
转自:知乎
作者:冈萨雷斯Tu
原文:
Data-Free Quantization Through Weight Equalization and Bias Correction
代码(目测是非官方发布,运行起来bug巨多,慎重,但是写的确实还不错):
PyTorch implementation of DFQ
导读:
这篇论文全称是《Data-Free Quantization Through Weight Equalization and Bias Correction》,来自于高通人工智能研究院,不久前被ICCV2019接收,后面简称DFQ。该论文提出了一种不需要额外数据来finetune恢复精度的离线8bit量化方法,它利用了relu函数的尺寸等价缩放的特性来调整不同channel的权重范围,并且还能纠正量化过程中引入的偏差,使用方法也很简单,只需要调用一个API就可以,该量化方法在图像分类、语义分割和目标检测中都很有效。
其实本质上这篇论文就是讲如何利用激活函数ReLU的数学性质,均衡相邻两层权重各通道的数据范围,让per-layer的量化方法能融合per-channel的优势,又不需要在硬件上承担额外开销,最大化离线量化的效果。但是论文的想法还是基于简单情况做的考虑,真正应用上的局限性还是存在的,不过总的看完感觉想法还是蛮新颖的,在一些方面具有启发性,所以还是想陈述一下自己看完后的理解。
一些概念:
通常我们用各种现有成熟的深度学习框架,如TensorFlow、Pytorch或mxnet等搭建网络模型时,参数和中间运行数据都是默认为float32类型的,然而在移动嵌入式设备上,由于内存大小、功耗等限制,直接部署原始的浮点网络是不切实际的,所以就需要对原始浮点模型进行压缩,减少参数所需的内存消耗,通常的方法有剪枝、知识蒸馏、量化、矩阵分解,其中量化方法是使用最为普遍的,因为将32bit的参数量化为8bit,需要消耗的内存直接就缩减到了原始的1/4,而其他方法针对不同任务,不同模型,在满足性能要求的情况下实际能节省多少资源都是无法保证的。
1. 8bit量化
一个32bit的浮点tensor量化为INT8(范围[0,255],也可以量化到[-128,127])只需要4步:缩放、取整、偏移和溢出保护,如下所示:

8bit量化器(来自Google量化白皮书)
最后de-quantization的操作有两个作用:计算量化误差、用于恢复精度的finetune训练
比如一个tensor的浮点范围是[-1,1],那么缩放系数就是255/2=127.5(equ. 1用的步长,和缩放系数互为倒数),缩放之后的tensor是[-127.5,127.5],取整是[-127,128],偏移是让浮点的0能够对应一个int8的整数,防止0填充出现误差,选取的时候也会尽量使得浮点最小值对应int8的0,所以这里z=127,偏移之后可以使得tensor是[0,255],溢出保护之后仍然是[0,255]。de-quantization回去的话可以看到量化的tensor恢复回来变成了[-127/127.5, 128/127.5],与原始的[-1,1]存在一些偏差,说明量化的过程是不可逆的,必定会存在量化误差,这个误差是四舍五入操作导致的。
2. 量化方案的四种境界(本文提出的)
- Level 1: 不需要额外的数据和训练操作。方法具有普适性,适合所有模型,只需要知道模型的结构和权重参数,直接离线量化就能得到很好的定点模型;
- Level 2: 需要额外的数据,但不进行训练。方法具有普适性,适合所有模型,但是需要额外数据用于校正batch normalization的统计参数如moving mean和moving variance,或者用来逐层地计算量化误差,并且根据该误差采取相应策略(如重新选择缩放系数等)来提升性能;
- Level 3: 需要额外的数据,并且用于finetune训练。方法具有普适性,适合所有模型。需要调节一些超参来寻找最优;
- Level 4: 需要额外的数据,并且用于finetune训练,但方法针对特定模型使用。这种特定模型指的是用全浮点训练收敛之后的模型进行量化效果极差,并且必须从头开始加上量化操作进行训练,这种方法需要消耗极大的时间成本。
回到这篇DFQ论文,我们分析一下他要解决的问题和作出的贡献
问题:
- 存在这样的情况:模型预训练完之后某些层的权重参数不同通道之间的数据方差很大如下图所示,利用常见的per-layer量化策略(即整个层的参数作为一个tensor进行量化),则会使得值较小的通道直接全部被置为0,导致精度的下降,per-channel的方法可以解决这个问题,但是在硬件实现上因为要针对每一个通道都有自己独立的缩放系数和偏移值考虑,会导致很多额外的开销,得不偿失;
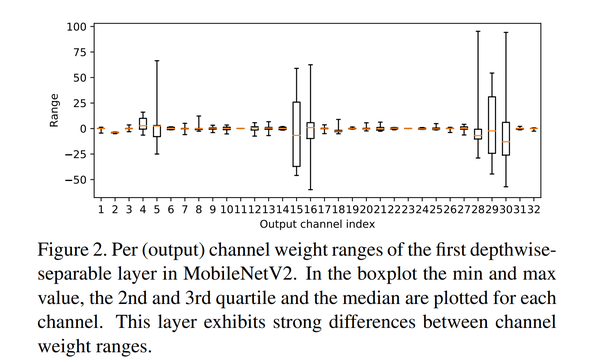
MobileNet v2
2. FP32->INT8量化过程中带来的noise是有偏误差,会导致不同模型不同程度的性能下降,目前的方法基本依赖于finetune;
解决方法:Data-Free Quantization
- 算法流程
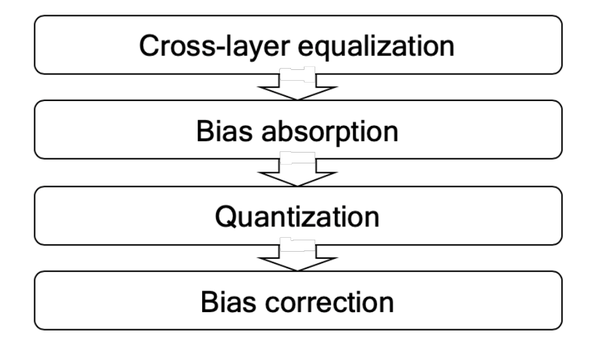
DFQ流程
- Cross-layer equalization

其中S是一个对角矩阵,对角线上的每个值是用来调整缩放系数的因子。前面讲到量化需要对参数Tensor进行缩放,如果不同通道的缩放系数差异很大的话就会导致巨大的量化误差,所以可以利用ReLU函数的缩放特性来进行上下层之间不同通道缩放系数的调整,如下所示:
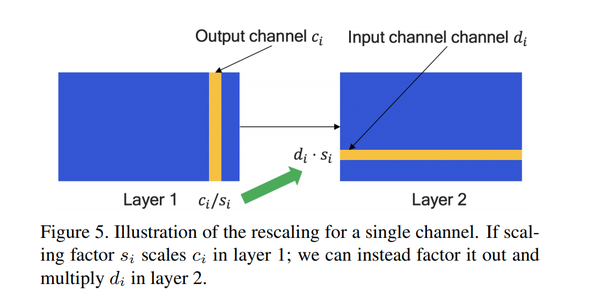
若Layer 1的weight在输出通道的range方差很大,那么可以利用上述的等价变换公式,给range大的层乘以小的系数,range小的层乘以大的系数,使得各个通道的range尽量一致,等于一个给定的范围(给定方式下面阐述),这样量化的时候整个tensor量化的误差就会最小,同时为了保证数值内部的等价,Layer 1乘完的系数,在Layer 2要除回,具体体现在Layer 1 weight的第i个输出通道乘了系数s,对应Layer 2 weight的第i个输入通道就要除以系数s,上图中的乘除关系和描述的相反,意思是相同的。

这里讲的是两层之间的range均衡,在真正的实验中是每相邻两层均衡,然后不断迭代着算下去的,可以设置一个量化误差阈值,如果把整个网络迭代完一遍之后的权重量化误差在一个预先设定的范围之内就可以停止迭代,或者设定一个最大迭代次数,达到最大次数即停止。
- Bias absorption

再具体说明一下:
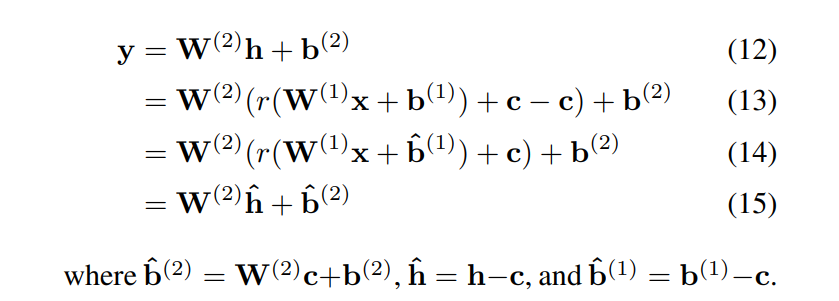

- Bias correction
本节讲述的是如何校正量化(四舍五入的不可逆性)带来的偏差。之前的研究认为量化带来的误差是无偏的,不影响输出的均值,但是本文发现权重的量化误差会导致输出的有偏误差,从而改变下一层输入数据的分布,在其他量化方法中方法中,可以直接计算activation量化前后的误差,加入loss中作为一个正则项,但是本文基于Data-Free的立场,决定继续采用网络中的已有信息(其实就是每层的权重和BN的各个参数信息),所以需要从数学形式上进行推导。

总结
具体实验结果可以看论文的Experiment,一句话描述就是量化后的效果能超过per-channel的方法,且逼近FP32的模型,更厉害的是还能推广到语义分割和目标检测等常见视觉任务上面,reviewers看完应该就没话说了。
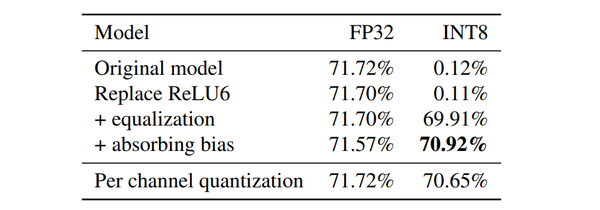
总的来说这个论文的工作很完整,从提出问题,总结前人方法和归类目前已有的方法,通过数学推导来提出自己的解决方法(而非调参),到对比实验,ablation study,最后推广到其他任务,最后的附录也是很好的,从论文的完整度写作上是非常值得借鉴的。但我感觉这篇论文还存在以下局限性:
- 论文仅仅考虑的是网络层与层之间单层连接方式(单一输入单一输出的层),对于add/concat的连接方式,即出现多输入多输出的层无法应用。论文中对于MobileNet-v2的实验也只是在block内部做的均衡,那么就是说block与block之间是相互独立的,block内部一般也就三个conv,三个之间来回迭代的效果还是存在质疑;

- 最后一个工作Bias correction,我的理解是论文通过计算上一层输出的均值,来作为本层输出的均值,那么第一层怎么处理?虽然有些网络一上来就做了规范化,均值可以认为是0,但还是有些网络对输入单纯/255,或者再加入一些例如-0.5的平移操作,虽然对于ImageNet等经典数据集,其实事先是有一个公认的均值可以拿来进行计算,但是不是又违背了Data-Free的初衷了呢?
- 每次权重均衡的迭代方式是本层权重的输出通道与下一层权重的输入通道进行一一对应的均衡,然后取最合适的范围,下一层经过本次均衡后又要基于输出通道与下下层的输入通道进行均衡,中间这层相当于经过了两次优化,经过第一次均衡之后留给下一层的优化空间还足够吗?当然来回迭代很多次有可能缓解这个问题,但是否有更好的迭代方式?如每两层之间的均衡都尽可能先满足上一层的权重各输出通道范围相似,然后最后一层单独再进行处理,这个只是一种设想。
启发
最后说说带来的启发吧,轻量级网络如MobileNet,ShuffleNet系列的直接离线量化效果其实不是很好,因为本身网络的冗余度就很低了,不像AlexNet, GoogleNet,ResNet这样巨无霸网络,说实话有些量化论文拿这些冗余网络来做对比实验真的是不要碧莲了。

目前针对轻量级网络直接量化效果差的解决办法是quantization-aware training,就是在FP32模型训练收敛之后,再加入量化的操作,继续进行finetune,这个过程还是比较耗时,且在一些情况下还需要一些调参技巧,如BN操作中的moving\_mean和moving\_variance要重新校正还是直接冻结等,且在一些深度学习框架上提供模型压缩与量化工具也是更倾向于一键直接离线量化,要加入量化训练的话还是稍微麻烦一些。所以如果有更好的离线量化方法的话,只需要给定一个FP32模型文件,就能得到一个性能不错的量化网络是最好的选择。这个论文带来的启发是直接在数学上考虑量化误差,并且利用已有的信息将误差来源大的项进行公式上的融合,比如上下层的权重逐通道范围均衡,使得每一层的权重各个通道之间的范围接近。朝着这个方法应该还可以做一些改进什么的吧。
以上就是我对本篇论文的解读和拙见,非官方复现的代码因为代码bug太多,实在debug不下去了,没能跑出相应的效果,不过最近又在偷偷更新,而且加入了很多看不懂的操作(明明Data-Free,咋还开始疯狂load数据了???)。希望有兴趣的读者读完原论文的可以私下交流一下。

推荐专栏文章
更多嵌入式AI算法部署等请关注极术嵌入式AI专栏。

