
首发:知乎
作者:糖心他爸
一、问题的提出
当前我们在做端侧的AI处理的时候,很难百分百的将整个网络的推理过程做到一个graph里面。于是我们将AI在端侧的推理过程一般化,可以分成如下三个过程:(1)网络预处理(2)网络主体推理(3)网络后处理。
我们取常见的几个AI任务进行分析,
第一个我们先看看分类任务。还是套用上述的三个过程:
(1)网络预处理:减均值除方差,数据白化等
(2)网络主体推理:graph-inference(resnet、mobilenet、shufflenet等等)
(3)网络后处理:softmax、sigmoid
第二个我们可以看看检测任务,仍然套用上述的三个过程:
(1)网络预处理:减均值除方差,数据白化等
(2)网络主体推理:graph-inference(同上)
(3)网络后处理:position/prob decode,NMS等
后面我们主要跟大家讨论检测任务的后处理优化。常见的AI检测算法根据推理的过程,可以分成multi-scale inference(如MTCNN)、one-stage(如SSD、yolo等)、two stage(faster-rcnn等)。很多时候,在采用上述的检测算法进行推理时,我们需要将推理的流程切分成上述三个步骤。第一步和第二步在很多量化校准的过程中,可以进行合并。但最后一步后处理往往都需要将数据拉回CPU进行处理。由于端侧资源紧张,往往后处理部分的资源损耗容易被大家忽视。
我们这里取MTCNN为例,跟大家简单分析一下。mtcnn是采用multi-scale的推理过程,假设在进行prob decode的时候采用softmax。则我们对于每一个feature的点,需要执行2 * exp + 1*div + 1 * add的浮点操作,具体可参考如下softmax的计算公式:

假设每个尺度的resolution分别为:355 * 635、279 * 501、220 * 394、172 * 311、135 * 244 、106 * 192 、83 * 151、64 * 118、50 * 92、38 * 72 、29 * 56 、22 * 43 、16 * 33 、12 * 25 、 8 * 19 、 5 * 14 、3 * 10 、2 * 7。则最终所需的浮点计算数为:
(355 * 635 + 279 * 501 + 220 * 394 + 172 * 311 + 135 * 244 + 106 * 192 + 83 * 151+ 64 * 118 + 50 * 92 + 38 * 72 + 29 * 56 + 22 * 43 + 16 * 33 + 12 * 25 + 8 * 19 + 5 * 14 +3 * 10 + 2 * 7)* 4 = 2359012 flops
对于SSD这类one-stage的后处理,浮点操作数与anchor的个数正相关。如果我们在cpu中直接对该操作使用浮点进行运算,则会引入很多其他问题,比如功耗的增加、cpu利用率的增加等等。
优化的策略也很简单,就是想办法对浮点运算进行等价优化,减少浮点操作数或采用低比特运算进行代替。
二、优化策略
我们在进行后处理的时候,需要对每个特征点的输出计算softmax值然后跟给定的阈值a进行逻辑判断,将大于阈值的特征点信息引入后续的NMS阶段。我们将上述过程抽象为如下数学公式:
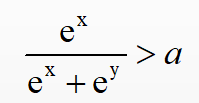
如果直接对上述的数学公式进行计算的话,我们需要做2 * exp + 1*div + 1 * add次浮点运算,其中div和exp的损耗都比add要重。除此之外,还需要进行1次逻辑判断。下面我们对上述的数学公式进行等价推导,推导的过程我直接给出了,如下图:
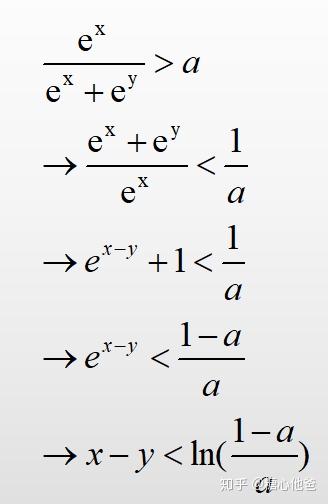
假设a是提前给出的阈值,对于ln((1-a)/a)我们可以事先进行计算。于是对于softmax概率值的计算和与阈值的逻辑判断,根据上式的推导结果,我们仅需使用1次add和1次逻辑判断。省去了2次exp和1次div的计算,这个对于cpu上的优化和推理是非常友好的。
三、最后
欢迎大家留言、关注专栏,谢谢大家!
推荐阅读
专注嵌入式端的AI算法实现,欢迎关注作者微信公众号和知乎嵌入式AI算法实现专栏。
更多嵌入式AI相关的技术文章请关注极术嵌入式AI专栏


