
本文将会结合TensorFlow的中文蹩脚文档和我的理解,浮光掠影地对委托代理(Delegate)做一定的解释。如果出错了还请读者指出,本文仅从TensorFlow Lite的文档出发结合我的思考,不做代码层面的分析。
需要注意的是,TensorFlow Lite的官网对于委托代理(Delegate)API的声明为仍处于试验阶段并将随时进行调整。
原文:https://mp.weixin.qq.com/s/jxW7mcysdl-CsUHb5oYVVQ
作者: 开心的派大星
1. 什么是委托代理及其优点
TFLite的委托代理是一种将部分或全部的模型运算委托予另一线程执行的方法。
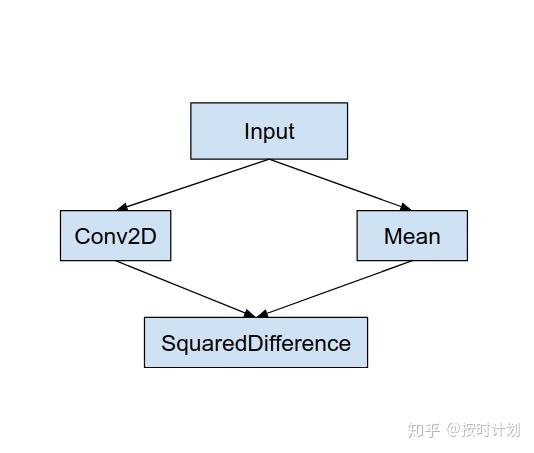
图:原始模型Graph
不过从我对文档的理解来看,感觉更像是添加的一种硬件后端(代理我想应该只是调用调用层面,不是底层实现,另外在Hexagon DSP的委托代理部分,文档坦言说Hexagon DSP的代理就是为了补充NNAPI,特别是针对那些NNAPI不可用DSP加速的、老旧驱动的设备,毕竟这些老旧设备也没有NNAPI这个东西,但有DSP硬件),交给模型的子图来去执行。比方原始模型的CPU执行Graph如上图。交给GPU的委托代理后,原Graph变为下面这样:
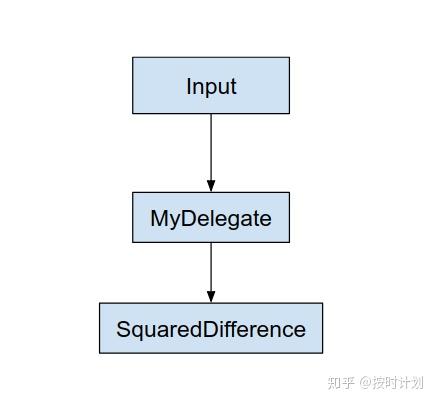
图:调用委托代理后的模型Graph
可以看到TFLite将原模型Graph做子图融合,将Conv2D和Mean结点的计算都交给了代理,前后的输入和输出都是一样的。中间的结点被代理处理,就成为黑盒。这个过程也可以理解成是 TFLite 对模型做了“翻译”,将其”翻译”为将执行后端的黑盒子图。
不过一般来说,该过程存在内存交换,若原有Graph模型中的“翻译转换”并不完全,那么将会有很多计算落在CPU上,原有Graph会拆分成很多子图交给委托代理执行。这种情况性能会因为来回的数据拷贝带来性能损耗。而且据我的一个小伙伴反馈,拿CPU和GPU来说(端侧),跑完CPU再接着跑GPU,或者相反,性能都会带来不稳定波动(下降)。
委托代理的优点:综合移动设备的算力和功耗,在CPU上做高算力计算不划算,但其他设备如 GPU 或 DSP 等硬件加速器或者如华为NPU,联发科APU、三星VPU之类的却可以获取更佳的性能与功耗表现。
2. 如何添加一个代理
注:这部分贴了文档的代码,挺长,不感兴趣的同学跳过即可。
TFLite的文档有说明(下面内容复制,粘贴一下原文档并做适当调整):
- 定义一个用于负责评估代理子图的核心节点;
- 创建一个用于负责注册该核心节点以及说明代理可用节点的实例 TensorFlow Lite 代理(即下面的
class MyDelegate)。
为了使用代码进行说明,下面将定义一个可执行 Conv2D 和 Mean 算子的代理,并将其命名为“MyDelegate”。
// 该MyDelegate类具有一个空实现,仅作结构体的声明。
class MyDelegate {
public:
// 若该代理有该算子的实现,则返回“true”。
static bool SupportedOp(const TfLiteRegistration* registration) {
switch (registration->builtin_code) {
case kTfLiteBuiltinConv2d:
case kTfLiteBuiltinMean:
return true;
default:
return false;
}
}
// 代码初始化,后文会绑定具体实现
bool Init() {}
// 初始工作分配,如分配缓冲区
bool Prepare(TfLiteContext* context, TfLiteNode* node) {}
// 代理子图开始运行
bool Invoke(TfLiteContext* context, TfLiteNode* node) {}
// ... 添加其他所需的方法
};
// 为核心节点创建一个替代主 TfLite Graph 中的子图的 TfLiteRegistration。
// 有点类似实际backend kernel注册的东西
TfLiteRegistration GetMyDelegateNodeRegistration() {
// kernel_registration有点像是Kernel的Context
TfLiteRegistration kernel_registration;
// buildin_code是op名,如Conv2D或Mean算子
kernel_registration.builtin_code = kTfLiteBuiltinDelegate;
// 这里是代理名,如GPU,Hexagon DSP之类的
kernel_registration.custom_name = "MyDelegate";
// 这里的free是对该节点的Buffer释放
kernel_registration.free = [](TfLiteContext* context, void* buffer) -> void {
delete reinterpret_cast<MyDelegate*>(buffer);
};
// 此处的Init 函数,仅用于代理的初始化,而非子图节点的初始化
// Invoke 函数将用于运行代理图
kernel_registration.init = [](TfLiteContext* context, const char* buffer,
size_t) -> void* {
// 在节点的初始化阶段中,初始化“MyDelegate”实例。
// Ps:有点KernelContext那个意思
const TfLiteDelegateParams* delegate_params =
reinterpret_cast<const TfLiteDelegateParams*>(buffer);
MyDelegate* my_delegate = new MyDelegate;
if (!my_delegate->Init(context, params)) {
return nullptr;
}
return my_delegate;
};
// 俄罗斯套娃:套了实际的kernel计算
kernel_registration.invoke = [](TfLiteContext* context,
TfLiteNode* node) -> TfLiteStatus {
MyDelegate* kernel = reinterpret_cast<MyDelegate*>(node->user_data);
return kernel->Invoke(context, node);
};
// 同上
kernel_registration.prepare = [](TfLiteContext* context,
TfLiteNode* node) -> TfLiteStatus {
MyDelegate* kernel = reinterpret_cast<MyDelegate*>(node->user_data);
return kernel->Prepare(context, node);
};
return kernel_registration;
}
// 下面这里有意思了
// 实现 TfLiteDelegate 方法
TfLiteStatus DelegatePrepare(TfLiteContext* context, TfLiteDelegate* delegate) {
// 评估可被代理的节点,并用代理kernel替换原Graph
// 当我们需要获取头节点的大小时,保留一个节点。
std::vector<int> supported_nodes(1);
TfLiteIntArray* plan;
TF_LITE_ENSURE_STATUS(context->GetExecutionPlan(context, &plan));
TfLiteNode* node;
TfLiteRegistration* registration;
for (int node_index : TfLiteIntArrayView(plan)) {
TF_LITE_ENSURE_STATUS(context->GetNodeAndRegistration(
context, node_index, &node, ®istration));
if (MyDelegate::SupportedOp(registration)) {
supported_nodes.push_back(node_index);
}
}
// 设置替换所有节点的头节点。
supported_nodes[0] = supported_nodes.size() - 1;
TfLiteRegistration my_delegate_kernel_registration =
GetMyDelegateNodeRegistration();
// 该返回值将图分割为子图块,对于子图,它将被代理视为一个
// ‘my_delegate_kernel_registration’进行处理。
return context->ReplaceNodeSubsetsWithDelegateKernels(
context, my_delegate_kernel_registration,
reinterpret_cast<TfLiteIntArray*>(supported_nodes.data()), delegate);
}
void FreeBufferHandle(TfLiteContext* context, TfLiteDelegate* delegate,
TfLiteBufferHandle* handle) {
// 用于实现释放内存的方法。
}
TfLiteStatus CopyToBufferHandle(TfLiteContext* context,
TfLiteDelegate* delegate,
TfLiteBufferHandle buffer_handle,
TfLiteTensor* tensor) {
// 若有所需,复制 tensor(张量)的数据至代理的缓冲区。
return kTfLiteOk;
}
TfLiteStatus CopyFromBufferHandle(TfLiteContext* context,
TfLiteDelegate* delegate,
TfLiteBufferHandle buffer_handle,
TfLiteTensor* tensor) {
// 从代理的缓冲区存入数据至 tensor 的原始内存区域。
return kTfLiteOk;
}
// 回调函数获取返回指针的所有权。
TfLiteDelegate* CreateMyDelegate() {
TfLiteDelegate* delegate = new TfLiteDelegate;
delegate->data_ = nullptr;
delegate->flags = kTfLiteDelegateFlagsNone;
delegate->Prepare = &DelegatePrepare;
// 该项不可为空。
delegate->CopyFromBufferHandle = &CopyFromBufferHandle;
// 该项可为空。
delegate->CopyToBufferHandle = &CopyToBufferHandle;
// 该项可为空。
delegate->FreeBufferHandle = &FreeBufferHandle;
return delegate;
}
// 下面就是和C++ API一样了
// 即外部用户实际调用的API
// 首先添加所需调用的代理
// 并根据代理对Graph做修改,应该涉及实际执行的Kernel
auto* my_delegate = CreateMyDelegate();
if (interpreter->ModifyGraphWithDelegate(my_delegate) !=
kTfLiteOk) {
// 用于实现解决异常的方法,如走CPU实现等等
} else {
interpreter->Invoke();
}
...
// 释放代理
delete my_delegate;其实正如我前面所想,翻译原有Graph中的op为代理的实现,也需要针对该backend实现,或许如果是第三方XPU、APU、NPU之类的话,即调用其实现的过程,并做异常处理如找不到其实现退回其CPU实现。
另外, 这些关于第三方XPU的集成,Paddle-Lite算是集成华为NPU最早的,MACE、MNN也有自己的集成方案,有时间也可以去看看并作对比。
3. TensorFlow LIte 的 GPU 代理

图 TensorFlow Lite的Demo展示安卓 GPU 推理
没说安卓的其他设备,而是 GPU 作为委托代理的一个经典示例,是因为 GPU 其三个优点:
- GPU适合完成高吞吐量的大规模并行工作;
- 16 位浮点计算,GPU可获得最佳的性能;
- 能源效率高。在完成和 CPU 一样的任务时可以消耗更少的电力和产生更少的热量。
TFLite在端侧 GPU 推理的支持方面,最早便支持了 OpenGL 的推理,在2020年5月中旬,基于委托代理方式也支持了 OpenCL 。
4. GPU委托代理对模型和算子的支持情况
注:数据来自文档,有一定滞后性。
目前TFLite GPU 支持的模型主要是CV类的:
1, MobileNetv1(224x224):图像份额里;
2. DeepLab(257x257):图像分割;
3. MobileNet SSD:物体检测;
4. PoseNet:姿势估计。
支持的算子有19个(忽略版本v1、v2),其中:
- 性能算子5个:CONV\_2D 、DEPTHWISE\_CONV\_2D、FULLY\_CONNECTED 、TRANSPOSE\_CONV 、MUL;
- 逐元素操作2个:ADD、SUB ;
- 经典算子2个:MAX\_POOL\_2D、AVERAGE\_POOL\_2D;
- 非线性5个:LOGISTIC 、PRELU、RELU、RELU6、SOFTMAX;
- 变换4个:CONCATENATION、RESHAPE、 RESIZE\_BILINEAR、PAD;
- 其它1个:STRIDED\_SLICE。
当模型执行到 GPU 不支持的算子时,会切到 CPU 上运行并同时给出警告WARNING: op code #42 cannot be handled by this delegate.,这个过程会有内存拷贝开销。因此,针对算子支持的情况,也有如下的优化建议,其实下面建议也不仅限于GPU,其它后端也是适用的:
- CPU 上的看起来不怎么耗时的操作由 GPU 计算可能带会慢得爆炸,比方多种输入维度的 reshape 操作,像 BATCH\_TO\_SPACE, SPACE\_TO\_BATCH, SPACE\_TO\_DEPTH 等,若没啥必要则需要移除。
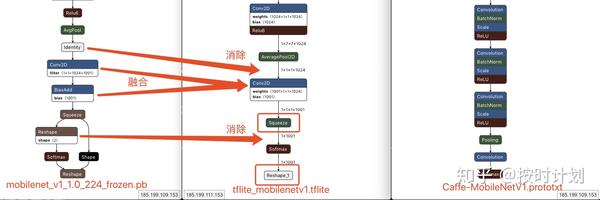
图 分别是MobileNetV1的TensorFlow原始模型、TFLite模型、Caffe模型可视化
这点上 TensorFlow MobileNetV1和V2的共同结构(见上图,分别是MobileNetV1的TensorFlow原始模型、TFLite模型、Caffe模型可视化)就是模型最后有conv2d->squeeze2->reshape2->softmax->reshape2结构。其中squeeze2和reshape2的来回折腾,实际在Netron里可视化对于维度并没有什么本质上的变化,反而因此引入了3个算子耗时。完全可以在端侧部署的时候优化掉。Caffe的MobileNetV1结构是没有reshape2和squeeze2操作的,其实在做端侧框架性能调研时,源自不同训练框架的模型会有不同,结合本身推理框架的底层实现上,对性能可能有不小的影响;
- 在 GPU 上,张量数据被分成4个通道。因此,计算一个 [B,H,W,5] 的张量和计算 [B,H,W,8]的效果是一样的,但是它们都比运行 [B,H,W,4] 的性能要差的多。这是因为 OpenCL 主要分两种数据 Layout ,Buffer 和 Image2D,而后者能用上L1 cache,性能理论上来说要比 Buffer 的形式要好。但是,以 Image2D 的RGBA形式来说,其最后一个通道的长度是 4,即RGBA四个值,是固定的,如果大于4,需要考虑重新排布,而且计算逻辑上也要重新设计为适应排布的方式。
- 从这个意义上讲,如果相机硬件支持 RGBA 形式图像帧,不需要做数据重排以适应 GPU 的预处理,直接交给 GPU 来算就好;
- 性能与网络架构设计的关系。需要基于移动场景做优化。
5. Android C++ API 使用 GPU 代理
关于如何在TF提供的演示应用的APP里使用安卓和 iOS (metal) 的 GPU 委托代理,参考安卓使用 GPU 的委托代理和 iOS 如何使用 GPU的委托代理。
实际 APP 中,多使用 C++ API,下面以 Android 系统的 C++ API 添加 GPU 代理为例。
// 加载FlatBuffer模型
auto model = FlatBufferModel::BuildFromFile(model_path);
if (!model) return false;
// 初始化使用 GPU 代理的解释器
ops::builtin::BuiltinOpResolver op_resolver;
std::unique_ptr<Interpreter> interpreter;
InterpreterBuilder(*model, op_resolver)(&interpreter);
// 基于 GPU 代理的信息,通过解释器修改模型执行Graph
const TfLiteGpuDelegateOptions options = {
.metadata = NULL,
.compile_options = {
.precision_loss_allowed = 1, // FP16
.preferred_gl_object_type = TFLITE_GL_OBJECT_TYPE_FASTEST,
.dynamic_batch_enabled = 0, // Not fully functional yet
},
};
auto* delegate = TfLiteGpuDelegateCreate(&options);
if (interpreter->ModifyGraphWithDelegate(delegate) != kTfLiteOk) return false;
// 写入输入数据、执行推理、获取输出
WriteToInputTensor(interpreter->typed_input_tensor<float>(0));
if (interpreter->Invoke() != kTfLiteOk) return false;
ReadFromOutputTensor(interpreter->typed_output_tensor<float>(0));
// 代理资源单独释放
TfLiteGpuDelegateDelete(delegate);从TfLiteGpuDelegateCreate这个API就看出,GPU 代理是单独的接口,感觉不是很好看。
关于输入和输出这里,TFLite有个优点,用户可以直接获取opengl的纹理数据作为输入,传给TFLite解释器,避免从opengl->cpu->tflite解释器这个过程的数据拷贝,只需要将输入转换为OpenGL着色器存储缓冲区对象(SSBO)。例如,包含相机传输的GPU纹理),那么可以直接保留在GPU内存中而无需进入到CPU内存,。TFLite有提供这样的接口。
除了输入,还有输出过程,如果网络的输出采用可渲染图像的格式(例如, image style transfer的输出,那么它可以直接显示在屏幕上。关于相关转换的TFLiteAPI可以参考gpu\_advanced#android。
6. 编译带 GPU 委托代理的TFLite并在ADB环境Benchmark
6.1 编译benchmark android-armv7:ADB环境
由于历史依赖库都是v7的原因,安卓平台在实际中多为armv7。
由于TensorFlow官网文档不提供ADB Shell环境的性能测试方法,但在TensorFlow的仓库有提TFLite Model Benchmark Tool,并在readme里有写道如何使用和编译,下面以ADB shell环境交叉编译Android-ARMv7版本的TFLite,详细步骤可以见="https://github.com/tensorflow/tensorflow/tree/master/tensorflow/lite/tools/benchmark#to-buildinstallrun">readme的To build/install/run小节:
# 拉去tensorflow代码,并切到最新release分支,略
# 假设当前在tensorflow目录下
# 配置tensorflow lite的编译安装第三方等环境
# android ndk、SDK需提前装好下载好
# 其他走默认选择
./confgure
# 编译android-armv7的benchmark_model
bazel build -c opt --verbose_failures \
--config=android_arm \
tensorflow/lite/tools/benchmark:benchmark_model
# 编译android-armv8的benchmark_model
#bazel build -c opt \
--config=android_arm64 \
tensorflow/lite/tools/benchmark:benchmark_model6.2 运行benchmark:ADB环境
serial_num=<your-phone-seriral-num>
TFMODEL_PATH=<your-tflite-model-dir-on-device>
adb -s ${serial_num} shell /data/local/tmp/tflite/benchmark_model \
--graph=${TFMODEL_PATH} \
--warmup_runs=20 \
--num_runs=1000 \
--use_gpu=truebenchmark的这个tool有一些公用参数,我们能得到一些信息:
- num\_threads: int (default=1)
CPU推理线程数,没啥说的 - max\_delegated\_partitions: int (default=0, i.e. no limit)
The maximum number of partitions that will be delegated. 我的理解是委托代理的最大子图个数;
当前支持GPU, Hexagon, CoreML和NNAPI的委托代理; - min\_nodes\_per\_partition: int (default=delegate's own choice)
最小委托硬件代理执行的子图所包含的节点个数,负值或0表示使用硬件委托代理的默认设置,该参数目前只支持Hexagon和CoreML的硬件委托子图代理执行。
该benchmark工具除提供共用参数外,也针对特定硬件的代理如GPU,有对应的参数:
- use\_gpu: bool (default=false)
是否使用GPU加速器代理,目前只适用于Android和iOS设备; - gpu\_precision\_loss\_allowed: bool (default=true)
是否允许精度损失,即是否能用FP16实现的gpu kernel来做运算,端侧GPU的FP16计算Kernel的性能非常好; - gpu\_experimental\_enable\_quant: bool (default=true)
GPU代理要运行的是否是一个量化的模型,目前该选项只针对Android设备; - gpu\_backend: string (default="")
迫使GPU硬件委托去运行某个特定的后端,因为TFLite的GPU后端有gl也有cl,参数值为cl、gl。默认情况下,GPU代理会先尝试执行CL,失败后悔执行GL。这是否说cl的通用性、计算效率比gl更好呢?同样,目前该设置仅适用于android设备; - gpu\_wait\_type: string (default="")
选择哪一种GPU等待类型,有如下参数:passive、active、do\_not\_wait、aggressive,默认为passive。仅适用于iOS的GPU设备。
下面是刚那个ADB shell命令的执行log,我讲摘录关键部分,并结合TFLite Delegate Registrar的说明,做内容上的补充:
# 的确是和API的名字一样,对原模型Graph做了修改
# 使用了GPU,另外是高性能的fp16推理,即FP16对应android C++的option设置
Max number of delegated partitions : [0]
Use gpu : [1]
Allow lower precision in gpu : [1]
# 这里看到在初始化TFLite的运行时
# 创建GPU的委托代理并找到squeeze这个算子不支持GPU
# 还记得我前文说的嘛,squeeze2->reshape2这些模型尾巴没啥意义
# 但看来是TFLite没有优化完
INFO: Initialized TensorFlow Lite runtime.
INFO: Created TensorFlow Lite delegate for GPU.
ERROR: Next operations are not supported by GPU delegate:
SQUEEZE: Operation is not supported.
First 29 operations will run on the GPU, and the remaining 2 on the CPU.
# 初始化的是OpenCL的API
# 并使用了gpu-opencl这个委托代理
INFO: Initialized OpenCL-based API.
Applied GPU delegate.
# 最后是性能,mobielnetv1,1000次均值12ms
# 相比mace、mnn的性能都差不多
Running benchmark for at least 1000 iterations and at least 1 seconds but terminate if exceeding 150 seconds.
count=1000 first=14341 curr=14632 min=7771 max=20203 avg=12198.5 std=2614除GPU外,TFLite Delegate Utilies for Tooling还有NNAPI、Hexagon、XNNPACK、CoreML的委托代理。
其实委托代理对Delegate的翻译听起来就比较别扭,更准确的说法,如GPU可能是“委托Mali GPU硬件,去代理子图执行”,更合适一些。
参考
- TensorFlow Lite 代理 | tensorflow.google.cn
- TFLite Model Benchmark Tool
- TFLite Delegate Utilities for Tooling | github.com/tensorflow/tensorflow
作者文章推荐:
- 端侧推理引擎Tengine初识:安卓平台交叉编译并跑通MobileNetV1
- PaddleLite底层在backend上的kernel选择策略
- 阿里轻量级的深度神经网络推理引擎MNN
- TensorFlow Lite概述:转换器、解释器、XLA和2019年路线图
欢迎关注公众号,关注模型压缩、低比特量化、移动端推理加速优化、部署。
获取更多嵌入式AI文章内容,请关注嵌入式AI专栏。


