关键词:LLM 定制,RTL 设计,VHDL 设计,LLM as a Judge,高性能处理器设计生产力

本文内容,主要来自官方文档的整合翻译与理解,涉及到的文档是《Blitz Course to TensorIR》,对TensorIR的实现与优化这部分介绍的Schedule是TensorIR的(这部分内容来自mlc.ai),Schedule Primitive这部分介绍的Schedule是Tensor Expression的,二者在Schedule上有一定共性。因为涉及到的官方文档中的概念与例程比较简...

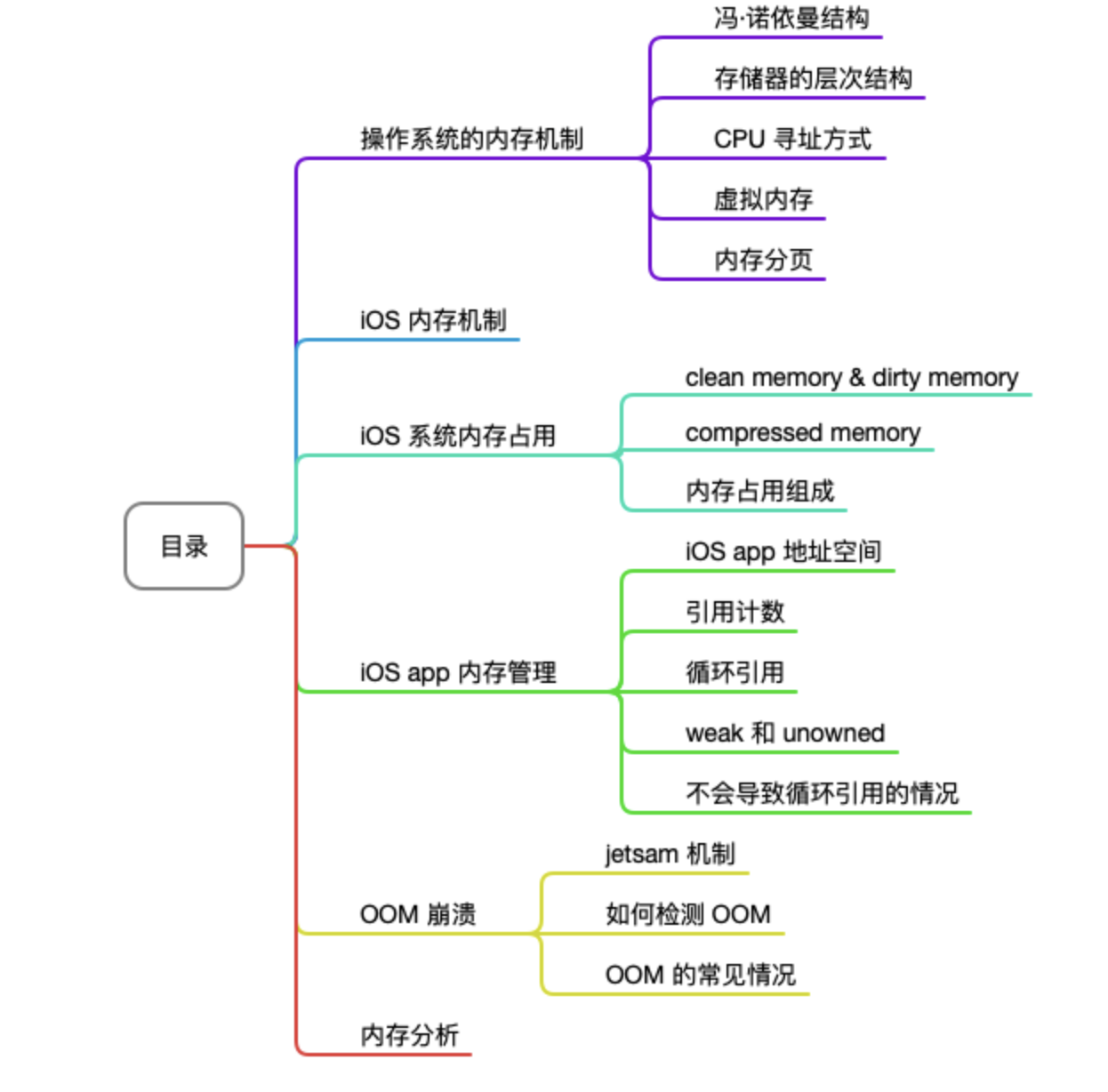
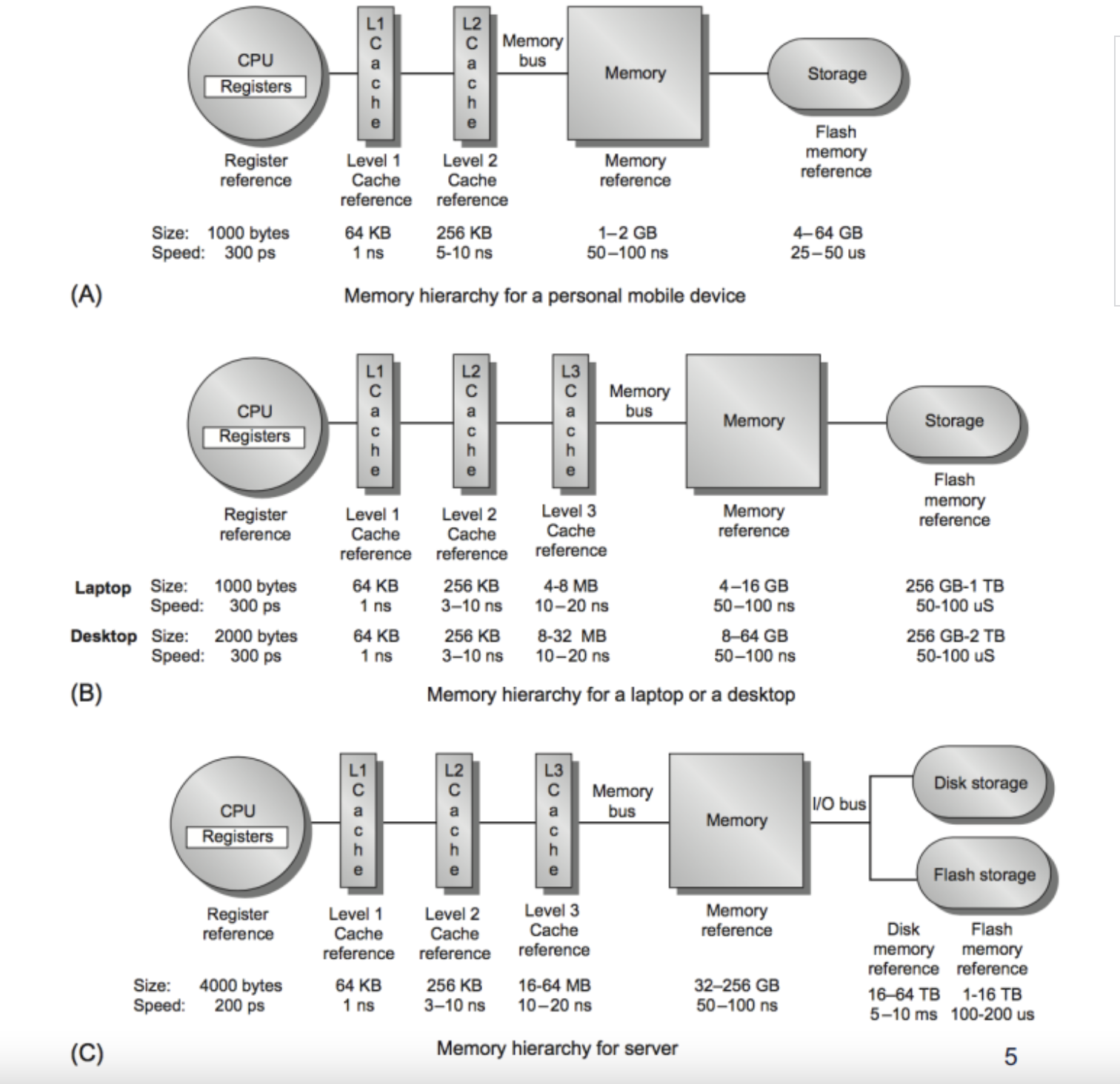
本文以 iOS Memory 的相关内容作为主题,主要从一般操作系统的内存管理、iOS 系统内存、app 内存管理等三个层面进行了介绍,主要内容的目录如下:
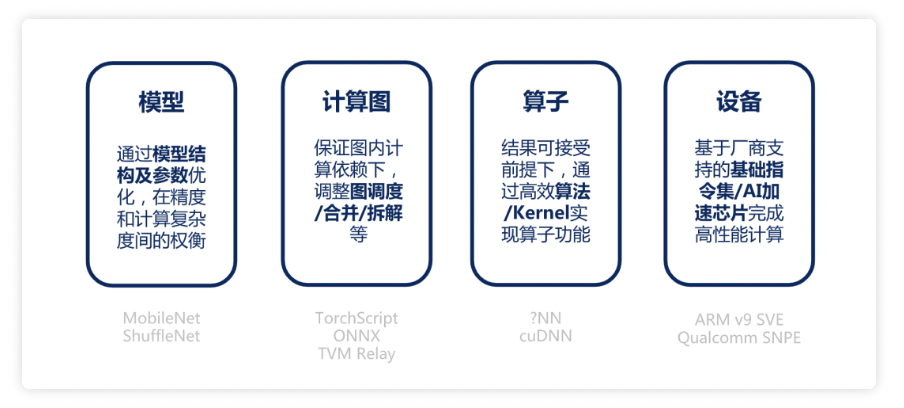
编者荐语:比较新颖的一点,可伸缩建模,实现对终端设备算力的精细化挖掘,即实现更细粒度的机型定制化适配,不过看来目前还处于探索之中,类似的,文末有字节和快手的相关方案文章。另外是与淘系开源框架MNN的关系,xNN是支付宝闭源的,二者无关。🙋🏻♀️ 编者按:蚂蚁端智能诉求可以追溯到 2017 年的支付宝新春扫福活动...
本文转载自知乎([链接]),作者凉风([链接]),是一位GPGPU/NPU方面的从业者,目前聚焦于AI编译器的工作,欢迎大家关注。注:对原文做了一些修改和补充。
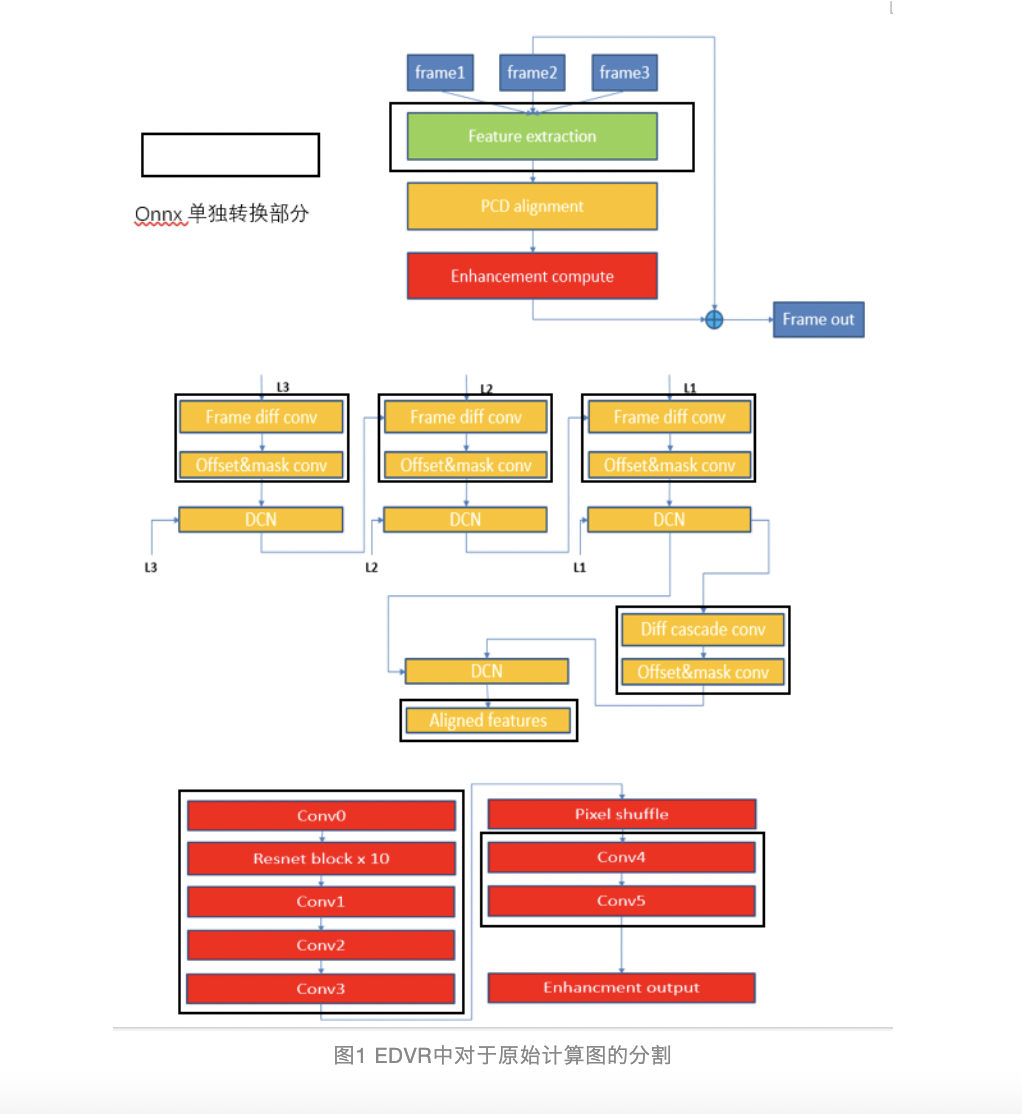
本文是对Bring Your Own Codegen to Deep Learning Compiler的文章解读,内容结合TVM Conf视频和相关slides。部分内容的关键节点,会参考TVM里的代码进行简要分析。代码分析部分难免出错,如有错误还望指出,非常感谢。深度学习的应用落地,体现在在不同硬件加速器上的部署,以支持快速高效的任务推理。通常来说,每个硬...

编者荐语:为了进一步提高模型推理性能,爱奇艺对TensorRT底层机制做了详细的解析。如何对复杂模型推理进行TensorRT的格式转换。以及TensorRT的int8量化推理内部机制,以及如何更好提升视频推理中int8量化模型的推理精度。以下文章来源于爱奇艺技术产品团队 ,作者深度学习平台团队
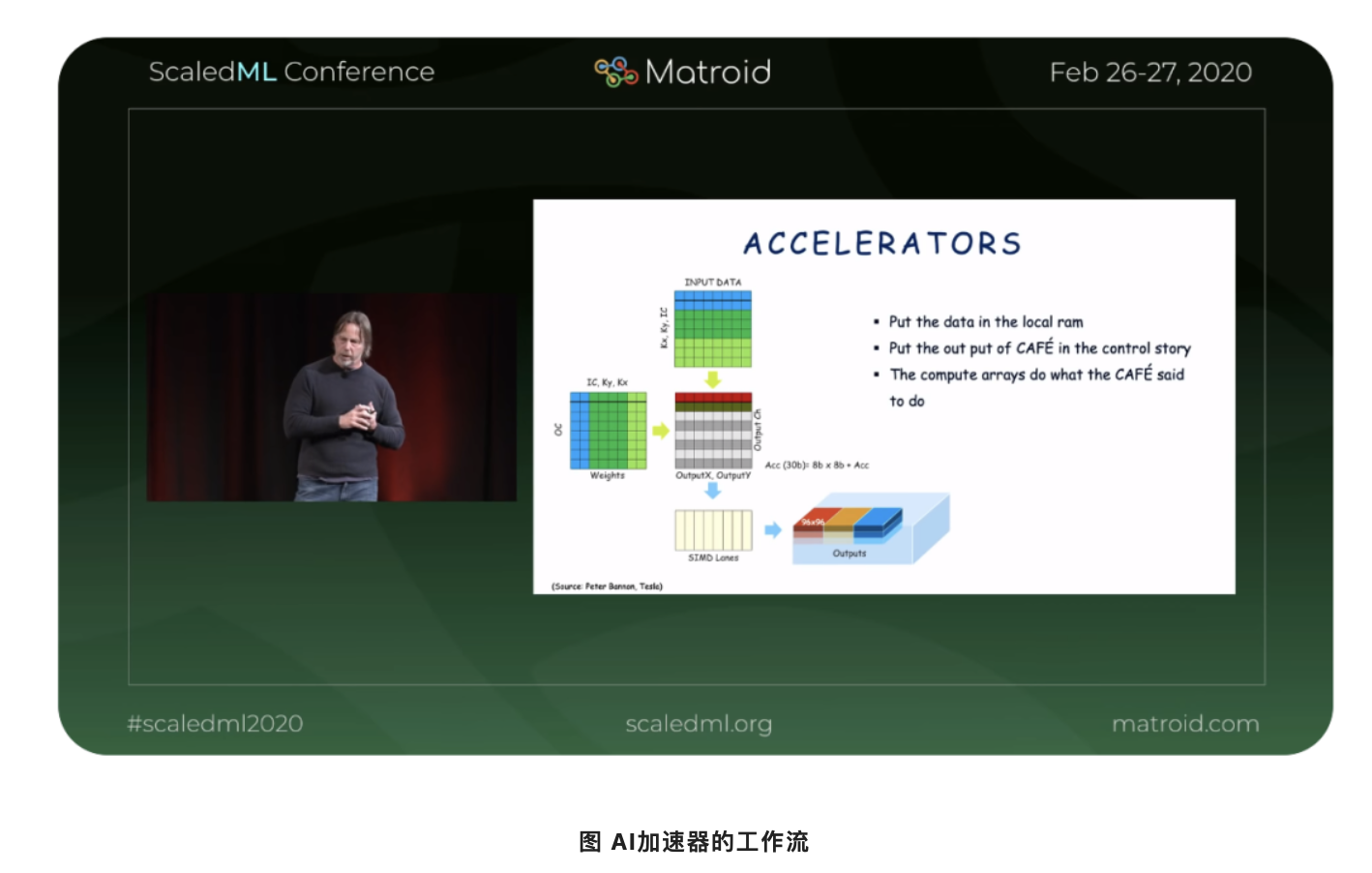
过去这一年,无论是初创公司还是成熟大厂,预告、发布和部署人工智能(AI)和机器学习(ML)加速器的步伐很缓慢。但这并非不合理,对于许多发布加速器报告的公司来说,他们花三到四年的时间研究、分析、设计、验证和对加速器设计的权衡,并构建对加速器进行编程的技术堆栈。对于那些已发布升级版本加速器的公司来说,虽...

编者荐语:OPPO机器学习团队于Nvidia GTC 2022会议分享,其GPU推理在NLP场景推理加速技术的演进历程包含:TensorFlow推理引擎、TVM编译优化、Model Structure优化、Nvidia生态优化、Subgraph优化。以下文章来源于OPPO数智技术,作者OPPO数智技术

编者荐语:一套轻量级AI算法模型,需要结合移动端硬件特性,差异化优化前馈推理库,让算法模型、推理库、硬件成为一体,使得视频云转码移动端化成为可能。本文将分享ZEGO在产品架构、移动端视频转码、移动端智能视频处理、四位一体网络模型设计上的思考。以下文章来源于LiveVideoStack,作者李凯

小红书技术团队基于 LarC 机器学习框架根据用户行为中的规律,找出用户感兴趣的内容并推荐。LarC 项目启动于 2019 年,逐渐落地到搜索、推荐、广告等领域,并已实现平台化,能力涵盖从底层基础设施到计算框架、资源调度、离线应用及在线部署。

high_service从集群服务调度、服务架构优化、模型推理加速等多个维度,构建了一整套解决方案,解决了流量波动导致的资源分配困难的问题,提高了服务的吞吐(QPS)和GPU利用率。

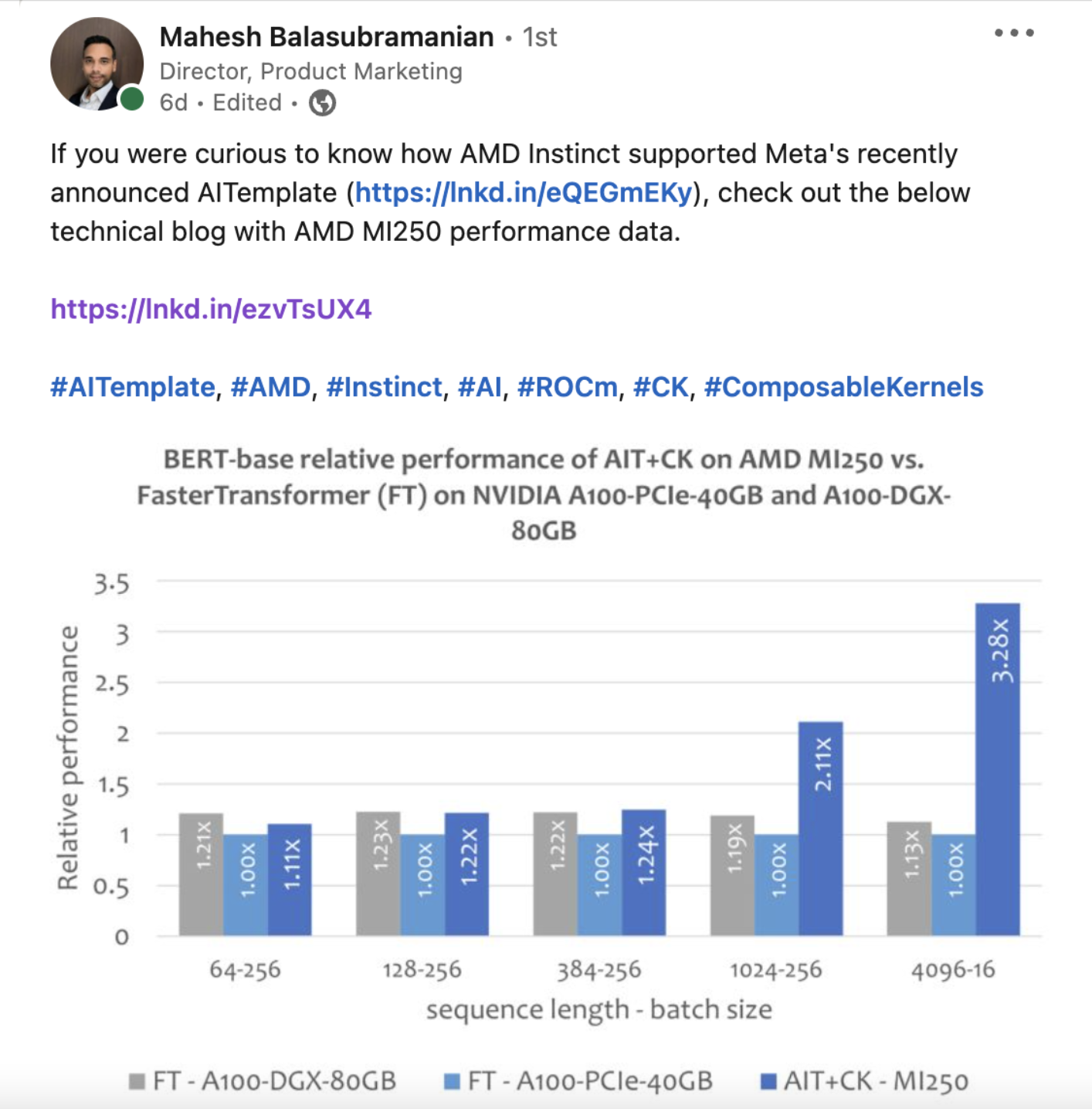
Composable Kernel(CK)库旨在提供一套在AMD GPU 上算子融合的后端方案,该研究希望未来能够移植到 AMD 的所有 GPU 上,并且最终也可以被移植到 AMD CPU 上,该项目已开源。
作者是一位AI编译器从业者,谈一谈工作以来对AI芯片软硬件协同、AI编译软件栈、TVM/MLIR的泛泛看法。作者主页:[链接],欢迎关注~共同交流AI编译相关的内容。
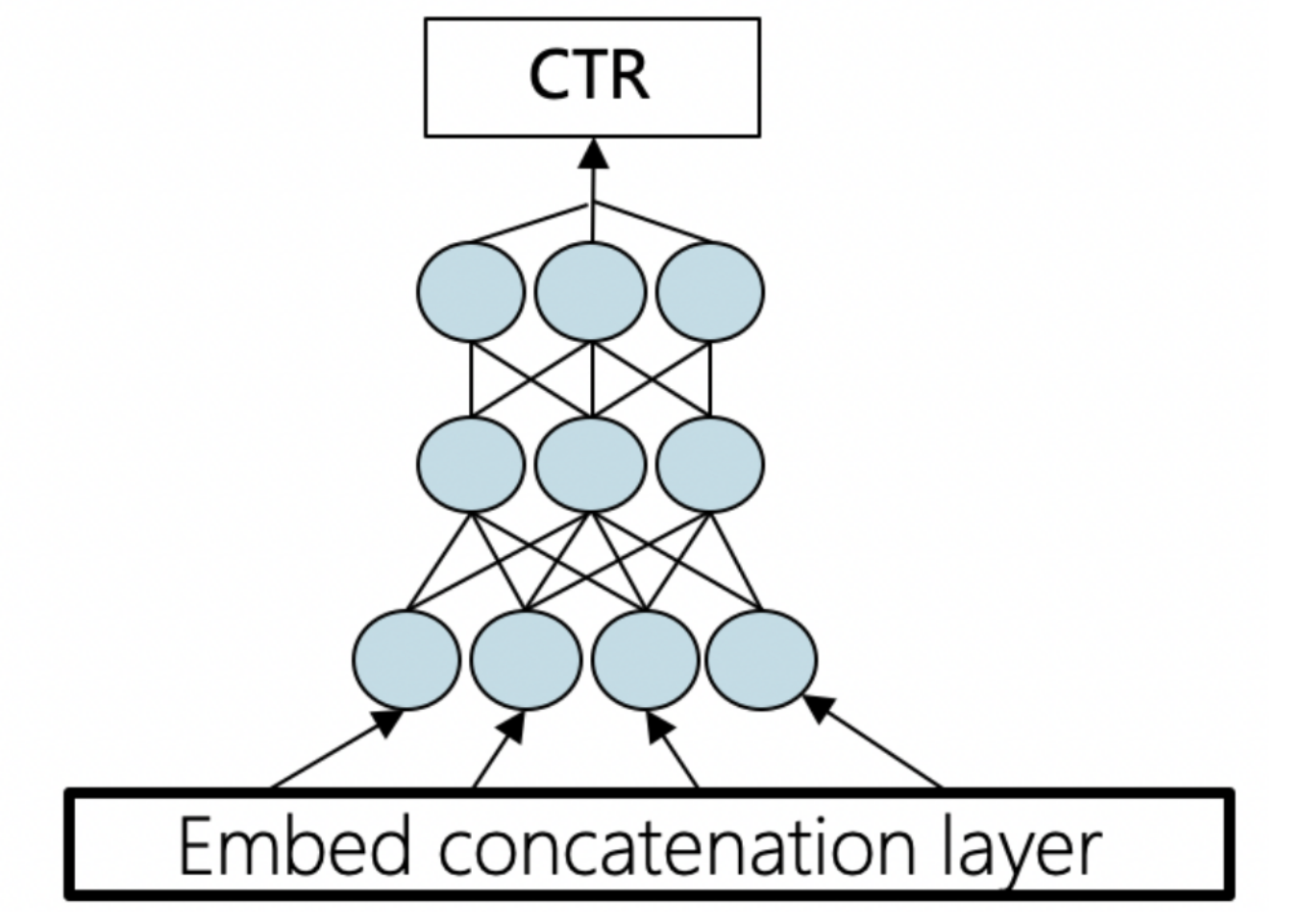
编者荐语:Paddlebox设计之初就开始潜心研究GPU分布式训练技术,以应对大规模离散模型的训练任务,在丰富的广告推荐业务驱动下,推出了业内首创的异构参数服务器,支持多种场景而且可以极大地提升硬件资源利用率,具有极高的性价比。
编者荐语:TMAM将各种CPU资源进行分类,通过不同的分类来识别使用这些资源的过程中存在瓶颈,先从大的方向确认大致的瓶颈所在,然后再进行深入分析,找到对应的瓶颈点各个击破。以下文章来源于vivo互联网技术 ,作者Li Qingxing

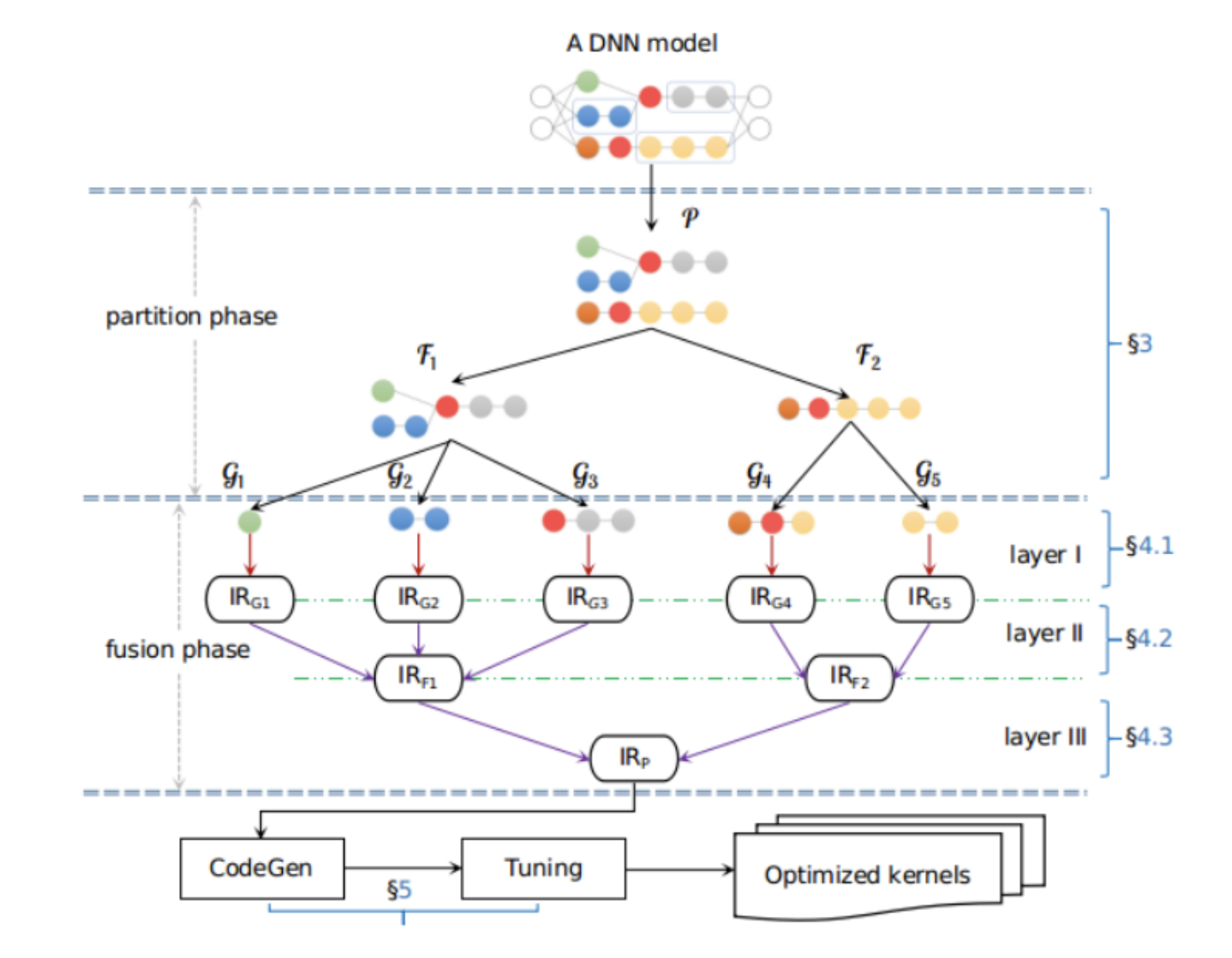
算子融合也称符算融合,作为面向DL模型推理的一种关键图优化技术,通过减少计算过程中的访存次数达到提升模型推理性能的目的,该技术在不同时期、不同框架下的落地方式各不相同。本文将首先带大家回顾算子融合技术的发展历程,并浅析其中颇有代表性的Apollo方案。
2020年8月TensorFlow Blog关于TensorFlow Lite的文章,就是提到OpenCL后端比OpenGL后端性能好,但事实真的是如此么?前几天我们刚发布有关《ShaderNN推理框架:来自OPPO的着色器深度学习推理引擎》的介绍,其GPU Kernel实现是基于OpenGL的Compute Shader(计算着色器),且性能好于TensorFlow Lite的OpenCL,也有实测的b...
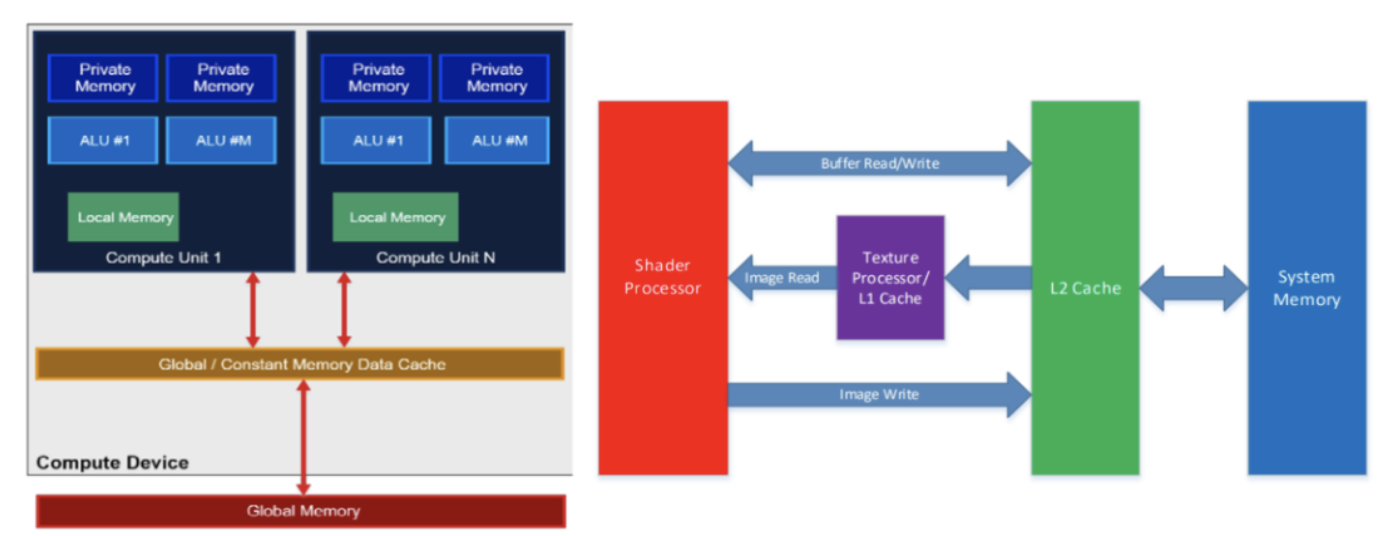
前不久,2022 OPPO开发者大会刚刚结束,OPPO在高性能异构计算领域,相较去年对于算力提升的追求,今年OPPO重点发力探索跨不同处理器的新型软件执行。比方,全部2D游戏图层渲染工作已经从GPU迁移到DSP,实现在GPU处理关键任务的同时,保证游戏的高性能运行。此外,OPPO针对目前行业存在的业务场景复杂、推理框架效率不足...

上周TFLite社区举办了一场名为《On-Device Machine Learning Solution with MediaPipe》的分享活动,分享嘉宾是来自Google MediaPipe的Jiuqiang Tang,恰巧前不久谷歌开发者大会也有相关活动对MediaPipe做了如何使用的基本介绍,本次将会从MediaPipe技术角度和最近的工作来与大家交流。MediaPipe推出已经有好几年了,先...



