu先预预加载到cache
// 等到下一次用到的时候,需要读取的数据已经
// 在cache中,所以可以看到预加载arr1Ptr偏移128字节
// 之后的一段内存,当然这个偏移量是需要调的
// 因为内存加载是一段段加载的,太远之后的不合理
// 太近又相当于浪费了这一条指令,因为下面的vld加载
// 指令本身也会加载一段内存进cache,
// 关于预加载可参考文档[4]P152
"pld [%[arr1Ptr], #128] \n"
// 对应
// float32x4_t arr1f4 = vld1q_f32(arr1Ptr);
// arr1Ptr += 4;
// 指令末尾的!表示,写完内容后地址会自增
// 增加的字节数就是读取的字节数
// {d4-d5}就是q2寄存器
"vld1.f32 {d4-d5}, [%[arr1Ptr]]! \n"
"pld [%[arr2Ptr], #128] \n"
"vld1.f32 {d6-d7}, [%[arr2Ptr]]! \n"
// 对应
// arr1f4 = vmulq_f32(arr1f4, arr1Wf4);
// arr2f4 = vmulq_f32(arr2f4, arr2Wf4);
"vmul.f32 q4, q0, q2 \n"
"vmul.f32 q5, q1, q3 \n"
// 对应 float32x4_t resultf4 = vaddq_f32(arr1f4, arr2f4);
"vadd.f32 q6, q4, q5 \n"
// 对应 neonLen--
// sub指令后面加个s表示会更新条件flag
// 关于条件分支这块可以参考[12]
"subs %[neonLen], #1 \n"
// 对应
// vst1q_f32(resultArrPtr, resultf4);
// resultArrPtr += 4;
// 指令末尾的!表示,写完内容后地址会自增
// 增加的字节数就是写入的字节数
"vst1.f32 {d12-d13}, [%[resultArrPtr]]! \n"
// 对应 while(neonLen > 0)
// b是跳转指令,后面跟条件判断gt
// 表示大于0则跳转到标志为0的地址
"bgt 0b \n"
:[arr1Ptr] "=r"(arr1Ptr),
[arr2Ptr] "=r"(arr2Ptr),
[resultArrPtr] "=r"(resultArrPtr),
[neonLen] "=r"(neonLen)
:[arr1Ptr] "0"(arr1Ptr),
[arr2Ptr] "1"(arr2Ptr),
[resultArrPtr] "2"(resultArrPtr),
[neonLen] "3"(neonLen),
[arr1Weight] "r"(arr1Weight),
[arr2Weight] "r"(arr2Weight),
[neonLen] "r"(neonLen)
:"cc", "memory", "q0", "q1", "q2", "q3", "q4", "q5", "q6", "q7"
);
#endif
......
}
其实从代码上来看,和intrinsic的代码是基本对应的上的,关于指令的一些注释都写在代码中了,下面来看下armv8的汇编和v7有什么区别。
armv8汇编
bool arrWeightedAvgAssembly(const float *arr1,
const float arr1Weight,
const float *arr2,
const float arr2Weight,
const int len,
float *resultArr) {
......
int neonLen = len >> 2;
int remain = len - (neonLen << 2);
float *resultArrPtr = resultArr;
const float *arr1Ptr = arr1;
const float *arr2Ptr = arr2;
#ifdef __aarch64__ // armv8
__asm__ volatile(
// 对应
// float32x4_t arr1Wf4 = vdupq_n_f32(arr1Weight);
// 这里因为armv8的寄存器是64-bit,不能直接拷贝4份
// 存到v0 128-bit 向量寄存器中
// 所以先移到一个x0寄存器中,然后
// 取其低32-bit w0
"mov x0, %[arr1Weight] \n"
"dup v0.4s, w0 \n"
"mov x1, %[arr2Weight] \n"
"dup v1.4s, w1 \n"
// 可以简单理解对应 do
"0: \n"
// 见下面解释
"prfm pldl1keep, [%[arr1Ptr], #128] \n"
// 对应
// float32x4_t arr1f4 = vld1q_f32(arr1Ptr);
// arr1Ptr += 4;
// 指令末尾的#16表示,写完内容后地址会自增
// 增加的字节数就是读取的字节数
"ld1 {v2.4s}, [%[arr1Ptr]], #16 \n"
"prfm pldl1keep, [%[arr2Ptr], #128] \n"
"ld1 {v3.4s}, [%[arr2Ptr]], #16 \n"
// 对应
// arr1f4 = vmulq_f32(arr1f4, arr1Wf4);
// arr2f4 = vmulq_f32(arr2f4, arr2Wf4);
"fmul v4.4s, v2.4s, v0.4s \n"
"fmul v5.4s, v3.4s, v1.4s \n"
// 对应
// float32x4_t resultf4 = vaddq_f32(arr1f4, arr2f4);
"fadd v6.4s, v4.4s, v5.4s \n"
// 对应 neonLen--
// sub指令后面加个s表示会更新条件flag
// 关于条件分支这块可以参考[12]
"subs %[neonLen], %[neonLen], #1 \n"
// 对应
// vst1q_f32(resultArrPtr, resultf4);
// resultArrPtr += 4;
// 指令末尾的#16表示,写完内容后地址会自增
// 增加的字节数就是写入的字节数
"st1 {v6.4s}, [%[resultArrPtr]], #16 \n"
// 对应 while(neonLen > 0)
// b是跳转指令,后面跟条件判断gt
// 表示大于0则跳转到标志为0的地址
"bgt 0b \n"
:[arr1Ptr] "=r"(arr1Ptr),
[arr2Ptr] "=r"(arr2Ptr),
[resultArrPtr] "=r"(resultArrPtr),
[neonLen] "=r"(neonLen)
:[arr1Ptr] "0"(arr1Ptr),
[arr2Ptr] "1"(arr2Ptr),
[resultArrPtr] "2"(resultArrPtr),
[neonLen] "3"(neonLen),
[arr1Weight] "r"(arr1Weight),
[arr2Weight] "r"(arr2Weight),
[neonLen] "r"(neonLen)
:"cc", "memory", "x0", "x1", "v0", "v1", "v2", "v3", "v4", "v5", "v6", "v7"
);
#else // armv7
......
#endif
......
}
从代码上看来起来,向量指令和v7的区别很大,不过掌握了区别也好写。
对于prfm pldl1keep, [%[arr1Ptr], #128] 预加载指令的使用方法,可以见文档[4]P152

速度对比与分析
ok代码改写完了,来看下改了普通C++,intrinsic和内联汇编三个版本速度的对比:
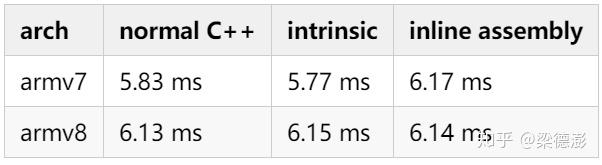
测试数组长度是10000000,测试机型华为P30 (Kirin 980),都是绑定大核。从测速结果看,还做了负优化,那我们来看下反汇编代码,看是不是因为编译器也做了向量化。
反汇编看编译器生成的代码
${NDK_ROOT}/toolchains/aarch64-linux-android-4.9/prebuilt/linux-x86_64/bin/aarch64-linux-android-objdump \
-d ${BUILD_DIR}/CMakeFiles/assemblyEx1ArrWeightSum.dir/assemblyEx1ArrWeightSum.cpp.o
可以用NDK目录下的
${NDK_ROOT}/toolchains/aarch64-linux-android-4.9/prebuilt/linux-x86_64/bin/aarch64-linux-android-objdump
工具对build目录下的obj文件反汇编,得到汇编代码,这里为了方便理解,我简化了代码:
Disassembly of section .text._Z14arrWeightedAvgPKffS0_fiPf:
00000000 <_Z14arrWeightedAvgPKffS0_fiPf>:
0: b5f0 push {r4, r5, r6, r7, lr}
2: af03 add r7, sp, #12
4: f84d 8d04 str.w r8, [sp, #-4]!
.......
82: fff4 2c60 vdup.32 q9, d16[0]
86: 4644 mov r4, r8
88: 4621 mov r1, r4
8a: 4675 mov r5, lr
8c: fff4 4c61 vdup.32 q10, d17[0]
90: 4616 mov r6, r2
92: 4603 mov r3, r0
94: f963 6a8d vld1.32 {d22-d23}, [r3]!
98: 3904 subs r1, #4
9a: ff46 6df4 vmul.f32 q11, q11, q10
9e: f966 8a8d vld1.32 {d24-d25}, [r6]!
a2: ff48 8df2 vmul.f32 q12, q12, q9
a6: ef48 6de6 vadd.f32 q11, q12, q11
aa: f945 6a8d vst1.32 {d22-d23}, [r5]!
ae: d1f1 bne.n 94 <_Z14arrWeightedAvgPKffS0_fiPf+0x94>
......
f6: bdf0 pop {r4, r5, r6, r7, pc}
我们看到地址94-ae,是不是和我们改写的汇编很类似,看来编译器也做了向量化,那其实对于简单的算法,改intrinsic或者汇编其实是没有优势的。
简单总结
所以可以看到,改写内嵌汇编和改Intrinsic可能还会引入负优化,因为对于简单的算法编译器会自动向量化。
所以也提供了一个优化思路就是其实把代码尽量改的简单就好了,去掉多余的分支判断等等。
后文请看 移动端arm cpu优化学习笔记第4弹--内联汇编入门(下)
参考资料
- [1] https://zhuanlan.zhihu.com/p/61356656
- [2] https://zhuanlan.zhihu.com/p/64025085
- [3]https://static.docs.arm.com/den0018/a/DEN0018A\_neon\_programmers\_guide\_en.pdf
- [4]https://static.docs.arm.com/den0024/a/DEN0024A\_v8\_architecture\_PG.pdf?\_ga=2.27603513.441280573.1589987126-874985481.1557147808
- [5] https://community.arm.com/developer/tools-software/oss-platforms/b/android-blog/posts/arm-neon-programming-quick-reference
- [6] https://gcc.gnu.org/onlinedocs/gcc/Using-Assembly-Language-with-C.html#Using-Assembly-Language-with-C
- [7]https://static.docs.arm.com/ddi0487/fb/DDI0487F\_b\_armv8\_arm.pdf?\_ga=2.262043400.441280573.1589987126-874985481.1557147808
- [8]http://infocenter.arm.com/help/topic/com.arm.doc.dui0965c/DUI0965C\_scalable\_vector\_extension\_guide.pdf
- [9] https://blog.csdn.net/chshplp\_liaoping/article/details/12752749
- [10] https://blog.csdn.net/aliqing777/article/details/50847440
- [11] https://azeria-labs.com/arm-conditional-execution-and-branching-part-6/
- [12] https://www.sciencedirect.com/topics/engineering/conditional-branch
推荐文章
- 移动端arm cpu优化学习笔记第3弹--绑定cpu(cpu affinity)
- 移动端arm cpu优化学习笔记第2弹--常量阶时间复杂度中值滤波
- 移动端arm cpu优化学习笔记第1弹--一步步优化盒子滤波(Box Filter)
更多AI移动端优化的请关注专栏嵌入式AI以及知乎(@梁德澎)。

