
作者:nihui
转自:知乎
本文模型结构使用 netron visualizer 截图展示,支持 onnx 和 ncnn 模型的可视化
pytorch 模型导出成 onnx 模型时,经常会遇到某些简单的操作,被替换为一堆琐碎的op
onnx-simplifier 可以简化网络结构
https://github.com/daquexian/onnx-simplifiergithub.com
但有时候会遇到无法简化的情况,或者因某些原因坏掉无法使用
ncnn 的模型转换工具 onnx2ncnn 本身也有常用的自动合并功能,并不断增加中
比如最新转换工具已经支持 torch.nn.functional.normalize -> Normalize
这是onnx的 x = nn.functional.normalize(x)

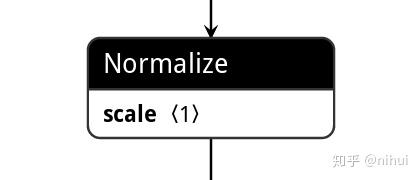
这是通过onnx2ncnn转换后的Normalize
但有时候,还是会遇到无法简化的情况,导致转换时报告很多op不支持
Unsupported Upsample/Resize scales !
Shape not supported yet!
Gather not supported yet!
# axis=0
Unsupported unsqueeze axes !
Unsupported unsqueeze axes !
Unsupported unsqueeze axes !
Unsupported unsqueeze axes !
Shape not supported yet!
Gather not supported yet!
# axis=0
Cast not supported yet!
# to=1
Cast not supported yet!
# to=1
Shape not supported yet!
Gather not supported yet!
# axis=0
Cast not supported yet!
# to=1
Cast not supported yet!
# to=1
Unsupported unsqueeze axes !
Unsupported unsqueeze axes !
Cast not supported yet!
# to=7
Unsupported Upsample/Resize scales !这时候怎么办呢?
这里,我用两个例子给大家介绍,手工合并优化ncnn模型的方法
将那些不支持的op替换为ncnn支持的op
举个例子,这个模型中有个 reshape 和 resize,转换时报错不支持
ncnn param 开头的 layer count 和 blob count 分别为 100 200
手工处理reshape例子
输入 [1,512]
输出 [1,512,1,1]
这是onnx的 x = x.view(x.size(0), -1, 1, 1)

这是通过onnx2ncnn转换后的reshape

Split splitncnn_49 1 2 1370 1370_splitncnn_0 1370_splitncnn_1
Shape 1423 1 1 1370_splitncnn_1 1423
Gather 1424 1 1 1423 1424
ExpandDims 1428 1 1 1424 1428 -23303=1,0
ExpandDims 1429 0 1 1429 -23303=1,0
ExpandDims 1430 0 1 1430 -23303=1,0
ExpandDims 1431 0 1 1431 -23303=1,0
Concat 1432 4 1 1428 1429 1430 1431 1432 0=-1
Reshape 1433 2 1 1370_splitncnn_0 1432 1433因为我知道 1370 的shape一定是 [1,512],1433 的shape一定是 [1,512,1,1]
我只需要用 Reshape w=1 h=1 c=512 参数就可以实现这个过程了
参照 ncnn src/layer/reshape.cpp 读参数的顺序,0就是w,1就是h,2就是c
Reshape 1433 1 1 1370 1433 0=1 1=1 2=5129个op被我换成了1个op,一共减少8行,将开头的 layer count 减去8,改写为 92 200
手工处理resize例子
输入 [1,512,1,1]
输出 [1,512,16,16]
这是onnx的 nn.Upsample(scale\_factor=16)
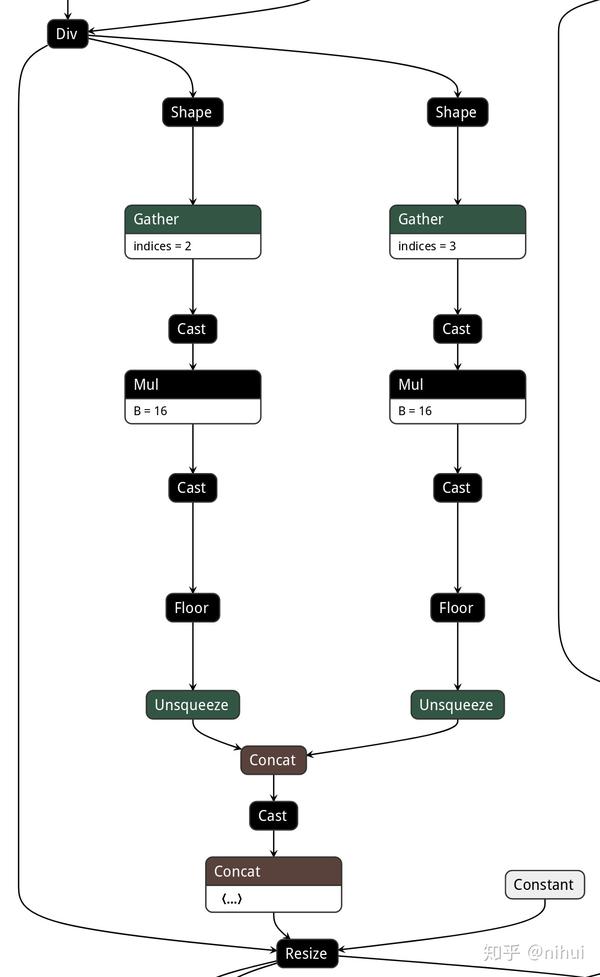
这是通过onnx2ncnn转换后的interp

Split splitncnn_54 1 3 1438 1438_splitncnn_0 1438_splitncnn_1 1438_splitncnn_2
Shape 1440 1 1 1438_splitncnn_2 1440
Gather 1441 1 1 1440 1441
Cast 1442 1 1 1441 1442
MemoryData 1443 0 1 1443 0=1
BinaryOp 1444 2 1 1442 1443 1444 0=2
Cast 1445 1 1 1444 1445
UnaryOp 1446 1 1 1445 1446 0=2
Shape 1448 1 1 1438_splitncnn_1 1448
Gather 1449 1 1 1448 1449
Cast 1450 1 1 1449 1450
MemoryData 1451 0 1 1451 0=1
BinaryOp 1452 2 1 1450 1451 1452 0=2
Cast 1453 1 1 1452 1453
UnaryOp 1454 1 1 1453 1454 0=2
ExpandDims 1455 1 1 1446 1455 -23303=1,0
ExpandDims 1456 1 1 1454 1456 -23303=1,0
Concat 1457 2 1 1455 1456 1457 0=-1
Cast 1459 1 1 1457 1459
Concat 1460 1 1 1459 1460 0=-1
Interp 1462 2 1 1438_splitncnn_0 1460 1462 0=1 1=1.000000e+00 2=1.000000e+00因为我知道 1438 的shape一定是 [1,512,1,1],1462 的shape一定是 [1,512,16,16]
我只需要用 Interp output\_height=16 output\_width=16 参数就可以实现这个过程了
参照 ncnn src/layer/interp.cpp 读参数的顺序,3就是output\_height,4就是output\_width,另外0=1表示使用nearest插值
这里要注意,改写的时候,带有weight的op(如Convolution MemoryData)是不能删除的,并且需要保留顺序,否则读bin文件会错误
MemoryData 1443 0 1 1443 0=1
MemoryData 1451 0 1 1451 0=1
Interp 1462 1 1 1438 1462 0=1 3=16 4=1621个op被我换成了3个op,一共减少18行,将开头的 layer count 再减去18,改写为 74 200
最后使用 ncnnoptimize 工具,自动将无用的 MemoryData 删除,并且会自动帮你将最终的 blob count 设置为合适的数量
$ ./ncnnoptimize model.param model.bin model-opt.param model-opt.bin 0所以前面步骤中不需要你自己改 blob count,也不用担心多出来的 MemoryData,都会帮你优化掉
Reshape 1433 1 1 1370 1433 0=1 1=1 2=512
Normalize 1438 1 1 1433 1438 1=1 2=1.000000e-12 3=1 9=1
Interp 1462 1 1 1438 1462 0=1 3=16 4=16
经过手工优化,不仅ncnn能跑模型,而且合并琐碎的op后,减少了总层数,也有加速效果
推荐阅读
更多嵌入式AI算法部署等请关注极术嵌入式AI专栏。

