
作者:Xiaohang Zhan
文章首发知乎:https://zhuanlan.zhihu.com/p/150224914
自监督学习的流行是势在必然的。在各种主流有监督学习任务都做到很成熟之后,数据成了最重要的瓶颈。从无标注数据中学习有效信息一直是一个很重要的研究课题,其中自监督学习提供了非常丰富的想象空间。
如何定义自监督学习?
自监督学习是指用于机器学习的标注(ground truth)源于数据本身,而非来自人工标注。如下图,自监督学习首先属于无监督学习,因此其学习的目标无需人工标注。其次,目前的自监督学习领域可大致分为两个分支。第一个是用于解决特定任务的自监督学习,例如上次讨论的场景去遮挡,以及自监督的深度估计、光流估计、图像关联点匹配等。另一个分支则用于表征学习。有监督的表征学习,一个典型的例子是ImageNet分类。而无监督的表征学习中,最主要的方法则是自监督学习。典型的方法包括:解决Jigsaw Puzzles、运动传播、旋转预测,以及最近很火的MoCo等等。当然还有其他分类方法,比如根据数据也可以分为video / image / language的自监督学习。本文主要讨论image上的自监督学习。
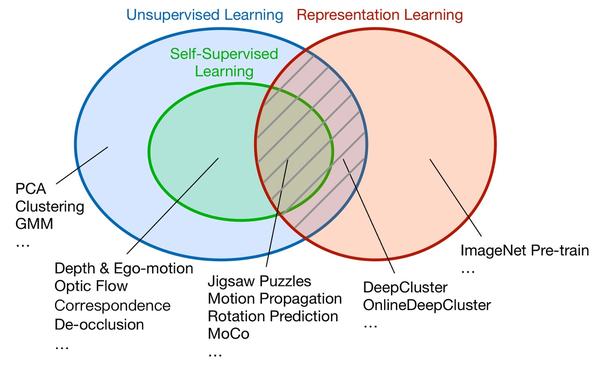
图1,自监督学习和其他学习类型的关系
判断一个工作是否属于自监督学习,除了无需人工标注这个标准之外,还有一个重要标准,就是是否学到了新的知识。举个简单的例子,例如image inpainting是否属于自监督学习?如果一篇image inpainting的论文,其主要目的是提升inpainting的效果,那么它就不属于自监督学习,虽然它无需额外标注。但是如果它的目的是借助inpainting这个任务来学习图像的特征表达,那么它就是自监督学习(参考论文:Context Encoders [1])。如下图,以自监督表征学习为例,我们通常需要设计一个自监督的proxy task,我们期望在解决这个proxy task的过程中,CNN能学到一些图像高级的语义信息。然后我们将训练好的CNN迁移到其他目标任务,例如图像语义分割、物体检测等等。

图2,典型的自监督表征学习流程
那么,自监督的proxy task有哪些呢?如下图举了一些有代表性的例子,第一行中的思路是将图像以某种方式破坏,然后用神经网络来学习恢复原图的过程,期望在此过程中能学到一些图像语义信息。然而,将图像破坏,可能带来预训练的domain和目标任务domain不一致的问题。第二行中的proxy tasks则代表了无需破坏原图的自监督任务。第三行中的方法是利用运动信息等多模态信息来学习图像特征。当然除了图中这些例子之外,还有各种各样其他有趣的自监督任务。

图3,自监督proxy tasks的例子
为什么自监督学习能学到新信息 ?
1. 先验
我们的世界是在严格的物理、生物规则下运行的,那么对这个世界的观测结果(图像)也必然存在一些先验规律。例如图像上色任务,就是利用了物体类别和物体颜色分布之间的关联;image inpainting,则是利用了物体类别和形状纹理之间的关联;旋转预测任务,利用了物体类别和其朝向之间的关联。通过挖掘更多的先验,我们也能设计自己的自监督学习任务。
那么什么样的先验更有效呢?结论是,低熵的先验。如下图,左边的运动预测任务(ICCV 2015: Dense Optical Flow Prediction From a Static Image [2]) ,是从单张图片中直接预测运动场,其利用的先验是物体的运动倾向性。而运动倾向性是比较歧义的,例如人在半蹲状态,难以预测下一时刻会站起来还是继续下蹲。因而,运动倾向性是一个高熵的先验。而右图的运动传播任务(CVPR 2019: Self-Supervised Learning via Conditional Motion Propagation [3]),从给定的稀疏运动来恢复完整运动场,利用的则是物体的运动学属性先验。运动学属性,例如头部是刚体,四肢是铰接体等,是较为确定的先验,那么这就是一个低熵的先验。从实验结果也可以发现,在transfer到分割任务上,运动传播比运动预测更好。

图4,运动预测和运动传播的对比
2. 连贯性
图片具有空间连贯性,视频具有时空连贯性。那么就可以利用这些特点来设计自监督任务。如下图,Solving Jigsaw Puzzles [4] 利用图片中物体空间上的语义连贯性,Temporal order verification [5]任务利用了视频中物体运动的时间连贯性。

图五,利用数据空间、时间连贯性的自监督任务
3. 数据内部结构
目前很火的基于contrastive learning的方法,包括NPID, MoCo, SimCLR等,我们可以将它们统一为instance discrimination [6]任务。如下图,这类任务通常对图片做各种变换,然后优化目标是同一张图片的不同变换在特征空间中尽量接近,不同图片在特征空间中尽量远离。
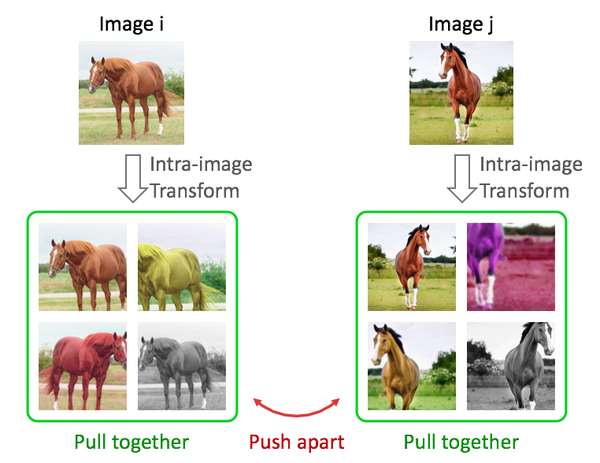
图6,instance discrimination任务
对于这类任务,下图假设了两种可能的优化后的特征空间。这两种结果都是符合instance discrimination优化目标的,即同一张图片的不同变换在特征空间中尽量接近,不同图片在特征空间中尽量远离。然而,我们发现,实际的优化结果更偏向于第二种而非第一种,也就是说,虽然我们在解决instance discrimination的过程中并没有用的物体的类别标签,但是在优化后的特征空间中,同类的物体还是相对能够靠拢。这就证明了,数据之间是具有结构性和关联性的。Instance discrimination则是巧妙地利用了这种结构性和关联性。类似地,最近的BYOL [7]也可能是利用了数据在特征空间中的分布结构特点来抛弃负样本对(个人理解)。
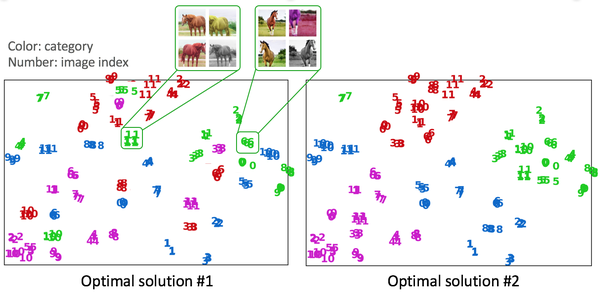
图7,instance discrimination的两种可能的优化后的特征空间
设计一个自监督学习任务还需要考虑什么?
- 捷径(shortcuts)
以jigsaw puzzles为例,如下图,如果我们让划分的patch之间紧密挨着,那么神经网络只需要判断patch的边缘是否具有连续性,就可以判断patch的相对位置,而不需要学到高级的物体语义信息。这就是一种捷径,我们在设计任务的过程中需要避免这样的捷径。

图8,解决jigsaw puzzles时,patch之间不能紧密挨着
对于这种捷径,处理的方式也很简单,我们只需要让patch之间产生一些随机的间隔就行,如下图。

图9,让patch之间产生随机间隔
Solving jigsaw puzzles的其他捷径还包括色差、彗差、畸变、暗角等可以指示patch在图像中的相对位置的信息。解决方案除了想办法消除这些畸变外,还可以让patch尽量靠近图像中心。
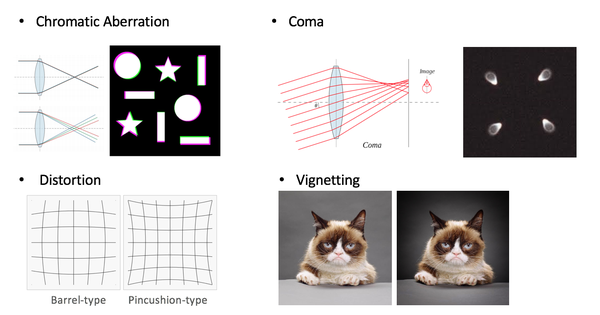
图10,色差、彗差、畸变、暗角等可利用的捷径
2. 歧义性(Ambiguity)
大多数利用先验来设计的自监督任务都会面临歧义性问题。例如colorization中,一种物体的颜色可能是多种多样的,那么从灰度图恢复颜色这个过程就具有ambiguity;再例如在rotation prediction中,有的物体并没有一个通常的朝向(例如俯拍放在桌上的圆盘子)。有不少已有工作在专门解决特定任务的歧义性问题,例如CVPR 2019的Self-Supervised Representation Learning by Rotation Feature Decoupling。另外就是设计低熵的先验,因为低熵的先验也具有较低的歧义性。
3. 任务难度

图11,solving jigsaw puzzles中的不同难度
神经网络就像一个小孩,如果给他太简单的任务,他学不到有用的知识,如果给他太难的任务,他可能直接就放弃了。设计合理的难度也是一个需要考虑的方面。
展望
我们的世界是在严格的物理学、化学、生物学规则下运行的,视觉信号是这些内在规则的外在反映,而深度学习,正好非常擅长处理高维的视觉信号。所以,无监督、自监督学习的存在和发展是必然的,因为世界本身就是有序的、低熵的,这使得数据本身就已经包含了丰富的信息。自监督学习看似神奇,但理解了其本质之后,也就会觉得是情理之中了。当然,目前学术界对自监督学习的理解程度,可能也只是九牛一毛而已。未来会走向什么方向,谁也说不准。目前是基于数据之间的结构的instance discrimination处于state-of-the-art,未来,基于priors的方法更胜一筹也是有可能的。所以,千万不要受限于一类方法,不要让自监督学习变成了调参游戏,自监督领域的想象空间其实非常大。
最后,这个总结主要基于自己的思考,也许不一定非常到位,权当抛砖引玉。希望大家都能够设计出有趣又有用的自监督学习任务,为这个领域添砖加瓦。
References:
- Pathak, Deepak, et al. "Context encoders: Feature learning by inpainting."_Proceedings of the IEEE conference on computer vision and pattern recognition_. 2016.
- Walker, Jacob, Abhinav Gupta, and Martial Hebert. "Dense optical flow prediction from a static image."_Proceedings of the IEEE International Conference on Computer Vision_. 2015.
- Zhan, Xiaohang, et al. "Self-supervised learning via conditional motion propagation." _Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition_. 2019.
- Noroozi, Mehdi, and Paolo Favaro. "Unsupervised learning of visual representations by solving jigsaw puzzles."_European Conference on Computer Vision_. Springer, Cham, 2016.
- Misra, Ishan, C. Lawrence Zitnick, and Martial Hebert. "Shuffle and learn: unsupervised learning using temporal order verification."_European Conference on Computer Vision_. Springer, Cham, 2016.
- Wu, Zhirong, et al. "Unsupervised feature learning via non-parametric instance discrimination."_Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition_. 2018.
- Grill, Jean-Bastien, et al. "Bootstrap Your Own Latent: A New Approach to Self-Supervised Learning."_arXiv preprint arXiv:2006.07733_(2020).
推荐阅读:
欢迎关注我 ,我是 Xiaohang~

