
首发:知乎
作者:糖心他爸
应朋友的委托,希望我来帮忙评估一下RV1126(RV1109)的AI性能。这两款芯片是pin2pin的,RV1109的算力为1.2Tops,RV1126的算力为2.0Tops。参与评估的网络为典型的Resnet50,模型链接: 下载链接。rv11xx的sdk是淘宝上花25 RMB买的(2020-11-24release的版本),评估板也是淘宝上淘的一块人脸识别面板机,里面用的是rv1126的soc。
还是老样子,我们将porting部署进行一下流程拆分:1、推理图优化 2、int8模型量化 3、native层性能评估业务代码。
一、推理图优化
下载下来的graph我采用netron进行了可视化,发现该graph中包含预处理op(tf中采用了element-wise op进行了组合,减均值除方差)、也包含了softmax节点(在npu中实现不是很友好,建议抽出cpu进行后处理)。预处理和softmax op的netron可视化如下图:
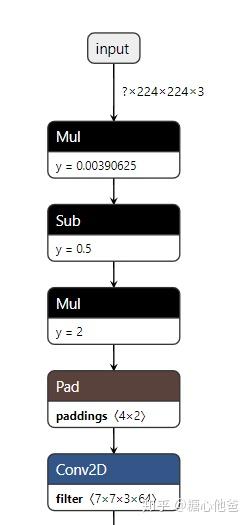
预处理sub-graph
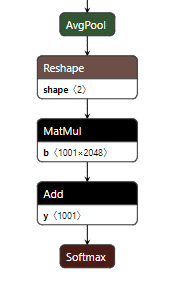
softmax输出
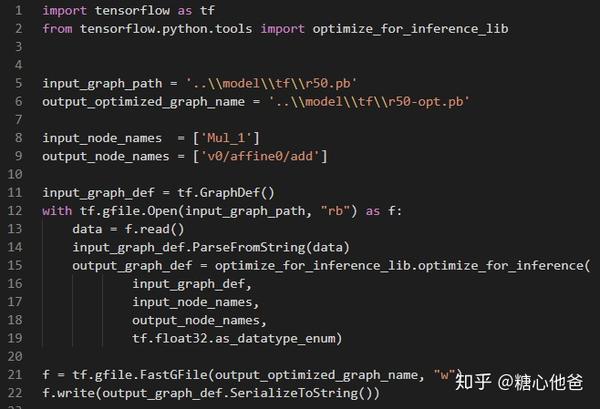
tf中提供了optimize\_for\_inference接口进行graph optimization操作,我们的优化思路很简单:即仅采用预处理之后到softmax之前的sub-graph,模型优化和裁剪的python脚本如下:
二、int8模型量化
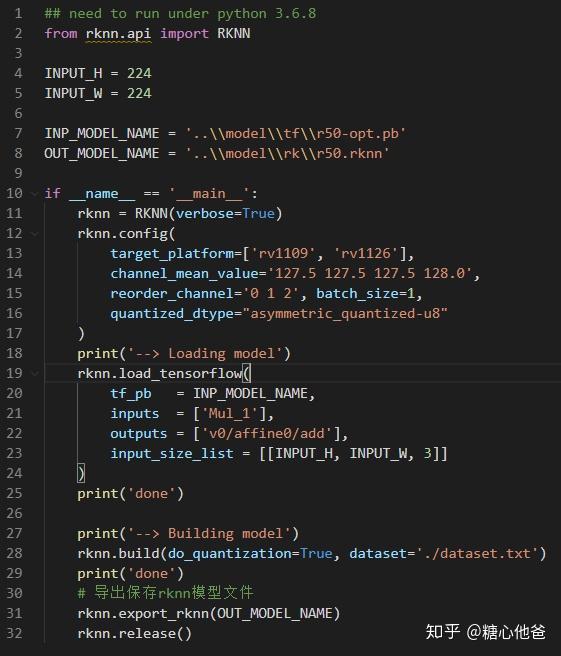
rk提供了rknn-toolkit进行模型定点化的操作,我这边的诉求只是进行inference的性能评估,其他的我就不管啦,所以直接上量化的业务代码:
三、native 层性能评估业务代码
rk提供了rknn的native api,我们只要在上位机上遵循其api调用规则进行业务代码书写就可以啦,代码的头文件和核心推理代码块我就直接贴上来啦。

推理头文件
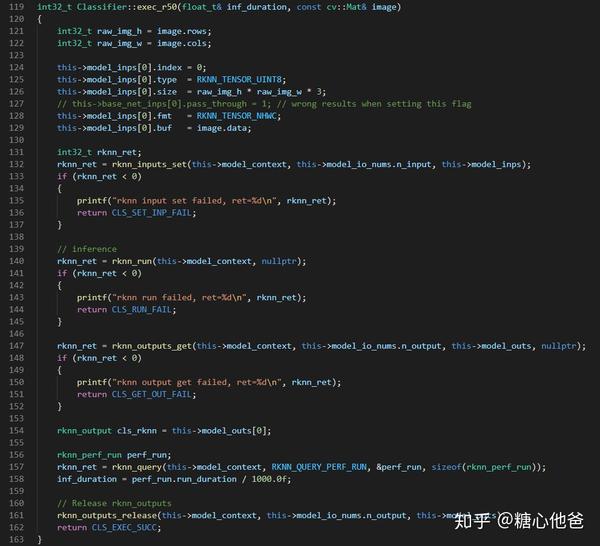
核心推理代码
最后
交叉编译后push到板子上进行了性能评估,resnet50的网络,输入为224x224,100次推理的平均耗时为25ms左右,基本跟rk提供的profile的性能文档可以对上。大家如果有感兴趣的任务或者话题,可以下方留言。欢迎大家留言、关注专栏,谢谢大家!如果需要这个项目的代码的话,可以关注下方微信公众号,然后回复rv1126-r50,我会给你发送下载链接的哈,或者在下方附件文档获取链接。
推荐阅读
专注嵌入式端的AI算法实现,欢迎关注作者微信公众号和知乎嵌入式AI算法实现专栏。
更多嵌入式AI相关的技术文章请关注极术嵌入式AI专栏

| 文件名 | 大小 | 下载次数 | 操作 |
|---|---|---|---|
| 代码链接下载 by26号AI实验室.txt | 166B | 6 | 下载 |

