
文章转载于:知乎
作者:金雪锋
最近基于MindSpore的论文逐步增多,我们后续会挑选一些好论文给大家分享一下,方便大家第一时间使用相关成果。
这篇论文是关于华为诺亚方舟实验室、北京邮电大学以及香港科技大学的研究者们提出了一个新的轻量模型范式TinyNet。相比于EfficientNet的复合放缩范式(compound scaling),通过TinyNet范式得到的模型在ImageNet上的精度要优于相似计算量(FLOPs)的EfficientNet模型。例如, TinyNet-A的Top1准确率为76.8% ,约为339M FLOPs,而EfficientNet-B0类似性能需要约387M FLOPs。另外,仅24M FLOPs 的TinyNet-E的准确率达到59.9%,比之前体量相当的MobileNetV3高约1.9%。
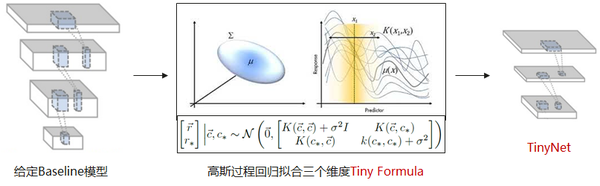
注:上图部分来源于:https://www.youtube.com/watch?v=mqOdIYxxNCs
论文链接:
https://arxiv.org/pdf/2010.14819.pdf
开源地址:
https://gitee.com/mindspore/mindspore/tree/master/model\_zoo/research/cv/tinynet
感谢林枫的供稿,感谢诺亚实验室云鹤/韩凯等专家的支持。
简介
深度卷积神经网络(CNN)在许多视觉任务中取得了很大成功。然而,如果要在移动设备上部署AI模型,我们需要持续调整网络深度(模型层数)、宽度(卷积通道的数量)和图像分辨率这些网络结构要素来优化内存使用并减少延迟。EfficientNet在模型深度,宽度,图像分辨率这三个维度复合缩放来调整神经网络结构。然而EfficientNet更多关注在如何产生大体量的模型,轻量模型的设计有待更好的发掘。
一个直接的方法是应用EfficientNet的缩放公式。例如,我们可以进一步缩小EfficientNet-B0,并得到一个具有200M FLOPs的EfficientNet-B-1。然而这种策略无法得到最有效的模型。我们随机生成了100个通过改变基线模型EfficientNet-B0的三维(模型深度,宽度,图像分辨率)得到的网络模型。这些模型的计算量小于或等于基线模型(图1)。我们发现这其中最佳模型的精度比用EfficientNet缩放公式得到的模型高出约2.5%。
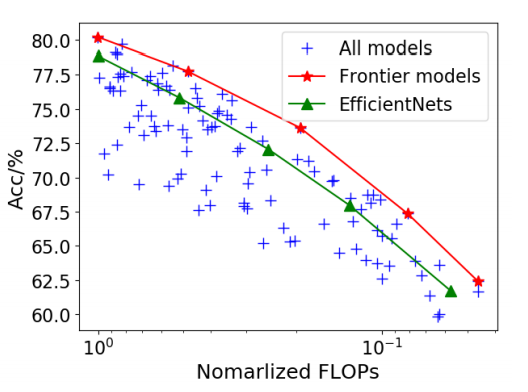
图1:图像分类精度与模型的计算量的关系。使用EfficientNet缩放公式生成的5个的模型(绿色)性能要劣于一些基于EfficientNet-B0随机突变产生的前沿模型(红色)。
本文研究的是模型精度和三个维度(模型深度,宽度,图像分辨率)的关系并希望探索出比EfficientNet更优的模型压缩范式。首先,我们发现对于轻量模型,图像分辨率和模型深度比宽度更重要。然后我们指出,EfficientNet的复合放缩方法不再适合为移动设备设计轻量网络。因此,我们通过对于前沿模型(图1中的红线)的大量实验和观察探索了一个新的压缩模型的范式‘Tiny Formula’。具体来说,给定FLOPs上限,我们通过在前沿模型上进行高斯过程回归,并用‘Tiny Formula’计算最佳输入图像分辨率和模型深度。然后根据最大FLOPs的约束来确定模型的宽度。论文中所提出的‘Tiny Formula’简单有效:例如, TinyNet-A的Top1准确率为76.8% ,计算量约为339M FLOPs,而EfficientNet-B0类似性能需要约387M FLOPs。另外,仅24M FLOPs 的TinyNet-E在ImageNet上图像分类的准确率达到59.9%,比当前体量相当的MobileNetV3高约1.9%。该文章原创地研究了如何通过同时改变分辨率、深度和宽度来生成微小且有效的神经网络。
图像分辨率,模型深度和宽度对精度的影响
图像分辨率,模型深度和宽度(Resolution, Depth, Width, 或r, d, w)是影响卷积神经网络性能的三个关键因素。但是,哪一种对性能影响更大现在并没有一个明确的结论。为了探究这个问题,我们选取了EfficientNet-B0作为基线模型,并约定其计算量为C0 FLOPs。之后,依据EfficientNet的放缩方式我们进一步得到了计算量为0.5C0的EfficientNet-B-1。我们进一步约定EfficientNet-B-1的分辨率、深度和宽度为单位1。为了在0.5C0 FLOPs这个计算量限制附近进行搜索,我们随机地改变分辨率和模型深度,并调整模型宽度w=,使新产生的模型有约0.5C0 FLOPs的计算量,这些随机搜索的模型在ImageNet-100数据集上训练了的100个epochs,训练结果如图2所示。
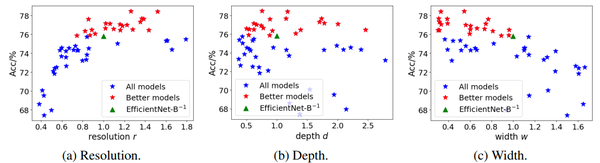
图2:在200M FLOPs的约束下,调整模型三维(图片分辨率,模型深度和宽度)对精度的影响
我们发现,高精度模型的输入图像分辨率大约在0.8到1.4之间。当r < 0.8时,分辨率越大,精度越高,而当r > 1.4时精度略微下降。在深度方面,高性能的模型深度从0.5到2不等。当固定计算量时,模型宽度与精度大致呈负相关。好模型主要分布在w < 1处。从图2中我们也发现EfficientNet-B-1精度只有75.8%,精度比相同计算量下的最佳模型要差很多。因此我们需要探索一种新的模型放缩公式,在计算量的约束下获得更好的模型。
探索最优Tiny Formula
对于给定的具有 FLOPs的神经网络(0 < c < 1,c是计算量系数),我们的目标是提供用于收缩模型的三维: r, d, w的最优值。
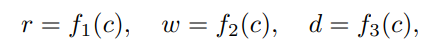
其中f1(·)、f2(·)、f3(·)为计算三个维度的函数。
为了寻找这样的函数,我们从[0.25,4]这个区间内对r, d, w进行随机采样,采样出n个参数组合。根据参数组合对基础模型的r, d, w进行改变,得到n个新模型,同时计算出n个新模型的计算量。我们根据计算量和精度,从这n个新模型中选出在帕累托前沿的m个模型(m <= n),这m个模型是我们需要的优秀模型,从而得到其r, d, w与计算量之间的关系。比如,我们得到三个关系如下所示:
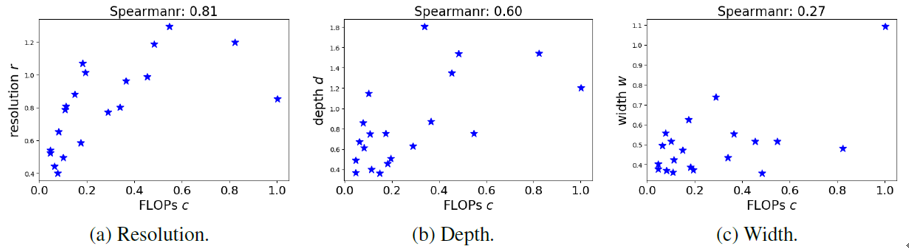
图3.帕累托前沿模型的三维(图片分辨率,模型深度和宽度)与计算量的关系
我们使用高斯过程回归来拟合上述3张图的3个曲线。以分辨率r为例,图中的m个点的横纵坐标分别为计算量FLOPs

和分辨率

。这m个点作为训练数据,训练数据和测试点c*的联合分布为如下高斯分布:
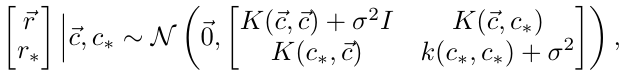
其中
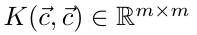
有
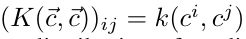
,k()是核函数(比如内积函数),
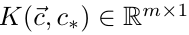
,
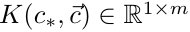
,δ是r的标准差。经过推导,我们可以得到预测值r*,也就是拟合的曲线公式:
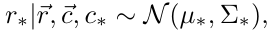
其中:
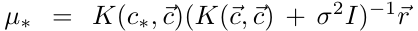
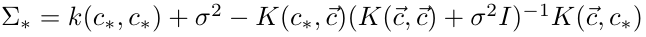
其他2个曲线公式也可以通过类似的方式得到。
得到了上述拟合曲线公式,用户只要输入想要的计算量c*,就可以得到预测的r*,d*,w*值。通过(r*,d*,w*)对基础模型EfficientNet的宽度、深度和输入分辨率进行改变,就可以得到计算量为c*的TinyNet模型。
实验结果
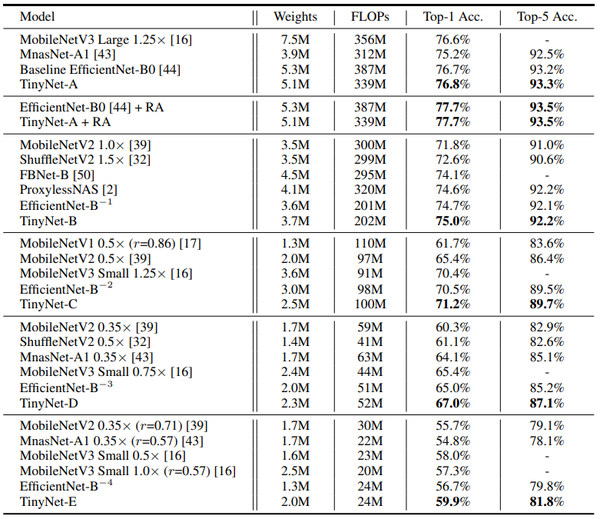
通过改变计算量系数c的值(c = {0.9, 0.5, 0.25, 0.13, 0.06})我们生成了5个轻量模型,TinyNet-A 到E。跟已有的方法相比,在同等计算量量的情况下,我们的方法能够得到性能更优的模型。其中,RA表示Random Augmentation, 一种自动数据增强的方法。
表1. TinyNet A-E在 ImageNet数据集上的精度与同样体量的业界领先模型对比
为了更好地体现TinyNet的优势,我们展示了EfficientNetB−4和TinyNet-E的可视化类激活图谱(Class Activation Map),如图4所示,相比于EfficientNetB−4,TinyNet-E会关注图片中更相关的部分。

图4:TinyNet-E和EfficientNetB−4类激活图谱(Class Activation Map)对比
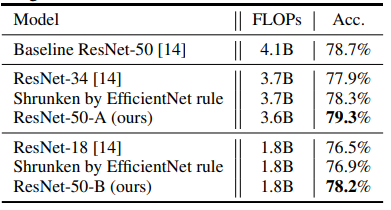
TinyNet提出的缩放方法具有很好的泛化性。除了EfficientNet-B0之外,我们还应用了我们的方法来压缩ResNet的网络架构的规模。采用ResNet-50模型作为基线模型,我们应用了EfficientNet和我们的方法对模型进行压缩。在ImageNet-100上的结果如表2所示。我们的模型总体上优于其他模型,表明所提出的‘tiny formula’的有效性。
表2. ImageNet-100数据集上使用不同方法压缩ResNet的精度对比
我们也把TinyNet应用到目标检测任务中。从表3的结果可以看出,我们的TinyNet-D与EfficientNet-B-3相比,其性能大大占优,且计算成本相当。
表3. MS COCO数据集上结果对比

MindSpore 代码实现
相关训练与推理代码,以及使用方法已经开源在:https://gitee.com/mindspore/mindspore/tree/master/model\_zoo/research/cv/tinynet
为了方便大家验证我们的结果,以及创新,我们将模型的结构,以及超参数的设置汇总到了相关代码仓的/script文件夹,我们同时提供了多卡分布式训练的启动脚本。参数设置以单卡训练脚本train\_1p\_gpu.sh为例:
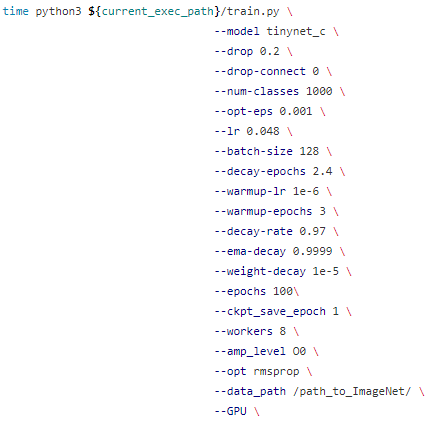
如果想切换其他的TinyNet模型,只需在—model的位置将模型从tinynet\_c更改即可。
相关模型结构定义在/src/tinynet.py中:
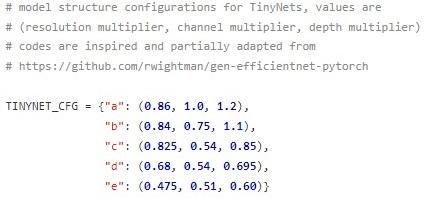
其中EfficientNet-B0为基线模型,它的输入图像分辨率,宽度和深度三维值为(1,1,1)。
TinyNet模型沿用了EfficientNet的模块化设计,其中又分为DepthwiseSeparableConv , InvertedResidual,SqueezeExcite,DropConnect,这些模块等。每一个模块都衍生自mindspore.nn.Cell。这些模块统一在GenEfficientNet中被调用,并依据用户给出的图像分辨率,宽度和深度三个数值生成神经网络。MindSpore的网络定义请参考:
https://www.mindspore.cn/tutorial/training/zh-CN/master/use/defining\_the\_network.html
数据集的加载定义在了/src/dataset.py中,主要使用了MindSpore强大的数据集加载和处理工具mindspore.dataset。具体使用方法大家可以参考:
https://www.mindspore.cn/tutorial/training/en/master/use/load\_dataset\_image.html
模型权重的指数移动平均(Exponential Moving Average),模型精度验证和训练数据的记录定义在了/src/callback.py。利用mindspore.train.callback模块,用户可以灵活地选择每一步训练或每一轮epochs后希望进行的操作,例如模型验证,Loss打印,模型保存,权重平均等。具体使用方法大家可以参考:
https://www.mindspore.cn/doc/api\_python/zh-CN/master/mindspore/mindspore.train.html
最后,我们使用MindSpore Lite工具转换了模型权重,并测试了EfficientNet和TinyNet在华为P40上的推理时延。TinyNet-A比EfficientNet-B0的运行速度快15%,但其精度与EfficientNet-B0相似。TinyNet-E与EfficientNet-B-4相比,在同等时延下,精度提升3.2%。
表4. 手机端推理时延对比

端测模型转换,部署等请参考:
广告时间:
MindSpore官网:https://www.mindspore.cn/
MindSpore论坛:https://bbs.huaweicloud.com/forum/forum-1076-1.html
代码仓地址:
Gitee-https://gitee.com/MindSpore/MindSpore
GitHub-https://github.com/MindSpore-ai/MindSpore
推荐阅读
- MindSpore首发:诺亚NeurIPS 2020多篇端侧模型轻量化技术
- 平安夜的平安果——Apple机器学习框架Core ML教程
- 2020 数字人体视觉挑战赛宫颈癌风险智能诊断_算法赛道亚军VNNI赛道冠军_LLLLC团队攻略分享
更多嵌入式AI技术干货请关注嵌入式AI专栏。

