
近一年各种深度学习平台和硬件层出不穷,各种xPU的功耗和面积数据也是满天飞,感觉有点乱。在这里我把我看到的一点情况做一些小结,顺便列一下可能的市场。在展开之前,我想强调的是,深度学习的应用无数,我能看到的只有能在千万级以上的设备中部署的市场,各个小众市场并不在列。
作者:djygrdzh
来源:https://zhuanlan.zhihu.com/p/32369174
深度学习目前最能落地的应用有两个方向,一个是图像识别,一个是语音识别。这两个应用可以在如下市场看到:个人终端(手机,平板),监控,家庭,汽车,机器人,服务器。
先说手机和平板。这个市场一年的出货量在30亿颗左右(含功能机),除苹果外总值300亿刀。手机主要玩家是苹果(4亿颗以下),高通(6亿颗以上),联发科(7亿颗以上,包括5亿颗功能机),三星(一亿颗以上),海思(一亿颗以上),展讯(6亿颗,包括4亿多功能机),平板总共4亿颗左右。而28纳米工艺,量很大的话(1亿颗以上),工程费用可以摊的很低,平均1平方毫米的成本是8美分左右,低端4G芯片(4核)的面积差不多是50平方毫米以下,成本就是4刀。中端芯片(8核)一般在100平方毫米左右,成本8刀。16纳米以及往上,同样的晶体管数,单位成本会到1.5倍。一般来说,手机的物料成本中,处理器芯片(含基带)价格占了1/6左右。一个物料成本90刀的手机,用的处理器一般在15刀以下,甚至只有10刀。这个10刀的芯片,包含了处理器,图形处理器,基带,图像信号处理器,每一样都是高科技的结晶,却和肯德基全家桶一个价,真是有点惨淡。然而生产成本只是一部分,人力也是很大的开销。一颗智能机芯片,软硬开发,测试,生产,就算全用的成熟IP,也不会少于300人,每人算10万刀的开销,量产周期两年,需要6000万刀。外加各种EDA工具,IP授权和开片费,芯片还没影子,1亿刀就下去了。
言归正传,手机上的应用,最直接的就是美颜相机,AR和语音助手。这些需求翻译成硬件指令就是对8位整数点乘(INT8)和16位浮点运算(FP16)的支持。具体怎么支持?曾经看到过一张图,我觉得较好的诠释了这一点:

智能手机和平板上,是安卓的天下,所有独立芯片商都必须跟着谷歌爸爸走。谷歌已经定义了Android NN作为上层接口,可以支持它的TensorFlow以及专为移动设备定义的TensorFlow Lite。而下层,针对各种不同场景,可以是CPU,GPU,DSP,也可以是硬件加速器。它们的能效比如下图:
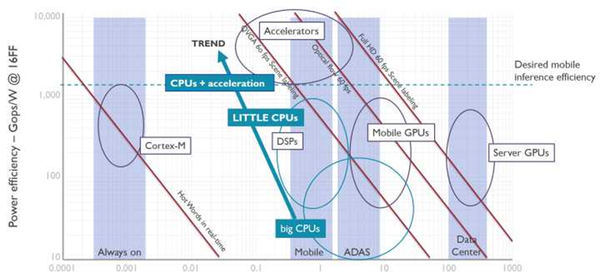
可以看到,在TSMC16纳米工艺下,大核能效比是10-100Gops/W(INT8),小核可以做到100G-1Tops/W,手机GPU是300Gops/W,而要做到1Tops/W以上,必须使用加速器。这里要指出的是,小核前端设计思想与大核完全不同,在后端实现上也使用不同的物理单元,所以看上去和大核的频率只差50%,但是在逻辑运算能效比上会差4倍以上,在向量计算中差的就更多了。
手机的长时间运行场景下,芯片整体功耗必须小于2.5瓦,分给深度学习任务的,不会超过1.5瓦。相对应的,如果做到1Tops/W,那这就是1.5T(INT8)的处理能力。对于照片识别而言,情况要好些,虽然对因为通常不需要长时间连续的处理。这时候,CPU是可以爆发然后休息的。语音识别对性能要求比较低,100Gops可以应付一般应用,用小核也足够。但有些连续的场景,比如AR环境识别,每秒会有30-60帧的图像送进来,如果不利用前后文帮助判断,CPU是没法处理的。此时,就需要GPU或者加速器上场。

上图是NVidia的神经网络加速器DLA,它只有Inference的功能。前面提到在手机上的应用,也只需要Inference来做识别,训练可以在服务端预先处理,训练好的数据下载到手机就行,识别的时候无需连接到服务端。
DLA绿色的模块形成类似于固定的流水线,上面有一个控制模块,可以用于动态分配计算单元,以适应不同的网络。稀疏矩阵压缩减少带宽,优化的矩阵算法减少计算量,外加SRAM(一个273x128, 128x128, 128x128 ,128x6 的4层INT8网络,需要70KBSRAM)。我看到的大多数加速器其实都是和它大同小异,有些加速器增加了一个SmartDMA引擎,可以通过简单计算预取所需的数据。根据我看到的一些跑分测试,这个预取模块可以把计算单元的利用率提高到90%以上。
至于能效比,我看过的加速器,在支持INT8的算法下,可以做到1.2Tops/W (1Ghz@T16FFC),1Tops/mm^2,并且正在向1.5Tops/W靠近。也就是说,1.5W可以获得2Tops(INT8)的理论计算能力。这个计算能力有多强呢?我这目前处理1080p60FPS的图像中的60x60及以上的像素大小的人脸识别,大致需要0.5Tops的计算能力,2Tops完全可以满足。当然,如果要识别复杂场景,那肯定是计算力越高越好。
为什么固定流水的能效比能做的高?ASIC的能效比远高于通用处理器已经是一个常识,更具体一些,DLA不需要指令解码,不需要指令预测,不需要乱序执行,流水线不容易因为等待数据而停顿。通常小核各个模块的动态功耗分布,计算单元只占1/3,而指令和缓存访问占了一半。
有了计算量,深度学习加速器对于带
宽的需求是多少?如果SRAM足够大,1Tops的计算量需要5GB/s以下的带宽。连接方法可以放到CPU的加速口ACP(跑在1.8GHz的Armv8.2内部总线可以提供9GB/s带宽)。只用一次的数据可以设成非共享类型,需要和CPU交换或者常用的数据使用Cacheable和Shareable类型,既可以在三级缓存分配空间,还可以更高效的做监听操作,免掉刷缓存。
不过,上述前提成立的前提是权值可以全部放到SRAM或者缓存。对于1TOPS INT8的计算量,所需权值的大小是512GB/s(有重复)。如果全部放DDR,由于手机的带宽最多也就是30GB/S,是完全不够看的。对于输入,中间值和输出数据,我在上文有个例子,一个273x128, 128x128, 128x128 ,128x6 的4层INT8网络,需要70KB的SRAM(片内)放权值,共7万个。但是输入,输出和中间结果加起来却只有535个,相对来说并不大。这里的运算量是14万次(乘和加算2次)。对于1T的运算量来说,类似。中间数据放寄存器,输出数据无关延迟,只看带宽,也够。最麻烦的就是权值,数据量大到带宽无法接受。所以只能把权值放进SRAM防止重复读取,从而免掉这500GB/s带宽。我看到的有些深度学习的算法,权值在几十到200兆,这样无论如何是塞不进SRAM的。哪怕只有10%需要读入,那也是50GB/s的带宽。虽说现在有压缩算法压缩稀疏矩阵,有论文达到30-50倍的压缩率,但我看到的实际识别算法,压缩后至少也是20MB,还是塞不进SRAM。
此外,移动端仅仅有神经网络加速器是远远不够的。比如要做到下图效果,那首先要把人体的各个细微部位精确识别,然后用各种图像算法来打磨。而目前主流图像算法和深度学习没有关系,也没看到哪个嵌入式平台上的加速器在软件上有很好的支持。目前图像算法的支持平台还主要是PC和DSP,连嵌入式GPU做的都一般。

那这个问题怎么解决?我看到两种思路:
第一种,GPU内置加速器。下图是Verisilicon的Vivante改的加速器,支持固定流水的加速器和可编程模块Vision core(类似GPU中的着色器单元),模块数目可配,可以同时支持视觉和深度学习算法。不过在这里,传统的图形单元被砍掉了,以节省功耗和面积。只留下调度器等共用单元,来做异构计算的调度。
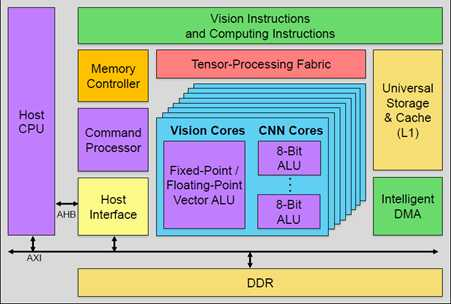
这类加速器比较适合于低端手机,自带的GPU和CPU本身并不强,可能光支持1080p的UI就已经耗尽GPU资源了,需要额外的硬件模块来完成有一定性能需求的任务。
对于中高端手机,GPU和CPU的资源在不打游戏的时候有冗余,那么就没有必要去掉图形功能,直接在GPU里面加深度学习加速器就可以,让GPU调度器统一调度,进行异构计算。

上图是某款GPU的材质计算单元,你有没有发现,其实它和神经网络加速器的流水线非常类似?都需要权值,都需要输入,都需要FP16和整数计算,还有数据压缩。所不同的是计算单元的密度,还有池化和激活。稍作改动,完全可以兼容,从而进一步节省面积。
但是话说回来,据我了解,目前安卓手机上各种图像,视频和视觉的应用,80%其实都是用CPU在处理。而谷歌的Android NN,默认也是调用CPU汇编。当然,手机芯片自带的ISP及其后处理,由于和芯片绑的很紧,还是能把专用硬件调动起来的。而目前的各类加速器,GPU,DSP,要想和应用真正结合,还有挺长的路要走。
终端设备上还有一个应用,AR。据说iPhone8会实现这个功能,如果是的话,那么估计继2015的VR/AR,2016的DL,2017的NB-IOT之后,2018年又要回锅炒这个了。
那AR到底用到哪些技术?我了解的如下,先是用深度传感器得到场景深度信息,然后结合摄像头拍到的2维场景,针对某些特定目标(比如桌子,面部)构建出一个真实世界的三维物体。这其中需要用到图像识别来帮助判断物体,还需要确定物体边界。有了真实物体的三维坐标,就可以把所需要渲染的虚拟对象,贴在真实物体上。然后再把摄像头拍到的整个场景作为材质,贴到背景图层,最后把所有这些图层输出到GPU或者硬件合成器,合成最终输出。这其中还需要判断光源,把光照计算渲染到虚拟物体上。这里每一步的计算量有多大?
首先是深度信息计算。获取深度信息目前有三个方法,双目摄像头,结构光传感器还有TOF。他们分别是根据光学图像差异,编码后的红外光模板和反射模板差异,以及光脉冲飞行时间来的得到深度信息。第一个的缺点是需要两个摄像头之间有一定距离并且对室内光线亮度有要求,第二个需要大量计算并且室外效果不佳,第三个方案镜头成本较高。据说苹果会用结构光方案,主要场景是室内,避免了缺点。结构光传感器的成本在2-3刀之间,也是可以接受的。而对于计算力的要求,最基本的是对比两个经过伪随机编码处理过的发射模板以及接受模板,计算出长度差,然后用矩阵倒推平移距离,从而得到深度信息。这可以用专用模块来处理,我看到单芯片的解决方案,720p60FPS的处理能力,需要20GFLOPS FP32的计算量以上。换成CPU,就是8核。当然,我们完全可以先识别出目标物体,用图像算法计算出轮廓,还可以降低深度图的精度(通常不需要很精确),从而大大降低计算量。而识别本身的计算量前文已经给出,计算轮廓是经典的图像处理手段,针对特定区域的话计算量非常小,1-2个核就可以搞定。
接下去是根据深度图,计算真实物体的三维坐标,并输出给GPU。这个其实就是GPU渲染的第一阶段的工作,称作顶点计算。在移动设备上,这部分通常只占GPU总计算量的10%,后面的像素计算才是大头。产生虚拟物体的坐标也在这块,同样也很轻松。
接下去是生成背景材质,包括产生minimap等。这个也很快,没什么计算量,把摄像头传过来的原始图像放到内存,告诉GPU就行。
稍微麻烦一些的是计算虚拟物体的光照。背景贴图的光照不需要计算,使用原图中的就可以。而虚拟物体需要从背景贴图抽取亮度和物体方向,还要计算光源方向。我还没有见过好的算法,不过有个取巧,就是生成一个光源,给一定角度从上往下照,如果对AR要求不高也凑合了。
其他的渲染部分,和VR有些类似,什么ATW啊,Front Buffer啊,都可以用上,但是不用也没事,毕竟不是4K120FPS的要求。总之,AR如果做的不那么复杂,对CPU和GPU的性能要求并不高,搞个图像识别模块,再多1-2个核做别的足矣。
如果加速器在GPU上,那么还是得用传统的ACE口,一方面提高带宽,一方面与GPU的核交换数据在内部进行,当然,与CPU的交互必然会慢一些。

在使用安卓的终端设备上,深度学习可以用CPU/DSP/GPU,也可以是加速器,但不管用哪个,一定要跟紧谷歌爸爸。谷歌以后会使用Vulkan
Compute来替代OpenCL,使用Vulkan 来替代OpenGL ES,做安卓GPU开发的同学可以早点开始学习。
第二个市场是家庭,包括机顶盒/家庭网关(4亿颗以下),数字电视(3亿颗以下),电视盒子(1亿以下)三大块。整个市场出货量在7亿片,电器里面的MCU并没有计算在内。这个市场公司比较散,MStar/海思/博通/Marvell/Amlogic都在里面,小公司更是无数。如果没有特殊要求,拿平板的芯片配个wifi就可以用。当然,中高端的对画质还是有要求,MTK现在的利润从手机移到了电视芯片,屏幕显示这块有独到的技术。很多机顶盒的网络连接也不是以太网,而是同轴电缆等,这种场合也得专门的芯片。
最近,这个市场里又多了一个智能音箱,各大互联网公司又拿出当年追求手机入口的热情来布局,好不热闹。主要玩家如下:

其中,亚马逊和谷歌占大头,芯片均采用Arm Cortex-A小核做控制器,DSP做图像和语音处理的方式。其中,DSP的运算能力在10Gops的INT8 MAC左右,并不高,价格却不便宜,大于20美金。在芯片内部,DSP的主要作用还是回声消除,去噪,语音识别等。自然语言理解和神经网络计算并不是在设备端,而是在云端。在国内,百度和科大讯飞提供SDK甚至模块,不过还是需要连到云端才能启用完整功能。在芯片方面,国内有些公司已经发布了一些带深度学习加速器的芯片,并集成语音处理模块和内存颗粒。未来这类芯片会更多,而软件平台,或者说语义处理到地方在云端还是终端,会成为争夺的焦点。
对于语音设别,如果是需要做自然语言理解,性能可能要到100Gops。对于无风扇设计引入的3瓦功耗限制,CPU/DSP和加速器都可以选。不过工艺就得用28纳米了或者更早的了,毕竟没那么多量,撑不起16纳米。最便宜的方案,可以使用RISC-V+DLA,没有生态系统绑定的情况下最省成本。
家庭电子设备里还有一个成员,游戏机。Xbox和PS每年出货量均在千万级别。VR/AR和人体识别早已经用在其中。
接下去是监控市场。监控市场上的图像识别是迄今为止深度学习最硬的需求。监控芯片市场本身并不大,有1亿颗以上的量,销售额20亿刀左右。主流公司有安霸,德州仪器和海思,外加几个小公司,OEM自己做芯片的也有。
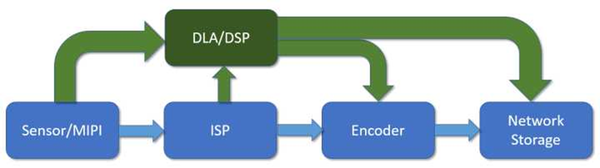
传统的监控芯片数据流如上图蓝色部分,从传感器进来,经过图像信号处理单元,然后送给视频编码器编码,最后从网络输出。如果要对图像内容进行识别,那可以从传感器直接拿原始数据,或者从ISP拿处理过的图像,然后进行识别。中高端的监控芯片中还会有个DSP,做一些后处理和识别的工作。现在深度学习加速器进来,其实和DSP是有些冲突的。以前的一些经典应用,比如车牌识别等,DSP其实就已经做得很好了。如果要做识别以外的一些图像算法,这颗DSP还是得在通路上,并不能被替代。并且,DSP对传统算法的软件库支持要好得多。这样,DSP替换不掉,额外增加处理单元在成本上就是一个问题。
对于某些低功耗的场景,我看到有人在走另外一条路。那就是完全扔掉DSP,放弃存储和传输视频及图像,加入加速器,只把特征信息和数据通过NB-IOT上传。这样整个芯片功耗可以控制在500毫瓦之下。整个系统结合传感器,只在探测到有物体经过的时候打开,平时都处于几毫瓦的待机状态。在供电上,采用太阳能电池,100mmx100mm的面板,输出功率可以有几瓦。不过这个产品目前应用领域还很小众。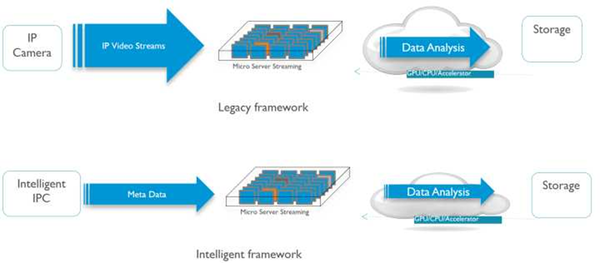
做识别的另一个途径是在局端。如果用显卡做,GFX1080的FP32 GLOPS是9T,180瓦,1.7Ghz,16纳米,320mm。而一个Mali G72MP32提供1T FP32的GFLOPS,16纳米,850Mhz,8瓦,9T的话就是72瓦,666mm。当然,如果G72设计成跑在1.7Ghz,我相信不会比180瓦低。此外桌面GPU由于是Immediate rendering的,带宽大,但对缓存没有很大需求,所以移动端的GPU面积反而大很多,但相对的,它对于带宽需求小很多,相应的功耗少很多。

GPU是拿来做训练的,而视频识别只需要做Inference,如果用固定流水的加速器,按照NVIDIA Tesla P40的数据,48T INT8 TOPS,使用固定流水加速器,在16nm上只需要48mm。48Tops对应的识别能力是96路1080p60fps,96路1080p60fps视频解码器对应的面积差不多是
50mm,加上SRAM啥的,估计200mm以下。如果有一千万的量,那芯片成本可以做到40美金以下(假定良率还可以,不然路数得设计的小一点),而一块Tesla P40板子的售价是500美金(包括DDR颗粒),还算暴利。国内现在不少小公司拿到了投资在做这块的芯片。
第四个市场是机器人/无人机。机器人本身有多少量我没有数据,手机和平板的芯片也能用在这个领域。无人机的话全球一年在200万左右,做视觉处理的芯片也应该是这个量级。。用到的识别模块目前看还是DSP和CPU为主,因为DSP还可以做很多图像算法,和监控类似。这个市场对于ISP和深度信息的需求较高,双摄和结构光都可以用来算深度计算,上文提过就不再展开。
在无人机上做ISP和视觉处理,除了要更高的清晰度和实时性外,还比消费电子多了一个要求,容错。无人机的定位都靠视觉,如果给出的数据错误或者模块无反应都不符合预期。解决这个问题很简单,一是增加各种片内存储的ECC和内建自检,二是设两个同样功能的模块,错开时钟输入以避免时钟信号引起的问题,然后输出再等相同周期,同步到一个时钟。如果两个结果不一致,那就做特殊处理,避免扩散数据错误。
第五个市场是汽车,整个汽车芯片市场近300亿刀,玩家众多:
在汽车电子上,深度学习的应用就是ADAS了。在ADAS里面,语音和视觉从技术角度和前几个市场差别不大,只是容错这个需求进一步系统化,形成Function Safety,整个软硬件系统都需要过认证,才容易卖到前装市场。Function Safety比之前的ECC/BIST/Lock Step更进一步,需要对整个芯片和系统软件提供详细的测试代码和文档,分析在各类场景下的错误处理机制,连编译器都需要过认证。认证本身分为ASIL到A-ASIL-D四个等级,最高等级要求系统错误率小于1%。我对于这个认证并不清楚,不过国内很多手机和平板芯片用于后装市场的ADAS,提供语音报警,出货量也是过百万的。

最后放一张Arm的ADAS参考设计框图。
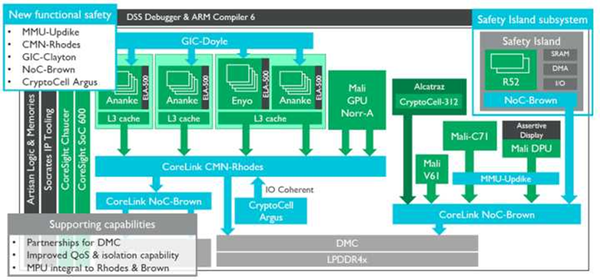
可能不会有人照着这个去设计ADAS芯片,不过有几处可以借鉴:
右方是安全岛,内涵Lock Step的双Cortex-R52,这是为了能够保证在左边所有模块失效的情况下复位整个系统或者进行异常中断处理的。中部蓝色和绿色的CryptoCell模块是对整个系统运行的数据进行保护,防止恶意窃取的。关于Trustzone设计我以前的文章有完整介绍这里就不展开了。
以上几个市场基本都是Inference的需求,其中大部分是对原有产品的升级,只有ADAS,智能音箱和服务器端的视频识别检测是新的市场。其中智能音箱达到了千万级别,其它的两个还都在扩张。
接下去的服务端的训练硬件,可以用于训练的移动端GPU每个计算核心面积是1.5mm(TSMC16nm),跑在1Ghz的时候能效比是300Gops/W。其他系统级的性能数据我就没有了。虽然这个市场很热,NVidia的股票也因此很贵,但是我了解到全球用于深度学习训练的GPU销售额,一年只有1亿刀不到。想要分一杯羹,可能前景并没有想象的那么好。
最近970发布,果然上了寒武纪。不过2T ops FP16的性能倒是挺高。我倒推了下这在16nm上可能是6mm的面积,A73MP4+A53MP4(不含二级缓存)也就是这点大小。麒麟芯片其实非常强调面积成本,而在高端特性上这么舍得花面积,可见海思要在高端机上走出自己的特色之路的决心,值得称道。不过寒武纪既然是个跑指令的通用处理器,那除了深度学习的计算,很多其他场合也能用上,比如ISP后处理,计算结构光深度信息等等,能效可能比DSP还高些。
推荐阅读
授权转自知乎,欢迎关注Arm攒机指南专栏,后续还有AI等相关篇章。

