
使用Keras Tuner进行超参数调整可以将您的分类神经网络网络的准确性提高10%。
这篇文章将解释如何使用Keras Tuner和Tensorflow 2.0执行自动超参数调整,以提高计算机视觉问题的准确性。

假如您的模型正在运行并产生第一组结果。但是,它们与您期望的最高结果相去甚远。您缺少一个关键步骤:超参数调整!
在本文中,我们将逐步完成整个超参数调整流程。完整的代码可以在Github上找到。
什么是超参数调整以及为什么要注意
机器学习模型具有两种类型的参数:
- 可训练参数,由算法在训练过程中学习。例如,神经网络的权重是可训练的参数。
- 超参数,需要在启动学习过程之前进行设置。学习率或密集层中的单元数是超参数。
即使对于小型模型,超参数也可能很多。调整它们可能是真正的难题,但值得挑战:良好的超参数组合可以极大地改善模型的性能。在这里,我们将看到在一个简单的CNN模型上,它可以帮助您在测试集上获得10%的精度!
幸运的是,开放源代码库可为您自动执行此步骤!
Tensorflow 2.0和Keras Tuner
Tensorflow是一个广泛使用的开源机器学习库。Tensorflow 2.0于2019年9月发布,具有重大改进,尤其是在用户友好方面。有了这个新的版本,Keras,更高级别的Python的深度学习的API,成为Tensorflow的主要API。
不久之后,Keras团队发布了Keras Tuner,该库可轻松使用Tensorflow 2.0执行超参数调整。这篇文章将展示如何将其与应用程序一起用于对象分类。它还将包括库中可用的不同超参数调整方法的比较。
Keras Tuner现在退出测试版!v1在PyPI上不可用。https://t.co/riqnIr4auA
适用于Keras及更高版本的功能全面,可扩展,易于使用的超参数调整。pic.twitter.com/zUDISXPdBw
-弗朗索瓦CHOLLET(@fchollet)2019 10月31日,
使用Keras Tuner进行超参数调整
在深入研究代码之前,请先了解一些有关Keras Tuner的理论。它是如何工作的?
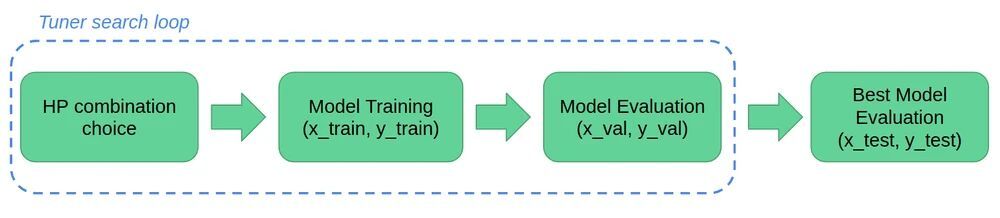
首先,定义一个调谐器。它的作用是确定应测试哪些超参数组合。库搜索功能执行迭代循环,该循环评估一定数量的超参数组合。通过在保持的验证集中计算训练模型的准确性来执行评估。
最后,就验证精度而言,最好的超参数组合可以在暂留的测试集上进行测试。
入门
让我们开始吧!通过本教程,您将拥有一条端到端管道,以调整简单卷积网络的超参数,以在CIFAR10数据集上进行对象分类。
安装步骤
首先,从终端安装Keras Tuner:

现在,您可以打开自己喜欢的IDE /文本编辑器,并在本教程的其余部分中启动Python脚本!
数据集

本教程使用CIFAR10数据集。CIFAR10是计算机视觉中常见的基准数据集。它包含10个类别,相对较小,有60000张图像。这个大小允许相对较短的训练时间,我们将利用它来执行多个超参数调整迭代。
加载和预处理数据:
调谐器期望浮点数作为输入,而除以255是数据归一化步骤。
模型建立
在这里,我们将尝试使用简单的卷积模型将每个图像分类为10个可用类之一。
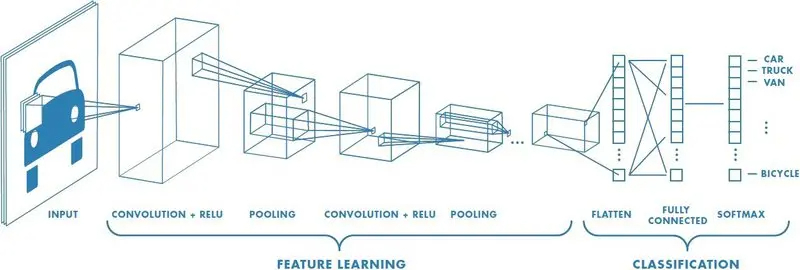
每个输入图像将经过两个卷积块(2个卷积层,后跟一个池化层)和一个Dropout层以进行正则化。最后,每个输出均被展平,并经过密集层,该密集层将图像分类为10类之一。
在Keras中,此模型可以定义如下:
搜索空间定义
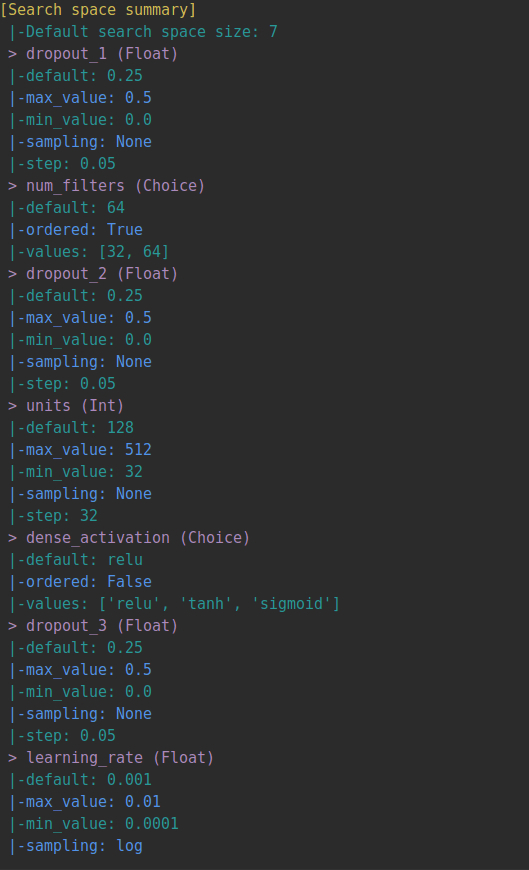
要执行超参数调整,我们需要定义搜索空间,即哪些超参数需要优化以及在什么范围内。在这里,对于这个相对较小的模型,已经有6个超参数可以调整:
- 三个Dropout层的Dropout率
- 卷积层的卷积核数
- 全连接层神经元个数
- 激活函数
在Keras Tuner中,超参数具有类型(可能是Float,Int,Boolean和Choice)和唯一名称。然后,需要设置一组帮助指导搜索的选项:
- Float和Int类型的最小值,最大值和默认值
- 选择类型的一组可能值
- (可选)线性,对数或反向对数内的采样方法。设置此参数可增加您可能对调优参数的了解。我们将在下一节中看到如何使用它来调整学习率
- 可选地,一个步长值,即两个超参数值之间的最小步长
例如,要设置超参数“过滤器数量”,您可以使用:
全连接层层具有两个超参数,神经元数量和激活函数:
模型编译
然后,让我们继续进行模型编译,其中还存在其他超参数。在编译步骤中,将定义优化器以及损失函数和度量。在这里,我们将分类熵用作损失函数,将准确性用作度量标准。对于优化器,可以使用不同的选项。我们将使用流行的亚当:
在这里,代表学习算法进展速度的学习速率通常是重要的超参数。通常,学习速度以对数刻度选择。通过设置采样方法,可以将这些先验知识合并到搜索中:
Keras Tuner超模型
为了将整个超参数搜索空间放在一起并执行超参数调整,Keras Tuners使用了“ HyperModel”实例。超模型是库引入的可重用的类对象,定义如下:
该库已经为计算机视觉提供了两个现成的超模型HyperResNet和HyperXception。
选择调谐器
Keras Tuner提供了主要的超参数调整方法:随机搜索,超频带和贝叶斯优化。
在本教程中,我们将重点介绍随机搜索和超带宽。我们不会涉及理论,但是如果您想了解有关随机搜索和贝叶斯优化的更多信息,我写了一篇有关它的文章:用于超参数调整的贝叶斯优化。至于Hyperband,其主要思想是根据搜索时间优化随机搜索。
对于每个调谐器,可以为实验可重复性定义种子参数:SEED = 1。
随机搜寻
执行超参数调整的最直观方法是随机采样超参数组合并进行测试。这正是RandomSearch调谐器的功能!
目标是优化功能。调谐器根据其值推断是最大化问题还是最小化问题。
然后,max\_trials变量代表调谐器将测试的超参数组合的数量,而execution\_per\_trial变量则是出于健壮性目的而应构建并适合于每个试验的模型数量。下一节将说明如何设置它们
超频
调谐器的超参数?
您可能想知道在整个过程中看到必须为不同的调谐器设置几个参数的有用性:
但是,这里的问题与超参数的确定略有不同。实际上,此处的这些设置将主要取决于您的计算时间和资源。您可以执行的试验次数越多越好!关于时期的数量,最好是知道模型需要收敛多少个时期。您还可以使用提前停止来防止过度拟合。
超参数调整
一旦建立了模型和调谐器,就可以轻松获得任务的摘要:
调整可以开始了!
搜索功能将训练数据和验证拆分作为输入,以执行超参数组合评估。epochs参数用于随机搜索和贝叶斯优化,以定义每种超参数组合的训练历元数。
最后,搜索结果可以归纳如下:
结果
您可以在Github上找到此结果。在RTX 2080 GPU上运行后获得以下结果:
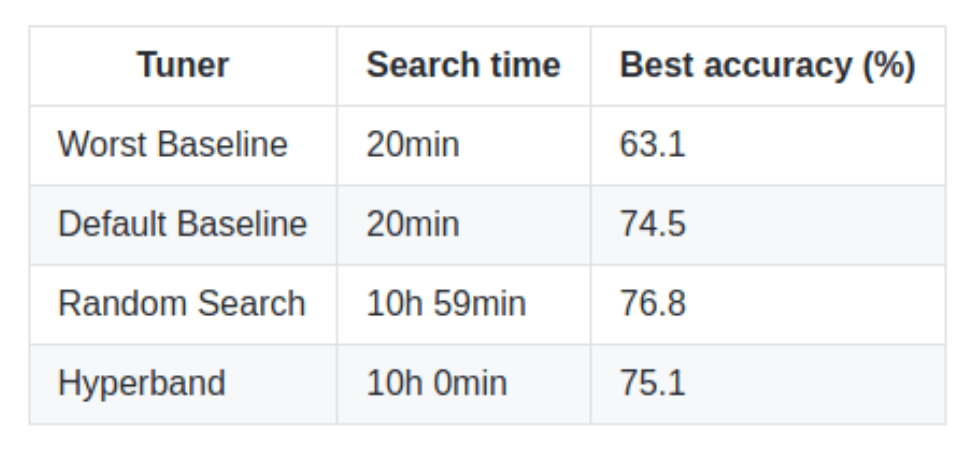
Keras Tuner结果。最差的基准:使用随机搜索的一组超参数之一实现最差的验证准确性的模型。默认基线:通过将所有超参数设置为其默认值获得。
这些结果与CIFAR10数据集上的最新模型所达到的99.3%的准确性相差甚远,但对于如此简单的网络结构而言,还算不错。您已经看到基线和调整后的模型之间有了显着的改进,在“随机搜索”和第一个基线之间的准确性提高了10%以上。
总体而言,Keras Tuner库是一个不错的易于学习的选项,可以为Keras和Tensorflow 2.O模型执行超参数调整。您必须要做的主要步骤是调整模型以适合超模型格式。实际上,该库中目前没有几个标准的超模型。
补充文档和教程可在Keras Tuner的网站及其Github存储库中找到!
- -
如果你喜欢本文的话,欢迎点赞转发!谢谢。
看完别走还有惊喜!
我精心整理了计算机/Python/机器学习/深度学习相关的2TB视频课与书籍,价值1W元。关注微信公众号“计算机与AI”,点击下方菜单即可获取网盘链接。
往期精彩链接:


